MySQL索引(一)
雨喝醉了,小路摇摇晃晃,倒在我怀里
1,B 树和 B+ 树之间的区别是什么?
2,Innodb 中的 B+ 树有什么特点?
3,什么是 Innodb 中的 page?
4,Innodb 中的 B+ 树是怎么产生的?
5,什么是聚簇索引?
6,Innodb 是如何支持范围查找能走索引的?
7,什么是联合索引?对应的 B+ 树是如何产生的?
8,什么是最左前缀原则?
9,为什么要遵守最左前缀原则才能利用到索引?
10,什么是索引条件下推?
11,什么是覆盖索引?
12,有哪些情况会导致索引失效?
一,索引是帮助 MySQL 高效获取数据的 排好序 的 数据结构
索引数据结构:二叉树,红黑树,Hash表,B-Tree,B+Tree
二叉树:当索引列为递增的数据时,二叉树索引会变成线性链表,效率没有提升(包括红黑是的缺点)。
红黑树:当数据量过大时,树太高,效率不够高。
Hash表:精准查询效率很高,但是不支持范围查询。
- 对索引的 key 进行一次 hash 计算就可以定位出数据存储的位置
- 很多时候 Hash 要比 B+ 树索引更高效
- 仅能满足 ‘=’,‘IN’,不支持范围查询。
- hash 冲突问题
B-Tree:不能很好的支持范围查询(范围查询的效率没有 B+Tree 高)。
二,B- 树和B+ 树的结构
B-Tree
叶节点具有相同的深度,叶节点的指针为空。
所有索引元素不重复。
节点中的数据索引从左到右递增排列。
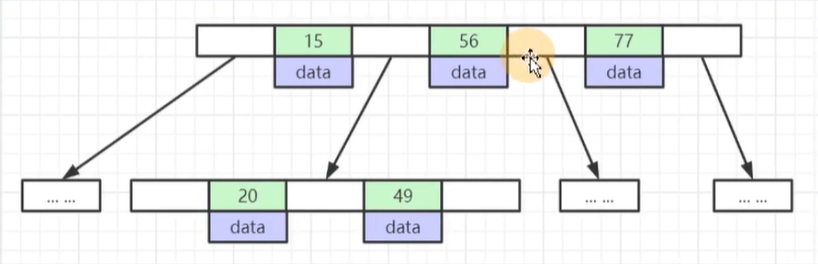
B+Tree
非叶子节点不存储 data,只存储索引(冗余),可以放更多的索引。
