











MySQL/Oracle中常用函数总结
记录在日常工作或者学习中中使用到的函数,以下是做一个备忘~
MySQL:
将某一列的值连接成一个字符串:group_concat
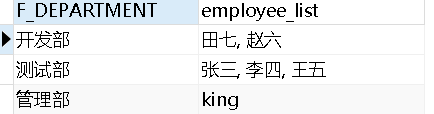
需求:按照部门名称分组,得到每个部门中所有的员工姓名
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | -- -------------------------------------------------------------------------insert into t_employees(id,f_name,f_department) values(1,'张三','测试部');insert into t_employees(id,f_name,f_department) values(2,'李四','测试部');insert into t_employees(id,f_name,f_department) values(3,'王五','测试部');insert into t_employees(id,f_name,f_department) values(4,'赵六','开发部');insert into t_employees(id,f_name,f_department) values(5,'田七','开发部');insert into t_employees(id,f_name,f_department) values(6,'king','管理部');-- -------------------------------------------------------------------------select f_department, group_concat( f_name order by f_name separator ', ' ) as employee_listfrom t_employeesgroup by f_department; |
窗口函数:
原文地址:https://zhuanlan.zhihu.com/p/92654574
1、窗口函数使用场景
窗口函数有什么用?
在日常工作中,经常会遇到需要在每组内排名,比如下面的业务需求:
- 排名问题:每个部门按业绩来排名
- topN问题:找出每个部门排名前N的员工进行奖励
面对这类需求,就需要使用sql的高级功能窗口函数了。
2、窗口函数的语法
窗口函数的基本语法如下:
1 | <窗口函数> over (partition by <用于分组的列名> order by <用于排序的列名>) |
那么语法中的<窗口函数>都有哪些呢?
<窗口函数>的位置,可以放以下两种函数:
- 1) 专用窗口函数,包括后面要讲到的rank, dense_rank, row_number等专用窗口函数。
- 2) 聚合函数,如sum. avg, count, max, min等
因为窗口函数是对where或者group by子句处理后的结果进行操作,所以窗口函数原则上只能写在select子句中。
3、窗口函数:rank
班级表以及测试数据SQL:



SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for class -- ---------------------------- DROP TABLE IF EXISTS `class`; CREATE TABLE `class` ( `ID` int NOT NULL AUTO_INCREMENT, `student_id` int(4) UNSIGNED ZEROFILL NOT NULL COMMENT '学号', `class_name` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL COMMENT '班级', `grade` int NULL DEFAULT NULL COMMENT '成绩', PRIMARY KEY (`ID`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 9 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_0900_ai_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Records of class -- ---------------------------- INSERT INTO `class` VALUES (1, 0001, '1', 86); INSERT INTO `class` VALUES (2, 0002, '1', 95); INSERT INTO `class` VALUES (3, 0003, '2', 89); INSERT INTO `class` VALUES (4, 0004, '1', 83); INSERT INTO `class` VALUES (5, 0005, '2', 86); INSERT INTO `class` VALUES (6, 0006, '3', 92); INSERT INTO `class` VALUES (7, 0007, '3', 86); INSERT INTO `class` VALUES (8, 0008, '1', 88); SET FOREIGN_KEY_CHECKS = 1;
例如下图,是班级表中的内容:

如果我们想在每个班级内按成绩排名,得到下面的结果。(按照班级进行分组,按照每个班级的成绩进行降序排列)
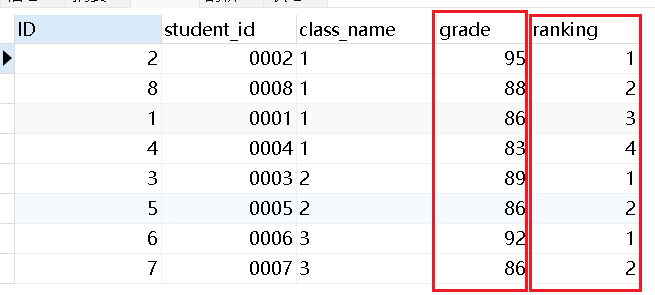
以班级“1”为例,这个班级的成绩“95”排在第1位,这个班级的“83”排在第4位。上面这个结果确实按我们的要求在每个班级内,按成绩排名了。
得到上面结果的sql语句代码如下:
1 2 3 4 5 | SELECT *, rank() over ( PARTITION BY class_name ORDER BY grade DESC ) AS ranking FROM class; |
窗口函数具备了我们之前学过的group by子句分组的功能和order by子句排序的功能。那么,为什么还要用窗口函数呢?
这是因为,group by分组汇总后改变了表的行数,一行只有一个类别。而partiition by和rank函数不会减少原表中的行数。
4、其他专业窗口函数:rank、dense_rank、row_number
专用窗口函数rank, dense_rank, row_number有什么区别呢?
