
docker专题(四)swarm
前言
上一个章节安装了四台虚拟机,当前swarm就在这四台虚拟机上实验
简介
Swarm 是 Docker 官方提供的一款集群管理工具,其主要作用是把若干台 Docker 主机抽象为一个整体,并且通过一个入口统一管理这些 Docker 主机上的各种 Docker 资源。
Docker Swarm 包含两方面:一个企业级的 Docker 安全集群,以及一个微服务应用编排引擎 。
集群方面,Swarm 将一个或多个 Docker 节点组织起来,使得用户能够以集群方式管理它们。
Swarm 默认内置有加密的分布式集群存储(encrypted distributed cluster store)、加密网络(Encrypted Network)、公用TLS(Mutual TLS)、安全集群接入令牌 Secure Cluster Join Token)以及一套简化数字证书管理的 PKI(Public Key Infrastructure)。我们可以自如地添加或删除节点。
编排方面,Swarm 提供了一套丰富的 API 使得部署和管理复杂的微服务应用变得易如反掌。通过将应用定义在声明式配置文件中,就可以使用原生的 Docker 命令完成部署。
此外,甚至还可以执行滚动升级、回滚以及扩缩容操作,同样基于简单的命令即可完成。
Nodes
一个节点是Docker参与Swarm的一个实例。您也可以将其视为 Docker 节点
worker节点接收并执行从管理节点分派的任务。默认情况下,管理器节点也将服务作为worker节点运行,但您可以将它们配置为专门运行manager任务并成为仅manager节点。代理在每个worke节点上运行并报告分配给它的任务。worker 节点将其分配的任务的当前状态通知给 manager 节点,以便 manager 可以维护每个 worker 的期望状态。
Services and tasks
一个服务是任务的定义,manager或worker节点上执行。它是 swarm 系统的中心结构,也是用户与 swarm 交互的主要根源。
创建服务时,您需要指定要使用的容器映像以及要在运行的容器内执行的命令。
在复制服务模型中,群管理器根据您在所需状态中设置的规模在节点之间分配特定数量的副本任务。
对于全局服务,swarm 在集群中的每个可用节点上为该服务运行一项任务。
一个任务携带一个 Docker 容器和在容器内运行的命令。它是swarm的原子调度单元。管理节点根据服务规模中设置的副本数量将任务分配给worker节点。一旦任务被分配到一个节点,它就不能移动到另一个节点。它只能在指定的节点上运行或失败。
Load balancing
swarm 管理器使用入口负载平衡来公开您希望在 swarm 外部可用的服务。群管理器可以自动为该服务分配一个PublishedPort,或者您可以为该服务配置一个 PublishedPort。您可以指定任何未使用的端口。如果你没有指定端口,swarm manager 会为服务分配一个 30000-32767 范围内的端口。
外部组件(例如云负载均衡器)可以访问集群中任何节点的 PublishedPort 上的服务,无论该节点当前是否正在运行该服务的任务。swarm 中的所有节点都路由入口连接到正在运行的任务实例。
Swarm 模式有一个内部 DNS 组件,可以自动为 swarm 中的每个服务分配一个 DNS 条目。群管理器使用内部负载平衡根据服务的 DNS 名称在集群内的服务之间分配请求。
环境准备
三台虚拟机,一台manager 两台worker,固定虚拟机ip参考
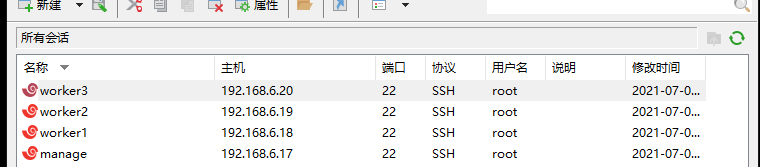
| 名称 | ip |
|---|---|
| manager | 192.168.6.17 |
| worker1 | 192.168.6.18 |
| worker2 | 192.168.6.19 |
需要修改一下主机名称参考
#执行命令将主机改为manager
[root@localhost ~]# hostnamectl set-hostname manager
#修改配置文件
[root@localhost ~]# vim /etc/hosts
#重启
[root@localhost ~]# reboot
swarm官方例子
创建swarm manager和worker
1.创建swarm
docker swarm init --advertise-addr <MANAGER-IP>
#当前节点是manager
#添加worker节点运行命令: docker swarm join --token SWMTKN-1-1fmah57r3nzokjcnl1rtbd4bb49xggxy45ovw9vacpg9rk0axc-45ygfd04r2qyq80s5or9a8t5j 192.168.6.17:2377
#添加manager节点的运行命令 docker swarm join-token manager
[root@localhost ~]# docker swarm init --advertise-addr 192.168.6.17
Swarm initialized: current node (z8wbqg138k7g3jte6wt8boul5) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-1fmah57r3nzokjcnl1rtbd4bb49xggxy45ovw9vacpg9rk0axc-45ygfd04r2qyq80s5or9a8t5j 192.168.6.17:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
- 运行
docker info以查看 swarm 的当前状态
[root@localhost ~]# docker info
Server:
Containers: 0
Running: 0
Paused: 0
Stopped: 0
#省略部分
Swarm: active
NodeID: z8wbqg138k7g3jte6wt8boul5
Is Manager: true
ClusterID: a0p1bf7udpjpl1klkyoe0qyu5
Managers: 1
Nodes: 1
#省略
- 运行
docker node ls命令查看节点信息:
[root@localhost ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
z8wbqg138k7g3jte6wt8boul5 * localhost.localdomain Ready Active Leader 20.10.7
注: 在*该节点ID下一表明当前连接此节点上。
-
以创建加入到现有 swarm 的工作节点
在woker1机器上运行
#运行主节点给出的命令,发现报错
[root@localhost ~]# docker swarm join --token SWMTKN-1-1fmah57r3nzokjcnl1rtbd4bb49xggxy45ovw9vacpg9rk0axc-45ygfd04r2qyq80s5or9a8t5j 192.168.6.17:2377
Error response from daemon: rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 192.168.6.17:2377: connect: no route to host"
[root@localhost ~]# ping 192.168.6.17
PING 192.168.6.17 (192.168.6.17) 56(84) bytes of data.
64 bytes from 192.168.6.17: icmp_seq=1 ttl=64 time=0.258 ms
64 bytes from 192.168.6.17: icmp_seq=2 ttl=64 time=0.307 ms
64 bytes from 192.168.6.17: icmp_seq=3 ttl=64 time=0.287 ms
^C
--- 192.168.6.17 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2001ms
rtt min/avg/max/mdev = 0.258/0.284/0.307/0.020 ms
#问题一原因就是manager节点这台机器上的防火墙没有关闭
#参考:https://www.cnblogs.com/shenjianping/p/12264103.html
[root@localhost ~]# systemctl status firewalld.service
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; enabled; vendor preset: enabled)
Active: active (running) since 五 2021-07-02 15:52:40 CST; 15h ago
Docs: man:firewalld(1)
Main PID: 677 (firewalld)
Tasks: 2
Memory: 492.0K
CGroup: /system.slice/firewalld.service
└─677 /usr/bin/python2 -Es /usr/sbin/firewalld --nofork --nopid
7月 02 16:10:38 localhost.localdomain firewalld[677]: WARNING: COMMAND_FAILED: '/usr/sbin/iptables -w10 -t filter -X DOCKER-...name.