叶子节点包含所有索引字段。
叶子节点用指针连接,提高区间访问的性能。
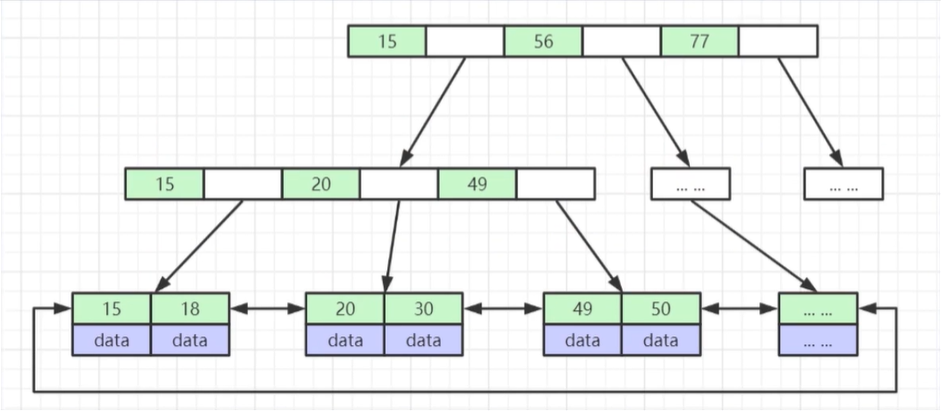
三,B+ 树高度为 3 时能存储多少数据
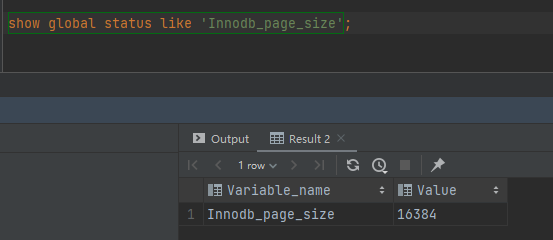
MySQL为每个节点分配了 16kb 的空间
假设主键为 bigint 类型,每个占 8b,由于每个索引后面还要存储一个地址,MySQL为这个地址分配了 6b 的空间,此时一个节点大约存放 16kb / (8b + 6b) ≈ 1142 个索引。
同理此时第二层约为 1142 个节点
由于第三层节点每个索引带数据(Innodb 存储引擎为聚簇索引,MYISAM 存储引擎为非聚簇索引),当为 Innodb 时,data 为索引所在行其他列的数据,当为 MYISAM 时,data 为索引所在的磁盘文件地址。
假设此时 索引+data 占用 1kb,那么第三层一个节点能存储 16 个数据。
此时的总数据量为 1142 * 1142 * 16 = 20866624,约为两千万个数据。
四,B+ 树怎么查找数据
将每个节点加载到内存做折半查找,远远小于磁盘 IO 的时间消耗。
而 B+ 树的冗余索引在数据库启动的时候就已经加载到了内存中,所以相当于就跟磁盘做了一次 IO。
思考:当 MySQL 数据库运行了很长时间后,有可能我们的每个索引元素都已经被加载到内存过,内存放不下,怎么办?(buffer pull)
五,存储引擎
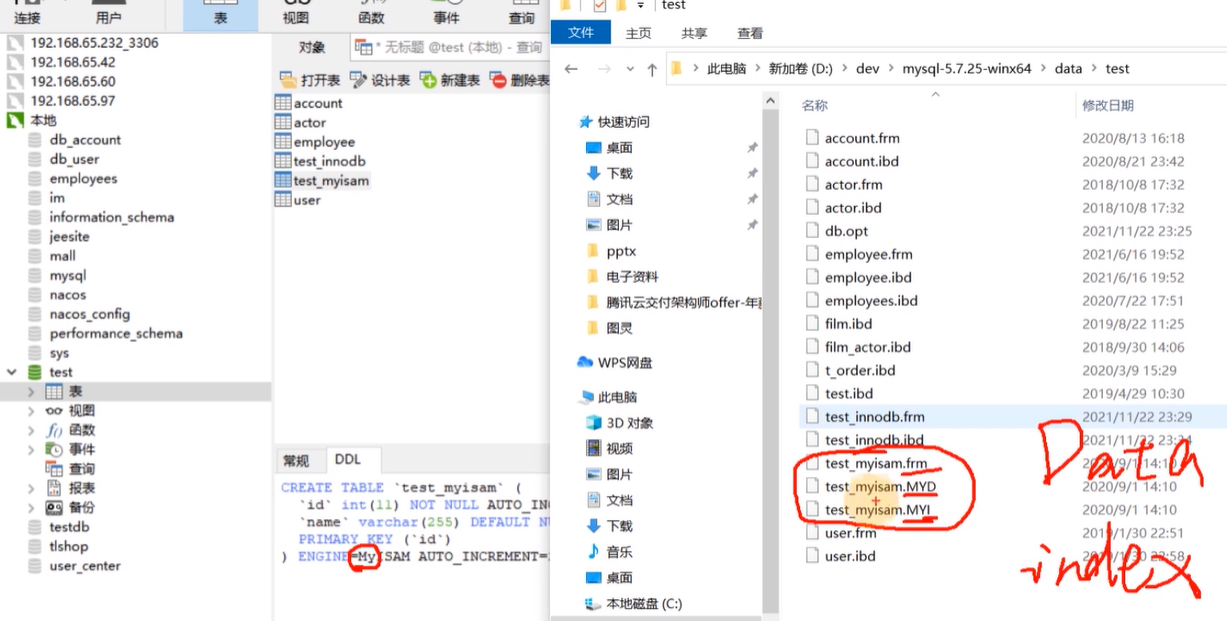
