











Fork/Join框架
在JDK7时,出现了一个新的框架用于并行执行任务,它的目的是为了把大型任务拆分为多个小任务,最后汇总多个小任务的结果,得到整大任务的结果,并且这些小任务都是同时在进行,大大提高运算效率。Fork就是拆分,Join就是合并。
我们来演示一下实际的情况,比如一个算式:18x7+36x8+9x77+8x53,可以拆分为四个小任务:18x7、36x8、9x77、8x53,最后我们只需要将这四个任务的结果加起来,就是我们原本算式的结果了,有点归并排序的味道。
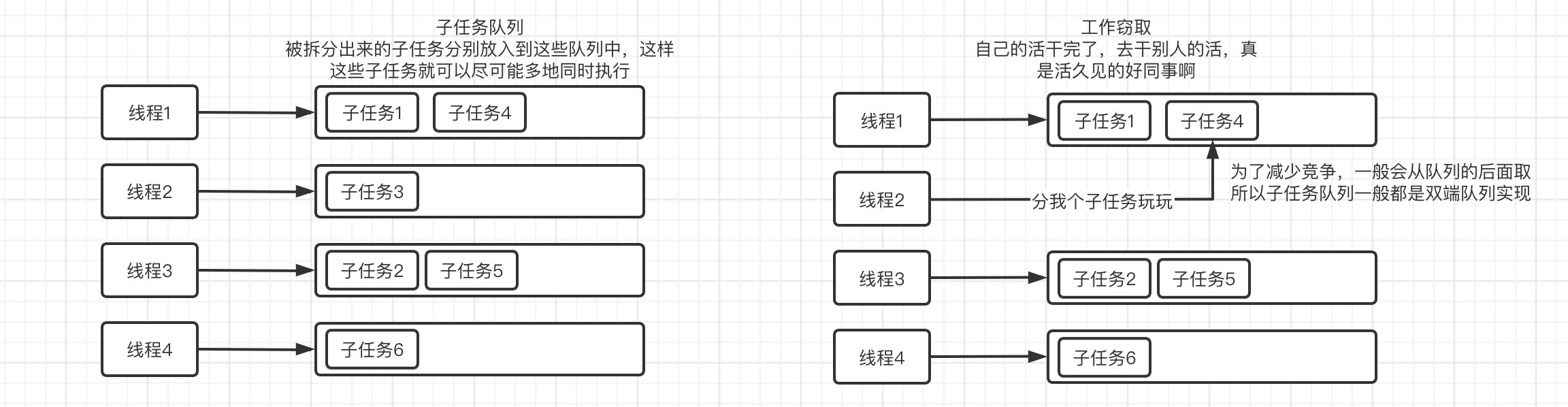
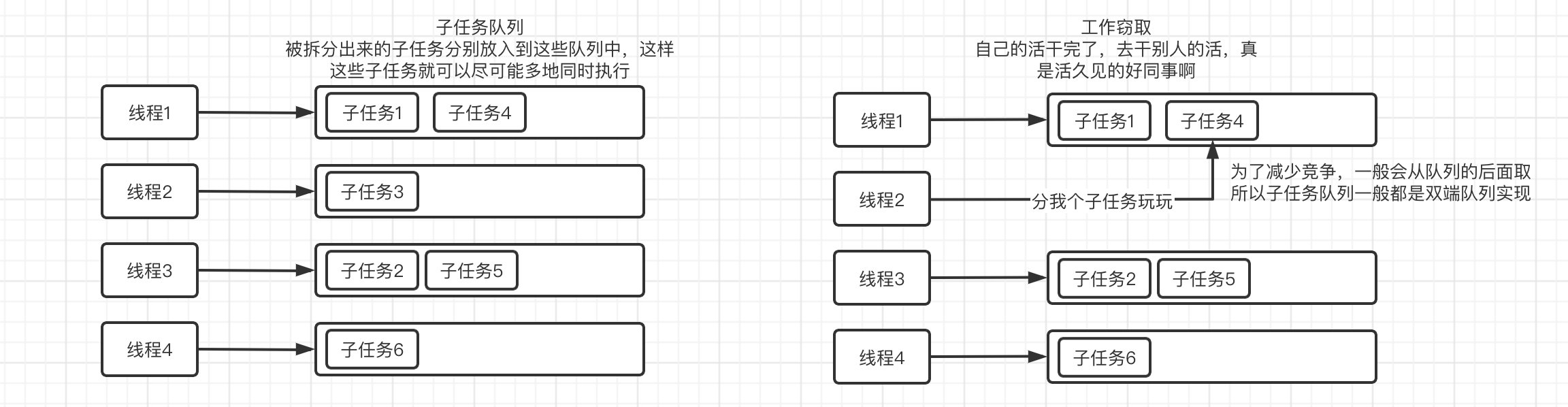
它不仅仅只是拆分任务并使用多线程,而且还可以利用工作窃取算法,提高线程的利用
- 工作窃取算法:是指某个线程从其他队列里窃取任务来执行。一个大任务分割为若干个互不依赖的子任务,为了减少线程间的竞争,把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和一对应。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务待处理。干完活的线程与其等着,不如帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。
Fork/Join使用两个类来完成以上两件事情:
ForkJoinTask
我们要使用ForkJoin框架,必须首先创建一个ForkJoin任务。它提供在任务中执行fork()和join()
操作的机制,通常情况下我们不需要直接继承ForkJoinTask类,而只需要继承它的子类,Fork/Join框架提供了以下两个子类:
-
RecursiveAction:用于没有返回结果的任务。
-
RecursiveTask :用于有返回结果的任务。
-
ForkJoinPool 需要通过
ForkJoinPool来执行,任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。当一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程的队列的尾部获取一个任务。
现在我们来看看如何使用它,这里以计算1-1000的和为例,我们可以将其拆分为8个小段的数相加,比如1-125、126-250... ,最后再汇总即可,它也是依靠线程池来实现的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | public static void main(String[] args) throws InterruptedException, ExecutionException { ForkJoinPool pool = new ForkJoinPool(); System.out.println(pool.submit(new SubTask(1, 