7月 02 16:10:38 localhost.localdomain firewalld[677]: WARNING: COMMAND_FAILED: '/usr/sbin/iptables -w10 -t filter -F DOCKER-...name.
7月 02 16:10:38 localhost.localdomain firewalld[677]: WARNING: COMMAND_FAILED: '/usr/sbin/iptables -w10 -t filter -X DOCKER-...name.
7月 02 16:10:38 localhost.localdomain firewalld[677]: WARNING: COMMAND_FAILED: '/usr/sbin/iptables -w10 -D FORWARD -i docker...in?).
7月 02 16:10:38 localhost.localdomain firewalld[677]: WARNING: COMMAND_FAILED: '/usr/sbin/iptables -w10 -D FORWARD -i docker...in?).
7月 02 16:10:44 localhost.localdomain firewalld[677]: WARNING: COMMAND_FAILED: '/usr/sbin/iptables -w10 -D FORWARD -i br-21d...in?).
7月 03 02:14:52 localhost.localdomain firewalld[677]: WARNING: COMMAND_FAILED: '/usr/sbin/iptables -w10 -D FORWARD -i br-7ca...in?).
7月 03 07:04:14 localhost.localdomain firewalld[677]: WARNING: COMMAND_FAILED: '/usr/sbin/iptables -w10 -D FORWARD -i docker...in?).
7月 03 07:04:14 localhost.localdomain firewalld[677]: WARNING: COMMAND_FAILED: '/usr/sbin/iptables -w10 -t filter -nL DOCKER...name.
7月 03 07:04:14 localhost.localdomain firewalld[677]: WARNING: COMMAND_FAILED: '/usr/sbin/iptables -w10 -t filter -nL DOCKER...name.
Hint: Some lines were ellipsized, use -l to show in full.
#停止防火墙
[root@localhost ~]# systemctl stop firewalld.service
#禁用防火墙
[root@manager ~]# systemctl disable firewalld.service
Removed symlink /etc/systemd/system/multi-user.target.wants/firewalld.service.
Removed symlink /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service.
#重试
[root@localhost ~]# docker swarm join --token SWMTKN-1-1fmah57r3nzokjcnl1rtbd4bb49xggxy45ovw9vacpg9rk0axc-45ygfd04r2qyq80s5or9a8t5j 192.168.6.17:2377
This node joined a swarm as a worker.
#成功
如果拿不到可用的命令可以在manager节点执行下方拿到加入命令
[root@localhost ~]# docker swarm join-token worker
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-1fmah57r3nzokjcnl1rtbd4bb49xggxy45ovw9vacpg9rk0axc-45ygfd04r2qyq80s5or9a8t5j 192.168.6.17:2377
#和上方一致的有没有
5.第二个工作节点加入到现有swarm
在worker2上执行
#提示证书过期
[root@localhost ~]# docker swarm join --token SWMTKN-1-1fmah57r3nzokjcnl1rtbd4bb49xggxy45ovw9vacpg9rk0axc-45ygfd04r2qyq80s5or9a8t5j 192.168.6.17:2377
Error response from daemon: error while validating Root CA Certificate: x509: certificate has expired or is not yet valid
#解决方案https://www.cnblogs.com/cuijinlong/p/13094016.html
#集群的时间不一致
#话不多说 工具-发送指令到所有窗口
[root@localhost ~]# yum -y install ntp ntpdate
[root@localhost ~]# ntpdate cn.pool.ntp.org
[root@localhost ~]# docker swarm join --token SWMTKN-1-1fmah57r3nzokjcnl1rtbd4bb49xggxy45ovw9vacpg9rk0axc-45ygfd04r2qyq80s5or9a8t5j 192.168.6.17:2377
This node joined a swarm as a worker.
6.在manager上面查看swarm管理的节点
[root@manager ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
z8wbqg138k7g3jte6wt8boul5 * manager Ready Active Leader 20.10.7
ks514rou8kc8rftgs8lqnjsl5 worker1 Ready Active 20.10.7
yq6n5395iakfznz803gobc6de worker2 Ready Active 20.10.7
部署服务到swarm
1.登录manager节点
2.创建服务
[root@manager ~]# docker service create --replicas 1 --name helloworld alpine ping docker.com
ckj2m9tili4h3b95xabl8wg7q
overall progress: 1 out of 1 tasks
1/1: running [==================================================>]
verify: Service converged
- 该
docker service create命令创建服务。 - 该
--name标志名称的服务helloworld。 - 该
--replicas标志指定 1 个正在运行的实例的所需状态。 - 这些参数
alpine ping docker.com将服务定义为执行命令的 Alpine Linux 容器ping docker.com。
3.查看服务列表
[root@manager ~]# docker service ls
ID NAME MODE REPLICAS IMAGE PORTS
ckj2m9tili4h helloworld replicated 1/1 alpine:latest
检查swarm上面的服务
1.连接到manager节点
2.查看有关helloworld服务的详细信息
