

JanusGraph : 图和图数据库的简介
JanusGraph:图数据库系统简介
图(graph)是《数据结构》课中第一次接触到的一个概念,它是一种用来描述现实世界中个体和个体之间网络关系的数据结构。
为了在计算机中存储图,《数据结构》中初步介绍了图的逻辑结构和存储结构。本文对图的定义、图的作用、图的逻辑结构、图的存储结构进行了回顾,继而引出了图数据库、主流的图数据库产品,最后重点介绍了JanusGraph图数据库的基本知识。
本文提纲:
1、图的简介
2、图数据库的概念
3、JanusGraph的简介
1、图的简介
============
参考《数据结构》,说明图的基本概念,举两个图的例子,图的存储方法。
图型结构中,节点间的关系可以是任意的,图中任意两个数据元素之间都可能相关。
2、图数据库的概念
==================
介绍清楚图数据库的基本概念,和目前主流的图数据库的简介
图数据库源起欧拉和图理论,也可称为面向/基于图的数据库,对应的英文是Graph Database。图数据库的基本含义是以“图”这种数据结构存储和查询数据,而不是存储图片的数据库。它的数据模型主要是以节点和关系(边)来体现,也可处理键值对。它的优点是快速解决复杂的关系问题。
图将实体表现为节点,实体与其他实体连接的方式表现为联系。我们可以用这个通用的、富有表现力的结构来建模各种场景,从宇宙火箭的建造到道路系统,从食物的供应链及原产地追踪到人们的病历,甚至更多其他的场景。
图形数据库是NoSQL数据库的一种类型,它应用图形理论存储实体之间的关系信息。最常见的例子,就是社会网络中人与人之间的关系。关系型数据库用于存储关系型数据的效果并不好,其查询复杂、缓慢、超出预期,而图形数据库的独特设计恰恰弥补了这个缺陷。 Google的图形计算系统名为Pregel。
目前主流的图数据库有:Neo4j,FlockDB,GraphDB,InfiniteGraph,Titan,JanusGraph,Pregel等。
图计算引擎多种多样。最出名的是有内存的、单机的图计算引擎Cassovary和分布式的图计算引擎Pegasus和Giraph。大部分分布式图计算引擎基于Google发布的Pregel白皮书,其中讲述了Google如何使用图计算引擎来计算网页排名。
3、JanusGraph简介
=================
3.1 JanusGraph简介
----------------------------
JanusGraph是一个可扩展的图数据库,可以把包含数千亿个顶点和边的图存储在多机集群上。它支持事务,支持数千用户实时、并发访问存储在其中的图。(JanusGraph is a scalable graph database optimized for storing and querying graphs containing hundreds of billions of vertices and edges distributed across a multi-machine cluster. JanusGraph is a transactional database that can support thousands of concurrent users executing complex graph traversals in real time.)
我们可以将图数据库系统的应用领域划分成以下两部分:
- 用于联机事务图的持久化技术(通常直接实时地从应用程序中访问)。这类技术被称为图数据库,它们和“通常的”关系型数据库世界中的联机事务处理(Online Transactional Processing,OLTP)数据库是一样的。
