程序员修仙之路--突破内存限制的高性能排序
菜菜呀,昨天晚上班级空间崩溃了
what?

我看服务器上写了很多个日志文件,我看着太费劲了,能不能按照日期排序整合成一个文件呀?
Y总要查日志呀?
我就是喜欢编程,编程就是我的全部,给你半个小时搞一下
天天这么短时间搞这么多烂七八糟的需求,能不能给我涨点工资呀?
你去和X总说,我不管这事,我只管编程!!
............

菜菜的涨工资申请还在待审批中....

作为一个技术人员,技术的问题还是要解决。经过线上日志的分析,日志采用小时机制,一个小时一个日志文件,同一个小时的日志文件有多个,也就是说同一时间内的日志有可能分散在多个日志文件中,这也是Y总要合并的主要原因。每个日志文件大约有500M,大约有100个。此时,如果你阅读到此文章,该怎么做呢?不如先静心想2分钟!!
要想实现Y总的需求其实还是有几个难点的:
1. 如何能把所有的日志文件按照时间排序
2. 日志文件的总大小为500M*100 ,大约50G,所以全部加载到内存是不可能的
3. 程序执行过程中,要频繁排序并查找最小元素。
那我们该怎么做呢?其中一个解决方案就是它:堆
堆(英语:heap)是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵树的数组对象。
堆总是满足下列性质:
1. 堆中某个节点的值总是不大于或不小于其父节点的值
2. 堆总是一棵完全二叉树(完全二叉树要求,除了最后一层,其他层的节点个数都是满的,最后一层的节点都靠左排列)
对于每个节点的值都大于等于子树中每个节点值的堆,我们叫作“大顶堆”。对于每个节点的值都小于等于子树中每个节点值的堆,我们叫作“小顶堆”。
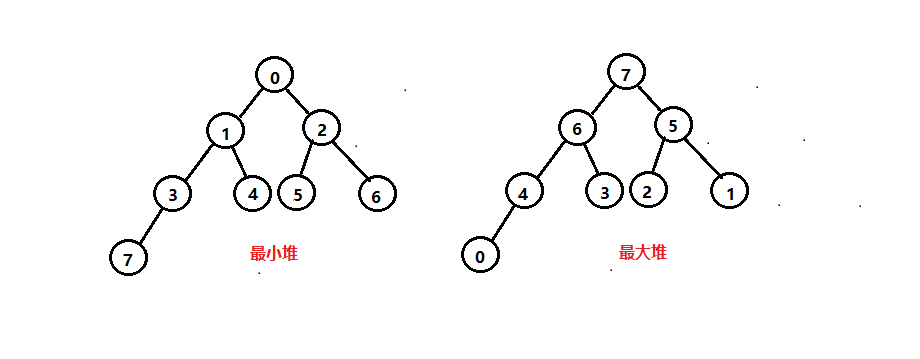
完全二叉树比较适合用数组来存储(链表也可以实现)。为什么这么说呢?用数组来存储完全二叉树是非常节省存储空间的。因为我们不需要存储左右子节点的指针,单纯地通过数组的下标,就可以找到一个节点的左右子节点和父节点。
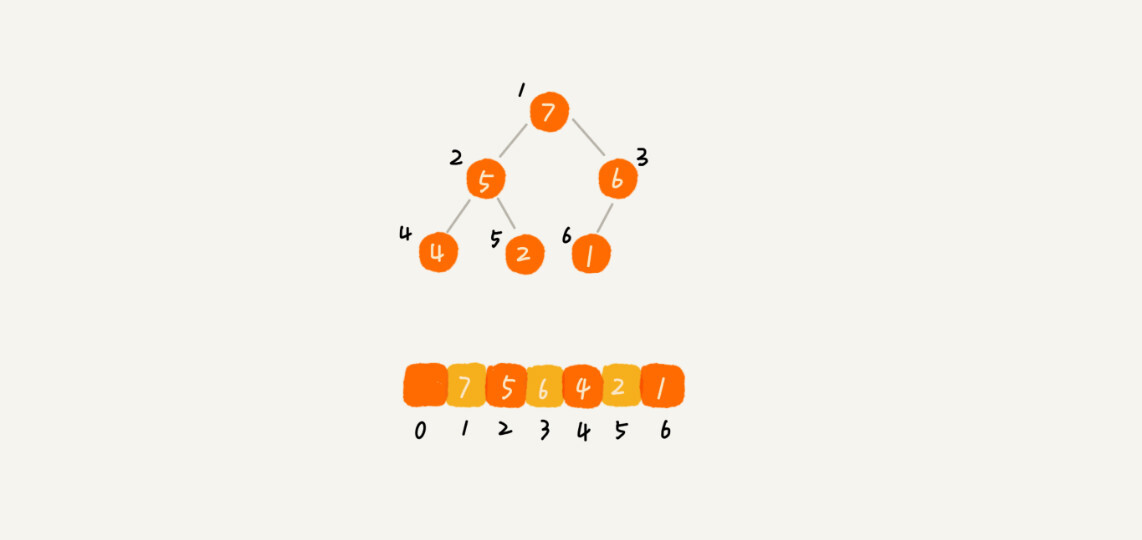
经过上图可以发现,数组位置0为空,虽然浪费了一个存储空间,但是当计算元素在数组位置的时候确非常方便:数组下标为X的元素的左子树的下标为2x,右子树的下标为2x+1。
其实实现一个堆非常简单,就是顺着元素所在的路径,向上或者向下对比然后交换位置
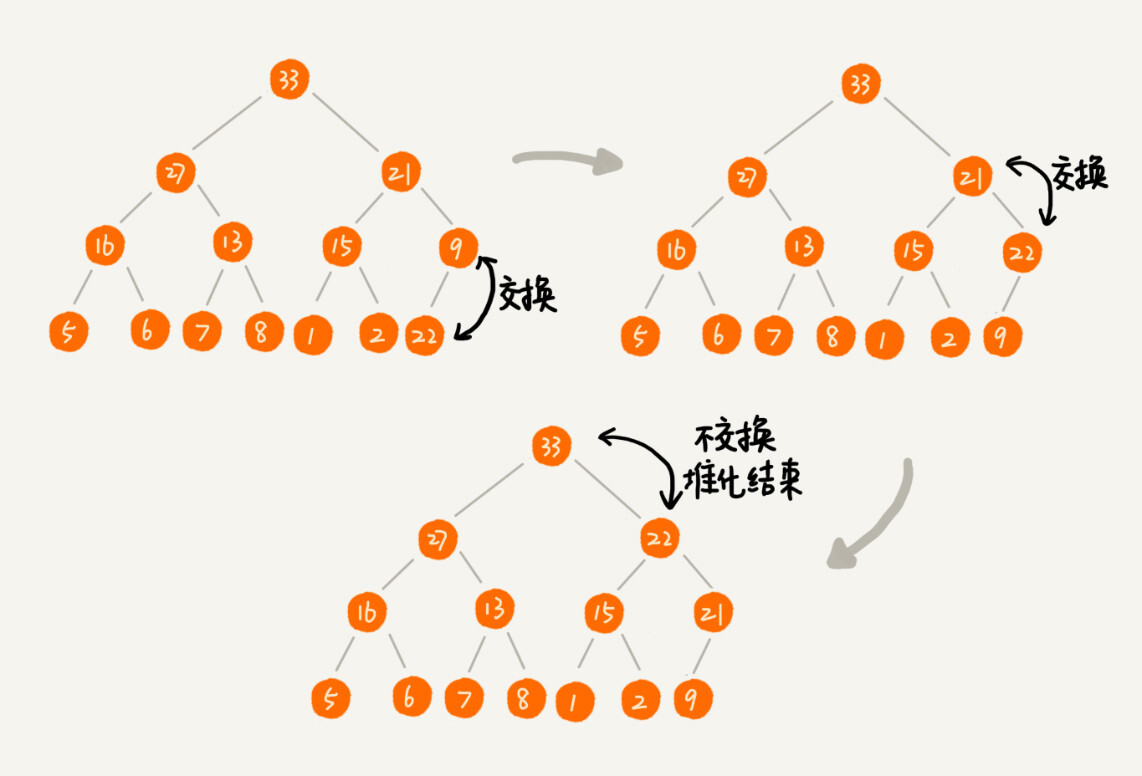
1. 添加元素
添加元素的时候我们习惯采用自下而上的调整方式来调整堆,我们在数组的最后一个空闲位置插入新元素,按照堆的下标上标原则查找到父元素对比,如果小于父元素的值(大顶堆),则互相交换。如图:
2. 删除最大(最小元素)
对于大顶堆,堆顶的元素就是最大元素。删除该元素之后,我们需要把第二大元素提到堆顶位置。依次类推,直到把路径上的所有元素都调整完毕。
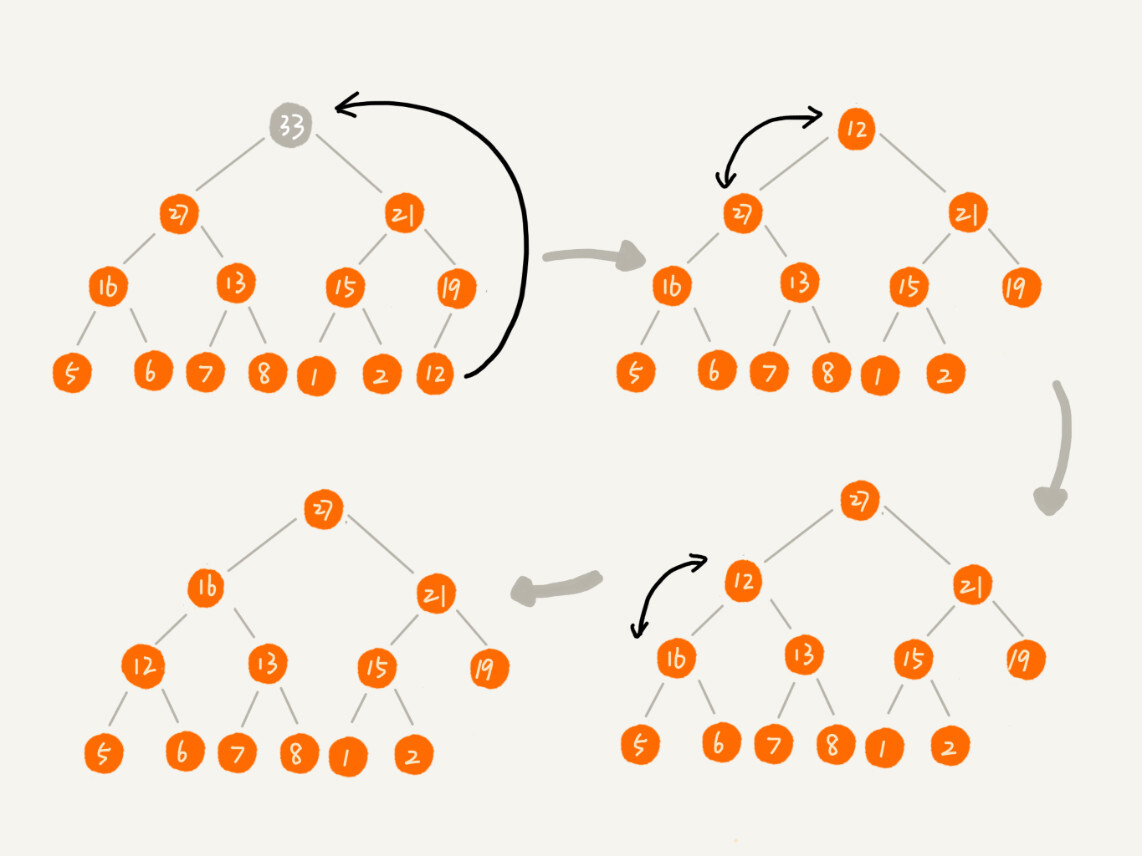