[root@localhost ~]# docker service inspect --pretty helloworld
[root@manager ~]# docker service inspect --pretty helloworld
ID: ckj2m9tili4h3b95xabl8wg7q
Name: helloworld
Service Mode: Replicated
Replicas: 1
Placement:
UpdateConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Update order: stop-first
RollbackConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Rollback order: stop-first
ContainerSpec:
Image: alpine:latest@sha256:234cb88d3020898631af0ccbbcca9a66ae7306ecd30c9720690858c1b007d2a0
Args: ping docker.com
Init: false
Resources:
Endpoint Mode: vip
要以json形式返回不指定
--pretty
[root@manager ~]# docker service inspect helloworld
[
{
"ID": "ckj2m9tili4h3b95xabl8wg7q",
"Version": {
"Index": 75
},
"CreatedAt": "2021-07-07T08:22:33.73547684Z",
"UpdatedAt": "2021-07-07T08:22:33.73547684Z",
"Spec": {
"Name": "helloworld",
"Labels": {},
"TaskTemplate": {
"ContainerSpec": {
"Image": "alpine:latest@sha256:234cb88d3020898631af0ccbbcca9a66ae7306ecd30c9720690858c1b007d2a0",
"Args": [
"ping",
"docker.com"
],
"Init": false,
"StopGracePeriod": 10000000000,
"DNSConfig": {},
"Isolation": "default"
},
"Resources": {
"Limits": {},
"Reservations": {}
},
"RestartPolicy": {
"Condition": "any",
"Delay": 5000000000,
"MaxAttempts": 0
},
"Placement": {
"Platforms": [
{
"Architecture": "amd64",
"OS": "linux"
},
{
"OS": "linux"
},
{
"OS": "linux"
},
{
"Architecture": "arm64",
"OS": "linux"
},
{
"Architecture": "386",
"OS": "linux"
},
{
"Architecture": "ppc64le",
"OS": "linux"
},
{
"Architecture": "s390x",
"OS": "linux"
}
]
},
"ForceUpdate": 0,
"Runtime": "container"
},
"Mode": {
"Replicated": {
"Replicas": 1
}
},
"UpdateConfig": {
"Parallelism": 1,
"FailureAction": "pause",
"Monitor": 5000000000,
"MaxFailureRatio": 0,
"Order": "stop-first"
},
"RollbackConfig": {
"Parallelism": 1,
"FailureAction": "pause",
"Monitor": 5000000000,
"MaxFailureRatio": 0,
"Order": "stop-first"
},
"EndpointSpec": {
"Mode": "vip"
}
},
"Endpoint": {
"Spec": {}
}
}
]
3.查看哪些节点正在运行服务,分配到了manager节点上运行了容器
[root@manager ~]# docker service ps helloworld
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
n4b7dyamkas5 helloworld.1 alpine:latest manager Running Running about a minute ago
如果遇到下面的问题:所有的node都是localhost.localdomain,就需要将主机改成不重名
[root@localhost ~]# docker service ps helloworld
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
sfzi4r92auze helloworld.1 alpine:latest localhost.localdomain Running Running 6 minutes ago
bhb3kz9f2lt1 \_ helloworld.1 alpine:latest localhost.localdomain Shutdown Failed 6 minutes ago "task: non-zero exit (1)"
jdcsmk33sa59 \_ helloworld.1 alpine:latest localhost.localdomain Shutdown Failed 6 minutes ago "task: non-zero exit (1)"
vve2xgz8nj0h \_ helloworld.1 alpine:latest localhost.localdomain Shutdown Failed 6 minutes ago "task: non-zero exit (1)"
扩展服务
1.进入manager节点
2.运行命令 docker service scale <SERVICE-ID>=<NUMBER-OF-TASKS>
#运行五个任务
[root@manager ~]# docker service scale helloworld=5
helloworld scaled to 5
overall progress: 5 out of 5 tasks
1/5: running [==================================================>]
2/5: running [==================================================>]
3/5: running [==================================================>]
4/5: running [==================================================>]
5/5: running [==================================================>]
verify: Service converged
3.查看更新的任务列表
[root@manager ~]# docker service ps helloworld
qdzivynk5i7v helloworld.1 alpine:latest worker2 Running Running 3 minutes ago
qv0qkgart8bv helloworld.2 alpine:latest worker1 Running Running 2 minutes ago