它们的区别我举个例子,你们一下就能看懂:
1 2 3 4 5 | select *, rank() over (order by grade desc) as ranking, dense_rank() over (order by grade desc) as dese_rank, row_number() over (order by grade desc) as row_numfrom class |
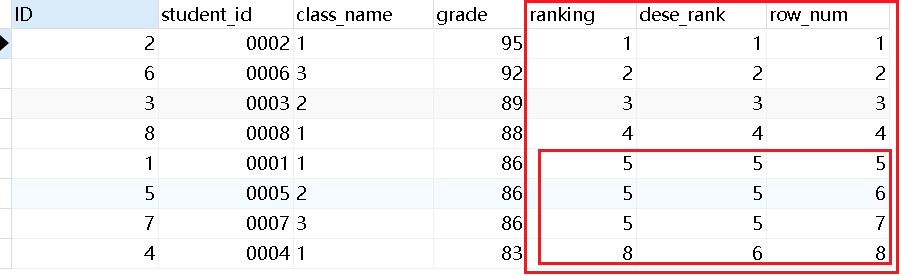
- ranking:并列名次的行,会占用下一名次的位置
- dense_rank:如果有并列名次的行,不占用下一名次的位置,并列第五
- row_number:不考虑并列名次的情况
5、聚合函数作为窗口函数
聚和窗口函数和上面提到的专用窗口函数用法完全相同,只需要把聚合函数写在窗口函数的位置即可,但是函数后面括号里面不能为空,需要指定聚合的列名。
我们来看一下窗口函数是聚合函数时,会出来什么结果:
1 2 3 4 5 6 7 | select *, sum(grade) over (order by student_id) as current_sum, avg(grade) over (order by student_id) as current_avg, count(grade) over (order by student_id) as current_count, max(grade) over (order by student_id) as current_max, min(grade) over (order by student_id) as current_minfrom class; |
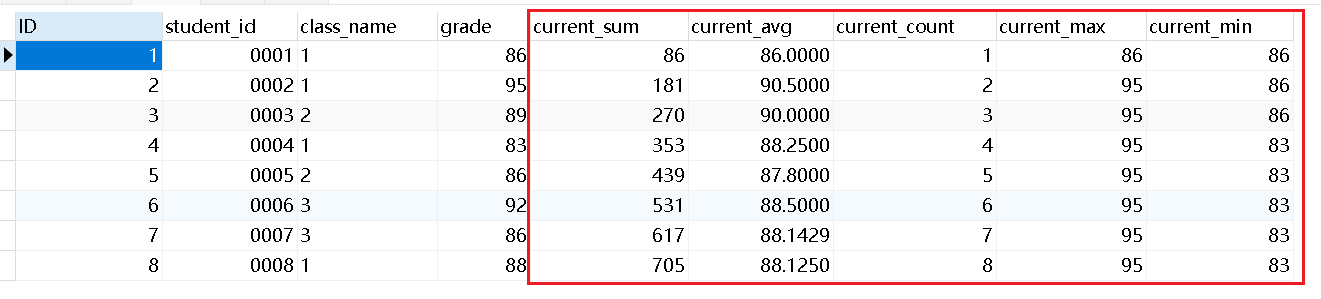
如上图,聚合函数sum在窗口函数中,是对自身记录、及位于自身记录以上的数据进行求和的结果。
比如0004号,在使用sum窗口函数后的结果,是对0001,0002,0003,0004号的成绩求和,若是0005号,则结果是0001号~0005号成绩的求和,以此类推。
比如avg函数,学号为003的学生,是(001+002+003)/3 = 90
不仅是sum求和,平均、计数、最大最小值,也是同理,都是针对自身记录、以及自身记录之上的所有数据进行计算。
如果想要知道所有人成绩的总和、平均等聚合结果,看最后一行即可。
6、这样使用窗口函数有什么用呢?
聚合函数作为窗口函数,可以在每一行的数据里直观的看到,截止到本行数据,统计数据是多少(最大值、最小值等)。
同时可以看出每一行数据,对整体统计数据的影响。
查询日期时间:
current_date:返回日期
示例:
1 | select current_date ; |

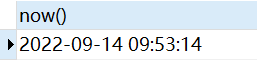
now():返回时间
1 | select now(); |
获取时间函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | select current_date ;SELECT CURRENT_TIMESTAMP ;SELECT CURRENT_TIMESTAMP ();SELECT NOW();SELECT LOCALTIME;SELECT LOCALTIME();SELECT LOCALTIMESTAMP;SELECT LOCALTIMESTAMP(); |
操作时间/日期:
1 2 3 4 5 6 7 8 9 10 11 | -- 加一天:select NOW() + INTERVAL 1 DAY ;-- 减一天:select NOW() - INTERVAL 1 DAY ;-- 加 30 分钟:select NOW() + INTERVAL 30 MINUTE ;-- 减 30 分钟:select NOW() - INTERVAL 30 MINUTE ; |
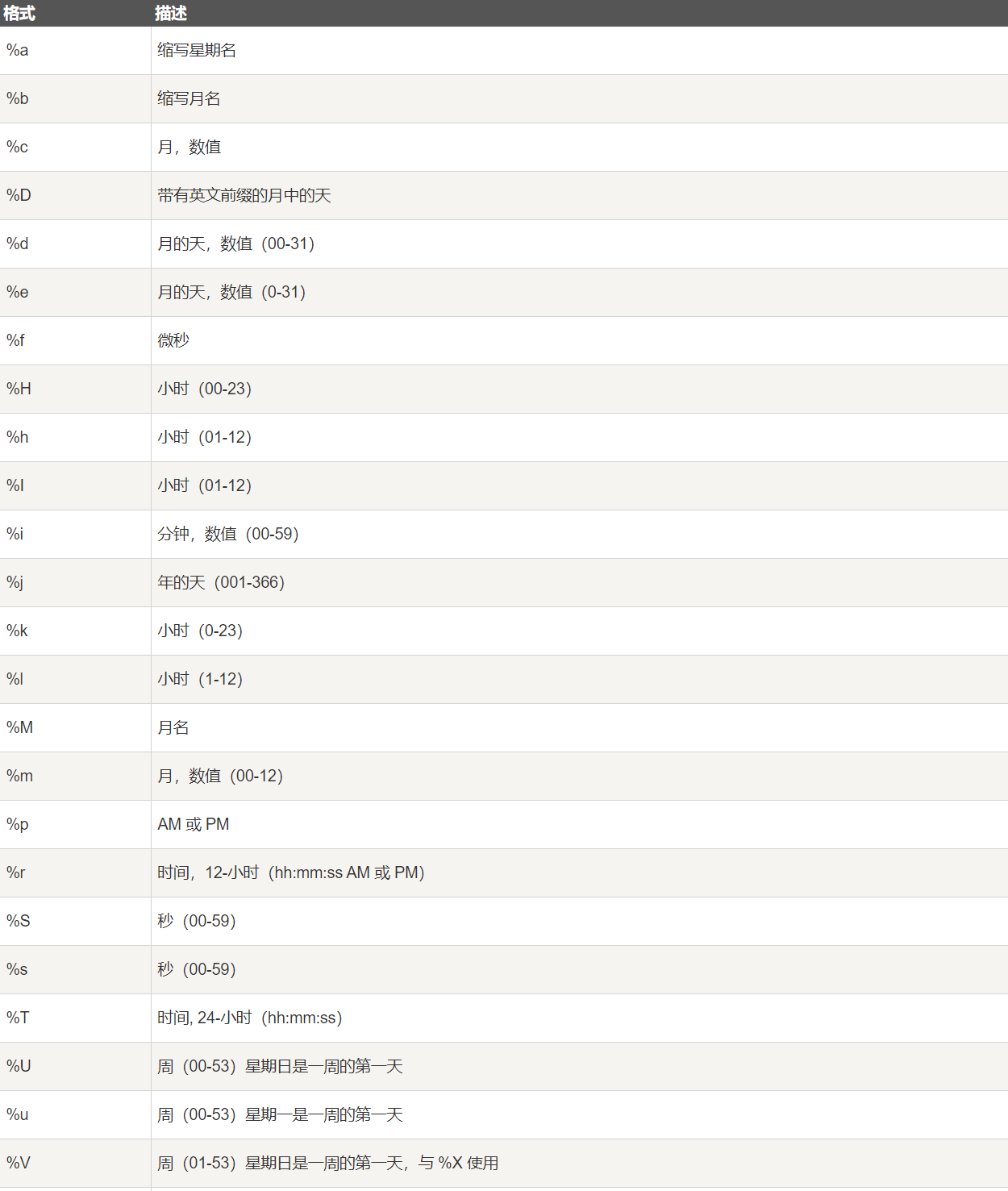
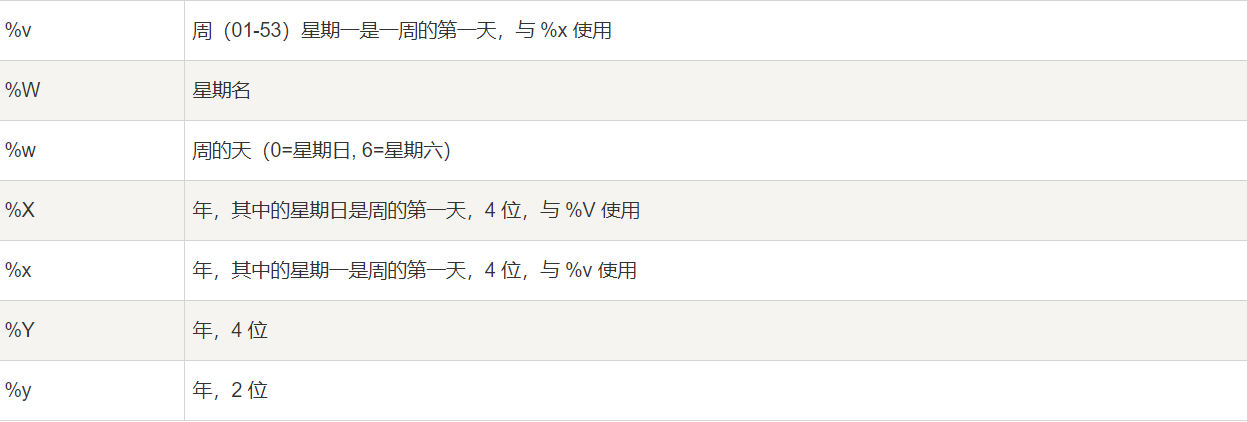
DATE_FORMAT() :用于以不同的格式显示日期/时间数据
语法:
1 | DATE_FORMAT(date,format) |
date 参数是合法的日期。
format 规定日期/时间的输出格式。
示例:
1 2 3 4 5 6 | SELECT DATE_FORMAT(NOW(),'%Y-%m-%d %H:%i:%s'); -- 结果:2020-12-07 22:18:58SELECT DATE_FORMAT(NOW(),'%Y-%m-%d %H:%i'); -- 结果:2020-12-07 22:18SELECT DATE_FORMAT(NOW(),'%Y-%m-%d %H'); -- 结果:2020-12-07 22SELECT DATE_FORMAT(NOW(),'%Y-%m-%d'); -- 结果:2020-12-07SELECT DATE_FORMAT(NOW(),'%H:%i:%s'); -- 结果:22:18:58SELECT DATE_FORMAT(NOW(),'%H'); -- 结果:22 |
统计每天的访问次数
1 2 3 4 5 6 7 8 9 | SELECT DATE_FORMAT( login_time, '%Y-%m-%d' ) AS date, COUNT(*) AS num_users FROM t_user_log GROUP BY DATE_FORMAT( login_time, '%Y-%m-%d' ) ORDER BY date DESC; |
