
机器学习分布式策略
背景
机器学习任务大多是一种迭代式优化算法,可分为三个步骤:
- 读取数据做模型前向计算forward;
- 计算loss,并进行反向传播backprop,得到参数梯度;
- 根据梯度利用优化算法optimizer进行参数迭代更新;
随着数据量的扩增,单节点的计算能力逐渐成为了瓶颈。13年可扩展的ParamerterServer被李沐提出,15年英伟达发布NCCL库,16年百度提出ringAllReduce, 随后Uber集成了部分分布式算法发布Horovod 第三方开源库兼容主流深度框架tf/pytorch/mxnet等。
Parameter Server
沐神的ParamerterServer论文有两个版本,NIPS偏向算法层面, OSDI偏向系统设计层面。
基本流程

总架构包含,(计算资源)两个机器角色 worker/servers,(算法任务)三个任务进程 scheduler/worker client/server client;
-
总调度进程:给每个worker分发数据;每个worker并行T轮执行WORKERITERATER方法
-
Worker进程:初始化(加载部分训练数据,从server中拉取初始参数W0);计算流程(使用训练数据计算梯度,将节点梯度 push到server节点,将下一轮模型参数pull同步到本地);
-
Server进程:初始化模型参数后等待接收;收到m个worker节点的梯度后汇总所有;使用汇总参数梯度计算更新梯度;
-
Server节点:保存模型参数、接受worker节点计算的梯度、汇总计算全局梯度,更新模型参数;
-
Worker节点:各保存部分训练数据,从server节点拉取模型参数,根据训练数据计算梯度,上传给server节点;

物理架构,server group和多个worker group,resource manager负责总体的资源分配调度(eg: K8S)。
- Server group包含多个server node,server manager负责维护和分配server资源,每个server node维护部分参数,node间相互通信和备份数据;
- Worker group各自对应训练任务(可不同),worker node只与server通信(实际不定)。
- Server Management,新增节点时,负责新节点的数据分配,从旧节点迁移数据到新节点,其他节点删除掉不属于自身的数据段;(节点删除同理)
- Worker Management,task scheduler给新节点分配数据,新节点拉取数据并拉取模型参数,其他节点释放掉部分数据任务;(训练节点丢失一般寻找替代或不做处理,很少进行节点恢复)
训练一致性和并行效率Trade-off
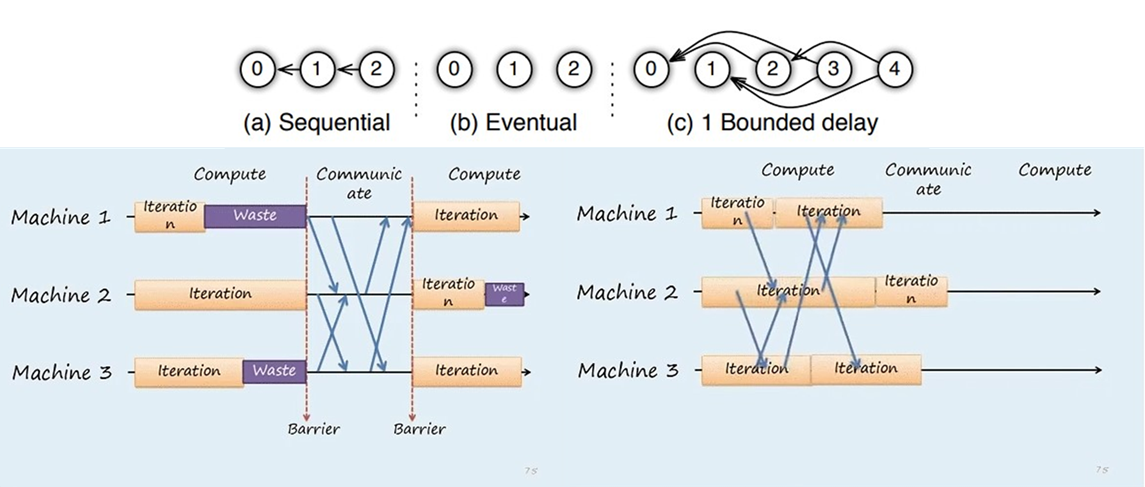
- Sequential: 同步模式,下一任务必须在前一任务完成后执行;
