pandas中groupby的参数:as_index
参考:https://blog.csdn.net/cjsyr6wt/article/details/78200444?locationNum=11&fps=1
以下是pandas官方的解释:
DataFrame.groupby(by = None,axis = 0,level = None,as_index = True,sort = True,group_keys = True,squeeze = False,observe = False,** kwargs )
as_index : bool,默认为True
对于聚合输出,返回以组标签作为索引的对象。仅与DataFrame输入相关。as_index = False实际上是“SQL风格”的分组输出。
import pandas as pd df = pd.DataFrame(data={'books':['bk1','bk1','bk1','bk2','bk2','bk3'], 'price': [12,12,12,15,15,17],'num':[2,1,1,4,2,2]}) print('df')
我们来看一下输出:
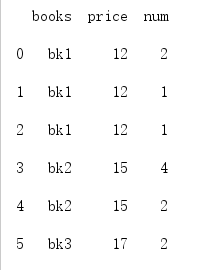
看一下as_index为True的输出:
1 print(df.groupby('books',as_index=True).sum())
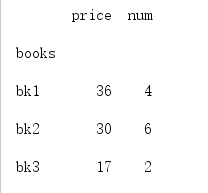
看以下as_index为False的输出:
1 print(df.groupby('books',as_index=False).sum())
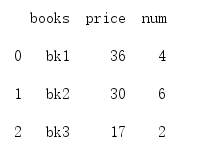
可以看到为True时 自动把第一列作为了index
as_index为True时可以通过book的name来提取这本书的信息,如:
1 df = df.groupby('books',as_index=True).sum() 2 print(df) 3 print('='*20) 4 print(df.loc['bk1'])
输出为:
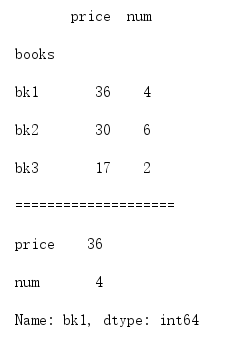
具体的作用就是这样了吧,有不同见解的可以分享一下~
https://www.cnblogs.com/zhangzhixing/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号