timestampdiff:计算两个日期时间的差值
语法
timestampdiff(unit,begin,end)
TIMESTAMPDIFF函数,有参数设置,可以精确到天(DAY)、小时(HOUR),分钟(MINUTE)和秒(SECOND),使用起来比datediff函数更加灵活。对于比较的两个时间,时间小的放在前面,时间大的放在后面。
unit参数是确定(end-begin)的结果的单位,表示为整数。 以下是有效单位:
- MICROSECOND
- SECOND
- MINUTE
- HOUR
- DAY
- WEEK
- MONTH
- YEAR
使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 | mysql> SELECT TIMESTAMPDIFF(MONTH, '2018-01-01', '2018-06-01') as result;+--------+| result |+--------+| 5 |+--------+1 row in set (0.00 sec)mysql> SELECT TIMESTAMPDIFF(DAY, '2010-01-01', '2010-06-01') as result;+--------+| result |+--------+| 151 |+--------+1 row in set (0.00 sec)mysql> SELECT TIMESTAMPDIFF(MINUTE, '2018-01-01 10:00:00', '2018-01-01 10:45:00') as result;+--------+| result |+--------+| 45 |+--------+1 row in set (0.00 sec)mysql> SELECT TIMESTAMPDIFF(MINUTE, '2018-01-01 10:00:00', '2018-01-01 10:45:59') as result;+--------+| result |+--------+| 45 |+--------+1 row in set (0.00 sec)mysql> SELECT TIMESTAMPDIFF(SECOND, '2018-01-01 10:00:00', '2018-01-01 10:45:59') as result;+--------+| result |+--------+| 2759 |+--------+1 row in set (0.00 sec) |
字符串拼接操作:concat、concat_ws、group_concat
这个博主总结的很好,仅供参考:MySQL拼接函数CONCAT的使用心得
CAST:格式转换
参考链接:https://blog.csdn.net/Hudas/article/details/124399908
CAST函数用于将值从一种数据类型转换为表达式中指定的另一种数据类型
语法:
1 | CAST (value AS datatype) |
参数说明:
value: 要转换的值
datatype: 要转换成的数据类型
| 值 | 描述 |
| DATE | 将value转换成'YYYY-MM-DD'格式 |
| DATETIME | 将value转换成'YYYY-MM-DD HH:MM:SS'格式 |
| TIME | 将value转换成'HH:MM:SS'格式 |
| CHAR | 将value转换成CHAR(固定长度的字符串)格式 |
| SIGNED | 将value转换成INT(有符号的整数)格式 |
| UNSIGNED | 将value转换成INT(无符号的整数)格式 |
| DECIMAL | 将value转换成FLOAT(浮点数)格式 |
| BINARY | 将value转换成二进制格式 |
示例:
将值转为Date类型:
1 2 3 4 5 6 7 8 | -- 2017-08-29SELECT CAST('2017-08-29' AS DATE); -- 2022-09-14 10:22:29SELECT NOW();-- 2022-09-14SELECT CAST(NOW() AS DATE); |
将值转换为DATETIME数据类型
1 2 | -- 2022-04-27 00:00:00SELECT CAST('2022-04-27' AS DATETIME); |
将值转换为TIME数据类型
1 2 3 4 | -- 14:06:10SELECT CAST('14:06:10' AS TIME); -- 14:06:10SELECT CAST('2022-04-27 14:06:10' AS TIME); |
将date转为char,将某一列的数据类型转为指定数据类型
1 2 3 4 5 6 7 8 9 | SELECT CAST( date AS CHAR ) AS date, IF( STATUS = 1, '正常', '迟到' ) AS STATUS FROM tb_checkin WHERE user_id = 6 AND date BETWEEN '2022-09-13 00:00:00' AND '2022-09-14 00:00:00'; |
IF语句:条件判断
IF:如果expr1条件为TRUE,则IF()返回值为expr2,否则返回值为expr3
1 | IF(expr1,expr2,expr3); |
1 2 | SELECT IF(2>1,'haha','hehe'); -- hahaSELECT IF(2<1,'haha','hehe'); -- hehe |
IFNULL:假如expr1不为null,则返回expr1,否则返回expr2
