day4(老男孩-Python3.5-S14期全栈开发)
作者:赵俊 发布日期:2020/08/25
三、装饰器详解
定义: 装饰器本质是函数,用来装饰其他函数(为其他函数添加新功能)
原则:不能修改被装饰函数的源代码
不能修改被装饰函数的调用方式
四、装饰器应用详解
实现装饰器知识储备
1、函数即“变量”
2、高阶函数
3、嵌套函数
高阶函数 + 嵌套函数 = 装饰器
1 import time 2 3 4 def timmer(func): # 要接收被装饰函数的内存地址 5 def warpper(*args, **kwargs): # 定义新功能 6 start_time = time.time() 7 func() 8 stop_time = time.time() 9 print("the func run time is %s" % (stop_time-start_time)) 10 return warpper # 新定义的函数回调给源函数,利用源函数的调用来执行 11 12 13 @timmer # 将被装饰函数传递给装饰器,装饰器返回值赋值给被装饰函数 14 def test(): 15 time.sleep(3) 16 print("ss") 17 18 19 print(test())
五、装饰器之函数即变量
函数先定义后调用
匿名函数:
calc = lambda x : x*3
print(calc(3))
六、装饰器之高阶函数
高阶函数:
把一个函数名当做实参传递给另一个函数(在不修改被装饰函数源代码的情况下为其添加新功能)
返回值中包含函数名(不修改函数的调用方式)
七、装饰器之嵌套函数
函数的嵌套:
在一个函数里用def声明另一个函数
八、装饰器之案例剖析1
九、装饰器之案例剖析2
带参数传递的装饰器
1 import time 2 3 4 def timmer(func): # 要接收被装饰函数的内存地址 5 def warpper(*args, **kwargs): # 定义新功能 6 start_time = time.time() 7 func(*args, **kwargs) 8 stop_time = time.time() 9 print("the func run time is %s" % (stop_time-start_time)) 10 return warpper # 新定义的函数回调给源函数,利用源函数的调用来执行 11 12 13 @timmer # 将被装饰函数传递给装饰器,装饰器返回值赋值给被装饰函数 14 def test(name): 15 time.sleep(3) 16 print(name) 17 18 19 test("hello")
十、装饰器之高潮讲解
之前的装饰器会改变被装饰函数的返回结果,不是很完善,不过可以应付90%的场景
test有返回值123,被装饰后返回值为none
1 import time 2 3 4 def timmer(func): # 要接收被装饰函数的内存地址 5 def warpper(*args, **kwargs): # 定义新功能 6 start_time = time.time() 7 func(*args, **kwargs) 8 stop_time = time.time() 9 print("the func run time is %s" % (stop_time-start_time)) 10 return warpper # 新定义的函数回调给源函数,利用源函数的调用来执行 11 12 13 @timmer # 将被装饰函数传递给装饰器,装饰器返回值赋值给被装饰函数 14 def test(name): 15 time.sleep(3) 16 print(name) 17 return 123 18 19 20 print(test("hello"))
不改变源函数返回值的做法
1 import time 2 3 4 def timmer(func): # 要接收被装饰函数的内存地址 5 def warpper(*args, **kwargs): # 定义新功能 6 start_time = time.time() 7 res = func(*args, **kwargs) # ---------修改的部分,可以不改变源函数返回值 8 stop_time = time.time() 9 print("the func run time is %s" % (stop_time-start_time)) 10 return res # ----------修改的部分,可以不改变源函数返回值 11 return warpper # 新定义的函数回调给源函数,利用源函数的调用来执行 12 13 14 @timmer # 将被装饰函数传递给装饰器,装饰器返回值赋值给被装饰函数 15 def test(name): 16 time.sleep(3) 17 print(name) 18 return 123 19 20 21 print(test("hello"))
装饰器写三层,修饰时传递参数。可以解决一个装饰器根据参数传递的不同来有选择的执行结果