s6aokr8eoa9p helloworld.3 alpine:latest worker2 Running Running 2 minutes ago
tejhd5vcc23d helloworld.4 alpine:latest worker1 Running Running 2 minutes ago
mfty49d88usq helloworld.5 alpine:latest worker1 Running Running 2 minutes ago
4.运行docker ps查看节点上运行的容器
#worker1上面
[root@worker1 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
ad3dcf788e58 alpine:latest "ping docker.com" About a minute ago Up About a minute helloworld.2.qv0qkgart8bvz4n7qprkrubyu
6fc025ae0984 alpine:latest "ping docker.com" About a minute ago Up About a minute helloworld.5.mfty49d88usqjtch6st10rb23
50ba7f3937fb alpine:latest "ping docker.com" 2 minutes ago Up 2 minutes helloworld.4.tejhd5vcc23d44730cw9o96ra
#worker2上面
[root@worker2 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
664ad666c6c9 alpine:latest "ping docker.com" 2 minutes ago Up 2 minutes helloworld.3.s6aokr8eoa9pcr0nonlfnq44r
75035231260f alpine:latest "ping docker.com" 2 minutes ago Up 2 minutes helloworld.1.qdzivynk5i7v4ghd85r6gooad
删除在swarm上运行的服务
1.进入manager节点
2.删除helloworld
[root@manager ~]# docker service rm helloworld
helloworld
3.验证是否删除
[root@manager ~]# docker service inspect helloworld
[]
Status: Error: no such service: helloworld, Code: 1
4.也可以用docker ps来验证是否删除任务,任务容器也需要几秒来清理
滚动更新
1.进入manager节点
2.将您的 Redis 标签部署到 swarm 并以 10 秒的更新延迟配置 swarm,请注意,以下示例显示了不是最新版的 Redis :
[root@manager ~]# docker service create --replicas 3 --name redis --update-delay 10s redis:3.0.6
yiq9d3bqq3r1snqsemucp2j7d
overall progress: 3 out of 3 tasks
1/3: running [==================================================>]
2/3: running [==================================================>]
3/3: running [==================================================>]
verify: Service converged
您可以在服务部署时配置滚动更新策略。
该--update-delay标志配置更新服务任务或任务集之间的时间延迟。您可以将时间描述T为秒数Ts、分钟数Tm或小时数的组合Th。So 10m30s表示 10 分 30 秒的延迟。
默认情况下,调度程序一次更新 1 个任务。您可以通过该 --update-parallelism标志来配置调度程序同时更新的最大服务任务数。
默认情况下,当对单个任务的更新返回 状态时 RUNNING,调度程序会调度另一个任务进行更新,直到所有任务都更新为止。如果在更新期间的任何时间有任务返回FAILED,调度程序就会暂停更新。您可以使用或 的--update-failure-action标志来控制行为 。docker service create``docker service update
3.检查redis服务
[root@manager ~]# docker service inspect --pretty redis
ID: yiq9d3bqq3r1snqsemucp2j7d
Name: redis
Service Mode: Replicated
Replicas: 3
Placement:
UpdateConfig:
Parallelism: 1
Delay: 10s
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Update order: stop-first
RollbackConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Rollback order: stop-first
ContainerSpec:
Image: redis:3.0.6@sha256:6a692a76c2081888b589e26e6ec835743119fe453d67ecf03df7de5b73d69842
Init: false
Resources:
Endpoint Mode: vip
4.更新redis manager根据UpdateConfig 策略将更新应用到节点
[root@manager ~]# docker service update --image redis:3.0.7 redis
redis
overall progress: 3 out of 3 tasks
1/3: running [==================================================>]
2/3: running [==================================================>]
3/3: running [==================================================>]
verify: Service converged
5.查看
[root@manager ~]# docker service inspect --pretty redis
ID: yiq9d3bqq3r1snqsemucp2j7d
Name: redis
Service Mode: Replicated
Replicas: 3
UpdateStatus:
State: completed
Started: 2 minutes ago
Completed: About a minute ago
Message: update completed
Placement:
UpdateConfig:
Parallelism: 1
Delay: 10s
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Update order: stop-first
RollbackConfig:
Parallelism: 1
On failure: pause
Monitoring Period: 5s
Max failure ratio: 0
Rollback order: stop-first
ContainerSpec:
Image: redis:3.0.7@sha256:730b765df9fe96af414da64a2b67f3a5f70b8fd13a31e5096fee4807ed802e20
