

Python爬虫学习1: Requests模块的使用
Requests函数库是学习Python爬虫必备之一, 能够帮助我们方便地爬取. Requests: 让HTTP服务人类. 本文主要参考了其官方文档.
Requests具有完备的中英文文档, 能完全满足当前网络的需求, 它使用了urllib3, 拥有其所有的特性!
Requests安装:
requests目前的版本是v2.11.1, 在WINDOWS上可以通过命令行窗口(运行cmd命令), 利用pip进行自动地安装(很方便):
> pip install requests
Collecting requests
Downloading requests-2.11.1-py2.py3-none-any.whl <514kB>
Installing collected packages: requests
Successfully installed requests-2.11.1
向网站发送请求:requests.get(url)
>>> import requests # 请求豆瓣读书网站点 >>> r = requests.get('https://book.douban.com/') # 返回一个实例,包含了很多的信息 >>> r.status_code # 响应状态码,200表示服务器已成功处理了请求
200
>>> r.headers['content-type'] # 浏览器根据该参数决定对文档进行如何解析,text是文档类型,html则是文档子类型;
'text/html; charset=utf-8'
>>> r.encoding # 所请求网页的编码方式
'utf-8'
>>> r.text # 所请求网页的内容
...
>>> r.cookie # 网页的cookie内容
<RequestsCookieJar[Cookie(version=0, name='bid', value='mGadkt5VXtk', port=None, port_specified=False, domain='.douban.com', domain_specified=True, domain_initial_dot=True, path='/', path_specified=True, secure=False, expires=1508551773, discard=False, comment=None, comment_url=None, rest={}, rfc2109=False)]>
>>> r.headers # 网页的头
{'X-Xss-Protection': '1; mode=block', 'X-DAE-App': 'book', 'X-Content-Type-Options': 'nosniff', 'Content-Encoding': 'gzip', 'Transfer-Encoding': 'chunked', 'Set-Cookie': 'bid=mGadkt5VXtk; Expires=Sat, 21-Oct-17 02:09:33 GMT; Domain=.douban.com; Path=/', 'Expires': 'Sun, 1 Jan 2006 01:00:00 GMT', 'Vary': 'Accept-Encoding', 'Keep-Alive': 'timeout=30', 'X-DAE-Node': 'dis16', 'X-DOUBAN-NEWBID': 'mGadkt5VXtk', 'X-Douban-Mobileapp': '0', 'Connection': 'keep-alive', 'Pragma': 'no-cache', 'Cache-Control': 'must-revalidate, no-cache, private', 'Date': 'Fri, 21 Oct 2016 02:09:33 GMT', 'Strict-Transport-Security': 'max-age=15552000;', 'Server': 'dae', 'Content-Type': 'text/html; charset=utf-8'}
>>> r.url # 实际的网址
u'https://book.douban.com/'
HTTP定义了与服务器进行交互的不同方式, 其中, 最基本的方法有四种: GET, POST, PUT, DELETE; 一个URL对应着一个网络上的资源, 这四种方法就对应着对这个资源的查询, 修改, 增加, 删除四个操作.上面的程序用到的requests.get()来读取指定网页的信息, 而不会对信息就行修改, 相当于是"只读". requests库提供了HTTP所有基本的请求方式, 都是一句话搞定:
1 r = requests.post('https://book.douban.com/') 2 r = requests.put('https://book.douban.com/') 3 r = requests.delete('https://book.douban.com/') 4 r = requests.head('https://book.douban.com/') 5 r = requests.options('https://book.douban.com/')
向URL传递参数:requests.get(url, param=None)
参考附录1可知,一个URL的?后面跟随的是查询(query)字符串, 现在我们手工构建URL, 向URL的后面传递查询字符串. request.get()的第二个参数允许我们使用params关键字参数,以一个字典的形式来提供参数, 比如我们想传递key1=value1,key2=value2到http://httpbin.org/get里面,可以这样做:
>>> param = {'key1':'value1', 'key2':'value2'} # 先生成一个字典
>>> param
{'key2': 'value2', 'key1': 'value1'}
>>> r = requests.get('http://httpbin.org/get', params = param)
>>> r.url
u'http://httpbin.org/get?key2=value2&key1=value1' # 可以看到,参数之间用&隔开,参数名和参数值之间用=隔开
# 还可以将一个列表作为参数值传入
>>> param = {'key1': 'value1', 'key2': ['value2', 'value3']}
>>> param
{'key2': ['value2', 'value3'], 'key1': 'value1'}
>>> r = requests.get('http://httpbin.org/get', params=param)
>>> r.url
u'http://httpbin.org/get?key2=value2&key2=value3&key1=value1'
响应内容:
现在我们可以对服务器响应的内容进行读取, 响应的内容存放在了r.text里面.
