

express项目的目录结构
express项目的目录结构
提纲
1、用express命令或者express -e命令生成项目后,产生的默认目录结构
2、自己添加的代码目录
用node建立一个express的后端项目,一般使用express-generator生成项目后,会自动产生一个目录结构,但是这个自动生成的目录结构还需要增加一些内容,主要是后端代码的分类目录。具体情况记录如下。
1、用express命令或者express -e命令生成项目后,产生的默认目录结构
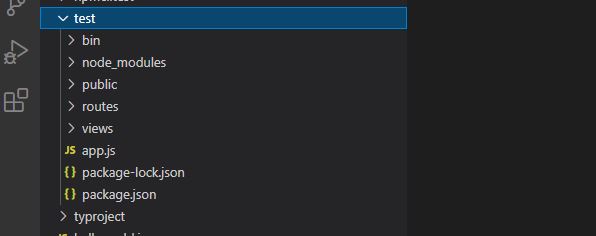
接下来介绍一下这些目录的作用。
1.1 bin目录
该目录下存放的是一些配置文件如:项目启动的端口号等
1.2 public目录
存放的是一些公共的样式。这里可能有些人会有疑问,这里面为什么会用到样式呢?我这是用Node做后端的呀,对!理解的没错。
但是,有时候我们可能会使用到服务端渲染,所以,这里才会有样式的存在。
1.3 routes目录
顾名思义:routes下面的是所有的路由配置(也就是,通常后端口中所说的接口)。
路由文件如下:
var express = require('express');
var router = express.Router();
var usersController = require('../controller/users');
/* GET users listing. */
router.get('/getList', usersController.list);
router.get('/login', usersController.login);
router.post('/register', usersController.register);
router.get('/delete', usersController.deleteUser);
router.post('/update', usersController.updateUser);
module.exports = router;
router.get():即前端用get的方法请求接口
router.post():即前端用post的方法请求接口
请求某个接口之后会调用一个对应的函数去处理相对应的业务逻辑,拿上述代码的router.get('/getList', usersController.list)来说,当前端请求该接口之后会去调用usersController.list这个方法,看一下userController.list这个方法吧
const list = async (req, res) => {
const { pageSize = 5, pageNum = 1 } = req.query;
const offset = parseInt(pageSize) * (pageNum - 1);
const limit = parseInt(pageSize);
const users = await usersModel.findAndCountAll({ offset, limit });
const data = {
success: true,
data: users
}
res.send(data)
}
该函数的两个参数分别是request和response分别是请求对象和响应对象。上面的代码res.send(data)即是将从数据库中查询的数据以json的形式返回给前端。关于findAndCountAll是sequelize提供的。这是一组封装好的ORM为了方便的查询数据库,读者可自行google查询用法
1.4 views目录
该目录是服务端渲染的html或jade文件的存放位置,不过需要在app.js中来指定该目录。
app.set('views', path.join(__dirname, 'views'));
1.5 app.js
该文件是项目的根文件包括一些路由的引用配置,统一的错误处理等。
2、自己添加的代码目录
代码目录结构按照MVC模式进行创建,因为public、views、app.js、package.json等文件已经有了,所以,只需要新增controller、model文件夹,结构如下:
- controller 控制层 -新增
- views 视图层 - 默认
- model 模型层(用于管理MongoDB文档对象)- 新增
- public 静态资源目录 - 默认
- app.js 入口文件 - 默认
- package.json 依赖管理文件 - 默认
上面的目录结构需要有一点说明,public是静态资源目录,这里有个疑问,后端项目为什么需要静态资源文件呢?view是视图层,后端项目为啥还要视图层呢?
入口文件
app.js 为入口文件,代码如下:
let express = require('express')
let crl = require('./controller')
let app = express()
//配置静态资源目录
app.use(express.static('./public'))
//配置模板所在目录
app.set('views','./views')
//配置ejs模板引擎
app.set('view engine','ejs')
//配置路由
app.get('/add',crl.getAdd)
app.post('/add',crl.postAdd)
app.listen(3000)
控制层
/controller/index.js 为控制层,文件代码如下:
//添加功能,get请求
function getAdd(req,res){
//接收get请求参数
let {name} = req.query
res.render('index',{msg: name})
}
//添加功能,post请求
function postAdd(req,res){
//接收post请求参数
let {name} = req.body
res.render('index',{msg: name})
}
module.exports = {
getAdd,
postAdd
}
视图层
/views/index.ejs 为视图层,文件代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div><%=msg %></div>
<h1>这是视图层</h1>
</body>
</html>
模型层model
model是MVC分层中的M层,主要是用来建立对照模型,即使用代码模型与数据库中数据表的字段一一对应。
那怎么做呢?其实前面已经提到过了就是使用sequelize
// 安装sequelize
npm install sequelize
// 在项目根目录下建立model文件夹,并建立users.js文件
var Sequelize = require('sequelize');
var sequelize = new Sequelize(
'user_info', // 数据库名
'limingyang', // 用户名
'limingyang', // 密码
{
dialect: 'mysql', // 数据库类型
host: 'mysql56.rdsmscdhekdxy4f.rds.bj.baidubce.com', // 数据库地址,本人用的是百度云的数据库
port: '3306' // 端口号
}
)
// 定义表的模型(对应数据库中users数据表)
var Users = sequelize.define('users',
{
id: { type: Sequelize.INTEGER, primaryKey: true, autoIncrement: true },
user_name: {
type: Sequelize.STRING(50)
},
user_pass: {
type: Sequelize.STRING(50)
},
},
{
freezeTableName: true,
timestamps: false // 是否自定生成并查询时间戳
}
);
Users.sync();
module.exports = Users;
定义表的模型时候需要注意的是如果你的表中没有createAt或者updateAt字段的时候 需要设置timestamps: false,否则在请求数据的时候会报错。
Controller中使用model中的代码:
controller是MVC分层的C层主要用来处理业务逻辑,即数据库的查询等相应的逻辑操作放在controller层中去完成。上面已经说过controller的简单使用,接下来主要阐述一些细节的东西。
我们在做一些业务逻辑处理的时候经常会操作到数据库,接下来说一下sequelize的用法,举一个简单的例子
const list = async (req, res, next) => {
const { pageSize = 5, pageNum = 1 } = req.query;
const offset = parseInt(pageSize) * (pageNum - 1);
const limit = parseInt(pageSize);
const users = await usersModel.findAndCountAll({ offset, limit });
const data = {
success: true,
data: users
}
res.send(data)
}
该list函数是一个简单的分页查询功能。值得一说的是await usersModel.findAndCountAll({ offset, limit });
当使用usersModel.findAndCountAll({ offset, limit })去操作数据库的时候返回的是promise对象,这样就可以使用async await语法来拿到请求回来的数据并返回到前端了。
配置项目启动
在 package.json 文件中添加如下配置:
{
"scripts": {
"start": "node app.js"
}
}
配置完成后执行 npm start 命令启动项目,在浏览器地址栏访问 http://localhost:3000/add?name=xxx ,即可执行添加的路由
参考资料:
1、express框架快速入门教程,https://blog.csdn.net/qq_26087315/article/details/113783288?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_title~default-1.no_search_link&spm=1001.2101.3001.4242
2、Express框架的使用教程,这篇文章中有很重要的内容,https://blog.csdn.net/qq_37506861/article/details/85008834?utm_medium=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~default-1.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~CTRLIST~default-1.no_search_link


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通