
java数据结构
Java 提供了丰富的数据结构来处理和组织数据。
Java 的 java.util 包中提供了许多这些数据结构的实现,可以根据需要选择合适的类。
以下是一些常见的 Java 数据结构:
数组(Array):
数组(Arrays)是一种基本的数据结构,可以存储固定大小的相同类型的元素。
int[] array = new int[5];
- 特点: 固定大小,存储相同类型的元素。
- 优点: 随机访问元素效率高。
- 缺点: 大小固定,插入和删除元素相对较慢。
int [] array =new int[3]; array[0]=1; array[1]=2; array[2]=3; System.out.println(array[1]);
列表(List):
Java 提供了多种列表实现,如 ArrayList 和 LinkedList。
List<String> arrayList = new ArrayList<>();
List<Integer> linkedList = new LinkedList<>();
ArrayList:
- 特点: 动态数组,可变大小。
- 优点: 高效的随机访问和快速尾部插入。
- 缺点: 中间插入和删除相对较慢。

ArrayList<String> sites = new ArrayList<String>(); sites.add("Google"); sites.add("Runoob"); sites.add("Taobao"); //添加元素 sites.add("Weibo"); //获取指定元素 System.out.println(sites.get(3)); // 访问第四个元素 sites.set(2, "Wiki"); // 第一个参数为索引位置,第二个为要修改的值 sites.remove(3); // 删除第四个元素
sites.size()//获取下标长度
LinkedList:
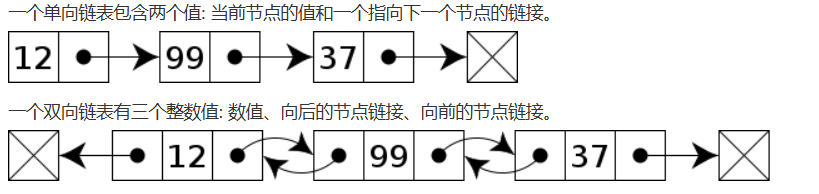
- 特点: 双向链表,元素之间通过指针连接。
- 优点: 插入和删除元素高效,迭代器性能好。
- 缺点: 随机访问相对较慢。
LinkedList<String> sites = new LinkedList<String>(); sites.add("Google"); sites.add("Runoob"); sites.add("Taobao"); sites.add("Weibo"); System.out.println(sites); // 使用 addFirst() 在头部添加元素 sites.addFirst("Wiki"); // 使用 addLast() 在尾部添加元素 sites.addLast("Wiki"); // 使用 removeFirst() 移除头部元素 sites.removeFirst(); // 使用 removeLast() 移除尾部元素 sites.removeLast(); // 使用 getFirst() 获取头部元素 System.out.println(sites.getFirst()); // 使用 getLast() 获取尾部元素 System.out.println(sites.getLast()); //获取下标长度 int size = sites.size();
集合(Set):
集合(Sets)用于存储不重复的元素,常见的实现有 HashSet 和 TreeSet。
Set<String> hashSet = new HashSet<>();
Set<Integer> treeSet = new TreeSet<>();
HashSet:
- 特点: 无序集合,基于HashMap实现。
- 优点: 高效的查找和插入操作。
- 缺点: 不保证顺序。