1 | IFNULL(expr1,expr2) |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | mysql> select * from xxl_job_user;+----+----------+----------------------------------+------+------------+| id | username | password | role | permission |+----+----------+----------------------------------+------+------------+| 1 | admin | e10adc3949ba59abbe56e057f20f883e | 1 | NULL || 2 | zhangsan | e10adc3949ba59abbe56e057f20f883e | 1 | || 4 | NULL | hhh | 1 | 1 |+----+----------+----------------------------------+------+------------+3 rows in set (0.01 sec)mysql> SELECT IFNULL(username,'no_username') as newname FROM xxl_job_user WHERE id = 2;+----------+| newname |+----------+| zhangsan |+----------+1 row in set (0.01 sec)mysql> SELECT IFNULL(username,'no_username') as newname FROM xxl_job_user WHERE id = 4;+-------------+| newname |+-------------+| no_username |+-------------+1 row in set (0.01 sec) |
case whth:条件判断
语法:
1 2 3 4 5 6 | case when 条件1 then '值' when 条件2 then '值' …… else then '值'end |
示例:
1 2 3 4 5 6 7 8 9 10 | SELECT CASE WHEN status= 1 THEN '正常' WHEN status= 2 THEN '迟到' ELSE '未知状态' END AS statusFROM tb_checkin WHERE user_id =6 |
Oracle:
定义临时查询结果集:WITH AS
Oracle SQL中的WITH AS语法(也称为子查询事实化或公共表达式子句)允许你在查询中定义临时的结果集(通常称为公用表表达式或CTE,Common Table Expression),这些结果集可以在主查询中多次引用,从而提高查询的可读性和性能。下面是WITH AS基本的使用语法和示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | -- 示例1:简单WITH AS用法WITH temp_table_name AS ( SELECT * FROM T_RDMS_RAIL_FLAW_DEAL_INFO WHERE id = 100)SELECT *FROM temp_table_name;-- 示例2:嵌套和多级WITH AS用法WITH tempTable1 AS ( SELECT a, b, c FROM table1), tempTable2 AS ( SELECT d, e FROM table2 JOIN tempTable1 ON tempTable1.a = table2.a )SELECT *FROM tempTable2 |
数据精度处理:
TRUNC 和 ROUND 是在数据库(如Oracle、SQL Server等)中处理数值时常用的两个函数,它们的主要区别在于对数字的处理方式不同:
-
TRUNC函数:- 功能:
TRUNC函数用于截断数字的小数部分而不会进行四舍五入。 - 用法举例:在Oracle中,
TRUNC(n, [m])函数返回的是数字n被截断到m位小数后的值。如果省略m,则默认截断到整数部分。
示例:
TRUNC(123.45678, 2) -- 返回结果为 123.45 TRUNC(123.45678) -- 返回结果为 123 - 功能:
-
ROUND函数:- 功能:
ROUND函数用于对数字进行四舍五入处理到指定的小数位数。 - 用法举例:同样在Oracle中,
ROUND(n, [m])函数会将数字n四舍五入到m位小数。如果省略m,默认四舍五入到最接近的整数。
示例:
ROUND(123.45678, 2) -- 返回结果为 123.46 ROUND(123.45678) -- 返回结果为 123 (对于正数,四舍五入;对于负数,同样是向最近的整数方向舍入) - 功能:
总结来说,TRUNC 不做任何四舍五入,直接删除超过指定精度的尾数部分,而 ROUND 则会对数值按照数学中的四舍五入规则进行处理。
注意:数据库层面 和 代码层面对于数据精度的处理
需要注意的是,通过Oracle默认处理方式进行插入、更新,是会对数据进行四舍五入。
假如你想要进行截取,就需要单独对数据使用TRUNC函数进行处理,如下所示:
1 2 3 4 5 6 7 8 9 10 11 | -- 默认:对数据进行四舍五入-- 1.455INSERT INTO "T_DEMAND_PLAN_SG_MAT" ("ID", "F_DEMAND_MONTHLY_NUM")VALUES ('4','1.4548');-- 1.455UPDATE "T_DEMAND_PLAN_SG_MAT" SET "F_DEMAND_MONTHLY_NUM" = '1.4549' WHERE "ID" = '4';-- 截取到3位-- 1.454INSERT INTO "T_DEMAND_PLAN_SG_MAT" ("ID", "F_DEMAND_MONTHLY_NUM")VALUES ('5',TRUNC(TO_NUMBER('1.4548'), 3));-- 1.454UPDATE "T_DEMAND_PLAN_SG_MAT" SET "F_DEMAND_MONTHLY_NUM" = TRUNC(TO_NUMBER('1.4549'), 3) WHERE "ID" = '5'; |
使用Mybatis插入数据时,可以通过上述操去指定是否要进行数据的截取,如果使用的MybatiPlus插入数据,就需要单独使用Java代码对字段进行处理了,如下:
1 2 3 4 | BigDecimal data = BigDecimal.valueOf(1.4548);System.out.println(data.setScale(3, RoundingMode.HALF_UP)); // 四舍五入:1.455System.out.println(data.setScale(3, RoundingMode.DOWN));// 截取3位:1.454System.out.println(data.setScale(3, BigDecimal.ROUND_DOWN)); // 截取3位:1.454 |
日期转特定格式字符串:to_char(日期,格式化)
Oracle日期格式化模型:https://docs.oracle.com/en/database/oracle/oracle-database/19/sqlrf/Format-Models.html
以下是一些TO_CHAR函数的基本使用示例:
-
将日期转换为特定格式的字符串("26-DEC-2023"):SELECT TO_CHAR(SYSDATE, 'DD-MON-YYYY') AS formatted_date FROM DUAL;
- 将时间转换为特定格式的字符串("14:30:45 PM"):SELECT TO_CHAR(SYSTIMESTAMP, 'HH:MI:SS AM') AS formatted_time FROM DUAL;
- 将数值转换为带有特定格式的字符串("123,456.78"):SELECT TO_CHAR(123456.78, '999G999G990D00') AS formatted_number FROM DUAL;
- 其中"G"表示分组分隔符(默认是逗号),"D"表示小数点。
获取一条记录:FETCH FIRST 1 ROWS ONLY
FETCH FIRST 1 ROWS ONLY: 仅返回第一行记录。使用FETCH FIRST子句可以限制结果集的行数
1 2 3 4 | SELECT *FROM T_SUPPLY_SEND_GOODS_MATWHERE F_SEND_GOODS_ID = 188ORDER BY id DESC FETCH FIRST 1 ROWS ONLY |
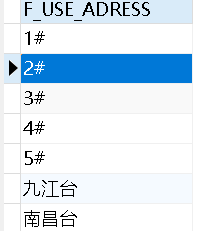
包含数字、字符的排序:TO_NUMBER(REGEXP_SUBSTR(排序字段, '\d+'))
按照使用地点默认排序,看到排序不是我们想要的:

按照Chatgpt所说,我们可以通过一个to_number实现排序
1 2 3 4 5 6 7 8 9 10 | SELECT f_use_adress FROM T_BILL_MAT_NUM WHERE ( f_unit_project_name = '铃子垄大桥' AND f_del_flag = '0' AND f_use_adress IS NOT NULL ) GROUP BY f_use_adress ORDER BY TO_NUMBER(REGEXP_SUBSTR(f_use_adress, '\d+')) |
将某一列的值连接成一个字符串:listagg
需求:按照部门名称分组,得到每个部门中所有的员工姓名
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | -- -------------------------------------------------------------------------INSERT into T_EMPLOYEES(id,F_NAME,F_DEPARTMENT) VALUES(1,'张三','测试部');INSERT into T_EMPLOYEES(id,F_NAME,F_DEPARTMENT) VALUES(2,'李四','测试部');INSERT into T_EMPLOYEES(id,F_NAME,F_DEPARTMENT) VALUES(3,'王五','测试部');INSERT into T_EMPLOYEES(id,F_NAME,F_DEPARTMENT) VALUES(4,'赵六','开发部');INSERT into T_EMPLOYEES(id,F_NAME,F_DEPARTMENT) VALUES(5,'田七','开发部');INSERT into T_EMPLOYEES(id,F_NAME,F_DEPARTMENT) VALUES(6,'king','管理部');-- -------------------------------------------------------------------------SELECT f_department, listagg ( f_name, ', ' ) within GROUP ( ORDER BY f_name ) AS emp_name_list FROM t_employees GROUP BY f_department; |