Init: false
Resources:
Endpoint Mode: vip
如果之间运行失败则可以再次运行docker service update redis
6.查看滚动更新
[root@manager ~]# docker service ps redis
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
q3cgqstjnqid redis.1 redis:3.0.7 manager Running Running 4 minutes ago
n8h1ahxfase0 \_ redis.1 redis:3.0.6 manager Shutdown Shutdown 5 minutes ago
x68327384syo redis.2 redis:3.0.7 worker1 Running Running 4 minutes ago
wh41hh6zlvfg \_ redis.2 redis:3.0.6 worker1 Shutdown Shutdown 4 minutes ago
3k84rkikemw4 redis.3 redis:3.0.7 worker2 Running Running 4 minutes ago
569rcx2q09ar \_ redis.3 redis:3.0.6 worker2 Shutdown Shutdown 4 minutes ago
删除swarm上的一个节点
在本教程的前面步骤中,所有节点都以ACTIVE 可用性运行。swarm manager 可以将任务分配给任何ACTIVE节点,所以到目前为止所有节点都可以接收任务。
有时,例如计划维护时间,您需要将节点设置为DRAIN 可用性。DRAIN可用性阻止节点从群管理器接收新任务。这也意味着管理器停止在节点上运行的任务并在具有ACTIVE可用性的节点上启动副本任务。
重要提示:一个节点设置为
DRAIN不删除从该节点独立的容器,如那些具有创建docker run,docker-compose up或泊坞窗引擎API。节点的状态,包括DRAIN,仅影响节点调度群服务工作负载的能力。
1.连接manager
2.验证所有节点是否可用
[root@manager ~]# docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION
z8wbqg138k7g3jte6wt8boul5 * manager Ready Active Leader 20.10.7
ks514rou8kc8rftgs8lqnjsl5 worker1 Ready Active 20.10.7
x5j7tw8i2lxz1dfuoaaokt8lr worker2 Down Active 20.10.7
yq6n5395iakfznz803gobc6de worker2 Ready Active 20.10.7
3.滚动更新启动redis3.0.6服务
[root@manager ~]# docker service update --image redis:3.0.6 redis
redis
overall progress: 3 out of 3 tasks
1/3: running [==================================================>]
2/3: running [==================================================>]
3/3: running [==================================================>]
verify: Service converged
4.查看任务运行情况
[root@manager ~]# docker service ps redis
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
wsse85zkli03 redis.1 redis:3.0.6 manager Running Running 50 seconds ago
q3cgqstjnqid \_ redis.1 redis:3.0.7 manager Shutdown Shutdown 50 seconds ago
n8h1ahxfase0 \_ redis.1 redis:3.0.6 manager Shutdown Shutdown 25 minutes ago
k0s6vk4a46wp redis.2 redis:3.0.6 worker1 Running Running 38 seconds ago
x68327384syo \_ redis.2 redis:3.0.7 worker1 Shutdown Shutdown 38 seconds ago
wh41hh6zlvfg \_ redis.2 redis:3.0.6 worker1 Shutdown Shutdown 24 minutes ago
bqaxsrynyv2a redis.3 redis:3.0.6 worker2 Running Running about a minute ago
3k84rkikemw4 \_ redis.3 redis:3.0.7 worker2 Shutdown Shutdown about a minute ago
569rcx2q09ar \_ redis.3 redis:3.0.6 worker2 Shutdown Shutdown 24 minutes ago
5 运行docker node update --availability drain 以耗尽分配了任务的节点:
[root@manager ~]# docker node update --availability drain worker1
worker1
6.检查节点以检查其可用性 发现节点
[root@manager ~]# docker node inspect --pretty worker1
ID: ks514rou8kc8rftgs8lqnjsl5
Hostname: worker1
Joined at: 2021-07-07 08:34:15.629765068 +0000 utc
Status:
State: Ready
Availability: Drain
Address: 192.168.6.18
#省略
排出的节点显示Drain为AVAILABILITY
7.运行docker service ps redis以查看 swarm manager 如何更新服务的任务分配redis:
# 查看k0s6vk4a46wp发现停止了重新启动了一个3cec1yv93x0i分配到worker2上面
[root@manager ~]# docker service ps redis
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
wsse85zkli03 redis.1 redis:3.0.6 manager Running Running 6 minutes ago
q3cgqstjnqid \_ redis.1 redis:3.0.7 manager Shutdown Shutdown 6 minutes ago
n8h1ahxfase0 \_ redis.1 redis:3.0.6 manager Shutdown Shutdown 31 minutes ago
3cec1yv93x0i redis.2 redis:3.0.6 worker2 Running Running 3 minutes ago
k0s6vk4a46wp \_ redis.2 redis:3.0.6 worker1 Shutdown Shutdown 3 minutes ago
x68327384syo \_ redis.2 redis:3.0.7 worker1 Shutdown Shutdown 6 minutes ago
wh41hh6zlvfg \_ redis.2 redis:3.0.6 worker1 Shutdown Shutdown 30 minutes ago
