day3(老男孩-Python3.5-S14期全栈开发)
作者:赵俊 发布日期:2020/01/14
一、集合操作
集合是一个无序的,不重复的数据组合,他的主要作用是
1、去重:把一个列表变成集合,自动去重
2、关系测试:测试两组数据的交集、差集、并集等关系
1、去重演示
1 #Author:ZHJ 2 #去重演示 3 list_1 = [1, 3, 5, 4, 3, 7, 3, 6, 5, 3] 4 print(set(list_1))
结果输出:
{1, 3, 4, 5, 6, 7}
2、交集演示(运算符 &)
1 #Author:ZHJ 2 #交集演示 3 list_1 = set([1, 3, 5, 4, 3, 7, 3, 6, 5, 3]) 4 list_2 = set([2, 5, 7, 23, 12, 45, ]) 5 print(list_1.intersection(list_2))
结果输出:
{5, 7}
3、并集演示(运算符 |)
1 #并集演示 2 list_1 = set([1, 3, 5, 4, 3, 7, 3, 6, 5, 3]) 3 list_2 = set([2, 5, 7, 23, 12, 45, ]) 4 print(list_1.union(list_2))
结果输出:
{1, 2, 3, 4, 5, 6, 7, 12, 45, 23}
4、差集演示(运算符 -)
1 #Author:ZHJ 2 #差集演示 3 list_1 = set([1, 3, 5, 4, 3, 7, 3, 6, 5, 3]) 4 list_2 = set([2, 5, 7, 23, 12, 45, ]) 5 print(list_1.difference(list_2)) 6 print(list_2.difference(list_1)) 7 #列表1里有,但列表2里没有的数据
结果输出:
{1, 3, 4, 6}
{2, 12, 45, 23}
5、子集演示
1 #Author:ZHJ 2 #子集演示 3 list_1 = set([1, 3, 5, 4, 3, 7, 3, 6, 5, 3]) 4 list_2 = set([5, 7]) 5 #判断是否为子集,是返回true。否则返回false 6 print(list_2.issubset(list_1)) 7 #判断是否为父集,是返回true。否则返回false 8 print(list_1.issuperset(list_2))
6、对称差集(运算符 ^)
1 #Author:ZHJ 2 #对称差集演示 3 list_1 = set([1, 3, 5, 4, 3, 7, 3, 6, 5, 3]) 4 list_2 = set([5, 7, 2]) 5 print(list_1.symmetric_difference(list_2)) 6 #两个集合相同的元素去掉,并且合并去重
7、是否没有交集
1 #Author:ZHJ 2 #是否没有交集演示 3 list_1 = set([1, 3, 5, 4, 3, 7, 3, 6, 5, 3]) 4 list_2 = set([33]) 5 print(list_1.isdisjoint(list_2)) 6 #有交集返回false,没有交集返回true
8、基本操作
1 #Author:ZHJ 2 #是否没有交集演示 3 list_1 = set([1, 3, 5, 4, 3, 7, 3, 6, 5, 3]) 4 #添加一项 5 list_1.add("dd") 6 #添加多项 7 list_1.update({11, 22}) 8 #删除指定一项,没有会报错 9 list_1.remove("dd") 10 #删除指定一项,没有不会报错 11 list_1.discard("ddd") 12 #集合长度 13 list_1 = len(list_1) 14 print(list_1)
二、文件读与写
1 # Author:ZHJ 2 import sys,time 3 # **********只读文件,读完文件指针在最末尾********** 4 # f = open("test.txt", "r", encoding="utf-8") 5 # data = f.read() 6 # print(data) 7 8 # **********只写文件,新建一个空白文件,有则覆盖,无则新建********** 9 # f = open("test.txt", "w", encoding="utf-8") 10 # f.write("123") 11 12 # **********追加内容到文件末尾********** 13 # f = open("test.txt", "a", encoding="utf-8") 14 # f.write("111") 15 16 # **********读多行********** 17 # f = open("test.txt", "r", encoding="utf-8") 18 # for i in range(5): 19 # print(f.readline()) 20 # for line in f.readlines(): 21 # print(line.strip()) # strip 去掉换行 22 23 # **********指定行跳过不打印********** 24 # f = open("test.txt", "r", encoding="utf-8") 25 # for index, line in enumerate(f.readlines()): 26 # if index == 3: 27 # print("--------------") 28 # continue 29 # print(line.strip()) 30 31 # **********高效的循环方法********** 32 # 如果读取文件比较大,就得使用如下方法。