字符串拼接:concat、||
使用了CONCAT函数来拼接字符串,但是在Oracle中,CONCAT函数只接受两个参数,所以需要单独再包一层
1 2 3 | SELECT * FROM t_sys_dict_data WHERE f_dict_label LIKE CONCAT(CONCAT('%', '草稿'), '%');SELECT * FROM t_sys_dict_data WHERE f_dict_label LIKE '%' || '草稿' || '%'; |
NVL:处理空值
Oracle中的NVL函数用于将一个表达式或列的空值替换为一个指定的值。其语法为:
NVL(expr1, expr2)
其中,
- expr1是需要判断是否为空的表达式或列;
- expr2是当expr1为空时要替换的值。
如果expr1为空,则NVL函数返回expr2,否则返回expr1的值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | -- 播放次数和时长(专题)SELECT TBS.F_SPECIAL_NAME, NVL( B.F_STUDY_TIME, 0 ) AS F_STUDY_TIME, NVL( B.F_STUDY_TIMES, 0 ) AS F_STUDY_TIMES, NVL( B.F_TERMINAL_TYPE, '-' ) AS F_TERMINAL_TYPE FROM T_BJCC_SUBJECT TBS LEFT JOIN ( SELECT TVVN.F_SPECIAL_FLAG, ROUND( SUM( TVVN.F_TOTAL_TIME ) / 3600, 2 ) AS F_STUDY_TIME, COUNT( TVVN.ID ) AS F_STUDY_TIMES, DECODE( TVVN.F_TERMINAL_TYPE, 1, 'PC端', 2, '移动端', 3, '智能TV' ) AS F_TERMINAL_TYPE FROM T_VIDEO_VISIT_NUM_DAY TVVN WHERE TVVN.F_START_TIME >= TO_DATE( '2023-06-20', 'yyyy-MM-dd' ) AND TVVN.F_START_TIME < TO_DATE( '2023-07-21', 'yyyy-MM-dd' ) AND TVVN.F_VALID_FLAG = 0 AND TVVN.F_CHANNEL_TYPE = '4' GROUP BY TVVN.F_SPECIAL_FLAG, TVVN.F_TERMINAL_TYPE ) B ON TBS.F_SPECIAL_FLAG = B.F_SPECIAL_FLAG |
NVL2:处理空值
nvl2(expr1,expr2,expr3):如果该函数的第一个参数为空,那么显示第二个参数的值,如果第一个参数的值不为空,则显示第三个参数的值。
对集合操作
- 1、union:对两个结果集进行并集操作,去重,按照默认规则排序
- 2、union all:对两个结果集并集操作,不去重,不排序
- 3、intersect:对两个结果集进行交集操作,去重,按照默认规则排序
- 4、minus:对两个结果集进行差操作,去重,按照默认规则排序
- 5、or:满足两个条件的并集,不去重,不排序
总结:
- 1、如果or字段是索引字段,那么使用union all代替or操作,可以走索引
- 2、如果能用union all ,尽量不要用union,相当于想distinct又执行了order by
- 3、这里所说的默认排序规则是按照select后边的字段顺序排序的,先按照第一个字段排序,如果第一个字段相同,就按照第二个字段排序
DECODE、CASE WHEN:根据给定的条件返回指定的结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | SELECT-- 第一种方式 DECODE( TVVN.F_TERMINAL_TYPE, 1, 'PC端', 2, '移动端', '其他设备' ) AS F_TERMINAL_TYPE,-- 第二种方式 CASE TVVN.F_TERMINAL_TYPE WHEN '1' THEN 'PC端' WHEN '2' THEN '移动端' ELSE '其他设备' END AS F_TERMINAL_NAME FROM T_VIDEO_VISIT_NUM_DAY TVVN WHERE TVVN.F_START_TIME >= TO_DATE( '2023-06-17', 'yyyy-MM-dd' ) AND TVVN.F_START_TIME < TO_DATE( '2023-07-18', 'yyyy-MM-dd' ) GROUP BY TVVN.F_TERMINAL_TYPE |

说明:
DECODE函数和CASE WHEN语句在功能上是相似的,都用于根据给定的条件返回指定的结果。但它们在语法和特性上有一些区别。
-
语法:
- DECODE函数:DECODE(expression, search1, result1, search2, result2,..., default_result)
- CASE WHEN语句:
CASE WHEN condition1 THEN result1 WHEN condition2 THEN result2 ... ELSE default_result END