- Eventual: 异步模式,所有任务独立执行;
- Bounded delay: 有界延迟,折中方案,限定阈值内强制更新模型参数;
异步梯度更新方式大幅加快了训练速度,但牺牲了模型一致性同时影响了收敛速度,最终选择需具体问题具体对比验证。
一致性哈希
对于参数server,单节点容易受带宽制约成为瓶颈节点,同步模式下广播所有参数对网络负载压力较大。因此采用server group内含多个node模式。参数服务器以命名空间的方式组织参数,模型的参数采用键值key-value的形式保存。
分布式存储带来的三个新问题:
- 每个节点存储哪些数据,保证数据存储的唯一性;
- 所有访问数据命中同一节点;
- 存储节点增删情况下,数据迁移量最小;
为每块数据构造存储查询key,采用哈希方式存储在N个节点。传统采用hash(key)%N方式能够解决前两个问题,但扔存在问题三。解决方案,一致性哈希(consistent hashing)。
算法原理:
- 将整个hash空间虚拟成圆环,顺时针方向0-2^32-1;
- 将服务器IP or 主机名hash到圆环上;
- 将数据对象key hash到圆环上,并顺时针滚动,遇到的首个机器节点即为存储位置;
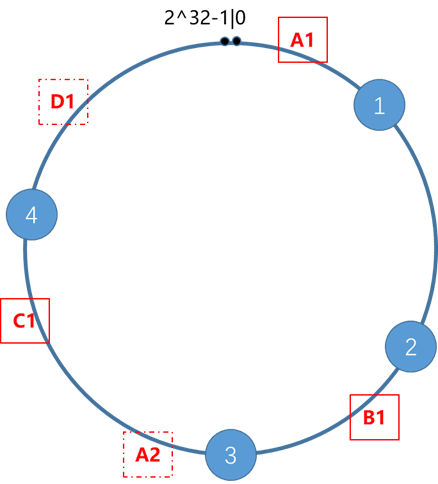
对于三台节点ABC,和四个存储数据块1234,按照算法原理可知,1/2->B,3->C,4->A;
- 容错性,C节点宕机,需迁移BC弧数据到A;
- 扩展性,增加节点D,需迁移CD弧数据到D;
- 虚拟节点,原始节点较少时可能会形成数据倾斜,通过在主机名后增加尾缀方式扩展节点A->(A1, A2),保证一定的负载均衡性;通常虚拟节点个数为32;
Vector Clock向量时钟
PS架构使用vector clock,利用向量钟来记录每个节点中参数的时间戳,用来跟踪状态或避免数据的重复发送。但如果有n个节点,m个参数,那么vector clock的空间复杂度就O(n*m)。
考虑到单worker在参数同步时的时间戳相同,将参数按照hash区域打包成k uniq key range,共享同一个时间戳,空间复杂度降低为O(n*k),k<<m;[此处为保持字母符号一致做了修改,原文是O(k*m),文中的m是node个数]
模型并行& 数据并行
-
数据并行:同一个模型复制多个副本到不同GPU,每个 GPU 分配不同数据,将所有 GPU结果按照规则合并;
-
模型并行:当模型很大时由于显存的限制难以在单卡上运行,需要将模型拆分,不同 GPU 负责网络模型的不同部分,不同层在不同GPU上或是同一层参数在不同GPU上,使得运行前后存在串行依赖关系影响效率,规模伸缩性差;
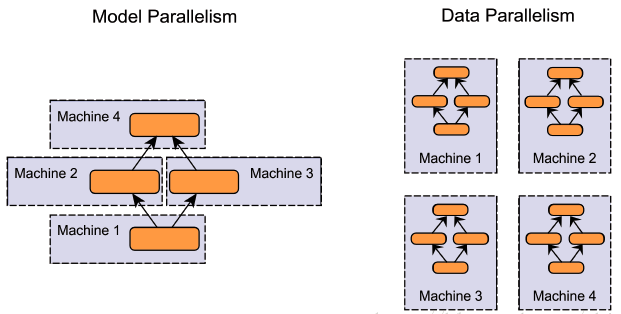
参数量巨大时,数据通信容易成为数据并行瓶颈,远高于模型并行;但基于减少数据等待的前提拆分模型同样增加人工工作量,不利于迭代,因此仍优先使用数据并行;