- 用于离线图分析的技术(通常都是按照一系列步骤执行)。这类技术被称为图计算引擎。它们可以和其他大数据分析技术看做一类,如数据挖掘和联机分析处理(Online Analytical Processing,OLAP)。
3.2 JanusGraph的发展历史
-------------------------------------
JanusGraph是2016年12月27日从Titan fork出来的一个分支,之后TiTan的开发团队在2017年陆续发了0.1.0rc1、0.1.0rc2、0.1.1、0.2.0等四个版本,最新的版本是2017年10月12日。
titan是从2012年开始开发,到2016年停止维护的一个分布式图数据库。最初在2012年启动titan项目的公司是Aurelius,2015年此公司被 DataStax(DataStax是开发apache Cassandra 的公司)收购,DataStax公司吸收了TiTan的图存储能力,形成了自己的商业产品DataStax Enterprise Graph。
TiTan开发者们希望把TitTan放到Apache Software Foundation下,不过,DataStax不愿意这样做(可能考虑到要保护自己的商业产品DataStax Enterprise Graph的技术优势吧,其实这点优势是从Titan来的),而且自从2015年9月DataStax收购了Titan的母公司后,TiTan一直处于停滞状态(应该是DataStax收购之后,忙于推出自己的商业产品DataStax Enterprise Graph,忙于整合Titan进自己的商业产品吧,可是Titan本身没有得到发展)。鉴于此,2016年6月,TiTan的开发者们fork了一个TiTan的分支(因为Titan已经属于DataStax了,所以他们必须另外弄一个商标),重命名为JanusGraph,并将其置于Linux Software Foundation下。
2017年4月6日发布了第一个版本0.1.0-rc1,目前最新版本是2017年10月12日发布的0.2.0版。
JanusGraph项目启动的初衷是“通过为其增加新功能、改善性能和扩展性、增加后端存储系统来增强分布式图系统的功能,从而振兴分布式图系统的开发”,JanusGraph从Apahce TinkerPop中吸收了对属性图模型(Property Graph Model)的支持和对属性图模型进行遍历的Gremlin遍历语言。(“reinvigorate development of the distributed graph system to add new functionality, improve performance and scalability, and maintain a variety of storage backends,JanusGraph incorporates support for the property graph model with the open source graph computing framework Apache TinkerPop and its Gremlin graph traversal language”.)
3.2 JanusGraph的功能(Benefits)
------------------------------------------------
