
思考:JDK1.8之后HashMap为什么要加入红黑树
在JDK1.7时
如果构造1000w个哈希码相同的字符串,把他们全部插入HashMap中,这将导致严重的哈希冲突
1000w个字符串全部挤入到一个哈希桶中,从而形成一个超长链表,这时候的HashMap的性能将从O(1)退化到O(n)
为什么性能会退化到O(n)?
因为在插入的时候要先比较这个节点是不是存在,因为每个字符串都是不一样的,所以它要把所有节点全部遍历完之后,才能发现不存在
当插入的节点越多,那么它遍历的节点也就越多,自然而然性能就会持续往下降
这就是所谓的哈希攻击,通过精心构造的字符串,让他们的哈希code一样,最后把他们全部挤入到一个哈希桶中,从而形成一个超长的链表,把它的速度从O(1)退化到O(n)
如何防止这种哈希碰撞攻击?
JDK1.8之后的HashMap升级了红黑树,当冲突的节点超过了8个就会树化,而红黑树的性能是O(log n),虽然不及原来的O(1),但是这个速度也是可以接受的
那是不是升级了之后的HashMap就再也不用担心这种哈希攻击了?
那也不一定,如果去重写了hashCode和equals方法的话,在这种情况,红黑树也救不了
红黑树性能退化分析
我们知道红黑树的查找类似二分查找,查询时与当前节点比较,比他大就往右走,比他小就往左边走,但是这里的hashCode都是同一个值,就无法比较大小,只能全部遍历了,性能就会从O(log n)退化到O(n)
但是为什么没有重写hashCode和equals方法就可以抵御哈希攻击呢?
因为HashMap还留了一手
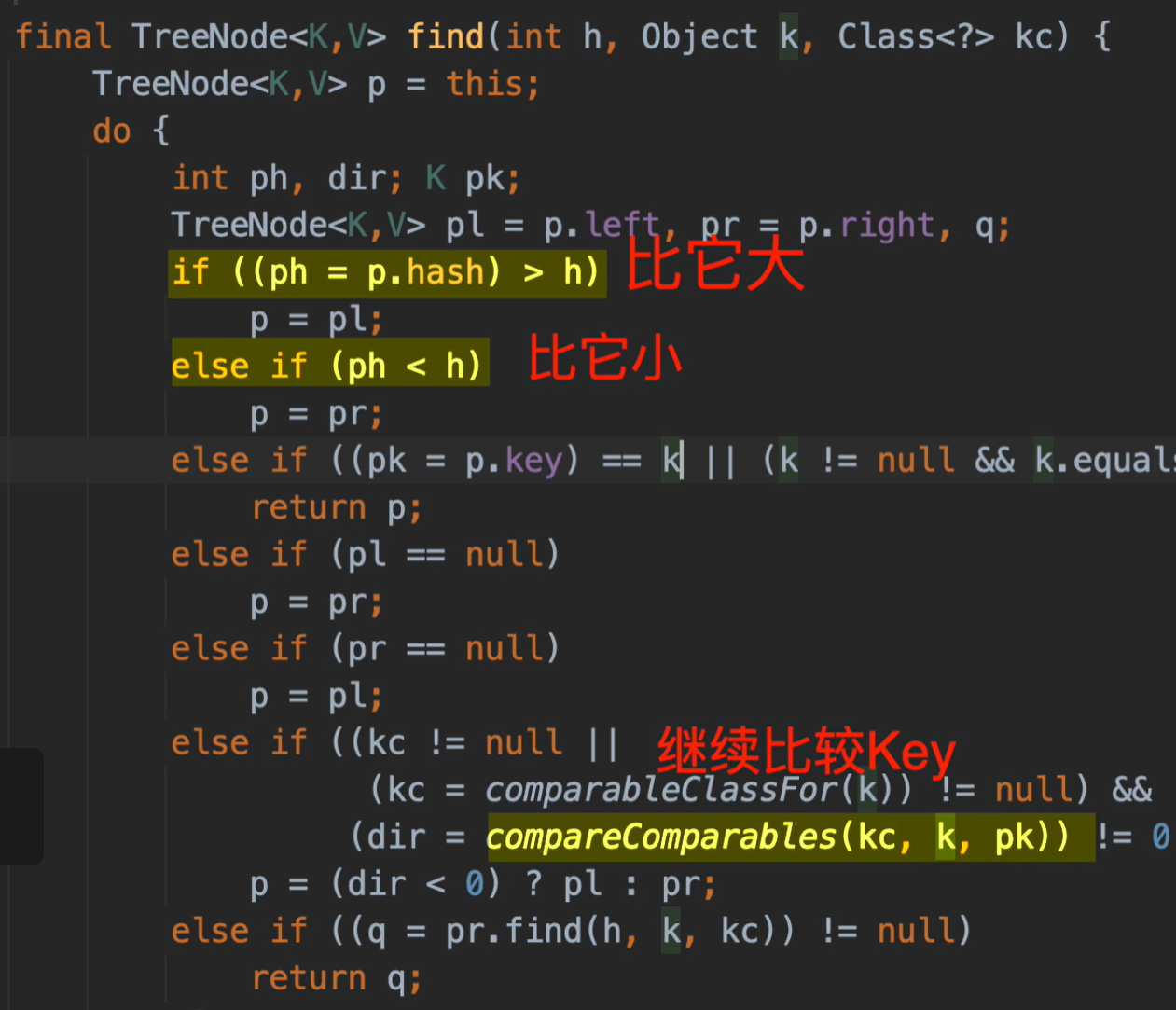
它的红黑树是经过特殊定制的,当比较的hashCode相等时,且key不相等,就会继续用key值比较大小,以继续支持二分查找
所以如果重写了hashCode和equals方法之后,这个key并不是一个可比较的对象,所以就直接退化到O(n)
给这个key实现Comparable接口可以重新恢复之前的效率
以下是个人的理解
JDK1.8HashMap为什么要去升级红黑树?
当有大量hashCode相同的数据插入时,会使哈希表中的某一个桶中链表过长,就会将其转换为红黑树,红黑树的任何操作都是O(log n),这样即使有大量相同的hashCode的数据,HashMap在该桶下操作的时间复杂度也只会从O(1)降到O(log n),而不会降到O(n)
红黑树为什么不直接用TreeMapp,而是自己去写一个?
虽然TreeMap也使用红黑树,但是TreeMap要求键实现Comparable接口或者提供Comparator来进行比较。而HashMap在使用红黑树时并不要求键实现Comparable接口。
这是因为HashMap在使用红黑树时,会使用特殊的比较方式来处理没有实现的Comparable接口的键
重写hashCode与equals方法到底会对HashMap造成哪些影响?
HashMap是通过实例对象的hashCode方法去找数据所在的桶,在通过对象的equals去该桶中寻找对应的数据,去比较对象是否相等
当我们new了两个相同数据的对象,不重写hashCode和equals方法。插入到HashMap中,由于hashCode和equals均不相等,HashMap会认为这是两个不同的对象
如果重写的了hashCode和equals方法则会认为这两个对象是相同的
具体要不要重写,怎么重写,还要看自己的业务


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?