redis--基础以及--集群架构
Redis简介:
Redis是一款开源的、高性能的键-值存储(key-value store)。它常被称作是一款数据结构服务器(data structure server)。
Redis的键值可以包括字符串(strings)类型,同时它还包括哈希(hashes)、列表(lists)、集合(sets)和 有序集合(sorted sets)等数据类型。 对于这些数据类型,你可以执行原子操作。例如:对字符串进行附加操作(append);递增哈希中的值;向列表中增加元素;计算集合的交集、并集与差集等。
为了获得优异的性能,Redis采用了内存中(in-memory)数据集(dataset)的方式。同时,Redis支持数据的持久化,你可以每隔一段时间将数据集转存到磁盘上(snapshot),或者在日志尾部追加每一条操作命令(append only file,aof)。
Redis同样支持主从复制(master-slave replication),并且具有非常快速的非阻塞首次同步( non-blocking first synchronization)、网络断开自动重连等功能。同时Redis还具有其它一些特性,其中包括简单的事物支持、发布订阅 ( pub/sub)、管道(pipeline)和虚拟内存(vm)等 。
Redis具有丰富的客户端,支持现阶段流行的大多数编程语言。
1.Redis安装流程
wget http://download.redis.io/releases/redis-4.0.10.tar.gz tar -xvf redis-4.0.10.tar.gz cd redis-4.0.10 make make install nohup redis-server & 注:redis-server默认启动端口是6379,没有密码 如果不使用默认配置文件,启动时可以加上配置文件 nohup redis-server /redis-2.8.17/redis.conf & redis-cli -p ###进入redis##指定端口
1.2.Redis 客户端验证
127.0.0.1:6379> ping PONG ##设置键值 127.0.0.1:6379> set var "hello word" OK ##获取键值 127.0.0.1:6379> get var "hello word" ##删除键值 127.0.0.1:6379> del var ##设定有效期 127.0.0.1:6379> setex var 10 "hello word" ##用EXPIRE key s 设定过期时间 毫秒用PEXPIRE 127.0.0.1:6379> EXPIRE test11 300 ###用TTL key 查看过期时间 毫秒用PTTL 127.0.0.1:6379> TTL test11 ###用PERSIST key 取消过期时间 127.0.0.1:6379> PERSIST test11
序号 Redis keys命令及描述 1 DEL key 该命令用于在 key 存在是删除 key。 2 DUMP key 序列化给定 key ,并返回被序列化的值。 3 EXISTS key 检查给定 key 是否存在。 4 EXPIRE key seconds 为给定 key 设置过期时间。 5 EXPIREAT key timestamp EXPIREAT 的作用和 EXPIRE 类似,都用于为 key 设置过期时间。 不同在于 EXPIREAT 命令接受的时间参数是 UNIX 时间戳(unix timestamp)。 6 PEXPIRE key milliseconds 设置 key 的过期时间亿以毫秒计。 7 PEXPIREAT key milliseconds-timestamp 设置 key 过期时间的时间戳(unix timestamp) 以毫秒计 8 KEYS pattern 查找所有符合给定模式( pattern)的 key 。例如keys * 返回所有的key 9 MOVE key db 将当前数据库的 key 移动到给定的数据库 db 当中。 10 PERSIST key 移除 key 的过期时间,key 将持久保持。 11 PTTL key 以毫秒为单位返回 key 的剩余的过期时间。 12 TTL key 以秒为单位,返回给定 key 的剩余生存时间(TTL, time to live)。 13 RANDOMKEY 从当前数据库中随机返回一个 key 。 14 RENAME key newkey 修改 key 的名称 15 RENAMENX key newkey 仅当 newkey 不存在时,将 key 改名为 newkey 。 16 TYPE key 返回 key 所储存的值的类型。