JanusGraph最大的一个好处就是:可以扩展图数据的处理,能支持实时图遍历和分析查询(Scaling graph data processing for real time traversals and analytical queries is JanusGraph’s foundational benefit.)。
因为JanusGraph是分布式的,可以自由的扩展集群节点的,因此,它可以利用很大的集群,也就可以存储很大的包含数千亿个节点和边的图。由于它又支持实时、数千用户并发遍历图和分析查询图的功能。所以这两个特点是它显著的优势。
它支持以下功能:
(1)分布式部署,因此,支持集群。
(2)可以存储大图,比如包含数千亿Vertices和edges的图。
(3)支持数千用户实时、并发访问。(并发访问肯定是实时的,这个唉,没必要强调好像)
(4)集群节点可以线性扩展,以支持更大的图和更多的并发访问用户。(Elastic and linear scalability for a growing data and user base)
(5)数据分布式存储,并且每一份数据都有多个副本,因此,有更好的计算性能和容错性。(Data distribution and replication for performance and fault tolerance)
(6)支持在多个数据中心做高可用,支持热备份。(Elastic and linear scalability for a growing data and user base)
(7)支持各种后端存储系统,目前标准支持以下四种,当然也可以增加第三方的存储系统:
-
- Apache Cassandra®
- Apache HBase®
- Google Cloud Bigtable
- Oracle BerkeleyDB
(8)通过集成大数据平台,比如Apache Spark、Apache Giraph、Apache Hadoop等,支持全局图数据分析、报表、ETL
(9)支持geo(Gene Expression Omnibus,基因数据分析)、numeric range(这个的含义不清楚)
(10) 集成ElasticSearch、Apache Solr、Apache Lucene等系统后,可以支持全文搜索。
(11) 原生集成Apache TinkerPop图技术栈,包括Gremlin graph query language、Gremlin graph server、Gremin applications。
(12) 开源,基于Apache 2 Licence。
(13) 通过使用以下系统可以可视化存储在JanusGraph中的图数据:
-
- Cytoscape
- Gephi plugin for Apache TinkerPop
- Graphexp
- KeyLines by Cambridge Intelligence
- Linkurious
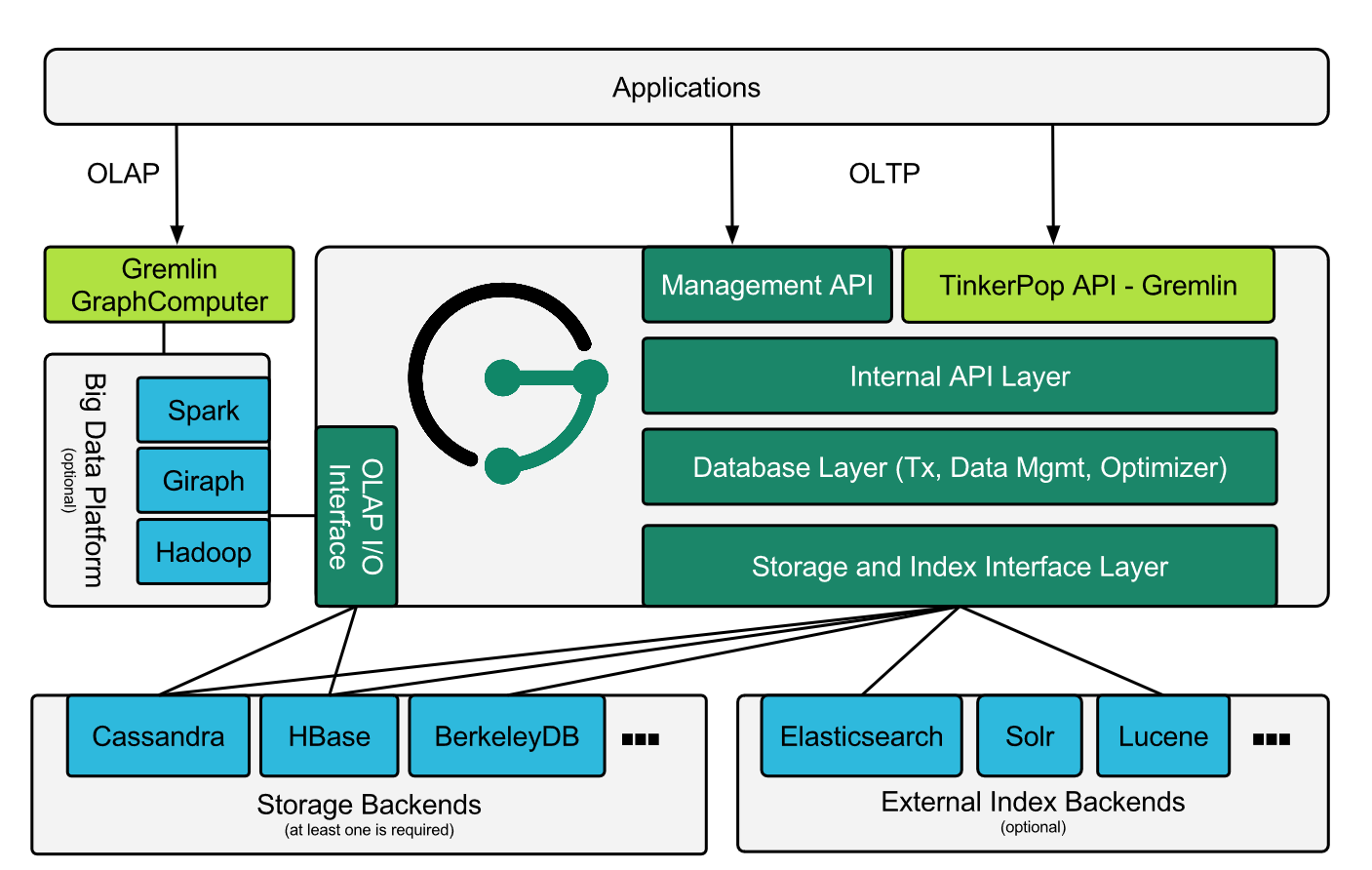
3.3. JanusGraph的体系结构(architecture,架构)
-------------------------------------------------------------------
JanusGraph是模块化的体系结构(JanusGraph has a modular architecture)。
它使用hadoop来做图的分析和图的批处理,使用模块化接口来做数据持久化、索引和客户端访问。
在JanusGraph和磁盘之间有多个后端存储系统和多个索引系统。(Between JanusGraph and the disks sits one or more storage and indexing adapters.)
