

钛媒体是一家专注于科技领域的媒体机构,每天都会发布大量的科技新闻和资讯。通过爬取钛媒体的快报,您可以了解到最新的科技动态和趋势,为自己的学习和工作提供参考和帮助。在本次教学中,我将为大家讲解如何使用Python的爬虫框架Scrapy来编写一个可以自动爬取钛媒体快讯的爬虫,并将获取到的数据保存在本地文件中。让我们开始吧! 我们要用到多个库。
-
datetime: 是Python内置的日期和时间处理模块,可以用于处理日期和时间相关的操作,例如日期的比较、格式化等。
-
time: 是Python内置的时间处理模块,提供了一些时间相关的函数,例如获取当前时间、暂停程序等。
-
BeautifulSoup: 是一个优秀的Python HTML解析库,可以快速地从HTML文档中提取数据,具有很好的容错性和可读性。
-
selenium: 是一个自动化浏览器测试工具,可以模拟用户在浏览器中的行为,例如点击、输入等操作。它可以用于爬虫中模拟登录、获取动态生成的数据等操作。
-
ChromeDriverManager: 是一个Python库,可以自动下载Chrome浏览器的驱动程序,使得我们可以使用selenium来自动化控制Chrome浏览器。
-
os.path: 是Python内置的文件和目录操作模块,提供了一些函数用于操作文件和目录,例如检查文件是否存在、获取文件路径等。
-
WebDriverWait: 是selenium提供的等待模块,可以设置等待时间和条件,直到满足条件或超时为止。
-
By: 是selenium提供的一个枚举类,可以用于定位元素的方式,例如按照id、class、标签名等定位。
-
expected_conditions: 是selenium提供的一个模块,可以用于设置等待的条件,例如等待元素可见、等待元素可点击等。
-
pandas: 是一个Python数据处理库,可以用于处理和分析数据,例如读取和写入各种格式的数据文件、数据清洗和转换、数据统计和分析等。在爬虫中,它通常用于将获取到的数据保存为Excel、CSV等格式的文件。
import datetime import time from bs4 import BeautifulSoup from selenium import webdriver from webdriver_manager.chrome import ChromeDriverManager import os.path from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC import pandas as pd
钛媒体快报的加载方式比较简单,下拉即可,但我们会发现,如果不断下拉,最终会加载出前一天的数据。这不符合我们的要求,不过,网站提供了日期选项。因此我们先设定好日期。
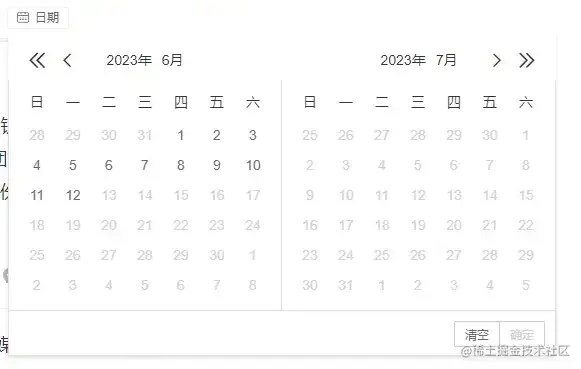
我们可以用class属性来确定日期按钮,在点击今天的日期,需要注意的是,我们需要利用日期函数来取得今天的日期并调整格式,这里我还设定来等待页面加载完成再点击按钮。


today = datetime.date.today()
today = today.strftime('%Y-%#m-%#d')
WebDriverWait(driver, wait_time).until(
EC.element_to_be_clickable((By.CLASS_NAME, "date_search_render"))
).click()
WebDriverWait(driver, wait_time).until(
EC.element_to_be_clickable((By.XPATH, "//td[@lay-ymd='%s']" % today))
).click()
WebDriverWait(driver, wait_time).until(
EC.element_to_be_clickable((By.XPATH, "//td[@lay-ymd='%s']" % today))
).click()
WebDriverWait(driver, wait_time).until(
EC.element_to_be_clickable((By.XPATH, '//span[@lay-type="confirm"]'))).click()
然后,我们模拟下拉页面来获取信息,我的思路是先加载完今天的快报,然后再对信息进行提取,而在下拉页面的过程中,我们发现当当日快讯加载完毕,继续下拉会出现没有相关内容的提示,我们可以以此判断信息是否加载完成。
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 滚动到底
time.sleep(2) # 等待页面加载
try:
element = driver.find_element_by_xpath("//p[text()='没有相关内容']")
print("爬取完成,正在下载")
break
except:
pass
最后,我们找到包含信息的标签并储存到excel表格中。
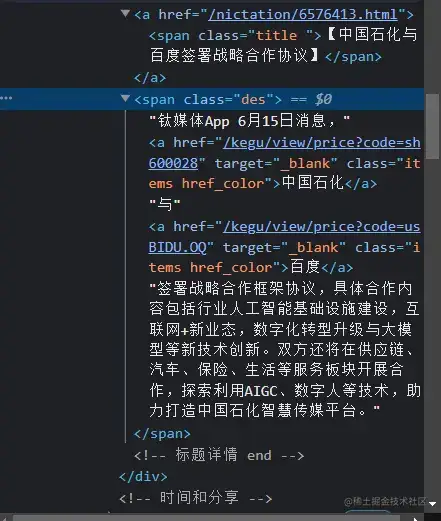
def save_page(driver):
n = 1
soup = BeautifulSoup(driver.page_source, 'html.parser')
articles = soup.find_all('div', class_='content_mode')
# print(articles)
for article in articles:
title = article.find("span",class_="title").get_text()
news_t = article.find("span",class_="time").get_text()
summary = article.find("span",class_="des").get_text()
data = {"序号":n,"标题":[news_t],"简介":[summary]}
print(news_t)
df = pd.read_excel('钛媒体%s快讯.xlsx'%datetime.date.today())