1.3.Redis关闭程序
redis-cli shutdown systemctl stop redis ####如果yum安装的用启动程序关闭 注:如果设置上密码后,单纯的redis-cli是关不掉的,必须加上ip、port、passwd redis-cli -h host -p port -a passwd shutdown
1.4.退出客户端
localhost:6379> QUIT
1.5.设立密码,并访问连接
打开redis.conf找到requirepass,去掉默认,修改 requirepass test111 nohup redis-server /data/ops/app/redis-4.0.10/redis.conf & ##指定配置文件 redis-cli -h 127.0.0.1 -p 6379 -a test111 ##当设置密码后就得这样输入
auth test111
OK 如果想远程机子访问这个redis需要改配置文件redis.conf protected-mode no ##改为no #bind 127.0.0.1 ###注释只本地访问 ###改完重启redis后就可以访问了 # redis-cli -h 10.240.17.103 -p 6379 -a test111 ##远程访问
1.6.查看redis数据统计信息
1.5 查看redis数据库统计信息 在cli下执行info 相关含义: Mrds:6379> info # Server redis_version:2.8.19 ###redis版本号 redis_git_sha1:00000000 ###git SHA1 redis_git_dirty:0 ###git dirty flag redis_build_id:78796c63e58b72dc redis_mode:standalone ###redis运行模式 os:Linux 2.6.32-431.el6.x86_64 x86_64 ###os版本号 arch_bits:64 ###64位架构 multiplexing_api:epoll ###调用epoll算法 gcc_version:4.4.7 ###gcc版本号 process_id:25899 ###服务器进程PID run_id:eae356ac1098c13b68f2b00fd7e1c9f93b1c6a2c ###Redis的随机标识符(用于sentinel和集群) tcp_port:6379 ###Redis监听的端口号 uptime_in_seconds:6419 ###Redis运行时长(s为单位) uptime_in_days:0 ###Redis运行时长(天为单位) hz:10 lru_clock:10737922 ###以分钟为单位的自增时钟,用于LRU管理 config_file:/etc/redis/redis.conf ###redis配置文件 # Clients connected_clients:1 ###已连接客户端的数量(不包括通过从属服务器连接的客户端) client_longest_output_list:0 ###当前连接的客户端中最长的输出列表 client_biggest_input_buf:0 ###当前连接的客户端中最大的输出缓存 blocked_clients:0 ###正在等待阻塞命令(BLPOP、BRPOP、BRPOPLPUSH)的客户端的数量 需监控 # Memory used_memory:2281560 ###由 Redis 分配器分配的内存总量,以字节(byte)为单位 used_memory_human:2.18M ###以更友好的格式输出redis占用的内存 used_memory_rss:2699264 ###从操作系统的角度,返回 Redis 已分配的内存总量(俗称常驻集大小)。这个值和 top 、 ps 等命令的输出一致 used_memory_peak:22141272 ### Redis 的内存消耗峰值(以字节为单位) used_memory_peak_human:21.12M ###以更友好的格式输出redis峰值内存占用 used_memory_lua:35840 ###LUA引擎所使用的内存大小 mem_fragmentation_ratio:1.18 ###used_memory_rss 和 used_memory 之间的比率 mem_allocator:jemalloc-3.6.0 ###在理想情况下, used_memory_rss 的值应该只比 used_memory 稍微高一点儿。