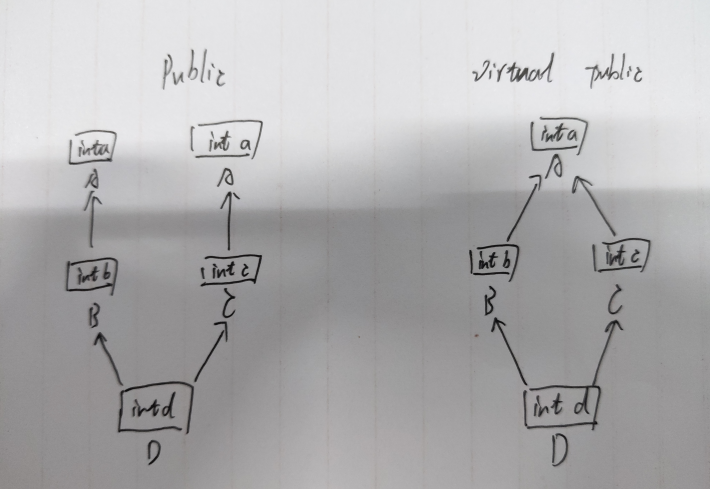
虚继承的汇编分析
# 环境为32-bit Debug
# 基础代码如下
class A { public: int a; public: A(int a_) : a(a_) {}; }; class B : public A { public: int b; public: B(int a_, int b_) : b(b_), A(a_) {}; }; class C : public A { public: int c; public: C(int a_, int c_) : c(c_), A(a_) {}; }; class D : public B, public C { public: int d; public: D(int a_, int b_, int c_, int d_) : d(d_), C(a_, c_), B(a_, b_), A(a_) {}; };
首先说一下为什么会去探究这个问题
1. 自从学了汇编之后, 就习惯性的去看内存的里的数字, 然后就发现了一个出乎意料的内存分配, 有两个ptr, 并且里面的数值也是比较奇怪的.
2. 感觉虚继承完全可以被替代(实际上并不是这样), 白白给程序员增加困难
3. 学c得站在编译器的角度去理解嘛, 要不总有种似懂非懂的感觉
在开始实验之前我们先了解几个不证自明的观点
1. 指针可以指向任何一块允许指向的内存, 不同类型的指针(例如 "int*", "double* "), 存储本质上没有任何不同, 唯一的区别只在于在一些对指针的操作, 例如:
a. int* Pint, 那么其在做加减运算时, 是以DWORD为基准
b. void (*Pfun) (void), 其可以将数据区的数据当作代码区的数据一样读取.
c. char (*Parr)[2][3], Parr+2(从Parr的地址开始向后移动12bytes), *Parr+2(从Parr的地址 开始向后移动6bytes), **Parr+2(从Parr内的地址开始向后移动2bytes)
总之, 编译器对于不同类型的指针, 会给出固定的01代码
2. 堆栈图下面为高位地址, 上面为低位地址, 并且一个格子为一个DWORD
3. 只要花时间, c里面不存在不可以理解的事情, 并且这些安排都是最好的安排
如果去试试上面的代码, 会发现代码报错, 理由是A类与D类没有关系
这个很好理解, 我们甚至可以从中脑补出D的内部的数据分配
D d(1, 2, 3, 4);
看看d的内存长啥样吧
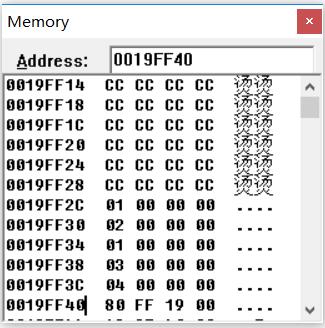
堆栈图如下

这个很好理解, 也很符合在没有引入虚继承之前我们的想象, 但这样分配内存有一些问题:
1. 会引出二义性的问题, 但这个是可以解决的, 在变量前面加入类的限定符
2. 更大的问题在于:
a. "C* pc"时, 我们可以让pc指向0x19ff34, 他可以自如的访问
b. 但"B* pb"时, 我们也很容易里它指向0x19ff2c, 那他如何去访问D::d呢, 你或许也能相处解决办法: 在pb->d时让编译器自己算出offset. 但如果我下次的B有不同的数据分布, 你难道要让编译器一个个算, 那显然满足不了我一个操作就对应一个01代码的唯一性, 会增加做编译器的难度, 甚至我觉得做不出来; 因此C++标准委员会创造了虚继承, Microsoft的工程师们也为其想出了一个聪明的办法来实现虚继承, 先给出这个聪明的办法
pb->a = 0x11; __asm{ mov eax, dword ptr [ebp - 0x1c] mov ecx, dword ptr [eax] mov edx, dword ptr [ecx + 4] mov eax, dword ptr [ebp - 0x1c] mov dword ptr [eax + edx], 11 }
*根据创建变量的不同中offset会有不同, 这段意思的大意就是我从[ebp - 0x1c]拿出一个地址(PA), 把这个地址里的数据作为下一个地址(PB), 把这个地址的下一个格子的数据(C)拿出来, 然后将C与PA相加, 算出一个新的地址(PD), 这个PD就是a的地址; 我们从这段代码中可以猜出拥有虚继承的对象d的内存中不止存了一般的数据, 还存了地址, 那下一步我们看看这些地址里存的是啥
1 class A { 2 public: 3 int a; 4 public: 5 A(int a_) : a(a_) {}; 6 }; 7 8 class B : virtual public A { 9 public: 10 int b; 11 public: 12 B(int a_, int b_) : b(b_), A(a_) {}; 13 }; 14 15 class C : virtual public A{ 16 public: 17 int c; 18 public: 19 C(int a_, int c_) : c(c_), A(a_) {}; 20 }; 21 22 class D : public B, public C { 23 public: 24 int d; 25 public: 26 D(int a_, int b_, int c_, int d_) : d(d_), 27 C(a_, c_), B(a_, b_), A(a_) {}; 28 };
沿用上面的方法, 先创建拥有虚继承的d
D d(1, 2, 3, 4);
看看他的内存分配

很显然里面有两个地址, 堆栈图如下:
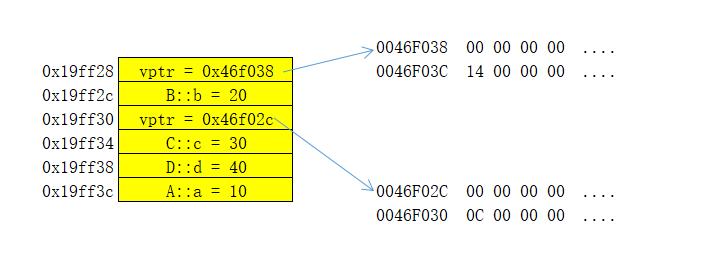
(a, b, c, d应该是1, 2, 3, 4; 打错了, 不好意思)
有意思的是vptr指向的地址存的是0, 但+4的地址存了一个有意义的数, 记得前面那段汇编有个+4, 那个就是去把0x14(十进制的20)读出来, 巧的是, 指针的地址和他指向内存的数据相加刚好都指向A::a, 到这我们应该很容易想明白, 编译器在对待虚继承时, 把虚基类的数据在派生类的偏移先算好, 存在了一块特定的区域, 基类指针去访问虚基类的数据时通过那块内存的数据去得到地址之差
总的来说, 虚继承拥有一般继承所不具备的优点, 和其存在的必要性, 因此他还是很重要的.
下面附上二者的结构图