-
使用方式:
- DECODE函数适用于Oracle数据库,是Oracle特有的函数,用于进行简单的条件匹配和结果转换。可以将多个搜索表达式和结果值作为参数传递给DECODE函数。
- CASE WHEN语句是SQL标准的条件表达式,通常在各种关系型数据库中都可以使用。它可以处理更复杂的条件逻辑,支持多个条件判断和结果返回。
-
支持性:
- DECODE函数只在Oracle数据库中支持,不适用于其他数据库系统。
- CASE WHEN语句是标准SQL语法,几乎所有的关系型数据库都支持它。
-
执行方式:
- DECODE函数在Oracle中是一个内置函数,它在查询时进行快速计算,一次性将所有表达式和结果值传递给DECODE函数进行匹配。
- CASE WHEN语句在查询时逐个条件进行匹配,如果条件满足则返回结果,并且只会依次判断条件,直到找到匹配的条件或默认结果。
总体而言,DECODE函数是Oracle特有的简单条件判断和结果转换函数,而CASE WHEN语句是标准SQL语法,适用于更复杂的条件逻辑和结果返回。在使用时需要根据具体的数据库和需求来选择合适的方式。
窗口函数:
Oracle支持窗口函数,可以使用窗口函数对查询结果进行分组和排序操作。窗口函数在SELECT语句的SELECT列表和ORDER BY子句中使用。
以下是一个使用窗口函数的示例查询:
1 2 3 | SELECT last_name, salary, department_id, ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY salary DESC) AS rankFROM employees; |
在这个查询中,ROW_NUMBER()函数是一个窗口函数,用于计算每个部门中工资最高的员工的排名。
PARTITION BY子句指定按照部门ID进行分组,而ORDER BY子句指定按照工资降序排序。查询结果将返回每个员工的姓氏、工资、所在部门ID以及该员工在其部门中的排名。
除了ROW_NUMBER()函数之外,Oracle还支持其他窗口函数,如RANK()、DENSE_RANK()、NTILE()、LAG()、LEAD()、SUM()等等。您可以在Oracle文档中查看完整的窗口函数列表和用法示例。
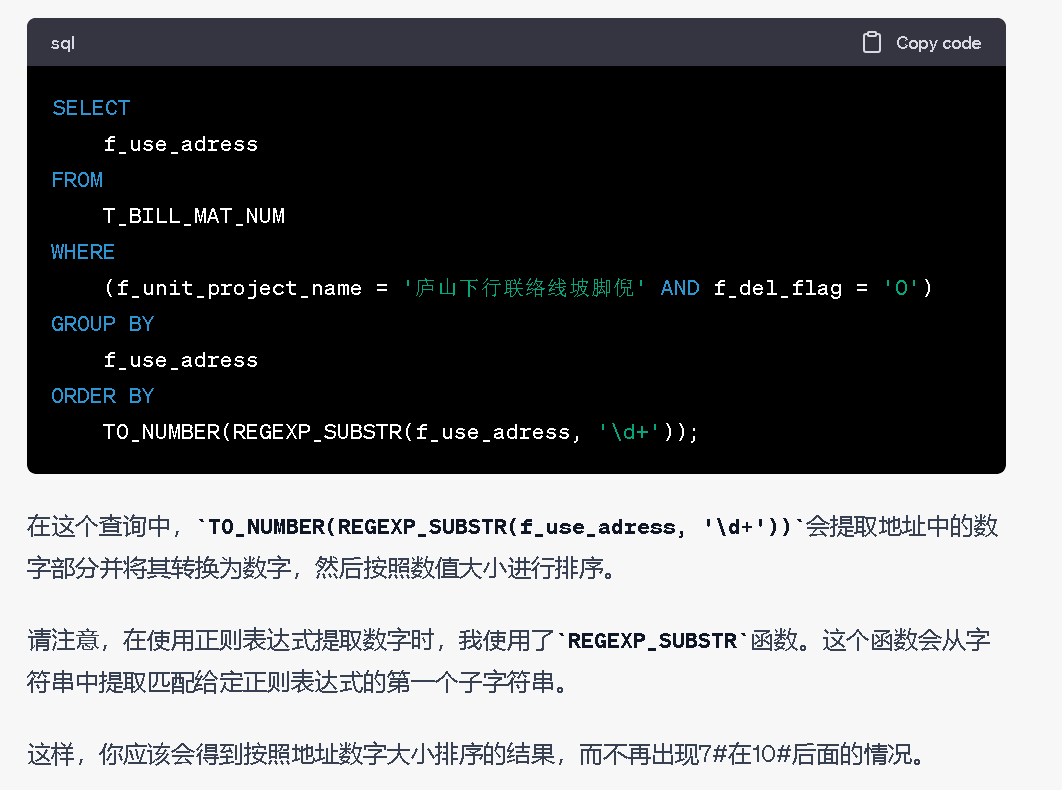
窗口函数:ROW_NUMBER() [对用户F_USER_ID进行去重(分组),按照登录时间排序,取最开始登录的一条记录]
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | SELECT * FROM ( SELECT ID, F_USER_ID, F_LOGIN_TIME, CASE F_TERMINAL WHEN '1' THEN 'PC端' WHEN '2' THEN '移动端' ELSE '其他设备' END AS F_TERMINAL_NAME, ROW_NUMBER() OVER (PARTITION BY F_USER_ID ORDER BY F_LOGIN_TIME) RN FROM T_LOG_SESSION WHERE F_USER_LOGIN_STATE = 1 AND F_REQUEST_URL = 'https://www.bjcc.gov.cn/vplayzb/2/6000585/600280123/0.html' AND F_CONNECT_TIME >= TO_DATE('2023-01-23 00:00:00', 'yyyy-mm-dd hh24:mi:ss') AND F_CONNECT_TIME <= TO_DATE('2023-02-23 12:00:00', 'yyyy-mm-dd hh24:mi:ss')) WHERE RN = 1; |
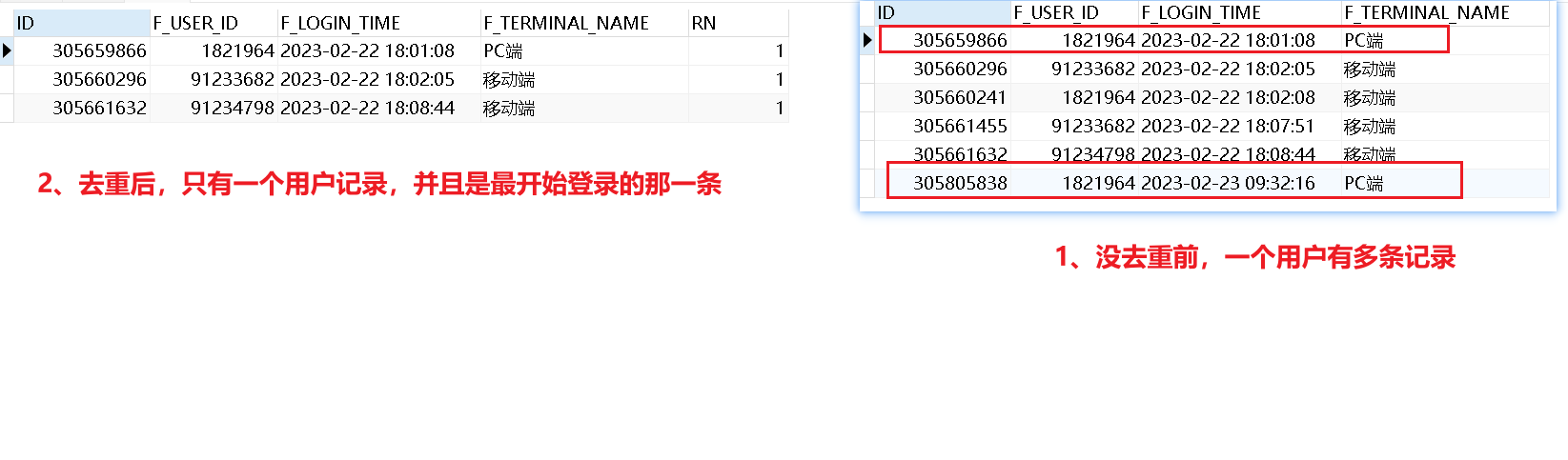
trunc:操作时间日期
1、截取时间
1 2 3 4 5 6 7 8 | select trunc(sysdate,'yyyy') from dual ;--返回当年第一天select trunc(sysdate-3) from dual ;--返回前三天的数据select trunc(sysdate,'mm') from dual ; --返回当月第一天select trunc(sysdate,'dd') from dual ;--返回当前年月日select trunc(sysdate,'d') from dual ; --返回当前星期的第一天(星期日)select trunc(sysdate,'hh') from dual ;--返回当前日期截取到小时,分秒补0select trunc(sysdate,'mi') from dual ;--返回当前日期截取到分,秒补0select to_char(sysdate,'yyyy-mm-dd hh24:mi:ss') from dual;--查看当前实时时间 |
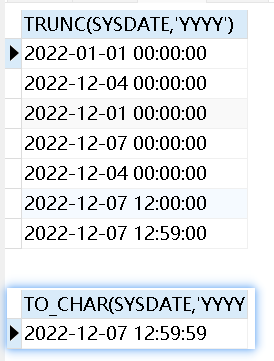
2、截取数字
1 2 3 | select trunc(122.555) from dual t; --默认取整select trunc(122.556,2) from dual t; --保留两位小数,是截取而不是四舍五入select trunc(122.555,-2) from dual t;--负数表示从小数点左边开始截取2位 |
MERGE INTO:条件判断
作用:判断C表(源表)和A表(目标表)是否满足ON中条件,如果满足则用C表去更新A表,如果不满足,则将C表数据插入A表.