当 rss > used ,且两者的值相差较大时,表示存在(内部或外部的)内存碎片。内存碎片的比率可以通过 mem_fragmentation_ratio 的值看出。 当 used > rss 时,表示 Redis 的部分内存被操作系统换出到交换空间了,在这种情况下,操作可能会产生明显的延迟。 # Persistence loading:0 ###记录服务器是否正在载入持久化文件 rdb_changes_since_last_save:0 ###距离最近一次成功创建持久化文件之后,经过了多少秒 rdb_bgsave_in_progress:0 ###记录了服务器是否正在创建 RDB 文件 rdb_last_save_time:1420023749 ###最近一次成功创建 RDB 文件的 UNIX 时间戳 rdb_last_bgsave_status:ok ###最近一次创建 RDB 文件的结果是成功还是失败 rdb_last_bgsave_time_sec:0 ###最近一次创建 RDB 文件耗费的秒数 rdb_current_bgsave_time_sec:-1 ###如果服务器正在创建 RDB 文件,那么这个域记录的就是当前的创建操作已经耗费的秒数 aof_enabled:1 ###AOF 是否处于打开状态 aof_rewrite_in_progress:0 ###服务器是否正在创建 AOF 文件 aof_rewrite_scheduled:0 ###RDB 文件创建完毕之后,是否需要执行预约的 AOF 重写操作 aof_last_rewrite_time_sec:-1 ###最近一次创建 AOF 文件耗费的时长 aof_current_rewrite_time_sec:-1 ###如果服务器正在创建 AOF 文件,那么这个域记录的就是当前的创建操作已经耗费的秒数 aof_last_bgrewrite_status:ok ###最近一次创建 AOF 文件的结果是成功还是失败 aof_last_write_status:ok aof_current_size:176265 ###AOF 文件目前的大小 aof_base_size:176265 ###服务器启动时或者 AOF 重写最近一次执行之后,AOF 文件的大小 aof_pending_rewrite:0 ###是否有 AOF 重写操作在等待 RDB 文件创建完毕之后执行 aof_buffer_length:0 ###AOF 缓冲区的大小 aof_rewrite_buffer_length:0 ###AOF 重写缓冲区的大小 aof_pending_bio_fsync:0 ###后台 I/O 队列里面,等待执行的 fsync 调用数量 aof_delayed_fsync:0 ###被延迟的 fsync 调用数量 # Stats total_connections_received:8466 ###服务器已接受的连接请求数量 total_commands_processed:900668 ###服务器已执行的命令数量 instantaneous_ops_per_sec:1 ###服务器每秒钟执行的命令数量 total_net_input_bytes:82724170 total_net_output_bytes:39509080 instantaneous_input_kbps:0.07 instantaneous_output_kbps:0.02 rejected_connections:0 ###因为最大客户端数量限制而被拒绝的连接请求数量 sync_full:2 sync_partial_ok:0 sync_partial_err:0 expired_keys:0 ###因为过期而被自动删除的数据库键数量 evicted_keys:0 ###因为最大内存容量限制而被驱逐(evict)的键数量。 keyspace_hits:0 ###查找数据库键成功的次数。 keyspace_misses:500000 ###查找数据库键失败的次数。 pubsub_channels:0 ###目前被订阅的频道数量 pubsub_patterns:0 ###目前被订阅的模式数量 latest_fork_usec:402 ###最近一次 fork() 操作耗费的毫秒数 # Replication role:master ###如果当前服务器没有在复制任何其他服务器,那么这个域的值就是 master ;否则的话,这个域的值就是 slave 。