输入矩阵X[200*1000],经过两个矩阵A[1000*1000] B[1000*500],计算loss ||XAB||;假设2个计算节点,在不考虑数据X传输耗时情况下:
模型并行传输,A=[A1, A2]拆分2个1000*500,B=[B1; B2]拆分2个500*500,XAB=XA1B1+_XA2B2,2个节点分别存储A1B1& A2B2,forward时需加和两部分得到结果,传输量200*500;backward不需要传输数据;
数据并行传输,输入数据拆分2个[100*1000],2个节点分别存储全部副本AB,forward不需要传输数据,backward需同步参数,1000*1000+1000*500;
同步更新& 异步更新
- 同步更新:每个batch所有GPU计算完成后才更新一次参数,收敛速度块,但训练速度略慢,木桶效应取决于性能最差的GPU;
- 异步更新:每个GPU计算完成后自行更新参数,训练速度快,但由于梯度失效过期问题导致最终训练效果略低于同步模式;

总结
- 异步模式的分布式梯度下降有效解决节点性能差异问题,松弛模型一致性条件允许算法在收敛速度和系统性能间做平衡决策;
- 多参数存储节点的架构,有效解决单节点的带宽和内存瓶颈;
- 一致性哈希方式实现信息的最小传递,增加节点无需重启网络,扩展性强;
- worker group模式使得系统支持多任务并行运算,能够使得线上线下训练结果无缝衔接;
All Reduce
模型参数的变化来自于各个节点梯度的更新。如果所有节点使用相同参数初始化,并在参数更新前完成节点梯度同步,保证各节点参数的一致性,间接实现参数同步目标。
AllReduce基于上述前提,将所有节点同时充当ps和worker的角色,用于分布式深度学习的通讯运算,算法的目标是高效得将不同节点中的数据整合之后再把结果分发给各个节点。
- reduce,将参数从多个节点收集到一个节点上,同时对收集到的参数进行归并(sum/max);
- broadcast,将参数从一个节点发到多个节点上;
- allreduce,每个节点都从其他节点上面收集参数,同时对收集到的参数进行归并。

具体的实现方式有很多种,后续介绍的估算耗时忽略了网络延迟,主要分析网络通信耗时与节点数据计算耗时。字母变量含义,模型总参数量S(ize),节点个数N(umber),节点间带宽B(andwidth),每字节数据的计算耗时C(omputation)。
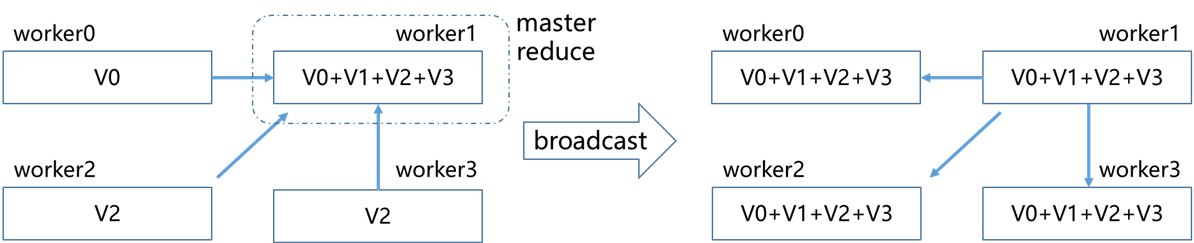
reduce+broadcast
由经典PS架构朴素对应算法,将一个worker设为master,其余所有worker数据同步到master进行整合,完成后再分发(broadcast)回个worker。
缺点与PS模式相同,当节点数过多时,master节点带宽会成为瓶颈,节点过多时容易引起显存OOM.