十一、迭代器与生成器1
列表生成式:[i*2 for i in rang(6)]
结果:[0,2,4,6,8,10]
列表生成式创建的列表受内存限制,列表大小有限,在python中有种一边循环一边计算的机制,称为生成器
创建一个generator,有很多方法,第一种方法是把列表生成式的[]改成()就可以
如要一个个打印出来,我们可以使用__next__()函数(注意在3.0是两个下划线,2.7没有下划线)获得generator的下一个返回值,不支持a[1]和len(a)方式
斐波那契:
1 def fib(max): 2 n,a,b = 0,0,1 3 while n<max: 4 print(b) 5 a,b = b,a+b 6 n = n + 1 7 return "done" 8 9 fib(100)
a, b = b, a+b 相当于
t = (b, a+b) t是元祖
a = t[0]
b = t[1]
变成生成器只有一步之遥,把函数里的print(b)换成yield b
1 def fib(max): 2 n, a, b = 0, 0, 1 3 while n < max: 4 #print(b) 5 yield b 6 a, b = b, a+b 7 n = n+1 8 return "hello" 9 10 11 f = fib(100) 12 print(f.__next__()) 13 print(f.__next__()) 14 print(f.__next__())
yield相当于定时器中断
这里,最难理解的就是generator和函数的执行流程不一样。函数是顺序执行,遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
但是用for循环调用generator时,发现拿不到generator的return语句的返回值。如果想要拿到返回值,必须捕获StopIteration错误,返回值包含在StopIteration的value中
1 g = fib(6) 2 while True: 3 try: 4 x = next(g) 5 print('g:', x) 6 except StopIteration as e: 7 print('Generator return value:', e.value) 8 break 9 10 g: 1 11 g: 1 12 g: 2 13 g: 3 14 g: 5 15 g: 8 16 Generator return value: done
疑难杂症记录
1、配置解释器时,无法保存,配置解释器窗口的show all里,将里面的重名的删除即可
2、调试时无法调试,提示Connection to Python debugger failed Interrupted function call: accept failed
是由于有个别文件有问题,拷贝到其他文件夹里不要放在工程根目录就可以(最终发现该文件名称为string.py,更改文件名也可以解决)
十二、迭代器与生成器2
1 import time 2 3 4 def consumer(name): 5 while True: 6 baozi = yield 7 print("%s开始吃第%s个包子了" % (name, baozi+1)) 8 9 10 def producer(name): 11 c = consumer("猪八戒") 12 c1 = consumer("白骨精") 13 c.__next__() 14 c1.__next__() 15 for i in range(10): 16 time.sleep(3) 17 print("------------------------") 18 print("%s开始生产包子了" % name) 19 c.send(i) 20 c1.send(i) 21 22 23 producer("阿里巴巴")
send在获取下一个值得效果和next的基本一致,这是send获取时给上一个yield传递一个数据
使用send注意事项
1、第一轮循环不能用send,只能用next,因为第一次send找不到上一个yield值,如果要使用必须传递一个none参数
十三、迭代器与生成器并行
可以作用于for循环的对象,list,tuple,dict,set,str,generater(包括生成器和带yield的函数)
可直接作用于for循环的对象,叫做可迭代对象Iterable
可以使用isinstance()判断一个对象是否是Iterable对象,使用时需要提前导入from collections import Iterable
*可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator
生成器都是Iterator对象,但list、dict、str虽然是Iterable,却不是Iterator。
把list、dict、str等Iterable变成Iterator可以使用iter()函数:
你可能会问,为什么list、dict、str等数据类型不是Iterator?