保证当读第二行时,前一行由内存中删除 33 # f = open("test.txt", "r", encoding="utf-8") 34 # for line in f: 35 # print(line.strip()) 36 37 # **********移动文件光标和查询光标位置********** 38 # f = open("test.txt", "r", encoding="utf-8") 39 # print(f.tell())# 返回文件指针位置,通俗也就是第几个字符位置 40 # print(f.readline()) 41 # print(f.tell()) 42 # f.seek(0)# 光标(指针)回到指定位置 43 # print(f.readline()) 44 45 # **********查询文件编码格式********** 46 # f = open("test.txt", "r", encoding="utf-8") 47 # print(f.encoding) 48 # print(f.readable()) # 判断文件是否可读 49 # print(f.writable()) # 判断文件是否可写 50 51 # **********flush刷新机制********** 52 # 当执行完写命令后,并不会立即写到硬盘上, 53 # 而是写到一个缓存中,直到达到缓存大小,才自动写到硬盘, 54 # 如果写的过程断电,就没写进去,flush的作用就是把缓存的内容手动写到硬盘中(在这个软件上无法演示) 55 # f = open("flush.txt", "w", encoding="utf-8") 56 # f.write("123\n") 57 # f.write("456\n") 58 59 # **********类似进度条********** 60 # for i in range(50): 61 # sys.stdout.write("*") 62 # sys.stdout.flush() # 似乎不要也可以,哈哈 63 # time.sleep(0.3) 64 65 # **********截断功能********** 66 # truncate() 方法用于截断文件,如果指定了可选参数 size,则表示截断文件为 size 个字符。 67 # 如果没有指定 size,则从当前位置起截断;截断之后 size 后面的所有字符被删除。 68 # f = open("test.txt", "a", encoding="utf-8") 69 # f.seek(5) 70 # f.truncate(1) # 从第10个字符开始截断,往后删除 71 72 # **********读写r+,写读w+,追加读a+********** 73 # 读写模式,不会覆盖整改文档;写读模式,会覆盖整个文档;追加读还是追加在后面 74 # f = open("test.txt", "a+", encoding="utf-8") 75 # print(f.write("ABCDE")) 76 # f.seek(0) 77 # print(f.read()) 78 79 # **********二进制模式********** 80 # 应用,网络传输使用二进制 81 # f = open("test.txt", "rb") 82 # print(f.read()) 83 # f = open("test.txt", "wb") 84 # f.write("hello world".encode())
三、文件修改
关键点在于,判断修改的字符串是否在某行里,然后利用字符串替换命令,来替换要修改的符串
1 # Author:ZHJ 2 f = open("旧日的足迹.txt", "r", encoding="utf-8") 3 f_new = open("旧日的足迹.bak", "w", encoding="utf-8") 4 for line in f: 5 if "在这个温暖家乡故地" in line: 6 line = line.replace("在这个温暖家乡故地", "在这个温暖家乡故地\n****************") 7 f_new.write(line) 8 f.close() 9 f_new.close()
with语句用法,帮助自动关闭文件,with语句执行完自动关闭
with open("旧日的足迹.txt", "r", encoding="utf-8") as f:
#代码块
在2.7之后,可以打开多个文件
with open("文件1") as f1,open("文件2") as f2: #代码块
四、字符编码与转码
参考文档:http://www.cnblogs.com/yuanchenqi/articles/5956943.html
需知:
1.在python2默认编码是ASCII, python3里默认是unicode
2.unicode 分为 utf-32(占4个字节),utf-16(占两个字节),utf-8(占1-4个字节), so utf-16就是现在最常用的unicode版本, 不过在文件里存的还是utf-8,因为utf8省空间
3.在py3中encode,在转码的同时还会把string 变成bytes类型,decode在解码的同时还会把bytes变回string
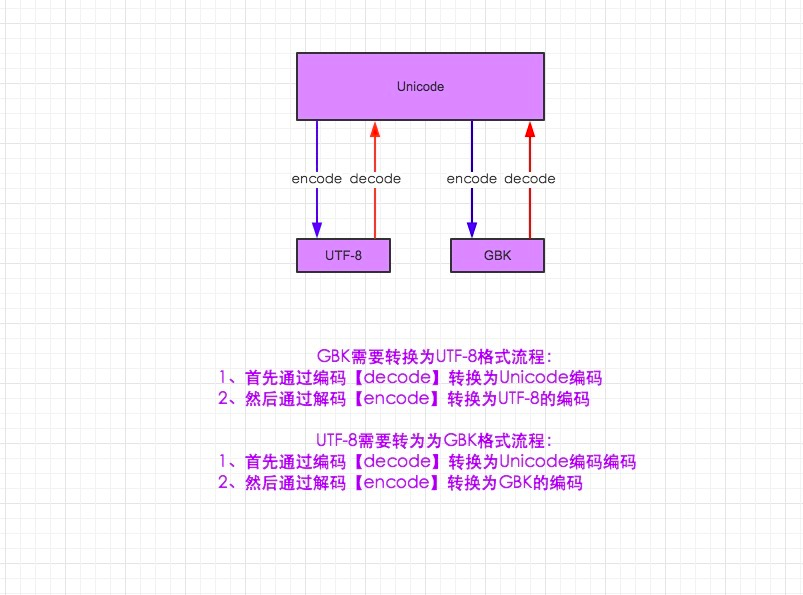
上图仅适用于py2
五、函数与函数式编程
1、面向对象
2、面向过程,定义没有返回值的函数
3、函数式编程