总耗时,2*S/B+N*S*C;
recursive halving and doubling
经典树形算法,将节点个数归并为2的幂次,两两进行数据合并逐层传递至master节点。
有效避免了单节点带宽瓶颈问题,但halving阶段有一半节点闲置等待接受数据,并未充分利用网卡的全双工模式;
总耗时,2*(logN+1)*(S/B+S*C) ;
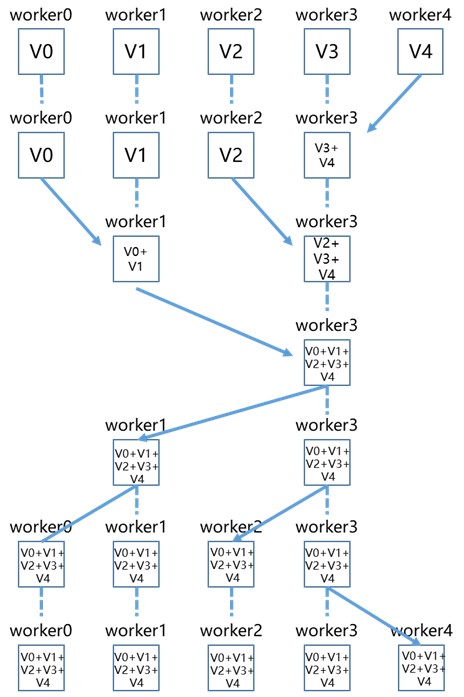
Butterfly
在通信中,充分利用所有节点的上行&下行带宽。
潜在风险,当数据量S过大时,每次传输完整模型参数,造成网络负载较高出现延时抖动。
总耗时,(logN+1)*(S/B+S*C);
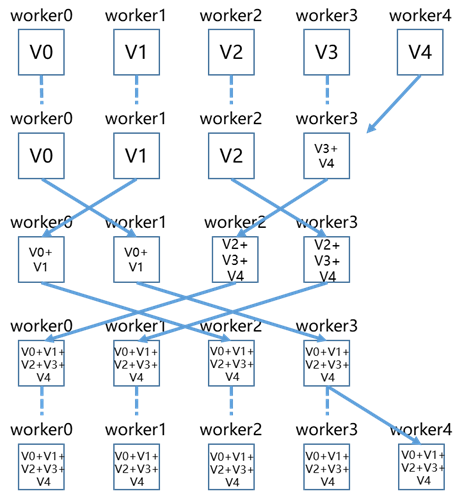
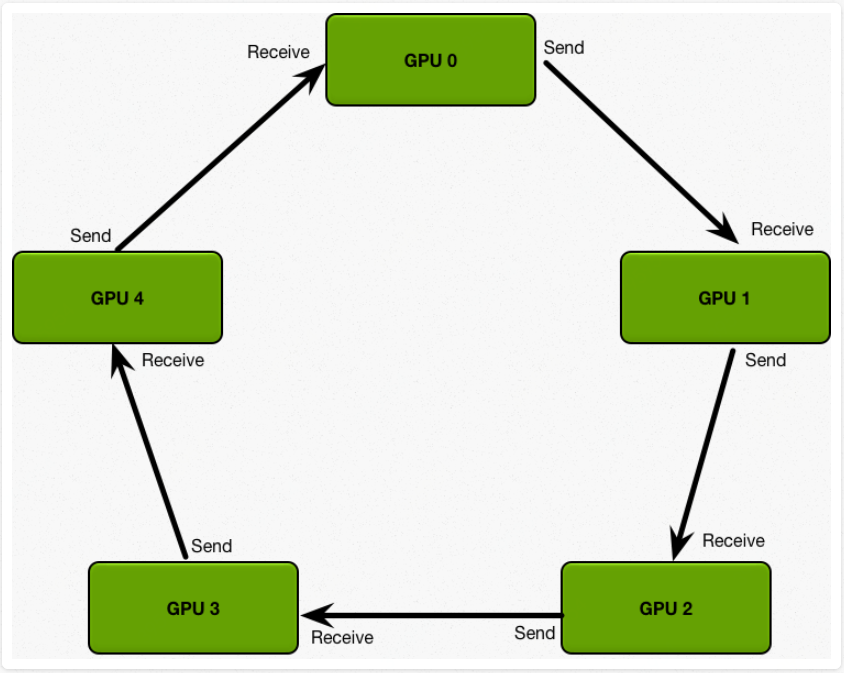
Ring AllReduce
将节点环形相连,算法将模型数据S按照节点个数切分成N份,第一阶段scatter-reduce,GPU交换数据,每个GPU得到最后结果的一部分(chunk),通过(N-1) 步使得每个节点都能得到 1/N 块的完整更新数据;第二阶段all-gather,GPU交换chunk,每个GPU得到最后结果,通过(N-1) 步将单节点1/N块完整数据传输给其他节点,使得所有节点的每个 1/N 块数据都是完整的更新数据。
总耗时,2*(N-1)*( S/(NB) ) + (N-1)* ( S/N*C );

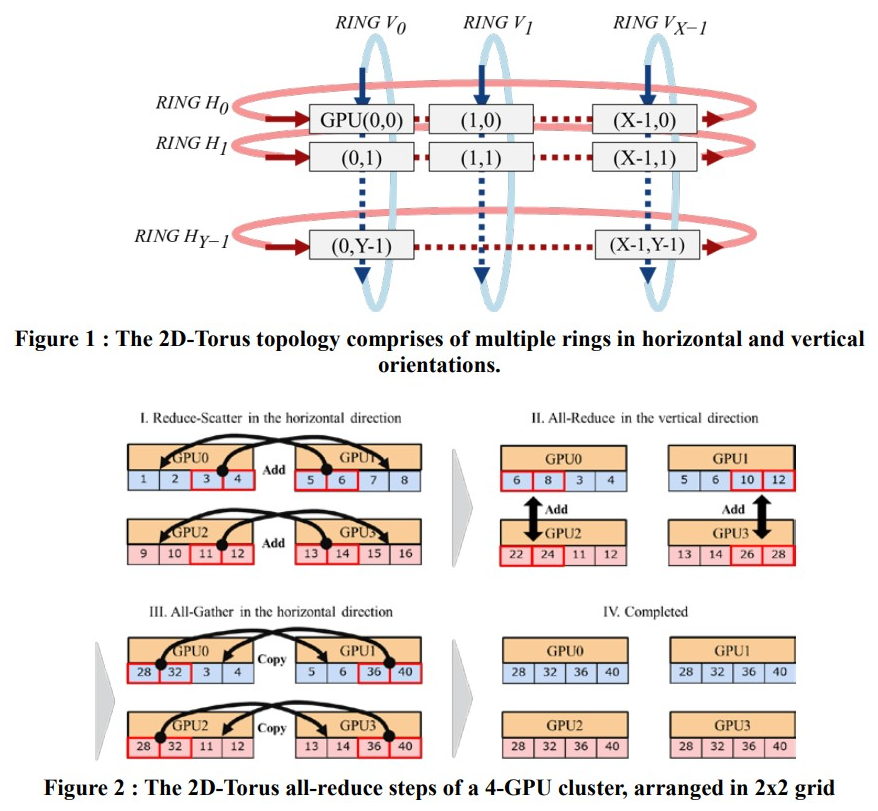
2D-Torus AllReduce
随着节点个数N的增多,通信延迟使得通信成本与GPU数量成正比,索尼对Ring做了改良,利用分层思想将集群中GPU分组排列为2D网格,第一阶段水平组内执行scatter-reduce,第二阶段竖直组间执行all-reduce,第三阶段水平组内执行all-gather;即执行两遍all-reduce;
总耗时,2*(X-1+Y-1)*( S/(XB) ) + (X-1+Y-1)* ( S/X*C );
工程框架
分布式框架,基础在于并行和通讯,传统经典的集合通信MPI(Message Passing Interface) 中实现了众多算法,由于实现较早,并未考虑深度GPU场景架构,NVIDIA在15年结合自身硬件系统做定制化通信性能优化NCCL库,可以看作是MPI的GPU版本。NCCL 1.x为单机版本,这一阶段大众仍以MPI框架为集合通讯首选,17年NCCL2.0推出了多节点版本,逐渐受到大众认可。
tf早期版本只有PS分布式,17年百度贡献了ring-allreduce的tf源码,之后使用NCCL2.0替换掉了MPI作为GPU间的通讯,至此tensorflow的分布式逐渐完备。
tensorflow PS
在Horovod 出现前,官方只推荐集群模式,tf的PS框架是基于grpc通信框架。数据并行是最常用的,tf称为复制训练(Replicated training)。
首先创建TensorFlow Cluster对象列出所有节点或设备,包含一组task(每个task一台独立机器或机器上的一台独立GPU),分布式执行TensorFlow计算图。Cluster切分为多个job, 一个job是一类特定任务( ps,worker),每个job可以包含多个task。每个task创建一个server,连接到Cluster,tf.server为主从模式包含worker service负责模型图计算和 master service负责与外界rpc通讯、tf.Session接口target以及worker的任务分配;一个完整的模型图执行任务由client创建tf.Session,调用master service启动任务,master service通知同一个server的worker service调用GPU处理执行任务。