HashSet<String> sites = new HashSet<String>(); sites.add("Google"); sites.add("Runoob"); sites.add("Taobao"); sites.add("Zhihu"); sites.add("Runoob"); // 重复的元素不会被添加 System.out.println(sites);//获取集合数据 System.out.println(sites.contains("Taobao"));//是否存在这个数据 true/false sites.remove("Taobao"); // 删除元素,删除成功返回 true,否则为 false sites.clear();//删除集合所有的元素 int size = sites.size();//获取下标长度
TreeSet:
- 特点:TreeSet 是有序集合,底层基于红黑树实现,不允许重复元素。
- 优点: 提供自动排序功能,适用于需要按顺序存储元素的场景。
- 缺点: 性能相对较差,不允许插入 null 元素。
//默认构造函数创建 TreeSet<String> treeSet = new TreeSet<>(); //您可以使用带有Comparator参数的构造函数来指定元素的排序方式。比如,创建一个降序排列的 TreeSet: TreeSet<Integer> customOrderTreeSet = new TreeSet<>(Comparator.reverseOrder()); //您还可以从现有的集合(如 List 或 Set)创建一个 TreeSet,以便在不同集合类型之间进行转换: Set<String> existingSet = new HashSet<>(Arrays.asList("A", "B", "C")); TreeSet<String> treeSetFromSet = new TreeSet<>(existingSet); treeSet.add("A"); treeSet.add("B"); treeSet.add("C"); //添加元素 treeSet.remove("B"); //删除元素 boolean containsC = treeSet.contains("C");//检查元素是否存在于 TreeSet 中: // 关于Iterator主要有三个方法:hasNext()、next()、remove() // hasNext:没有指针下移操作,只是判断是否存在下一个元素 // next:指针下移,返回该指针所指向的元素 // remove:删除当前指针所指向的元素,一般和next方法一起用,这时候的作用就是删除next方法返回的元素 Iterator<String> iterator = treeSet.iterator();//获取有序的元素列表 boolean b = iterator.hasNext(); //使用迭代器遍历 while (iterator.hasNext()) { String element = iterator.next(); System.out.println(element); } //for遍历 for (String element : treeSet) { System.out.println(element); }
映射(Map):
射(Maps)用于存储键值对,常见的实现有 HashMap 和 TreeMap。
Map<String, Integer> hashMap = new HashMap<>();
Map<String, Integer> treeMap = new TreeMap<>();
HashMap:
- 特点: 基于哈希表实现的键值对存储结构。
- 优点: 高效的查找、插入和删除操作。
- 缺点: 无序,不保证顺序。
// 创建 HashMap 对象 Sites HashMap<Integer, String> Sites = new HashMap<Integer, String>(); // 添加键值对 Sites.put(1, "Google"); Sites.put(2, "Runoob"); Sites.put(3, "Taobao"); Sites.put(4, "Zhihu"); System.out.println(Sites);//访问对象 System.out.println(Sites.get(3));//访问指定元素 Sites.remove(4);//删除指定key的元素 Sites.clear();//删除所有元素 Sites.size();//获取下标长度 Set<Integer> integers = Sites.keySet();//获取所有key Collection<String> values = Sites.values();//获取所有value // 输出 key 和 value for (Integer i : Sites.keySet()) { System.out.println("key: " + i + " value: " + Sites.get(i)); } // 返回所有 value 值 for(String value: Sites.values()) { // 输出每一个value System.out.print(value + ", "); }
TreeMap:
- 特点: 基于红黑树实现的有序键值对存储结构。
- 优点: 有序,支持按照键的顺序遍历。
- 缺点: 插入和删除相对较慢。
public class TreeMapTest { public static void main(String[] agrs){ //创建TreeMap对象: TreeMap<String,Integer> treeMap = new TreeMap<String,Integer>(); System.out.println("初始化后,TreeMap元素个数为:" + treeMap.size()); //新增元素: treeMap.put("hello",1); treeMap.put("world",2); treeMap.put("my",3); treeMap.put("name",4); treeMap.put("is",5); treeMap.put("jiaboyan",6); treeMap.put("i",6); treeMap.put("am",6); treeMap.put("a",6); treeMap.put("developer",6); System.out.println("添加元素后,TreeMap元素个数为:" + treeMap.size()); //遍历元素: Set<Map.Entry<String,Integer>> entrySet = treeMap.entrySet(); for(Map.Entry<String,Integer> entry : entrySet){ String key = entry.getKey(); Integer value = entry.getValue(); System.out.println("TreeMap元素的key:"+key+",value:"+value); } //获取所有的key: Set<String> keySet = treeMap.keySet(); for(String strKey:keySet){ System.out.println("TreeMap集合中的key:"+strKey); } //获取所有的value: Collection<Integer> valueList = treeMap.values(); for(Integer intValue:valueList){ System.out.println("TreeMap集合中的value:" + intValue); } //获取元素: Integer getValue = treeMap.get("jiaboyan");//获取集合内元素key为"jiaboyan"的值 String firstKey = treeMap.firstKey();//获取集合内第一个元素 String lastKey =treeMap.lastKey();//获取集合内最后一个元素 String lowerKey =treeMap.lowerKey("jiaboyan");//获取集合内的key小于"jiaboyan"的key String ceilingKey =treeMap.ceilingKey("jiaboyan");//获取集合内的key大于等于"jiaboyan"的key SortedMap<String,Integer> sortedMap =treeMap.subMap("a","my");//获取集合的key从"a"到"jiaboyan"的元素 //删除元素: Integer removeValue = treeMap.remove("jiaboyan");//删除集合中key为"jiaboyan"的元素 treeMap.clear(); //清空集合元素: //判断方法: boolean isEmpty = treeMap.isEmpty();//判断集合是否为空 boolean isContain = treeMap.containsKey("jiaboyan");//判断集合的key中是否包含"jiaboyan" } }
栈(Stack):
栈(Stack)是一种线性数据结构,它按照后进先出(Last In, First Out,LIFO)的原则管理元素。在栈中,新元素被添加到栈的顶部,而只能从栈的顶部移除元素。这就意味着最后添加的元素是第一个被移除的。
Stack<Integer> stack = new Stack<>();
Stack 类:
- 特点: 代表一个栈,通常按照后进先出(LIFO)的顺序操作元素。
队列(Queue):
队列(Queue)遵循先进先出(FIFO)原则,常见的实现有 LinkedList 和 PriorityQueue。
Queue<String> queue = new LinkedList<>();
Queue 接口:
- 特点: 代表一个队列,通常按照先进先出(FIFO)的顺序操作元素。
- 实现类: LinkedList, PriorityQueue, ArrayDeque。
堆(Heap):
堆(Heap)优先队列的基础,可以实现最大堆和最小堆。
PriorityQueue<Integer> minHeap = new PriorityQueue<>();
PriorityQueue<Integer> maxHeap = new PriorityQueue<>(Collections.reverseOrder());
树(Trees):
Java 提供了 TreeNode 类型,可以用于构建二叉树等数据结构。
class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode(int x) { val = x; }
}


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?