注意,在创建复制链的时候,一个从服务器也可能是另一个服务器的主服务器 connected_slaves:2 ###2个slaves slave0:ip=192.168.65.130,port=6379,state=online,offset=1639,lag=1 slave1:ip=192.168.65.129,port=6379,state=online,offset=1639,lag=0 master_repl_offset:1639 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:2 repl_backlog_histlen:1638 # CPU used_cpu_sys:41.87 ###Redis 服务器耗费的系统 CPU used_cpu_user:17.82 ###Redis 服务器耗费的用户 CPU used_cpu_sys_children:0.01 ###后台进程耗费的系统 CPU used_cpu_user_children:0.01 ###后台进程耗费的用户 CPU # Keyspace db0:keys=3101,expires=0,avg_ttl=0 ###keyspace 部分记录了数据库相关的统计信息,比如数据库的键数量、数据库已经被删除的过期键数量等。对于每个数据库,这个部分都会添加一行以下格式的信息
1.7 其他命令
##查看记录数 127.0.0.1:6379> dbsize ##查看所有KEY 127.0.0.1:6379> KEYS * ##列出所有客户端连接 127.0.0.1:6379> CLIENT LIST ##关闭ip:port的客户端 127.0.0.1:6379> CLIENT KILL 127.0.0.1:11902 ##清空所有数据库的所有key 127.0.0.1:6379> FLUSHALL ##清空当前数据库中所有key 127.0.0.1:6379> FLUSHDB ##返回最后一次成功保存数据到磁盘的时间,以UNIX时间戳格式表示 127.0.0.1:6379> LASTSAVE ##返回当前服务器时间,以UNIX时间戳格式表示 127.0.0.1:6379> TIME ##连接到其他数据库(默认数据库是0) 127.0.0.1:6379> SELECT 1 ##将当前数据库的 key 移动到指定的数据库 127.0.0.1:6379> MOVE test2 1
1.8./etc/redis.conf
daemonize no 是否以后台daemon方式运行 timeout 0 请求超时时间 maxclients 10000 最大连接数 maxmemory <bytes> 最大内存 maxmemory-policy volatile-lru 达到最大内存时的LRU驱逐策略 maxmemory-samples 3 随机抽取n个key执行LRU hash-max-ziplist-entries 512 Map内部不超过多少个成员时会采用线性紧凑格式存储 hash-max-ziplist-value 64 Map内成员值长度不超过多少字节会采用线性紧凑格式存储 类似的还有,list-max-ziplist-entries 512,list-max-ziplist-value 64等等 slowlog-log-slower-than 10000 slow log计入时间,microseconds(1000000) slowlog-max-len 128 slow log计入条数
查看最大连接数 127.0.0.1:6379> config get maxclients 1) "maxclients" 2) "10000" 运行过程中调整参数 127.0.0.1:6379> config set maxclients 10001
2.数据持久化
众所周知,redis是内存数据库,它把数据存储在内存中,这样在加快读取速度的同时也对数据安全性产生了新的问题,即当redis所在服务器发生宕机后,redis数据库里的所有数据将会全部丢失。
为了解决这个问题,redis提供了持久化功能——RDB和AOF。通俗的讲就是将内存中的数据写入硬盘中。
一、持久化之全量写入:RDB
more redis.conf save 900 1 save 300 10 save 60 10000 dbfilename "dump.rdb" #持久化文件名称 dir "/data/dbs/redis/6381" #持久化数据文件存放的路径
上面是redis配置文件里默认的RDB持久化设置,前三行都是对触发RDB的一个条件,例如第一行的意思是每900秒钟里redis数据库有一条数据被修改则触发RDB,依次类推;只要有一条满足就会调用BGSAVE进行RDB持久化。第四行dbfilename指定了把内存里的数据库写入本地文件的名称,该文件是进行压缩后的二进制文件,通过该文件可以把数据库还原到生成该文件时数据库的状态。第五行dir指定了RDB文件存放的目录。