tf的实现方案中,分为In-graph replication 和Between-graph replication 。
- In-graph replication,只构建一个client,对应一张计算图,每张GPU上的子图可完全相同也可相互不同,但都属于同一Graph。此方式极少使用,系统容错能力差;
- Between-graph replication,每个task创建一个client,各client构建相同的Graph,但参数仍放置在ps上。优势在于单节点宕机不影响任务;
cluster: tf.train.ClusterSpec (job, task)
server: tf.train.Server (master service, worker service)
replica_device_setter: tf.train.replica_device_setter
worker: tf.train.ChiefSessionCreator, tf.train.WorkerSessionCreator
tf.train.MonitoredTrainingSession(tf.train.Supervisor), tf.train.MonitoredSession
tf.train.SessionCreator
tf.train.Scaffold
tf.train.replica_device_setter,自动将参数放置ps,但默认轮询放置到机器上,可能造成ps负载不均衡;
tf.train.ChiefSessionCreator,在worker中指定chief,执行参数初始化、保存模型等公共操作,避免资源浪费;
tf.train.MonitoredTrainingSession,自动load model,变量初始化,保存ckpt和summary,是tf.train.Supervisor的替代版,继承自tf.train.MonitoredSession;
Horovod
Horovod 的梯度参数同步就采用了 ring-allreduce 算法。在实现上,为每个节点都创建一个新进程,每个进程的输入数据独立执行,各节点算出梯度后,通过 Horovod 的 DistributedOptimizer 和 BroadcastGlobalVariablesHook 进行进程间的参数/梯度同步。Horovod 还支持配置集合通信(Collective Communication)的不同实现。
- size: 进程数量,一般指GPU数量;
- rank: 进程ID;
- local rank: 每个server中进程的本地ID;
import tensorflow as tf
import horovod.tensorflow as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank (一个GPU绑定一个进程)
config = tf.ConfigProto()
config.gpu_options.visible_device_list = str(hvd.local_rank())
# Build model,根据GPU数量放大lr
loss = ...