它支持的外部存储系统,目前标准支持的有(当然也可以将第三方的存储系统作为JanusGraph的后端存储系统):
-
- Apache Cassandra
- Apache HBase
- Oracle Berkeley DB Java Edition
- Google Cloud BigTable
支持的外部索引系统:
-
- Elasticsearch
- Apache Solr
- Apache Lucene
体系结构图:
3.4 应用使用JanusGraph的方法
---------------------------------------------
作为一个数据库系统,它是要用来为应用程序存储数据用的,那么应用程序应该如何使用JanusGraph来为自己存储数据呢?
一般来说,应用程序可以通过两种不同的方式来使用JanusGraph:
(1)第一种方式:可以把JanusGraph嵌入到应用程序中去,JanusGraph和应用程序处在同一个JVM中。应用程序中的客户代码(相对JanusGraph来说是客户)直接调用Gremlin去查询JanusGraph中存储的图,这种情况下外部存储系统可以是本地的,也可以处在远程。
(2)第二种方式:应用程序和Janus Graph处在两个不同JVM中,应用通过给JanusGraph提交Gremlin查询给GremlinServer,来使用JanusGraph,因为JanusGraph原生是支持Gremlin Server的。(Gremlin Server是Apache Tinkerpop中的一个组件)。
3.5 JanusGraph的配置文件
----------------------------------------
JanusGraph集群包含一个、或者多个JanusGraph实例。每次启动一个JanusGraph实例的时候,都必须指定JanusGraph的配置。在配置中,可以指定JanusGraph要用的组件,可以控制JanusGraph运行的各个方面,还可以指定一些JanusGraph集群的调优选项。
最小的JanusGraph配置只需要指定一下JanusGraph的后端存储系统,也就是它的持久化引擎。
如果要JanusGraph支持高级的图查询,就需要为JanusGraph指定一个索引后端。
若果要提升JanusGraph的查询性能,就必须为JanusGraph指定缓存,指定性能调优的选项。
以上提到的后端存储系统、索引后端、缓存、调优选项等都可以在JanusGraph的配置文件中进行指定。默认情况下它的配置文件存放在JanusGraph_home/conf目录下。
在JanusGraph_home/conf目录下有一些JanusGraph的示例配置文件。
下面是一个JanusGraph的示例配置文件的内容,这个文件中为JanusGraph指定了cassandra作为后端存储引擎,并且指定了elasticsearch作为索引后端。
storage.backend=cassandra storage.hostname=localhost index.search.backend=elasticsearch index.search.hostname=100.100.101.1, 100.100.101.2 index.search.elasticsearch.client-only=true
3.6 JanusGraph配置文件的加载方法
----------------------------------------------------
JanusGraph的配置文件如何加载呢?
(1)对于单独安装的JanusGraph,可以在Gremlin中使用JanusGraphFactory类的方法来加载配置文件
graph = JanusGraphFactory.open('path/to/configuration.properties')
(2)对于嵌入到应用中的JanusGraph来说,应用可以直接调用JanusGraph的公共API,只要在应用中调用JanusGraph的JanusGraphFactory就可以加载配置文件了
(3)还可以在JanusGraphFactory中使用简写来加载配置。