简单的说就是,判断表中有没有符合on()条件中的数据,有了就更新数据,没有就插入数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # 判断表中有没有符合 on ()条件中的数据,有了就更新数据,没有就插入数据。MERGE INTO 目标表 A USING ( SELECT B.ID, B.F_LOGINNAME, B.F_PASSWORD FROM T_MEM_MEMBER B where B.F_LOGINNAME= '???') 源表C ON (A.条件字段 = C.条件字段)# 匹配成功执行更新语句WHEN MATCHED THEN UPDATE SET A.F_PASSWORD = C.F_PASSWORD# 匹配不成功执行插入语句WHEN NOT MATCHED THEN INSERT (A.ID, A.F_NAME, A.F_PASSWORD,A.F_CAPTION, A.F_TYPE,A.F_STATE,A.F_NOTE,A.F_ORDER,A.F_DEPT_ID,A.F_DEPT_NAME,A.F_MS_RECEIVED) VALUES (C.ID, C.F_LOGINNAME, C.F_PASSWORD, '区级管理员/街道管理员/...' , '2' , '0' , '1' , '1' , '0' , '管理员' , '0' ); |
start with connect by prior:递归查询
基本语法:
1 | select [字段] from [表名] start with ... connect by prior id = pId |
- start with:表示以什么为根节点,不加限制可以写1=1,要以id为123的节点为根节点,就写为start with id =123
- connect by:connect by是必须的,start with有些情况是可以省略的,或者直接start with 1=1不加限制
- prior:prior关键字可以放在等号的前面,也可以放在等号的后面,表示的意义是不一样的,比如 prior id = pid,就表示pid就是这条记录的根节点了
举例:
查询指定父栏目(根节点)下所有的一级(子)栏目,一级栏目下可能还有二级栏目,将这些栏目的信息都查询出来
1 2 3 4 5 6 7 | SELECT ID, F_TITLE FROM T_MK_CMS_CHANNEL START WITH id = '800535'CONNECT BY PRIOR ID = F_PARENT_ID |
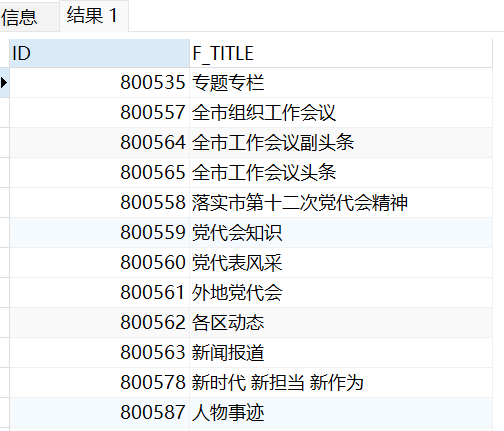
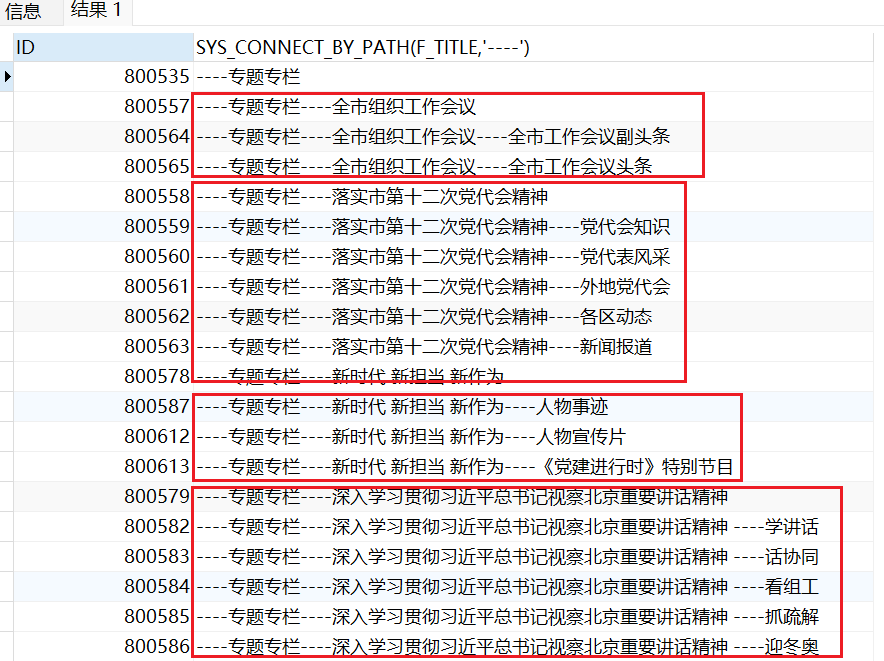
sys_connect_by_path:将递归查到的数据加上特定的符号
按照上面的例子来说,查询到的数据,并不能直观的看到哪些是父节点,哪些是子节点,使用sys_connect_by_path就可以很好的区分了:
sys_connect_by_path第一个参数是形成树形式的字段,第二个参数是父级和其子级分隔显示用的分隔符!
1 2 3 4 5 6 7 | SELECT ID, sys_connect_by_path ( F_TITLE, '----' ) FROM T_MK_CMS_CHANNEL START WITH ID = '800535'CONNECT BY PRIOR ID = F_PARENT_ID |






【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
2021-09-14 Centos7下的磁盘分区
2020-09-14 希尔排序