opt = tf.train.AdagradOptimizer(0.01 * hvd.size())
# Add Horovod Distributed Optimizer,梯度计算仍为tf.opt,参数同步hvd负责
opt = hvd.DistributedOptimizer(opt)
# Add hook to broadcast variables from rank 0 to all other processes during,确报所有进程初始值相同
# initialization.
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
# Make training operation
train_op = opt.minimize(loss)
# Save checkpoints only on worker 0 to prevent other workers from corrupting them. 只在一张卡保存操作
checkpoint_dir = '/tmp/train_logs' if hvd.rank() == 0 else None
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf.train.MonitoredTrainingSession(checkpoint_dir=checkpoint_dir,
config=config,
hooks=hooks) as mon_sess:
while not mon_sess.should_stop():
# Perform synchronous training.
mon_sess.run(train_op)
##### 任务启动
# horovodrun -np 4 -H localhost:4 python train.py
# CUDA_VISIBLE_DEVICES=6,7 horovodrun -np 2 -H localhost:2 python tensorflow_mnist.py
分布式训练减速
在默认的数据并行模式下,整体耗时主要由三部分引起,
- inference+ backward (并行加速计算)
- Gradients communication (额外开销)
- update weights (固定开销)
第三点几乎无影响,第一点为并行加速影响收益,第二天为并行的损耗,整体来看不一定能加速。
关键点在于计算通信比,对于深度模型参数少计算量大,梯度通信量小相对适合并行加速。
对应两条优化手段,1.增加每轮计算量(增大batch_size,梯度累计延迟更新),2.降低每轮通信量(半精度传输)。
Reference
- M. Li, L. Zhou, Z. Yang, A. Li, F. Xia, D.G. Andersen, and A. J. Smola. Parameter server for distributed machine learning. In Big Learning NIPS Workshop, 2013.
- Scaling Distributed Machine Learning with the Parameter Server
- https://zhuanlan.zhihu.com/p/82116922 https://juejin.cn/post/6844903877335056391 https://blog.csdn.net/abcdefg90876/article/details/108413885 https://www.jianshu.com/p/d3e503ddd68e https://www.cnblogs.com/sug-sams/articles/9999375.html https://zhuanlan.zhihu.com/p/72939003
- https://juejin.cn/post/6844903750860013576
- https://zhuanlan.zhihu.com/p/79030485 https://andrew.gibiansky.com/blog/machine-learning/baidu-allreduce/ https://zhuanlan.zhihu.com/p/100012827
- Massively Distributed SGD: ImageNet/ResNet-50 Training in a Flash https://zhuanlan.zhihu.com/p/49915897
- https://github.com/horovod/horovod https://www.infoq.cn/article/J4ry_9bsfbcNkv6dfuqC https://zhuanlan.zhihu.com/p/75318339
- https://tensorflow.google.cn/tutorials https://zhuanlan.zhihu.com/p/35083779 https://zhuanlan.zhihu.com/p/39731797 https://www.cnblogs.com/libinggen/p/7399307.html https://zhuanlan.zhihu.com/p/73580663 https://zhuanlan.zhihu.com/p/141177382 https://cloud.tencent.com/developer/article/1398209
- https://zhuanlan.zhihu.com/p/50116885 https://images.nvidia.com/events/sc15/pdfs/NCCL-Woolley.pdf
- https://mp.weixin.qq.com/s/OY-qhXjrixAlg7UU9PLVzg