1. 小顶堆的顶部元素其实就是整个堆最小的元素,大顶堆顶部元素是整个堆的最大元素。这也是堆排序的最大优点,取最小元素或者最大元素时间复杂度为O(1)
2. 删除元素的时候我们要注意一点,如果采用自顶向下交换元素的方式,在很多情况下造成堆严重的不平衡(左右子树深度相差较大)的情况,为了防止类似情况,我们可以把最后一个元素提到堆顶,然后调整的策略,因为最后一个元素总是在最后一级,不会造成左右子树相差很大的情况。
3. 对于有重复元素的堆,一种解决方法是认为是谁先谁大,后进入堆的元素小于先进入堆的元素,这样在查找的时候一定要查彻底才行。另外一种方式是在堆的每个元素中存储一个链表,用来存放相同的元素,原理类似于散列表。不过这样在删除这个元素的时候需要特殊处理一下。
4. 删除堆顶数据和往堆中插入数据的时间复杂度都是 O(logn)。
5. 不断调整堆的过程其实就是排序过程,在某些场景下,我们可以利用堆来实现排序。

/// <summary>
/// 小顶堆,T类型需要实现 IComparable 接口
/// </summary>
class MinHeap<T> where T : IComparable
{
private T[] container; // 存放堆元素的容器
private int capacity; // 堆的容量,最大可以放多少个元素
private int count; // 堆中已经存储的数据个数
public MinHeap(int _capacity)
{
container = new T[_capacity + 1];
capacity = _capacity;
count = 0;
}
//插入一个元素
public bool AddItem(T item)
{
if (count >= capacity)
{
return false;
}
++count;
container[count] = item;
int i = count;
while (i / 2 > 0 && container[i].CompareTo(container[i / 2]) < 0)
{
// 自下往上堆化,交换 i 和i/2 元素
T temp = container[i];
container[i] = container[i / 2];
container[i / 2] = temp;
i = i / 2;
}
return true;
}
//获取最小的元素
public T GetMinItem()
{
if (count == 0)
{
return default(T);
}
T result = container[1];
return result;
}
//删除最小的元素,即堆顶元素
public bool DeteleMinItem()
{
if (count == 0)
{
return false;
}
container[1] = container[count];
container[count] = default(T);
--count;
UpdateHeap(container, count, 1);