>>> r = requests.get('https://www.douban.com/') >>> r.status_code 200>>> r.encoding 'utf-8'
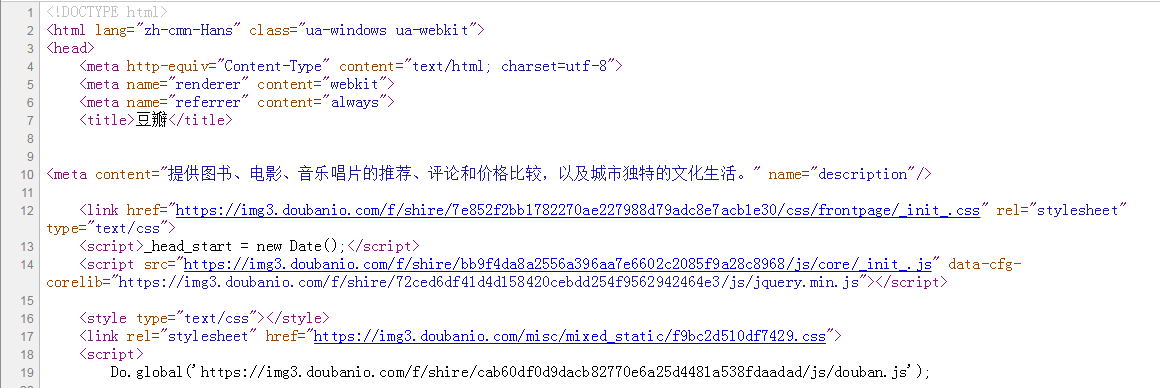
图1 在豆瓣网上"查看源代码"得到的部分内容
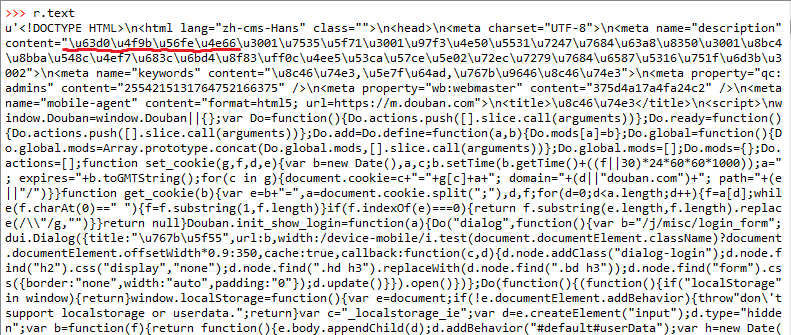
图2 r.text的部分内容
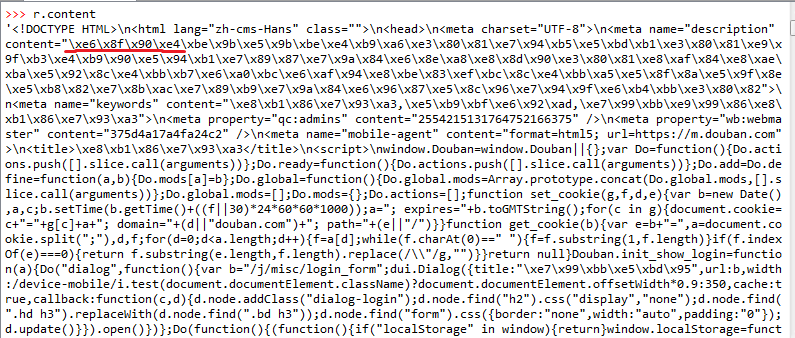
图3 r.content的部分内容
从图1,图2可以看出: 1) 网页响应的内容就是网页的源代码.2) r.text和r.content都是经过了编码的,图1和图2中红线部分为"提供图书"的编码:图1为Unicode编码16进制,图2为'ISO-8859-1'编码.