配置文件修改需要重启redis服务,我们还可以在命令行里进行配置,即时生效,服务器重启后需重新配置
bin/redis-cli 127.0.0.1:6379> CONFIG GET save #查看redis持久化配置 1) "save" 2) "900 1 300 10 60 10000" 127.0.0.1:6379> CONFIG SET save "21600 1000" #修改redis持久化配置 OK
而RDB持久化也分两种:SAVE和BGSAVE
SAVE是阻塞式的RDB持久化,当执行这个命令时redis的主进程把内存里的数据库状态写入到RDB文件(即上面的dump.rdb)中,直到该文件创建完毕的这段时间内redis将不能处理任何命令请求。
BGSAVE属于非阻塞式的持久化,它会创建一个子进程专门去把内存中的数据库状态写入RDB文件里,同时主进程还可以处理来自客户端的命令请求。但子进程基本是复制的父进程,这等于两个相同大小的redis进程在系统上运行,会造成内存使用率的大幅增加。
(本人在生产中就碰到过这问题,redis本身内存使用率就60%,总的内存使用率在百分之七八十左右,持久化的时候立马飙到百分之一百三十多,告警邮件是每天几十封/(ㄒoㄒ)/~~ 最后根据需求选择了AOF持久化)
二、持久化之增量写入:AOF
与RDB的保存整个redis数据库状态不同,AOF是通过保存对redis服务端的写命令(如set、sadd、rpush)来记录数据库状态的,即保存你对redis数据库的写操作,以下就是AOF文件的内容

1 [redis@iZ]$ more appendonly.aof 2 *2 3 $6 4 SELECT 5 $1 6 0 7 *3 8 $3 9 SET 10 $47 11 DEV_USER_LEGAL_F9683BE0E27F1A06C0CB869CEC7E3B22 12 $11 13 ¬ 14 *3 15 $3 16 SET 17 $47
先让我们看看如何配置AOF
1 [redis@iZ]$ more ~/redis/conf/redis.conf 2 dir "/data/dbs/redis/6381" #AOF文件存放目录 3 appendonly yes #开启AOF持久化,默认关闭 4 appendfilename "appendonly.aof" #AOF文件名称(默认) 5 appendfsync no #AOF持久化策略 6 auto-aof-rewrite-percentage 100 #触发AOF文件重写的条件(默认) 7 auto-aof-rewrite-min-size 64mb #触发AOF文件重写的条件(默认)
要弄明白上面几个配置就得从AOF的实现去理解,AOF的持久化是通过命令追加、文件写入和文件同步三个步骤实现的。当reids开启AOF后,服务端每执行一次写操作(如set、sadd、rpush)就会把该条命令追加到一个单独的AOF缓冲区的末尾,这就是命令追加;然后把AOF缓冲区的内容写入AOF文件里。看上去第二步就已经完成AOF持久化了那第三步是干什么的呢?这就需要从系统的文件写入机制说起:一般我们现在所使用的操作系统,为了提高文件的写入效率,都会有一个写入策略,即当你往硬盘写入数据时,操作系统不是实时的将数据写入硬盘,而是先把数据暂时的保存在一个内存缓冲区里,等到这个内存缓冲区的空间被填满或者是超过了设定的时限后才会真正的把缓冲区内的数据写入硬盘中。也就是说当redis进行到第二步文件写入的时候,从用户的角度看是已经把AOF缓冲区里的数据写入到AOF文件了,但对系统而言只不过是把AOF缓冲区的内容放到了另一个内存缓冲区里而已,之后redis还需要进行文件同步把该内存缓冲区里的数据真正写入硬盘上才算是完成了一次持久化。而何时进行文件同步则是根据配置的appendfsync来进行:
appendfsync有三个选项:always、everysec和no:
1、选择always的时候服务器会在每执行一个事件就把AOF缓冲区的内容强制性的写入硬盘上的AOF文件里,可以看成你每执行一个redis写入命令就往AOF文件里记录这条命令,这保证了数据持久化的完整性,但效率是最慢的,却也是最安全的;
2、配置成everysec的话服务端每执行一次写操作(如set、sadd、rpush)也会把该条命令追加到一个单独的AOF缓冲区的末尾,并将AOF缓冲区写入AOF文件,然后每隔一秒才会进行一次文件同步把内存缓冲区里的AOF缓存数据真正写入AOF文件里,这个模式兼顾了效率的同时也保证了数据的完整性,即使在服务器宕机也只会丢失一秒内对redis数据库做的修改;