bqaxsrynyv2a redis.3 redis:3.0.6 worker2 Running Running 7 minutes ago
3k84rkikemw4 \_ redis.3 redis:3.0.7 worker2 Shutdown Shutdown 7 minutes ago
569rcx2q09ar \_ redis.3 redis:3.0.6 worker2 Shutdown Shutdown 30 minutes ago
manager通过在具有Drain可用性的节点上结束任务并在具有可用性的节点上创建新任务来维持所需的状态Active
8.运行 docker node update --availability active 以将耗尽的节点返回到活动状态:
[root@manager ~]# docker node update --availability active worker1
worker1
9.查看更新状态
[root@manager ~]# docker node inspect --pretty worker1
ID: ks514rou8kc8rftgs8lqnjsl5
Hostname: worker1
Joined at: 2021-07-07 08:34:15.629765068 +0000 utc
Status:
State: Ready
Availability: Active
Address: 192.168.6.18
#省略
当您将节点设置回Active可用性时,它可以接收新任务:
- 在服务更新期间扩大规模
- 在滚动更新期间
- 当您将另一个节点设置为
Drain可用性时 - 当另一个活动节点上的任务失败时
设置swarm路由网络
Docker swarm 模式可以很容易地为服务发布端口,使其可用于 swarm 之外的资源。所有节点都参与一个入口路由网格。路由网格使 swarm 中的每个节点都能接受在已发布端口上为在 swarm 中运行的任何服务的连接,即使节点上没有运行任何任务。路由网格将所有传入请求路由到可用节点上的已发布端口到活动容器。
要在 swarm 中使用入口网络,您需要在启用 swarm 模式之前在 swarm 节点之间打开以下端口:
7946用于容器网络发现的端口TCP/UDP。4789容器入口网络的端口UDP。
您还必须打开 swarm 节点和需要访问端口的任何外部资源(例如外部负载均衡器)之间的已发布端口。
发布一个服务的端口
--publish创建服务时使用该标志发布端口。target 用于指定容器内部的端口,published用于指定要绑定到路由网格上的端口。如果离开published 端口,每个服务任务都会绑定一个随机的高编号端口。您需要检查任务以确定端口。
#旧版写法
docker service create \
--name <SERVICE-NAME> \
--publish published=<PUBLISHED-PORT>,target=<CONTAINER-PORT> \
<IMAGE>
#新版写法
docker service create \
--name <SERVICE-NAME> \
-p 8080:80 \
<IMAGE>
如下 以下命令将 nginx 容器中的 80 端口发布到 swarm 中任何节点的 8080 端口:
[root@manager ~]# docker service create --name my-web -p 8080:80 --replicas 2 nginx
0qchr205re1pek40mmmyj83mj
overall progress: 2 out of 2 tasks
1/2: running [==================================================>]
2/2: running [==================================================>]
verify: Service converged
当您访问任何节点上的 8080 端口时,Docker 会将您的请求路由到活动容器。在 swarm 节点本身,端口 8080 可能实际上没有被绑定,但路由网格知道如何路由流量并防止发生任何端口冲突。
路由网格在已发布的端口上侦听分配给节点的任何 IP 地址。对于外部可路由的 IP 地址,该端口可从主机外部使用。对于所有其他 IP 地址,只能从主机内部访问。
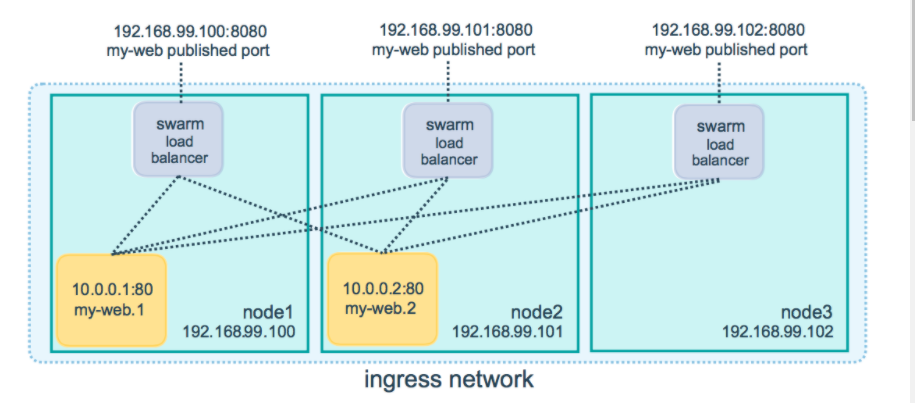
可以为现有服务发布端口
docker service update \
--publish-add published=<PUBLISHED-PORT>,target=<CONTAINER-PORT> \
<SERVICE>
[root@manager ~]# docker service update --publish-add published=80,target=8080 my-web
my-web
overall progress: 2 out of 2 tasks
1/2: running [==================================================>]
2/2: running [==================================================>]
verify: Service converged
可以使用 docker service inspect 来查看服务的已发布端口
[root@manager ~]# docker service inspect --format="{{json .Endpoint.Spec.Ports}}" my-web
[{"Protocol":"tcp","TargetPort":80,"PublishedPort":8080,"PublishMode":"ingress"}]
只为 TCP 或 UDP 发布端口
默认情况下,当您发布端口时,它是一个 TCP 端口。您可以专门发布 UDP 端口来代替 TCP 端口或作为其补充。当您同时发布 TCP 和 UDP 端口时,如果省略协议说明符,则该端口将作为 TCP 端口发布。如果您使用较长的语法(推荐),请将protocol键设置为tcp或udp
仅TCP
长语法
root@manager ~]# docker service rm my-web
my-web
[root@manager ~]# docker service create --name my-web --publish published=8080,target=80 nginx
locxlpmx6yhzyv3us7bgqgahh
overall progress: 1 out of 1 tasks
1/1: running [==================================================>]
verify: Service converged
短语法
docker service create --name my-web -p 8080:80 nginx
TCP 和 UDP
root@manager ~]# docker service rm my-web
my-web
[root@manager ~]# docker service create --name my-web -p 8080:80 -p 8080:80/udp nginx
bzah2q5mdy55mkiwwciql2ksx
overall progress: 1 out of 1 tasks
1/1: running [==================================================>]
verify: Service converged
[root@manager ~]# docker service inspect --format="{{json .Endpoint.Spec.Ports}}" my-web