graph = JanusGraphFactory.open('cassandra:localhost');
graph = JanusGraphFactory.open('berkeleyje:/tmp/graph');
3.7 JanusGraph分布式集群的安装方法
------------------------------------------------------
JanusGraph作为一个图数据库系统,其实还是比较复杂的,它的安装可以是很简单的单机安装,也可以是很复杂的分布式安装,最不可理解的是官网(janusgraph.org)上没有专门介绍安装的文档。这里的安装方法是从IBM Developer works搜索来的,下面着重介绍单机安装,分布式集群的安装较为复杂,目前还没有时间做,以后在做吧,任务在即。
从JanusGraph的架构图可以看出,Janus的安装需要以下组件:
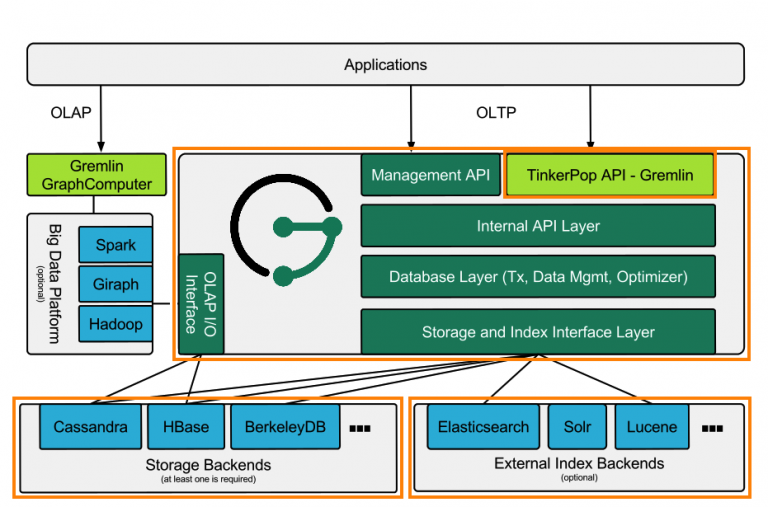
(1)外部存储系统,上图左下的橙色方框,JP也集成了一个Cassandra,可以用于单一数据库使用
(2)外部索引系统,上图右下的橙色方框,JP本身集成了一个ES,这个是可选的。
(3)启动JanusGraph Server,上图中部的橙色方框,它是从Apache Tinkpop项目中的Gremlin Server来的。
(4)启动Gremlin客户端去连接JanusGraph Server,上图中部橙色方框中的小框Tinkpop API-Gremlin指的是Gremlin console这个客户端是调用了Tinkpop API去访问JanusGraph Server的。
由以上的架构分析可以看出,安装JP的过程中最少要安装一个外部存储系统。这里按照以下顺序安装:
1、安装后端存储系统。这里下载了Cassandra,同时启动Cassandra和thrift。
$cassandra_home/bin/cassandra
$cassandra_home/bin/nodetool enablethrift #开启thrift,或者也可以在启动cassandra之前,在conf/cassandra.yaml中修改start_rpc选项的值为true,那么启动cassandra同时就启动了thrift了,不需要单独启动thrift
2、安装JanusGraph。它的安装很简单,就是解压即可。
$janusgraph_home/bin/gremlin-server.sh #启动JanusGraph Server
$janusgraph_home/bin/gremlin.sh #启动gremlin console
3、在gremlin console中输入gremlin query language,新建图数据库,在其中存入vertexs,edges、vertex labels、edge labels、property key等元素,来存入图的组成元素。
3.8 JanusGraph的命令接口使用方法
-------------------------------------------
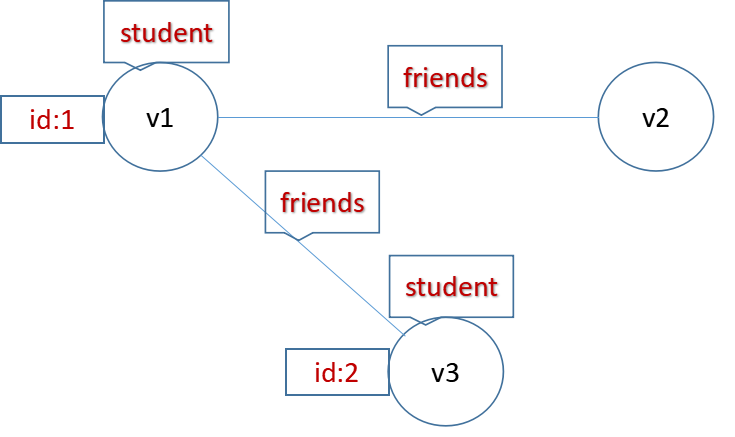
如下的命令会创建一个图,如下所示:
它有3个顶点,2个边
3 vertex:
v1: label student property id: 1
v2: no label, no property
v3: label studentproperty id: 2
2 edges with label friends
graph = JanusGraphFactory.open('conf/janusgraph-cassandra.properties');
mgmt = graph.openManagement();
student = mgmt.makeVertexLabel('student').make();
friends = mgmt.makeEdgeLabel('friends').make();
mgmt.commit();
v1 = graph.addVertex(label, 'student');
v1.property('id', '1');
v2 = graph.addVertex();