这是因为Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
十四、内置方法详解1
内置参数详解 https://docs.python.org/3/library/functions.html?highlight=built#ascii
十五、内置方法详解2
内置参数详解 https://docs.python.org/3/library/functions.html?highlight=built#ascii
十六、Json与pickle数据序列化
用于序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
json不能序列化内存地址,pickle可以,但是序列化内存地址后,在反序列化后内存中没有了那个内存地址
十七、软件目录结构规范
目录组织方式
假设你的项目名为foo, 我比较建议的最方便快捷目录结构这样就足够了:
Foo/
|-- bin/
| |-- foo
|
|-- foo/
| |-- tests/
| | |-- __init__.py
| | |-- test_main.py
| |
| |-- __init__.py 在创建包时自己创建
| |-- main.py
|
|-- docs/
| |-- conf.py
| |-- abc.rst
|
|-- setup.py
|-- requirements.txt
|-- README
简要解释一下:
bin/: 存放项目的一些可执行文件,当然你可以起名script/之类的也行。foo/: 存放项目的所有源代码。(1) 源代码中的所有模块、包都应该放在此目录。不要置于顶层目录。(2) 其子目录tests/存放单元测试代码; (3) 程序的入口最好命名为main.py。docs/: 存放一些文档。setup.py: 安装、部署、打包的脚本。requirements.txt: 存放软件依赖的外部Python包列表。README: 项目说明文件。
除此之外,有一些方案给出了更加多的内容。比如LICENSE.txt,ChangeLog.txt文件等,我没有列在这里,因为这些东西主要是项目开源的时候需要用到。如果你想写一个开源软件,目录该如何组织,可以参考这篇文章。
下面,再简单讲一下我对这些目录的理解和个人要求吧。
关于README的内容
这个我觉得是每个项目都应该有的一个文件,目的是能简要描述该项目的信息,让读者快速了解这个项目。
它需要说明以下几个事项:
- 软件定位,软件的基本功能。
- 运行代码的方法: 安装环境、启动命令等。
- 简要的使用说明。
- 代码目录结构说明,更详细点可以说明软件的基本原理。
- 常见问题说明。
我觉得有以上几点是比较好的一个README。在软件开发初期,由于开发过程中以上内容可能不明确或者发生变化,并不是一定要在一开始就将所有信息都补全。但是在项目完结的时候,是需要撰写这样的一个文档的。
可以参考Redis源码中Readme的写法,这里面简洁但是清晰的描述了Redis功能和源码结构。
关于requirements.txt和setup.py
setup.py
一般来说,用setup.py来管理代码的打包、安装、部署问题。业界标准的写法是用Python流行的打包工具setuptools来管理这些事情。这种方式普遍应用于开源项目中。不过这里的核心思想不是用标准化的工具来解决这些问题,而是说,一个项目一定要有一个安装部署工具,能快速便捷的在一台新机器上将环境装好、代码部署好和将程序运行起来。
这个我是踩过坑的。
我刚开始接触Python写项目的时候,安装环境、部署代码、运行程序这个过程全是手动完成,遇到过以下问题:
- 安装环境时经常忘了最近又添加了一个新的Python包,结果一到线上运行,程序就出错了。
- Python包的版本依赖问题,有时候我们程序中使用的是一个版本的Python包,但是官方的已经是最新的包了,通过手动安装就可能装错了。
- 如果依赖的包很多的话,一个一个安装这些依赖是很费时的事情。
- 新同学开始写项目的时候,将程序跑起来非常麻烦,因为可能经常忘了要怎么安装各种依赖。