1,MYISAM
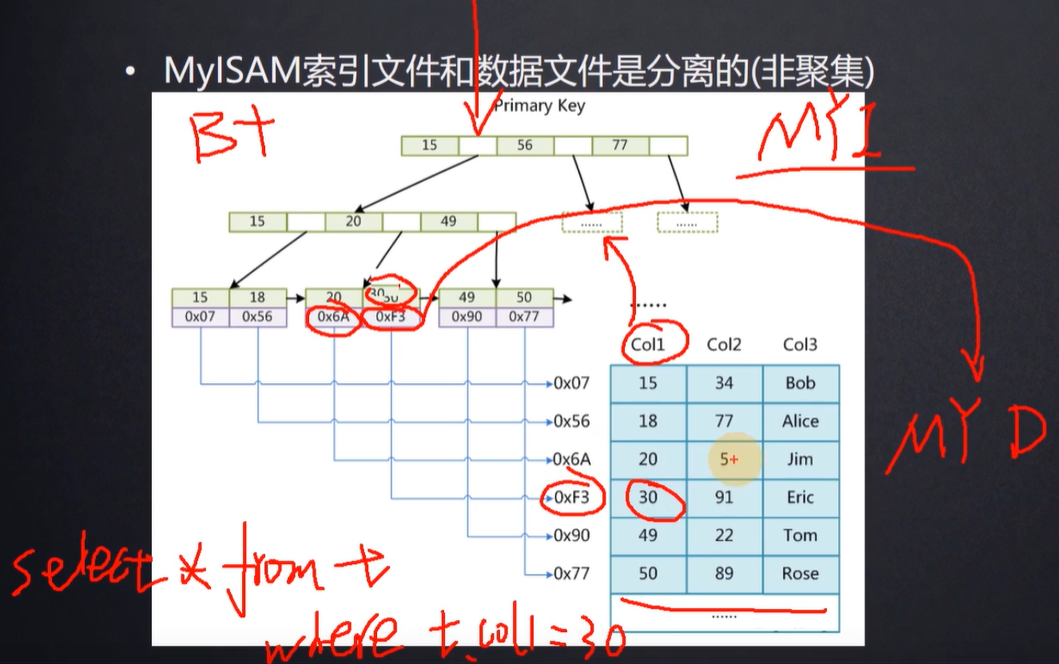
2,Innodb
- 表数据文件本身就是按 B+Tree 组织的一个索引结构文件
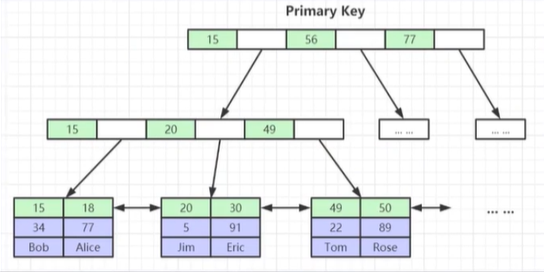
- 聚簇索引——叶节点包含了完整的数据记录
- 为什么建议Innodb表必须建主键,并且推荐使用整形的自增主键?
- 为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
主键索引:
非主键索引:
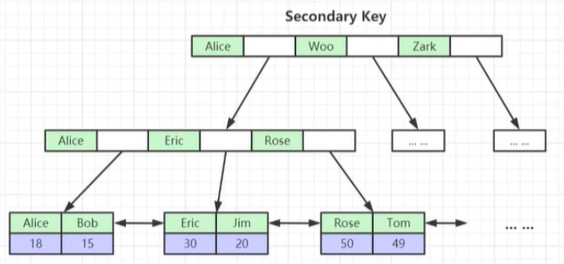
由于非主键索引存储的是主键的值,所以当这个表没有主键时,数据库将会帮你维护一个主键(自动查找没有重复的列或者生成一个虚拟的列),这将耗费数据库资源和性能。
自增主键的原因是,自增的主键生成索引时,更加快速和高效。
整形主键的原因是,整形的主键插入对比时,更加的快速和高效。
但是需要注意的是,自增主键在以下几种情况可能出现重复值:
- 在分布式系统中,如果多个数据库节点使用相同的自增策略,可能会产生相同的主键
- 在MySQL8.0之前,如果删除了某个自增主键,然后重启MySQL,再插入新的数据,可能会使用之前被删除的主键
- 当自增整形主键达到最大值时,再添加新的数据,会报重复错误
所以一般还是用别的办法来生成全局唯一的主键,如 UUID,雪花算法,Redis 等。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
2019-05-29 冲刺第十三天