v3 = graph.addVertex(label, 'student');
v3.property('id', '2');
graph.tx().commit();
v1.addEdge('friends', v2);
v1.addEdge('friends', v3);
graph.tx().commit();
graph.traversal().V();
graph.traversal().V().values('id');
graph.traversal().E();
3.9 用Java访问JanusGraph中的图
-------------------------------------------------
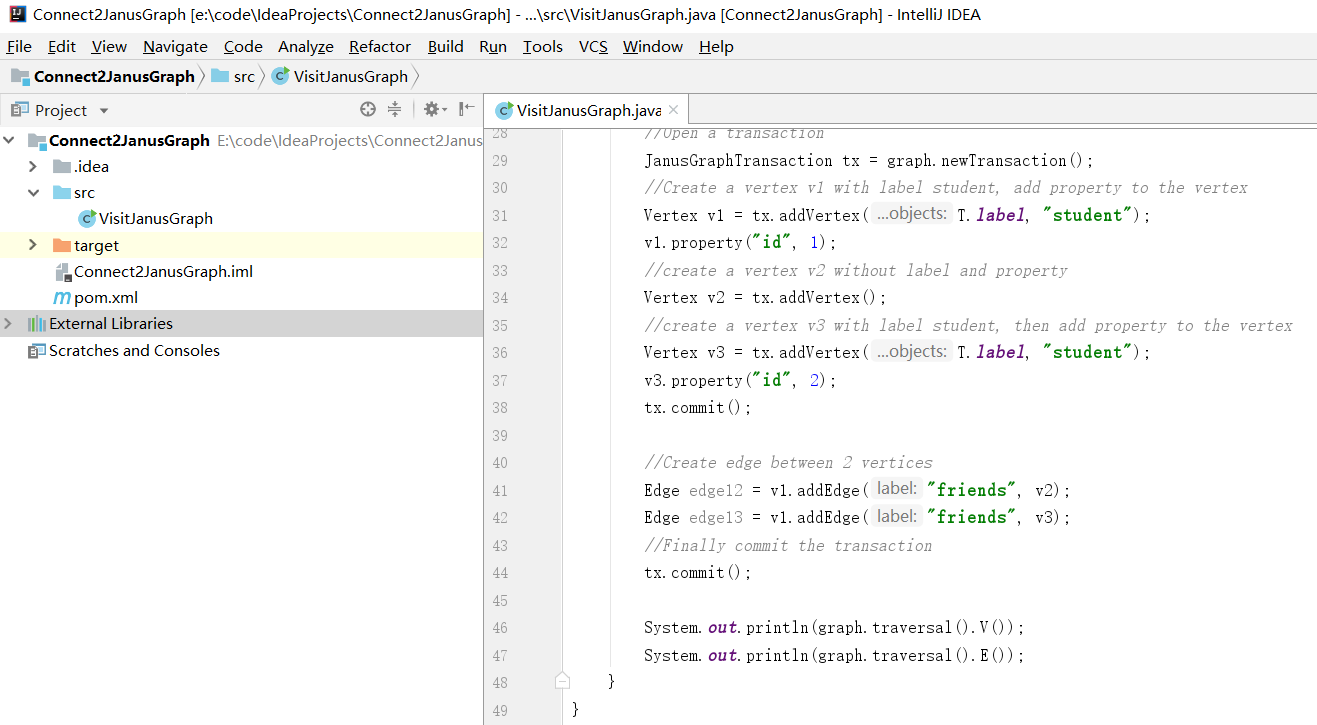
如下为项目结构:
pom.xml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>cn.cnic</groupId> <artifactId>Connect2JanusGraph</artifactId> <version>0.0.1-SNAPSHOT</version> <name>Connect2JanusGraph</name> <description>a project to connect JanusGraph using java code</description> <dependencies> <dependency> <groupId>org.janusgraph</groupId> <artifactId>janusgraph-core</artifactId> <version>0.1.1</version> </dependency> <dependency> <groupId>org.janusgraph</groupId> <artifactId>janusgraph-cassandra</artifactId> <version>0.2.0</version> </dependency> </dependencies></project> |
VisitJanusGraph.java源代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | import org.janusgraph.core.JanusGraph;import org.janusgraph.core.JanusGraphFactory;import org.janusgraph.core.JanusGraphTransaction;import org.apache.tinkerpop.gremlin.structure.Edge;import org.apache.tinkerpop.gremlin.structure.T;import org.apache.tinkerpop.gremlin.structure.Vertex;public class VisitJanusGraph { public static void main(String[] args) { createVertexAndEdge(); } public static void createVertexAndEdge() { //First configure the graph JanusGraphFactory.Builder builder = JanusGraphFactory.build(); builder.set("storage.backend", "cassandrathrift"); builder.set("storage.hostname", "192.168.192.128"); builder.set("storage.port", "9160"); //ip address where cassandra is installed //builder.set("storage.username", “cassandra”); //buder.set("storage.password", “cassandra”); //builder.set("storage.cassandra.keyspace", "testing"); //open