setup.py可以将这些事情自动化起来,提高效率、减少出错的概率。"复杂的东西自动化,能自动化的东西一定要自动化。"是一个非常好的习惯。
setuptools的文档比较庞大,刚接触的话,可能不太好找到切入点。学习技术的方式就是看他人是怎么用的,可以参考一下Python的一个Web框架,flask是如何写的: setup.py
当然,简单点自己写个安装脚本(deploy.sh)替代setup.py也未尝不可。
requirements.txt
这个文件存在的目的是:
- 方便开发者维护软件的包依赖。将开发过程中新增的包添加进这个列表中,避免在
setup.py安装依赖时漏掉软件包。 - 方便读者明确项目使用了哪些Python包。
这个文件的格式是每一行包含一个包依赖的说明,通常是flask>=0.10这种格式,要求是这个格式能被pip识别,这样就可以简单的通过 pip install -r requirements.txt来把所有Python包依赖都装好了。具体格式说明: 点这里。
关于配置文件的使用方法
注意,在上面的目录结构中,没有将conf.py放在源码目录下,而是放在docs/目录下。
很多项目对配置文件的使用做法是:
- 配置文件写在一个或多个python文件中,比如此处的conf.py。
- 项目中哪个模块用到这个配置文件就直接通过
import conf这种形式来在代码中使用配置。
这种做法我不太赞同:
- 这让单元测试变得困难(因为模块内部依赖了外部配置)
- 另一方面配置文件作为用户控制程序的接口,应当可以由用户自由指定该文件的路径。
- 程序组件可复用性太差,因为这种贯穿所有模块的代码硬编码方式,使得大部分模块都依赖
conf.py这个文件。
所以,我认为配置的使用,更好的方式是,
- 模块的配置都是可以灵活配置的,不受外部配置文件的影响。
- 程序的配置也是可以灵活控制的。
能够佐证这个思想的是,用过nginx和mysql的同学都知道,nginx、mysql这些程序都可以自由的指定用户配置。
所以,不应当在代码中直接import conf来使用配置文件。上面目录结构中的conf.py,是给出的一个配置样例,不是在写死在程序中直接引用的配置文件。可以通过给main.py启动参数指定配置路径的方式来让程序读取配置内容。当然,这里的conf.py你可以换个类似的名字,比如settings.py。或者你也可以使用其他格式的内容来编写配置文件,比如settings.yaml之类的
调用其他目录文件的方法
1 import os 2 import sys 3 4 print(__file__) # 打印文件执行的相对路径 5 print(os.path.dirname(__file__)) # 往上退一个目录 6 print(os.path.dirname(os.path.dirname(__file__))) 7 BASE_DIR = os.path.dirname(os.path.dirname(__file__)) 8 sys.path.append(BASE_DIR) #加入系统环境变量 9 from core import main
十八、本周作业
免费在线作图网页https://www.processon.com/
参考部分代码https://github.com/triaquae/py3_training/tree/master/atm
作业需求:
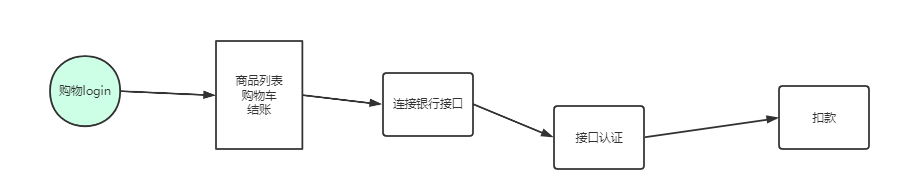
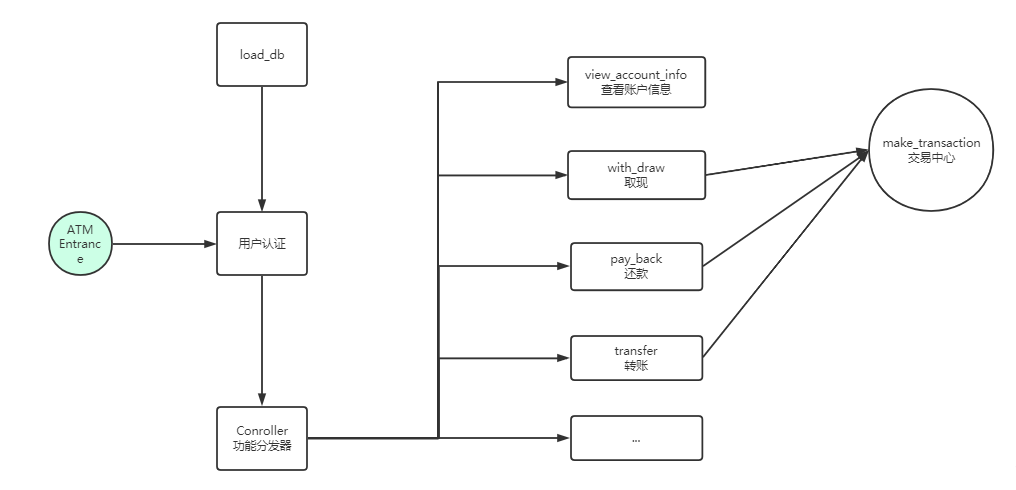
模拟实现一个ATM + 购物商城程序
- 额度 15000或自定义
- 实现购物商城,买东西加入 购物车,调用信用卡接口结账
- 可以提现,手续费5%
- 每月22号出账单,每月10号为还款日,过期未还,按欠款总额 万分之5 每日计息
- 支持多账户登录
- 支持账户间转账
- 记录每月日常消费流水
- 提供还款接口
- ATM记录操作日志
- 提供管理接口,包括添加账户、用户额度,冻结账户等。。。
- 用户认证用装饰器
简易流程图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号