[{"Protocol":"tcp","TargetPort":80,"PublishedPort":8080,"PublishMode":"ingress"},{"Protocol":"udp","TargetPort":80,"PublishedPort":8080,"PublishMode":"ingress"}]
仅UDP
[root@manager ~]# docker service rm my-web
my-web
[root@manager ~]# docker service create --name my-web -p 8080:80/udp nginx
ih14v3j43nn1s826d18pfy3j8
overall progress: 1 out of 1 tasks
1/1: running [==================================================>]
verify: Service converged
[root@manager ~]# docker service inspect --format="{{json .Endpoint.Spec.Ports}}" my-web
[{"Protocol":"udp","TargetPort":80,"PublishedPort":8080,"PublishMode":"ingress"}]
总结
ocker swarm init用于创建一个新的 Swarm。执行该命令的节点会成为第一个管理节点,并且会切换到 Swarm 模式。docker swarm join-token用于查询加入管理节点和工作节点到现有 Swarm 时所使用的命令和 Token。 要获取新增管理节点的命令,请执行 docker swarm join-token manager 命令; 要获取新增工作节点的命令,请执行 docker swarm join-token worker 命令。docker node ls用于列出 Swarm 中的所有节点及相关信息,包括哪些是管理节点、哪个是主管理节点。docker service create用于创建一个新服务。docker service ls用于列出 Swarm 中运行的服务,以及诸如服务状态、服务副本等基本信息。docker service ps <service>该命令会给出更多关于某个服务副本的信息docker service inspect用于获取关于服务的详尽信息。附加 --pretty 参数可限制仅显示重要信息。docker service scale用于对服务副本个数进行增减。docker service update用于对运行中的服务的属性进行变更。docker service logs用于查看服务的日志。docker service rm用于从 Swarm 中删除某服务。该命令会在不做确认的情况下删除服务的所有副本,所以使用时应保持警惕。
集群的工作原理
节点如何工作
swarm 由一个或多个节点组成 ,有两种类型的节点:manager和workers
manager
管理节点处理集群管理任务:
- 维护集群状态
- 调度服务
- 为swarm模式HTTP API 端点提供服务
使用Raft实现 ,manager管理整个swarm及其上运行的所有服务的一致内部状态, 出于测试目的,可以使用单个管理器运行 swarm。如果单管理器群中的管理器出现故障,您的服务会继续运行,但您需要创建一个新集群来恢复
为了利用 swarm 模式的容错特性,Docker 建议您根据组织的高可用性要求实现奇数个节点。当您有多个管理器时,您可以在不停机的情况下从管理器节点的故障中恢复。
- 三个管理器的群体最多可以容忍一个管理器的损失。
- 一个五管理器群可以容忍最大同时丢失两个管理器节点。
- 一个
N管理器集群最多可以容忍管理器的丢失(N-1)/2。 - Docker 建议一个集群最多有七个管理器节点。
注意:添加更多管理器并不意味着增加可扩展性或更高的性能。一般来说,情况正好相反。
简而言之
manager就是使用Raft一致性算法实现,管理整个集群上的所有服务,也可以在单机运行,管理节点数需要奇数个,为了就是投票的时候不至于打平,管理节点不是越多越好
workers
worker节点也是 Docker 的实例,其唯一目的是执行容器。Worker 节点不参与 Raft 分布式状态,不做出调度决策,也不为 swarm 模式 HTTP API 提供服务。
您可以创建一个由一个管理器节点组成的集群,但是如果没有至少一个管理器节点,您就不能拥有一个工作节点。默认情况下,所有manager也是worker。在单个管理器节点集群中,您可以运行类似docker service create的命令,调度程序将所有任务放在本地引擎上。
为了防止调度程序将任务放置在多节点群中的管理器节点上,请将管理器节点的可用性设置为Drain。调度器在Drainmode 中优雅地停止节点上的任务并调度Active节点上的任务 。调度程序不会将新任务分配给具有Drain 可用性的节点。
请参阅docker node update 命令行参考以了解如何更改节点可用性。
简而言之
worker节点只运行docker实例,不参与节点的管理和投票
角色
您可以通过运行将工作节点提升为管理器docker node promote。例如,当您将管理节点脱机进行维护时,您可能希望提升工作节点。请参阅节点提升。
您还可以将管理节点降级为工作节点。请参阅 节点降级。
简而言之
当manager节点挂掉的时候,workder节点可以升级成为manager
服务如何运行
要在 Docker 处于 swarm 模式时部署应用程序镜像,您需要创建一个服务。通常,服务是某个较大应用程序上下文中微服务的镜像。服务的示例可能包括 HTTP 服务器、数据库或您希望在分布式环境中运行的任何其他类型的可执行程序。
创建服务时,您需要指定要使用的容器镜像以及要在运行的容器内执行的命令。您还可以为服务定义选项,包括:
- 集群在集群外部提供服务的端口
- 服务连接到swarm中其他服务的覆盖网络
- CPU 和内存限制和预留
- 滚动更新策略
- 要在 swarm 中运行的镜像副本的数量
简而言之
使用swarm部署镜像,需要创建一个服务(微服务镜像、http服务器、数据库或其他可执行程序),创建服务的识货需要指定要是用容器的镜像和运行容器的命令,其他的需要制定如端口、网络、cpu限制、滚动更新策略、副本数量等
服务、任务和容器
当您将服务部署到 swarm 时,swarm manager接受您的服务定义作为服务所需的状态。然后它将集群中节点上的服务作为一个或多个副本任务进行调度。任务在swarm中的节点上彼此独立运行。
例如,假设您要在 HTTP 侦听器的三个实例之间进行负载均衡。下图显示了监听三个副本的 HTTP 侦听器服务。监听服务对应的的三个实例中的每一个都是 swarm 中的一个任务。
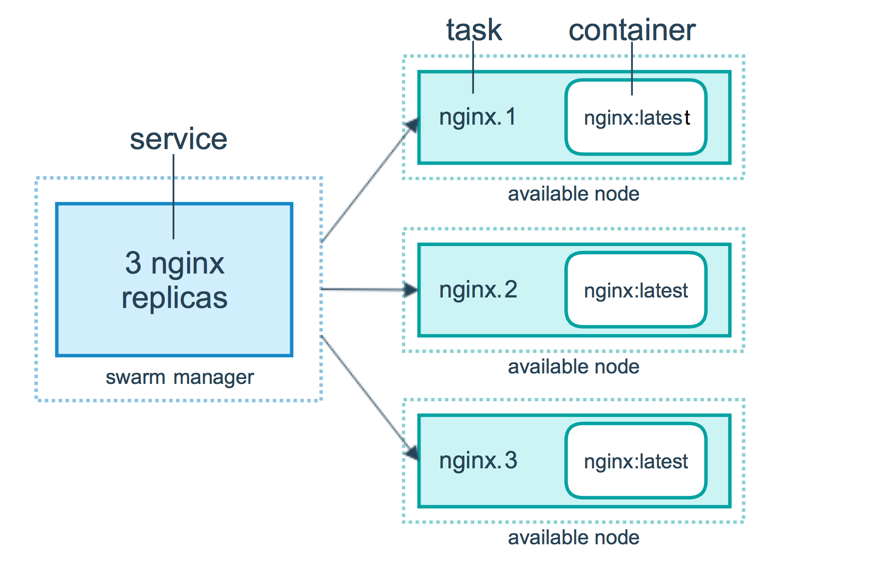
容器是一个孤立的进程。在swarm模式模型中,每个任务只调用一个容器。任务类似于调度程序放置容器的“槽”。一旦容器处于活动状态,调度程序就会识别出任务处于运行状态。如果容器未通过健康检查或终止,则任务终止
简而言之
当服务部署到swarm时,通过定义的配置作为服务运行的标准,分发任务部署到集群中的节点上,并且监控其运行的状态,进行下线和调度
任务和日程安排
任务是集群内调度的原子单元。当您通过创建或更新服务声明所需的服务状态时,编排器通过调度任务来实现所需的状态。例如,您定义了一个服务,该服务指示协调器始终保持 HTTP 去侦听三个实例运行。协调器通过创建三个任务来响应。每个任务都是一个槽,调度程序通过生成一个容器来填充它。容器是任务的实例化。如果 HTTP 侦听任务随后未能通过其健康检查或崩溃,那么协调器会创建一个新的副本任务来生成新的容器。
任务是一种单向机制。它通过一系列状态单调前进:分配、准备、运行等。如果任务失败,协调器将删除任务及其容器,然后根据服务指定的所需状态创建一个新任务来替换它。
Docker swarm 模式的底层逻辑是一个通用的调度器和编排器。服务和任务抽象本身不知道它们实现的容器。假设您可以实现其他类型的任务,例如虚拟机任务或非容器化进程任务。调度器和协调器不知道任务的类型。但是,当前版本的 Docker 仅支持容器任务。