return true;
}
//从某个节点开始从上向下 堆化
private void UpdateHeap(T[] a, int n, int i)
{
while (true)
{
int maxPos = i;
//遍历左右子树,确定那个是最小的元素
if (i * 2 <= n && a[i].CompareTo(a[i * 2]) > 0)
{
maxPos = i * 2;
}
if (i * 2 + 1 <= n && a[maxPos].CompareTo(a[i * 2 + 1]) > 0)
{
maxPos = i * 2 + 1;
}
if (maxPos == i)
{
break;
}
T temp = container[i];
container[i] = container[maxPos];
container[maxPos] = temp;
i = maxPos;
}
}
}//因为需要不停的从log文件读取内容,所以需要一个和log文件保持连接的包装
class LogInfoIndex : IComparable
{
//标志内容来自于哪个文件
public int FileIndex { get; set; }
//具体的日志文件内容
public LogInfo Data { get; set; }
public int CompareTo(object obj)
{
var tempInfo = obj as LogInfoIndex;
if (this.Data.Index > tempInfo.Data.Index)
{
return 1;
}
else if (this.Data.Index < tempInfo.Data.Index)
{
return -1;
}
return 0;
}
}
class LogInfo
{
//用int来模拟datetime 类型,因为用int 看的最直观
public int Index { get; set; }
public string UserName { get; set; }
} static void WriteFile()
{
int fileCount = 0;
while (fileCount < 10)
{
string filePath = $@"D:\log\{fileCount}.txt";
int index = 0;
while (index < 100000)
{
LogInfo info = new LogInfo() { Index = index, UserName = Guid.NewGuid().ToString() };
File.AppendAllText(filePath, JsonConvert.SerializeObject(info)+ "\r\n");
index++;
}
fileCount++;
}
}文件内容如下:
static void Main(string[] args)
{
int heapItemCount = 10;