a graph database JanusGraph graph = builder.open(); //Open a transaction JanusGraphTransaction tx = graph.newTransaction(); //Create a vertex v1 with label student, add property to the vertex Vertex v1 = tx.addVertex(T.label, "student"); v1.property("id", 1); //create a vertex v2 without label and property Vertex v2 = tx.addVertex(); //create a vertex v3 with label student, then add property to the vertex Vertex v3 = tx.addVertex(T.label, "student"); v3.property("id", 2); tx.commit(); //Create edge between 2 vertices Edge edge12 = v1.addEdge("friends", v2); Edge edge13 = v1.addEdge("friends", v3); //Finally commit the transaction tx.commit(); System.out.println(graph.traversal().V()); System.out.println(graph.traversal().E()); }} |
以上的源代码创建了如下的图:
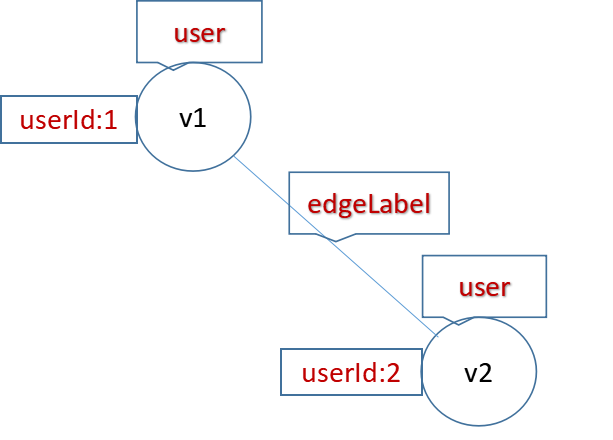
至此,使用JanusGraph提供的JavaAPI访问JG的Java程序就算是介绍完了。
进一步,探索JanusGraph作为一个gdbms的其他功能,需要认真阅读它的官方文档,配置、集群、HA、Failure and Failover等内容。
再深入想要对JanusGraph的源代码进行阅读,并为它贡献代码,得认真的阅读JanusGraph Development Process(https://docs.janusgraph.org/latest/development-process.html)的内容。
参考资料:
1、严蔚敏,《数据结构》
2、百度百科-图形数据库,https://baike.baidu.com/item/图形数据库/5199451?fr=aladdin
3、JanusGraph picks up where TitanDB left off,https://www.datanami.com/2017/01/13/janusgraph-picks-titandb-left-off/
4、JanusGraph官方网站,http://janusgraph.org/
5、Janus集群搭建,http://www.itboth.com/d/YVvEja6jueA3/janusgraph-cassandra
6、JanusGraph with Cassandra,https://www.bluepiit.com/blog/janusgraph-with-cassandra/
7、图数据库——大数据时代的高铁,https://blog.csdn.net/heyc861221/article/details/80128421
8、Getting started with JanusGraph, Part 1 – Deployment,https://developer.ibm.com/dwblog/2018/whats-janus-graph-learning-deployment/
9、Part VII. JanusGraph Development Process,https://docs.janusgraph.org/latest/development-process.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通