图4 "提供图书"四个汉字的编码
当你访问r.text之时,requests会使用r.encoding的编码格式进行编码, 如果你把r.encoding的值改变了, 再访问t.text的时候, 它就会按照新的编码形式进行编码.如下所示将'utf-8'编码改成'ISO-8859-1',再访问r.text,得到如图5所示的内容:
>>> r.encoding 'utf-8' >>> r.encoding = 'ISO-8859-1'

图5 用了'ISO-8859-1'的编码
那r.text和r.content的区别是什么呢?
r.text是unicode编码的响应内容(r.text is the content of the response in unicode), r.content是字符编码的响应内容(r.content is the content of the response in bytes); text属性会尝试按照encoding属性自动将响应的内容进行转码后返回,如果encoding为None,requests会按照chardet(这是什么?)猜测正确的编码; 如果你想取文本,可以通过r.text, 如果想取图片,文件,则可以通过r.content(这点我现在也不是很明白).针对响应内容是二进制文件(如图片)的场景,content属性获取响应的原始内容(以字节为单位),例如:
from PIL import Image from io import BytesIO r = requests.get('http://pic6.huitu.com/res/20130116/84481_20130116142820494200_1.jpg') i = Image.open(BytesIO(r.content)) # 得到图像 i.save('sample.jpg', 'jpeg') # 保存图像

图6 图片的r.content内容
JSON响应内容:
requests内置了一个JSON解码器, 帮助处理JSON数据,JSON的简介见附录2.
>>> r = requests.get('https://github.com/timeline.json') >>> r.json() {u'documentation_url': u'https://developer.github.com/v3/activity/events/#list-public-events', u'message': u'Hello there, wayfaring stranger. If you\u2019re reading this then you probably didn\u2019t see our blog post a couple of years back announcing that this API would go away: http://git.io/17AROg Fear not, you should be able to get what you need from the shiny new Events API instead.'} >>> r.json <bound method Response.json of <Response [410]>>
附录:
1.URL组成:
基本的URL的格式为: "协议://授权/路径?查询", 如在百度上分别搜索"Brad Pitt"和"url", 出来的URL如下所示, 协议为: https(用安全套接字层传送的超文本传输协议), 授权为: www.baidu.com, 路径为: s, 查询为: ?后面的一坨.
搜索"Brad Pitt", 出来的URL是:https://www.baidu.com/s?wd=Brad%20Pitt&rsv_spt=1&rsv_iqid=0xf7315fbc0002f13b&issp=1&f=8&rsv_bp=0&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_sug3=2&rsv_n=2&rsv_sug1=1&rsv_sug7=100&rsv_sug2=0&inputT=364&rsv_sug4=530&rsv_sug=1
搜索"url", 出来的URL是:https://www.baidu.com/s?wd=url&rsv_spt=1&rsv_iqid=0xed90010e00032652&issp=1&f=8&rsv_bp=0&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_n=2&rsv_sug3=1
URL由三部分组成: 资源类型, 存放资源的主机域名, 资源文件名. URL的一般语法为([]里面的为可选项): protocol://hostname[:port]/path/[:parameters][?query]#fragmentpro
protocol: 协议,最常用的是HTTP协议;hostname: 主机名,指用来存放资源的服务器的域名系统(DNS)主机名或IP地址;post: 端口号,整数,可选,各种协议都有默认的端口号(http的80端口),忽略的时候采用方案的默认端口; path: 路径, 一般用来表示主机上的一个目录或者文件地址; parameters: 参考(可选),用于指定特殊参数.query: 查询,用于给动态网页(如使用PHP/ASP/NET的技术制作的网页)传递参数,可以有多个参数, 用符号"&"隔开,每个"参数名:参数值"用"="隔开. fragment: 信息片段,是个字符串,用于指定网络资源中的片段.
2.JSON:
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式, 作为数据交换语言, 易于人阅读和编写, 同时也易于机器解析和生成. JSON数据的书写格式是: 名称:值 对.中间用:隔开(这个就像python的dict定义嘛). 如: r'documentation_url': u'https://developer.github.com/v3/activity/events/#list-public-events'.
参考:
[1] Python爬虫利器一之Requests库的用法: https://cuiqingcai.com/2556.html
[2] Requests: 让HTTP服务人类(中文官方文档): http://cn.python-requests.org/zh_CN/latest/
[3] http://docs.python-requests.org/zh_CN/latest/user/advanced.html
[4] 浅谈HTTP中Get与Post的区别: http://www.cnblogs.com/hyddd/archive/2009/03/31/1426026.html
[5] W3School-HTML/CSS: http://www.w3school.com.cn/html/html_forms.asp