3、将appendfsync配置成no则意味redis数据库里的数据就算丢失你也可以接受,它也会把每条写命令追加到AOF缓冲区的末尾,然后写入文件,但什么时候进行文件同步真正把数据写入AOF文件里则由系统自身决定,即当内存缓冲区的空间被填满或者是超过了设定的时限后系统自动同步。这种模式下效率是最快的,但对数据来说也是最不安全的,如果redis里的数据都是从后台数据库如mysql中取出来的,属于随时可以找回或者不重要的数据,那么可以考虑设置成这种模式。
相比RDB每次持久化都会内存翻倍,AOF持久化除了在第一次启用时会新开一个子进程创建AOF文件会大幅度消耗内存外,之后的每次持久化对内存使用都很小。但AOF也有一个不可忽视的问题:AOF文件过大。你对redis数据库的每一次写操作都会让AOF文件里增加一条数据,久而久之这个文件会形成一个庞然大物。还好的是redis提出了AOF重写的机制,即我们上面配置的auto-aof-rewrite-percentage和auto-aof-rewrite-min-size。AOF重写机制这里暂不细述,之后本人会另开博文对此解释,有兴趣的同学可以看看。我们只要知道AOF重写既是重新创建一个精简化的AOF文件,里面去掉了多余的冗余命令,并对原AOF文件进行覆盖。这保证了AOF文件大小处于让人可以接受的地步。而上面的auto-aof-rewrite-percentage和auto-aof-rewrite-min-size配置触发AOF重写的条件。
Redis 会记录上次重写后AOF文件的文件大小,而当前AOF文件大小跟上次重写后AOF文件大小的百分比超过auto-aof-rewrite-percentage设置的值,同时当前AOF文件大小也超过auto-aof-rewrite-min-size设置的最小值,则会触发AOF文件重写。以上面的配置为例,当现在的AOF文件大于64mb同时也大于上次重写AOF后的文件大小,则该文件就会被AOF重写。
最后需要注意的是,如果redis开启了AOF持久化功能,那么当redis服务重启时会优先使用AOF文件来还原数据库。
1. Redis主从同步
Redis支持主从同步。数据可以从主服务器向任意数量的从服务器上同步,同步使用的是发布/订阅机制。
2. 配置主从同步
Mater Slave的模式,从Slave向Master发起SYNC命令。
可以是1 Master 多Slave,可以分层,Slave下可以再接Slave,可扩展成树状结构。
2.1 配置Mater,Slave
配置非常简单,只需在slave的设定文件中指定master的ip和port
Master: test166
修改设定文件,服务绑定到ip上
|
1
2
|
# vi /etc/redis.confbind 10.86.255.166 |
重启Redis
# systemctl restart redis
|
1
|
# less /etc/redis.conf |
Slave: test167
修改设定文件,指定Master
|
1
2
3
|
slaveof <masterip> <masterport> 指定master的ip和portmasterauth <master-password> master有验证的情况下slave-read-only yes 设置slave为只读模式 |
也可以用命令行设定:
|
1
2
|
redis 127.0.0.1:9999> slaveof localhost 6379OK |
2.2 同期情况确认
Master:
|
1
2
3
4
5
6
|
127.0.0.1:6379> INFO replication# Replicationrole:masterconnected_slaves:1slave0:ip=10.86.255.167,port=6379,state=online,offset=309,lag=1…… |
Slave:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
127.0.0.1:6379> INFO replication# Replicationrole:slavemaster_host:10.86.255.166master_port:6379master_link_status:upmaster_last_io_seconds_ago:7master_sync_in_progress:0slave_repl_offset:365slave_priority:100slave_read_only:1connected_slaves:0master_repl_offset:0repl_backlog_active:0repl_backlog_size:1048576repl_backlog_first_byte_offset:0repl_backlog_histlen:0 |