data = pd.DataFrame(data)
df = df.append(data, ignore_index=True)
df.to_excel('钛媒体%s快讯.xlsx'%datetime.date.today(), index=False)
n = n + 1
print(title)
n = n + 1
最后是完整代码。
# -*- codeing = utf-8 -*-
import datetime
import time
from bs4 import BeautifulSoup
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
import os.path
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
import pandas as pd
if os.path.exists('钛媒体%s快讯.xlsx'%datetime.date.today()):
os.remove('钛媒体%s快讯.xlsx'%datetime.date.today())
if not os.path.isfile('钛媒体%s快讯.xlsx'%datetime.date.today()):
df = pd.DataFrame()
df.to_excel('钛媒体%s快讯.xlsx'%datetime.date.today(), index=False)
page_num = 3
def get_article_info(url):
driver.get(url)
pages(driver,page_num)
save_page(driver) #储存数据
def save_page(driver):
n = 1
soup = BeautifulSoup(driver.page_source, 'html.parser')
articles = soup.find_all('div', class_='content_mode')
# print(articles)
for article in articles:
title = article.find("span",class_="title").get_text()
news_t = article.find("span",class_="time").get_text()
summary = article.find("span",class_="des").get_text()
data = {"序号":n,"标题":[news_t],"简介":[summary]}
print(news_t)
df = pd.read_excel('钛媒体%s快讯.xlsx'%datetime.date.today())
data = pd.DataFrame(data)
df = df.append(data, ignore_index=True)
df.to_excel('钛媒体%s快讯.xlsx'%datetime.date.today(), index=False)
n = n + 1
print(title)
n = n + 1
# wb.save("钛媒体%stmt快讯.xls"%datetime.date.today())
def pages(driver,page_num):
today = datetime.date.today()
today = today.strftime('%Y-%#m-%#d')
WebDriverWait(driver, wait_time).until(
EC.element_to_be_clickable((By.CLASS_NAME, "date_search_render"))
).click()
WebDriverWait(driver, wait_time).until(
EC.element_to_be_clickable((By.XPATH, "//td[@lay-ymd='%s']" % today))
).click()
WebDriverWait(driver, wait_time).until(
EC.element_to_be_clickable((By.XPATH, "//td[@lay-ymd='%s']" % today))
).click()
WebDriverWait(driver, wait_time).until(
EC.element_to_be_clickable((By.XPATH, '//span[@lay-type="confirm"]'))).click()
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 滚动到底
time.sleep(2) # 等待页面加载
try:
element = driver.find_element_by_xpath("//p[text()='没有相关内容']")
print("爬取完成,正在下载")
break
except:
pass
return driver
if __name__ == "__main__":
try:
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--window-size=1920,1080")
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(ChromeDriverManager().install(),options=chrome_options)
wait_time =10
url = 'https://www.tmtpost.com/nictation'
get_article_info(url)
driver.quit()
except:
print("请重试")
github地址:https://github.com/zhangaynami/python-study-and-project/tree/aynami1/%E7%88%AC%E8%99%AB/%E9%92%9B%E5%AA%92%E4%BD%93