int startIndex = 0;
StreamReader[] allReader = new StreamReader[10];
MinHeap<LogInfoIndex> container = new MinHeap<LogInfoIndex>(heapItemCount);
//首先每个文件读取一条信息
while(startIndex< heapItemCount)
{
string filePath = $@"D:\log\{startIndex}.txt";
System.IO.StreamReader reader = new System.IO.StreamReader(filePath);
allReader[startIndex] = reader;
string content= reader.ReadLine();
var contentObj = JsonConvert.DeserializeObject<LogInfo>(content);
LogInfoIndex item = new LogInfoIndex() { FileIndex= startIndex , Data= contentObj };
container.AddItem(item);
startIndex++;
}
//然后开始循环出堆,入堆
while (true)
{
var heapFirstItem = container.GetMinItem();
if (heapFirstItem == null)
{
break;
}
container.DeteleMinItem();
File.AppendAllText($@"D:\log\total.txt", JsonConvert.SerializeObject(heapFirstItem.Data) + "\r\n");
var nextContent = allReader[heapFirstItem.FileIndex].ReadLine();
if (string.IsNullOrWhiteSpace( nextContent))
{
//如果其中一个文件已经读取完毕 则跳过
continue;
}
var contentObj = JsonConvert.DeserializeObject<LogInfo>(nextContent);
LogInfoIndex item = new LogInfoIndex() { FileIndex = heapFirstItem.FileIndex, Data = contentObj };
container.AddItem(item);
}
//释放StreamReader
foreach (var reader in allReader)
{
reader.Dispose();
}
Console.WriteLine("完成");
Console.Read();
}
结果如下:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号