下图显示了 swarm 模式如何接受服务创建请求并将任务调度到工作节点。
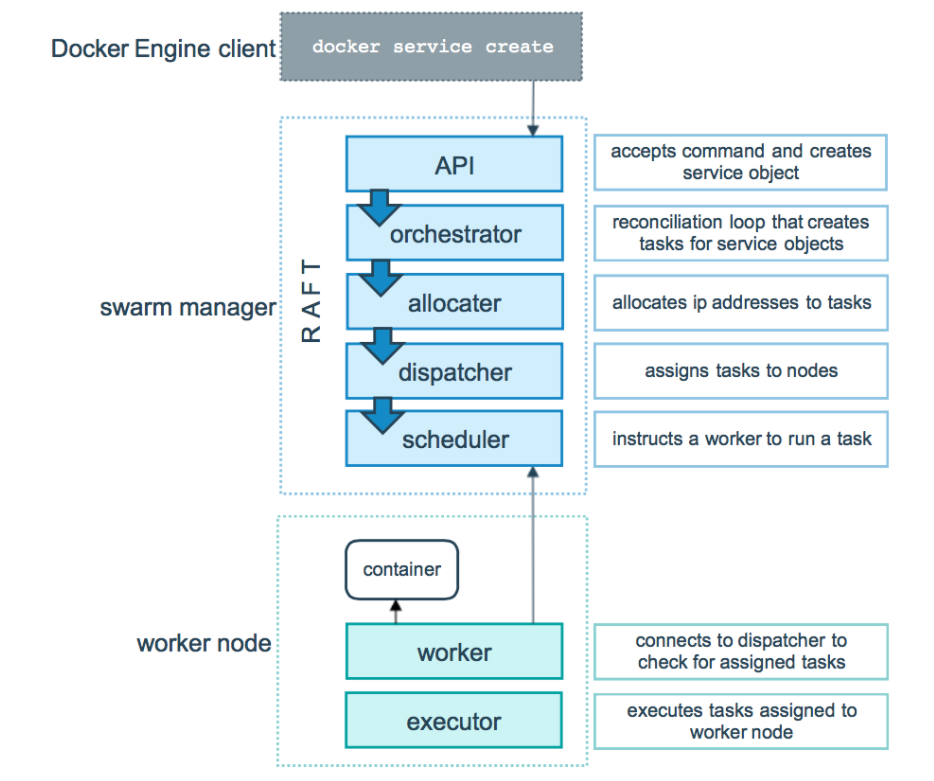
简而言之
任务是集群内调度的最小单元,swarm包含调度器和编排器,服务和任务抽象本身不知道它们实现的容器,不过当前版本仅支持容器任务,任务是一种单向机制,它可以通过一系列状态运行,如果任务失败,则协调器则删除任务及其容器,然后根据服务指定所需状态创建新的任务替代
待定服务
服务可以以这样的方式配置,即当前集群中的任何节点都不能运行其任务。在这种情况下,服务保持在状态pending。以下是一些服务何时可能保持在 state 中的示例pending。
注意:如果您的唯一目的是阻止部署服务,请将服务扩展到 0,而不是尝试以保留在
pending.
- 如果所有节点都暂停或耗尽,并且您创建了一个服务,则该服务将处于挂起状态,直到一个节点可用为止。实际上,第一个可用的节点会获得所有任务,因此在生产环境中这不是一件好事。
- 您可以为服务保留特定数量的内存。如果 swarm 中没有节点具有所需的内存量,则服务将保持挂起状态,直到有一个可以运行其任务的节点可用。如果您指定一个非常大的值,例如 500 GB,则任务将永远处于挂起状态,除非您确实有一个可以满足它的节点。
- 您可以对服务施加放置约束,并且可能无法在给定时间遵守这些约束。
此行为说明您的任务的要求和配置与swarm的当前状态没有紧密联系。作为 swarm 的管理员,您声明了您的 swarm 所需的状态,并且管理器与 swarm 中的节点一起创建该状态。您不需要对 swarm 上的任务进行微观管理。
简而言之
待定服务是让服务保持在pending的状态,当前集群任何节点不能运行该任务,以上行为导致pending的状态说明现在任务的要求和配置和当前集群的状态不一致
复制和全局服务
有两种类型的服务部署,复制的和全局的。
对于复制服务,您可以指定要运行的相同任务的数量。例如,您决定部署具有三个副本的 HTTP 服务,每个副本提供相同的内容。
全局服务是在每个节点上运行一个任务的服务。没有预先指定的任务数量。每次向 swarm 添加节点时,协调器都会创建一个任务,调度器将任务分配给新节点。全局服务的良好候选者是监视代理、防病毒扫描程序或您希望在 swarm 中的每个节点上运行的其他类型的容器。
下图显示了黄色的三服务副本和灰色的全局服务。
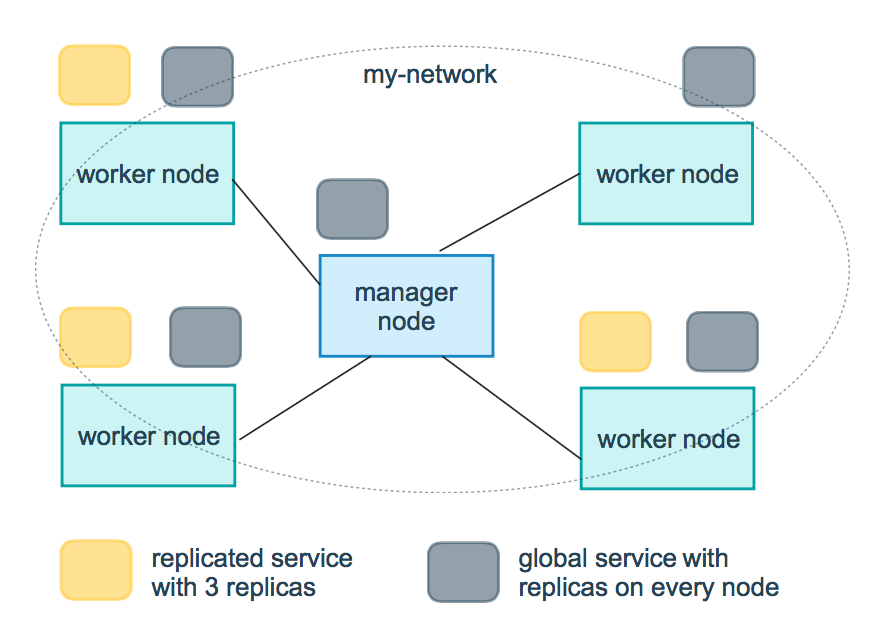
简而言之
复制服服务就是制定运行任务的数量,全局服务是在没个节点上只运行一个任务
使用公钥基础设施 (PKI) 管理群安全
Docker 内置的群模式公钥基础设施 (PKI) 系统使安全部署容器编排系统变得简单。群中的节点使用相互传输层安全 (TLS) 来验证、授权和加密与群中其他节点的通信。
当您通过运行创建 swarm 时docker swarm init,Docker 将自己指定为管理器节点。默认情况下,管理器节点会生成一个新的根证书颁发机构 (CA) 以及一个密钥对,用于保护与加入群的其他节点的通信。如果您愿意,可以使用docker swarm init命令的--external-ca标志 指定您自己的外部生成的根 CA。
当您将其他节点加入群时,管理器节点还会生成两个令牌以供使用:一个工作令牌和一个管理器令牌。每个令牌包括根 CA 证书的摘要和随机生成的机密。当节点加入群时,加入节点使用摘要来验证来自远程管理器的根 CA 证书。远程管理器使用秘密来确保加入的节点是一个被批准的节点。
每次有新节点加入群时,管理器都会向该节点颁发证书。证书包含随机生成的节点 ID,用于标识证书通用名 (CN) 下的节点和组织单位 (OU) 下的角色。节点 ID 在当前群中节点的生命周期内用作加密安全节点身份。
下图说明了管理节点和工作节点如何使用至少 TLS 1.2 加密通信。
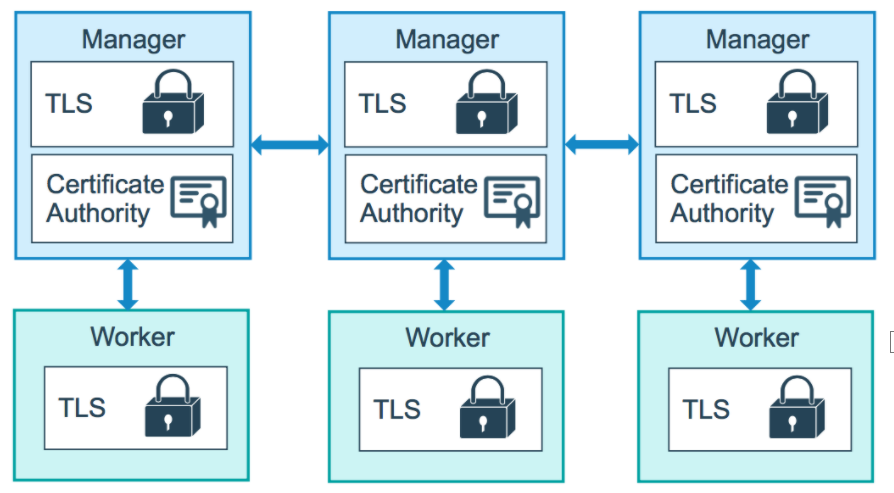
默认情况下,swarm 中的每个节点每三个月更新一次证书。您可以通过运行docker swarm update --cert-expiry 命令来配置此时间间隔。最小旋转值为 1 小时
简而言之
Docker内置的集群模式公钥基础设施系统,管理节点会生成根证书颁发机构一级一个密钥对,加入集群时,管理节点会生成worker令牌和manager令牌,令牌包含CA证书摘要和随机生成的秘钥,摘要用来验证CA证书,秘钥用来确保加入节点是一个被批准的节点
CA证书
如果集群 CA 密钥或管理器节点遭到破坏,您可以轮换 swarm 根 CA,这样所有节点都不再信任由旧根 CA 签署的证书。
运行docker swarm ca --rotate以生成新的 CA 证书和密钥。如果您愿意,您可以传递--ca-cert和--external-ca标志来指定根证书并使用集群外部的根 CA。或者,您可以传递--ca-cert和--ca-key标志来指定您希望 swarm 使用的确切证书和密钥。
当您发出docker swarm ca --rotate命令时,以下事情会依次发生:
-
Docker 生成一个交叉签名的证书。这意味着新的根 CA 证书的一个版本是用旧的根 CA 证书签名的。此交叉签名证书用作所有新节点证书的中间证书。这确保了仍然信任旧根 CA 的节点仍然可以验证由新 CA 签署的证书。
-
Docker 还告诉所有节点立即更新它们的 TLS 证书。此过程可能需要几分钟,具体取决于 swarm 中的节点数量。
-
在 swarm 中的每个节点都有新 CA 签署的新 TLS 证书后,Docker 会忘记旧的 CA 证书和密钥材料,并告诉所有节点只信任新的 CA 证书。
这也会导致群的加入令牌发生变化。以前的加入令牌不再有效。
从现在开始,所有新颁发的节点证书都使用新的根 CA 签名,并且不包含任何中间证书。
简而言之
CA证书需要更换的时候,可以通过docker swarm ca --rotate命令来更新证书,具体过程是,1生成交叉证书用于兼容旧版本CA证书,2.更新没个节点的TLS证书,3.删除就旧CA证书和秘钥,指定新的CA证书
Swarm任务状态
Docker 允许您创建可以启动任务的服务。服务是对期望状态的描述,而任务完成这项工作。按以下顺序在 swarm 节点上安排工作:
- 使用
docker service create. - 请求会发送到 Docker 管理器节点。
- Docker 管理器节点安排服务在特定节点上运行。
- 每个服务可以启动多个任务。
- 每个任务都有一个生命周期,与美国一样
NEW,PENDING和COMPLETE。
任务是运行一次直到完成的执行单元。当一个任务停止时,它不会再次执行,但一个新任务可能会取而代之。
任务通过多个状态前进,直到它们完成或失败。任务在NEW状态中初始化。任务通过多个状态向前推进,并且其状态不会后退。例如,任务永远不会从 COMPLETE到RUNNING。
任务按以下顺序经历状态:
| 任务状态 | 描述 |
|---|---|
NEW |
任务已初始化。 |
PENDING |
分配了任务的资源。 |
ASSIGNED |
Docker 将任务分配给节点。 |
ACCEPTED |
任务已被工作节点接受。如果工作节点拒绝任务,则状态更改为REJECTED。 |
PREPARING |
Docker 正在准备任务。 |
STARTING |
Docker 正在启动任务。 |
RUNNING |
任务正在执行。 |
COMPLETE |
任务退出时没有错误代码。 |
FAILED |
任务退出并显示错误代码。 |
SHUTDOWN |
Docker 请求关闭任务。 |
REJECTED |
工作节点拒绝了该任务。 |
ORPHANED |
节点停机时间过长。 |
REMOVE |
任务不是终端,但相关的服务已被删除或缩小。 |
运行
docker service ps以获取任务的状态。该CURRENT STATE字段显示任务的状态以及它存在的时间
本文来自博客园,作者:zhao56,转载请注明原文链接:https://www.cnblogs.com/zhao56/p/15001673.html

