
mysql索引优化
1. 索引的优点
大大减少了服务器需要扫描的数据量
帮助服务器避免排序和临时表
将随机io变成了顺序io
2. 索引的分类
主键索引 唯一键索引 普通索引
全文索引(text,varchar类型,类似es,solr全文) 组合索引
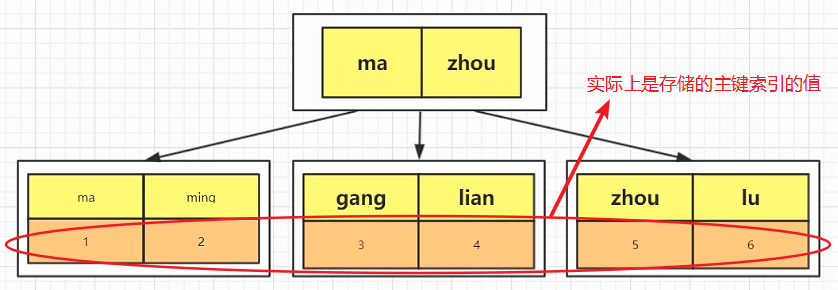
3. 回表
除了主键索引,后添加了普通的name索引,根据name索引查找的叶子节点数据,实际上是存储的主键索引的值,然后根据主键索引来查找其他列的数据,这叫回表
如果不需要其他列的信息,只要name列,不用回表
没增加一个索引都会生成一个列的B+树,根据name列的B+树,查找到子节点储存的主键,然后到主键列的B+树查找对应的数据信息
4. 最左匹配原则
(name,age)建立组合索引,第1,2,4条会生效,与顺序无关,mysql自动优化
select * from t1 where name = '张三'
select * from t1 where name = '张三' and age = '10'
select * from t1 where age = '10'
select * from t1 where age = '20' and name = '张三'
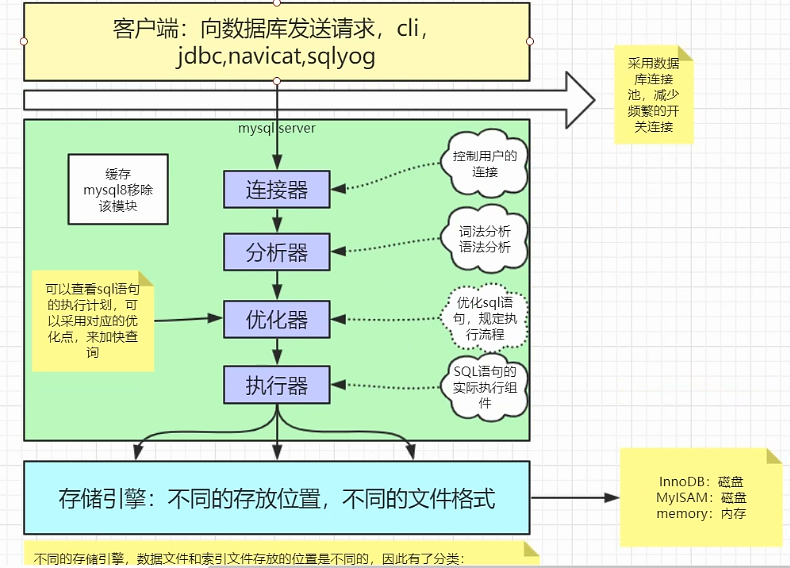
5. 执行过程
6. 索引下推
name,age索引字段
原来是先找name的值,然后在匹配age的值,下推操作是直接在最底层存储引擎匹配,匹配出来的数据量变小,执行的io变小
直接从存储引擎拉取数据的时候直接按照name,age做判断,将符合的结果返回给mysqlserver
7. 哈希索引的缺点
利用hash存储的话需要将所有的数据文件添加到内存,比较耗费内存空间
如果是等值的查询,hash索引快,但是hash索引不支持不等值的查询
8. 优化细节
sql语句尽量不要用表达式,把计算放在业务层
尽量使用主键索引,而不是其他列索引,因为主键索引不会触发回表操作
使用前缀索引
使用索引来排序
union all,in,or都能够使用索引,推荐用in
范围列可以用到索引
强制类型转换会全表扫描
更新十分频繁,数据区分度不高的字段不宜建立索引
创建索引的列,不允许为null
当需要连表的时候,最好不要超过三张
能使用limit的时候尽量使用limit
单表索引控制在5个以内
不是索引越多越好,不是所有查询优化都需要建立索引
9. 哪些情况不走索引
索引列参与计算
索引列使用函数
索引列使用前置百分号%name
使用or必须所有条件都是索引列,尽量不要使用or
join操作时,必须主键和外键的数据类型相同时才生效
索引列存在强制类型转换的时候, bigint varchar
select *