同期正常时:
master_link_status:up
master_repl_offset和slave_repl_offset相等,
master_last_io_seconds_ago在10秒内。
2.3 Slave升级为Master
Master不可用的情况下,停止Master,将Slave的设定无效化后,Slave升级为Master
|
1
2
3
4
5
6
7
|
redis 127.0.0.1:9999> SLAVEOF NO ONE OKredis 127.0.0.1:9999> info......role:master...... |
2.4 Health Check
Slave按照repl-ping-slave-period的间隔(默认10秒),向Master发送ping。
如果主从间的链接中断后,再次连接的时候,2.8以前按照full sync再同期。2.8以后,因为有backlog的设定,backlog存在master的内存里,重新连接之前,如果redis没有重启,并且offset在backlog保存的范围内,可以实现从断开地方同期,不符合这个条件,还是full sync
用monitor命令,可以看到slave在发送ping
|
1
2
3
|
127.0.0.1:6379> monitorOK1448515184.249169 [0 10.86.255.166:6379] "PING" |
2.5 设置Master的写行为
2.8以后,可以在设定文件中设置,Master只有当有N个Slave处于连接状态时,接受写操作
|
1
2
|
min-slaves-to-write 3min-slaves-max-lag 10 |
3. Redis HA管理工具
redis-sentinel 能监视同期的状态,发现Master down的时候,会进行failover,将Slave升级为Master,启动后会自动更新sentinel设定文件,发生failover时,会自动修改sentinel和redis的设定文件
环境:
Master: 10.86.255.167 :6379 sentinel:26379
Slave1: 10.86.255.166 :6379 sentinel:26379
Slave2: 10.86.255.167 :7379 sentinel:36379
Sentinel的设定文件在/etc/redis-sentinel.conf,对failover的动作等可以进行一些定义,本次主要验证Sentinel的动作,设定文件可以根据具体情况自行调整
3.1 设定Master,Slave
参照上文设定Master,Slave,并确认Mater和2个Slave的同期状态正常
3.2 Master上设定Sentinel
|
1
2
3
|
# vi /etc/redis-sentinel.confdaemonize yessentinel monitor mymaster <master ip> 6379 2 |
启动sentinel
|
1
2
3
|
# redis-sentinel /etc/redis-sentinel.conf或# redis-server /etc/redis-sentinel.conf --sentinel |
确认
|
1
2
|
# redis-cli -p 26379127.0.0.1:26379> INFO sentinel |

确认Master信息
|
1
|
127.0.0.1:26379> sentinel masters |
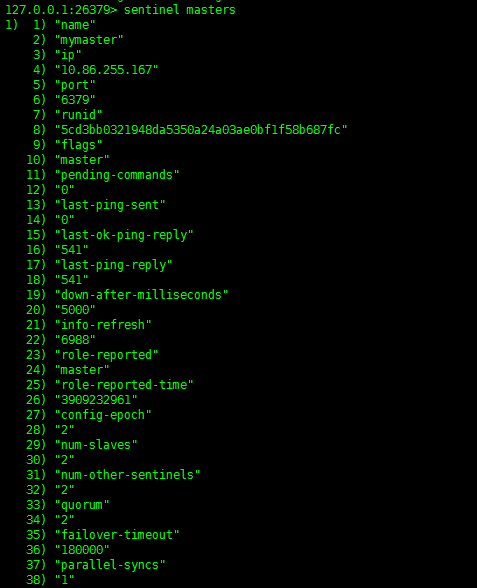
确认Slave信息
|
1
|
127.0.0.1:26379> sentinel slaves mymaster |
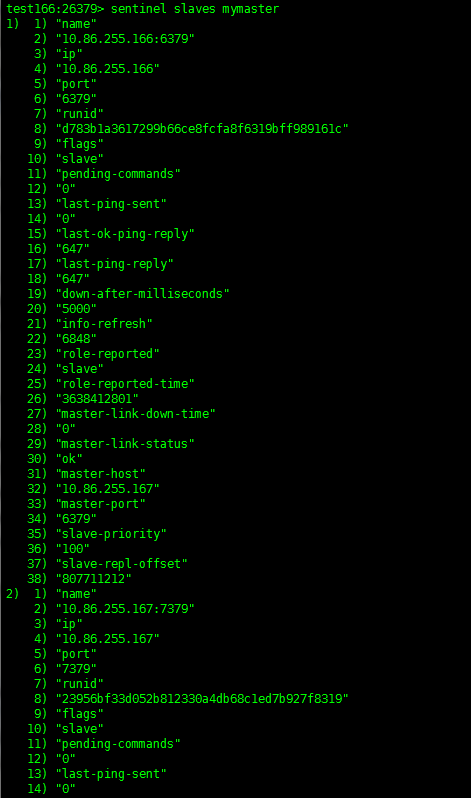
3.3 Slave上设定Sentinel
在slave1上设定sentinel
|
1
2
3
|
# vi /etc/redis-sentinel.confdaemonize yessentinel monitor mymaster <master ip> 6379 2 |
启动slave1
|
1
|
# redis-sentinel /etc/redis-sentinel.conf |
在slave2上设定sentinel
|
1
2
3
4
|
