[tf] tensorflow中multi-GPU小坑记录
tensorflow中multi-GPU小坑记录
最近又需要点tf的代码,有几个点关于多卡的代码点需要记录下。一直想把平时常用的一些代码段整理一下,但是一直没时间,每周有在开新的进程,找时间再说吧。先零星的记点吧。
干货
- 在tf构图阶段,把计算点都开在GPU上,尽量不要开在CPU上。提速杠杠滴!
- 在多卡读取数据阶段,在for len(num_gpu)循环外建立queue,在循环内取数据。
好了,主要的干货就没有了,看懂的可以ctrl+w了。
不太了解的,咱继续。
tf构图在GPU上
- 在tf构图阶段,把计算点都开在GPU上,尽量不要开在CPU上。提速杠杠滴!
with tf.Graph().as_default(), tf.device('/gpu:0'):
y = interface(x)
...
with tf.Session(config = tf.ConfigProto(log_device_placement=True,allow_soft_placement=True)) as sess:
sess.run(...)
在train function中构静态图时,把节点和运算都放在GPU上,同时需要加上allow_soft_placement=True,这个flag的作用是保证程序能正常运行,因为有些运算操作是不能放在GPU上运行的,flag保证了那些操作会转移到CPU上运行。
result
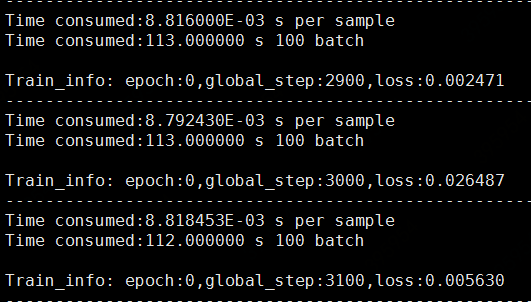
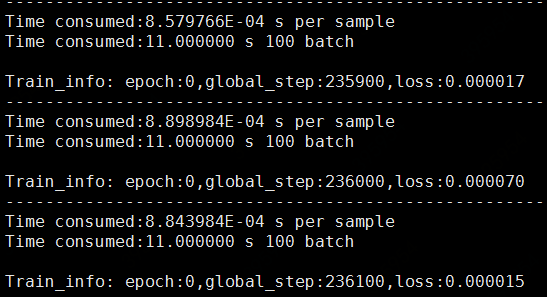
在单卡上os.environ["CUDA_VISIBLE_DEVICES"] = "0"跑的数据,不做严谨定量展现,只定量的感受下提速。CPU上
113s per 100 batch_size,转到GPU上后提速到11s。
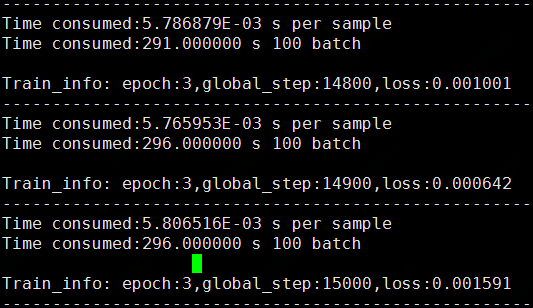
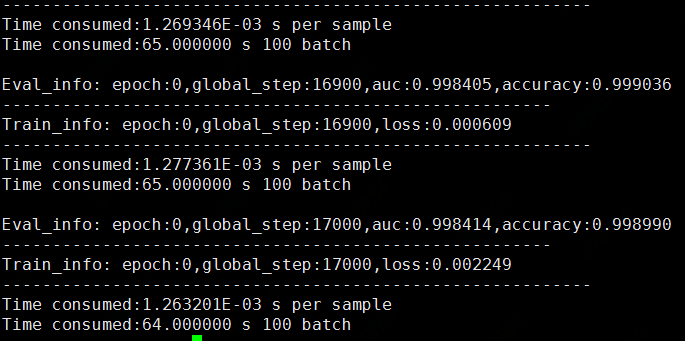
在4卡上跑实验,per 100 batch_size,CPU:295s,GPU:65s。
multiGPU读取数据
目前在r1.2的版本上用的还是queue的方式,好像在r1.4版本上官方推荐使用Dataset API,暂时还没有切版本。
2.在多卡读取数据阶段,在for len(num_gpu)循环外建立queue,在循环内取数据。
def get_input(self,data_path_list,batch_size):
file_list = os.listdir(data_path_list)
file_list = [data_path_list+'/'+ i for i in file_list]
with tf.variable_scope("tfrecords_input"):
filename_queue = tf.train.string_input_producer(file_list)
reader = tf.TFRecordReader()
_,serialized_example = reader.read(filename_queue)
# 解析单个数据格式
features = tf.parse_single_example(serialized_example,
features={
'x':tf.FixedLenFeature([],tf.string),
'labels':tf.FixedLenFeature([],tf.string)
})
x = tf.reshape(tf.decode_raw(features['x'],tf.int32),[2,self.n_features])
labels = tf.reshape(tf.decode_raw(features['labels'],tf.int32), [1,2])
return x, labels
def train():
min_after_dequeue = 1000
capacity = min_after_dequeue+4*batch_size
x_, labels = get_input(train_tfrecords_path,batch_size)
with tf.variable_scope(tf.get_variable_scope()):
for i in range(num_gpus):
with tf.device('gpu:%d' % i):
with tf.name_scope('GPU_%d' % i) as scope:
train_data = tf.train.shuffle_batch([x_,labels],
batch_size=batch_size,
capacity=capacity,
min_after_dequeue=min_after_dequeue,
num_threads=3)
x = train_data[0]
y_ = train_data[-1]
interface_output = interface(x)
cur_loss = compute_loss(interface_output,y_,reg=None)
...
最初是把tf.train.shuffle_batch这步放在了for循环的外边,紧跟着get_input()函数,但是发现这样的话读取出来的是同一个batch_size的数据。

haha
写tf的时候还是记得转变下思维,不能总是按照C++的方式觉得每一步都会有定值,tf在没有sess.run之前只是个占位符而已,并没有数据流动!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号