没有函数的编程只是在写逻辑,想脱离函数,重用你的逻辑,唯一的方法就是拷贝
定义函数的优点:
1、代码重用
2、保持一致性
3、可扩展性
1 # Author:ZHJ 2 import time 3 4 5 def log(): 6 time_style = "%Y-%m-%d %X" 7 time_current = time.strftime(time_style) 8 with open("log.txt","a+", encoding="utf-8") as f: 9 f.write("%s我的日志\n" % time_current) 10 11 12 log()
六、函数式编程之参数详解
1、返回值
不指定返回值,python默认返回none
返回值不限数量类型,多个返回值包含在一个元祖中返回
2、参数
函数名后的括号内可以有参数
a、形参与实参
形参:不实际存在,虚拟参数,定义函数的时候使用
实参:实际的参数,调用函数时,传递给函数的参数
b、位置参数和关键字参数
位置参数调用 test(1,2)
关键字参数调用 test(x=1,y=2)
混合调用 test(1,y=2)
混合调用时,关键字参数必须写到位置参数后面
c、默认参数
定义函数时,写形参时提前赋值
1 def test(x,y=2): 2 print(x) 3 print(y)
特点:调用函数时,默认参数可以传递也可以不传递参数,不会报错
d、参数组
针对实参不固定的情况下使用
参数组和其他组合时必须放在最后
1 def test(*args): 2 print(args) 3 4 test(1,2,3,4)#接收位置参数 5 test(*[1,2,3,4,5,6,7])
1 def test(x,*args): 2 print(x) 3 print(args) 4 5 test(1,2,3,4,,5,6)#这时候随便写,不会有参数数量的错误
#传递字典参数 def test(**kwargs): print(kwargs) test(name="sunni",age = 19)
七、局部变量与全局变量作用域
在子程序中定义的变量叫局部变量,在程序一开始定义的变量叫全局变量
全局变量的作用域是整个程序,局部变量的作用域是定义该变量的子程序
当局部变量和全局变量同名时:
在定义变量的子程序内局部变量起作用,在其他地方全局变量起作用
1、在函数中要改全局变量时,在函数内定义变量前加global,该变量就为全局(尽量不要用)
2、字符串和数值不能在局部改全局,但是列表,字典,集合,类,可以在局部作用域改全局变量
八、递归
在函数内部,可以调用其他函数。如果一个函数在内部调用其本身,这个函数就是递归函数
递归的特性
1、必须有一个明确的结束条件
2、每次进入更深一层次递归时,问题规模都比上次递归应有所减少
3、递归效率不高,递归层次过高会导致栈溢出(在计算机中,函数调用是通过栈这种数据结构实现的,每当进入一次函数调用,栈就会增加一层栈帧,每当函数返回时,栈就会减少一层栈帧。由于栈的大小不是无限的,所以递归调用的次数过多,会导致栈溢出)
1 # Author:ZHJ 2 3 4 def calc(n): 5 print(n/2) 6 if n/2 > 1: 7 return calc(n/2) 8 9 10 calc(1000)
九、函数式编程与函数不同
函数是Python内建支持的一种封装,我们通过把大段代码拆成函数,通过一层一层的函数调用,就可以把复杂任务分解成简单的任务,这种分解可以称之为面向过程的程序设计。函数就是面向过程的程序设计的基本单元。
函数式编程中的函数这个术语不是指计算机中的函数(实际上是Subroutine),而是指数学中的函数,即自变量的映射。也就是说一个函数的值仅决定于函数参数的值,不依赖其他状态。比如sqrt(x)函数计算x的平方根,只要x不变,不论什么时候调用,调用几次,值都是不变的。
Python对函数式编程提供部分支持。由于Python允许使用变量,因此,Python不是纯函数式编程语言。
一、定义
简单说,"函数式编程"是一种"编程范式"(programming paradigm),也就是如何编写程序的方法论。
主要思想是把运算过程尽量写成一系列嵌套的函数调用。举例来说,现在有这样一个数学表达式:
(1 + 2) * 3 - 4
传统的过程式编程,可能这样写:
var a = 1 + 2;
var b = a * 3;
var c = b - 4;
函数式编程要求使用函数,我们可以把运算过程定义为不同的函数,然后写成下面这样:
var result = subtract(multiply(add(1,2), 3), 4);
这段代码再演进以下,可以变成这样
add(1,2).multiply(3).subtract(4)
这基本就是自然语言的表达了。再看下面的代码,大家应该一眼就能明白它的意思吧:
merge([1,2],[3,4]).sort().search("2")
因此,函数式编程的代码更容易理解。
要想学好函数式编程,不要玩py,玩Erlang,Haskell, 好了,我只会这么多了。。。
十、高阶函数
变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。
def add(x,y,f): return f(x) + f(y) res = add(3,-6,abs) print(res)
十一、作业
eval() 函数用来执行一个字符串表达式,并返回表达式的值。可以字符串转成字典
程序2:修改haproxy配置文件
需求:


1、查 输入:www.oldboy.org 获取当前backend下的所有记录 2、新建 输入: arg = { 'bakend': 'www.oldboy.org', 'record':{ 'server': '100.1.7.9', 'weight': 20, 'maxconn': 30 } } 3、删除 输入: arg = { 'bakend': 'www.oldboy.org', 'record':{ 'server': '100.1.7.9', 'weight': 20, 'maxconn': 30 } } 需求
global log 127.0.0.1 local2 daemon maxconn 256 log 127.0.0.1 local2 info defaults log global mode http timeout connect 5000ms timeout client 50000ms timeout server 50000ms option dontlognull listen stats :8888 stats enable stats uri /admin stats auth admin:1234 frontend oldboy.org bind 0.0.0.0:80 option httplog option httpclose option forwardfor log global acl www hdr_reg(host) -i www.oldboy.org use_backend www.oldboy.org if www backend www.oldboy.org server 100.1.7.9 100.1.7.9 weight 20 maxconn 3000 原配置文件
作业内容:
1 # Author:ZHJ 2 print("1、查询\n2、新建\n3、删除") 3 selected = input("请选择操作方式......") 4 5 6 def query(q): 7 flag = 0 8 with open("ini.txt", "r", encoding="utf-8") as f: 9 for line in f: 10 if "backend " + q + "\n" == line: 11 flag = 1 12 continue 13 if flag == 1: 14 flag = 0 15 print(line.lstrip()) 16 17 18 def new(n): 19 #print(n) 20 w = eval(n) 21 flag = 0 22 #print(w["backend"]) 23 with open("ini.txt", "r", encoding="utf-8") as f: 24 for line in f: 25 if "backend " + w["backend"] + "\n" == line: 26 print("要增加的节点已经存在,无需重复添加!") 27 flag = 1 28 break 29 if flag == 0: 30 string1 = "backend "+ w["backend"] 31 string2 = " "+"server "+ w["record"]["server"]+" weight "+str(w["record"]["weight"])+" maxconn "+str(w["record"]["maxconn"]) 32 with open("ini.txt","a",encoding="utf-8") as f: 33 f.write(string1) 34 f.write("\n"+string2+"\n") 35 36 37 def delete(d): 38 w = eval(d) 39 string1 = "backend " + w["backend"]+"\n" 40 string2 = " " + "server " + w["record"]["server"] + " weight " + str(w["record"]["weight"]) + " maxconn " + str(w["record"]["maxconn"])+"\n" 41 with open("ini.txt", "r", encoding="utf-8") as f: 42 line = f.readlines() 43 with open("ini.txt", "w", encoding="utf-8") as f: 44 for l in line: 45 if string1 != l and string2 != l: 46 f.write(l) 47 print() 48 49 50 if selected == "1": 51 a = input("请输入要查询的内容!") 52 query(a) 53 elif selected == "2": 54 b = input("请输入要增加的内容!") 55 new(b) 56 elif selected == "3": 57 d = input("请输入要删除的内容!") 58 delete(d) 59 else: 60 print("输入有误!")
配置文件最后一行要带回车,不然字符串比较时不同
输入方式如下:
1、查
输入:www.oldboy.org
获取当前backend下的所有记录
2、新建
输入:
{'backend': 'www.oldboy.org','record':{'server': '100.1.7.9','weight': 20,'maxconn': 30}}
3、删除
输入:
{'backend': 'www.oldboy.org','record':{'server': '100.1.7.9','weight': 20,'maxconn': 30}}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号