# less /etc/redis-sentinel_36379.confdaemonize yesport 36379sentinel monitor mymaster <master ip> 6379 2 |
启动slave2
|
1
|
# redis-sentinel /etc/redis-sentinel_36379.conf |
3.4 动作确认
停止Master
|
1
|
127.0.0.1:6379> SHUTDOWN |
确认日志发生fail over
|
1
|
# tail /var/log/redis/sentinel.log |
确认Slave2变成Master,Slave1是Slave
|
1
|
test167:7379> info replication |
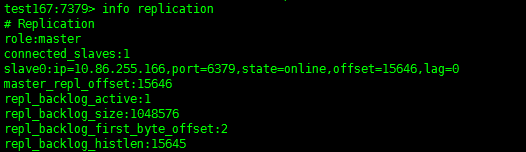
|
1
|
test166:6379> info replication |

启动刚才停掉的Master,确认变为Slave
|
1
|
10.86.255.167:6379> info replication |
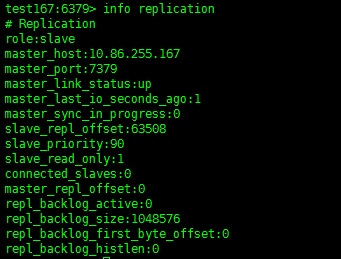
3.5 Sentinel命令
|
1
2
3
4
5
6
|
127.0.0.1:26379> sentinel masters127.0.0.1:26379> sentinel slaves mymaster127.0.0.1:26379> SENTINEL get-master-addr-by-name mymaster127.0.0.1:26379> SENTINEL reset mymaster127.0.0.1:26379> SENTINEL failover mymaster127.0.0.1:26379> SENTINEL flushconfig mymaster |


daemonize yes pidfile /data/ops/app/redis-2.8.17_yunping_6381/redis.pid port 6381 tcp-backlog 20000 timeout 0 tcp-keepalive 0 loglevel notice logfile "/data/ops/app/redis-2.8.17_yunping_6381/redis.log" databases 16 stop-writes-on-bgsave-error yes rdbcompression yes rdbchecksum yes dbfilename dump.rdb dir ./ slave-serve-stale-data yes slave-read-only yes repl-disable-tcp-nodelay no slave-priority 100 maxmemory 2GB appendonly no appendfilename "appendonly.aof" appendfsync everysec no-appendfsync-on-rewrite no auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb aof-load-truncated yes lua-time-limit 5000 slowlog-log-slower-than 10000 slowlog-max-len 128 latency-monitor-threshold 0 notify-keyspace-events "" hash-max-ziplist-entries 512 hash-max-ziplist-value 64 list-max-ziplist-entries 512 list-max-ziplist-value 64 set-max-intset-entries 512 zset-max-ziplist-entries 128 zset-max-ziplist-value 64 hll-sparse-max-bytes 3000 activerehashing yes client-output-buffer-limit normal 0 0 0 client-output-buffer-limit slave 256mb 64mb 60 client-output-buffer-limit pubsub 32mb 8mb 60 hz 10 aof-rewrite-incremental-fsync yes rename-command CONFIG "" rename-command EVAL ""

 浙公网安备 33010602011771号
浙公网安备 33010602011771号