1000)).get()); } /** * 继承RecursiveTask,这样才可以作为一个任务,泛型就是计算结果类型 */ private static class SubTask extends RecursiveTask<Integer> { private final int start; //比如我们要计算一个范围内所有数的和,那么就需要限定一下范围,这里用了两个int存放 private final int end; public SubTask(int start, int end) { this.start = start; this.end = end; } @Override protected Integer compute() { if(end - start > 125) { //每个任务最多计算125个数的和,如果大于继续拆分,小于就可以开始算了 SubTask subTask1 = new SubTask(start, (end + start) / 2); subTask1.fork(); //会继续划分子任务执行 SubTask subTask2 = new SubTask((end + start) / 2 + 1, end); subTask2.fork(); //会继续划分子任务执行 return subTask1.join() + subTask2.join(); //越玩越有递归那味了 } else { System.out.println(Thread.currentThread().getName()+" 开始计算 "+start+"-"+end+" 的值!"); int res = 0; for (int i = start; i <= end; i++) { res += i; } return res; //返回的结果会作为join的结果 } } } |
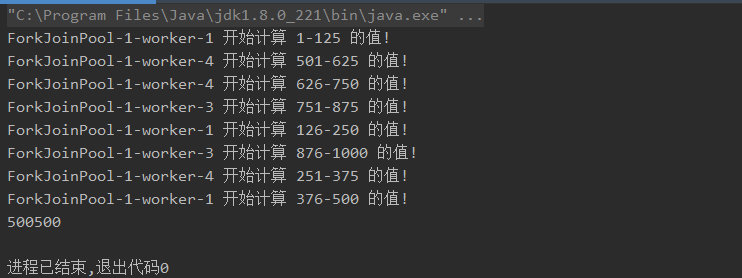
可以看到,结果非常正确,但是整个计算任务实际上是拆分为了8个子任务同时完成的,结合多线程,原本的单线程任务,在多线程的加持下速度成倍提升。
包括Arrays工具类提供的并行排序也是利用了ForkJoinPool来实现:
1 2 3 4 5 6 7 8 9 10 11 | public static void parallelSort(byte[] a) { int n = a.length, p, g; if (n <= MIN_ARRAY_SORT_GRAN || (p = ForkJoinPool.getCommonPoolParallelism()) == 1) DualPivotQuicksort.sort(a, 0, n - 1); else new ArraysParallelSortHelpers.FJByte.Sorter (null, a, new byte[n], 0, n, 0, ((g = n / (p << 2)) <= MIN_ARRAY_SORT_GRAN) ? MIN_ARRAY_SORT_GRAN : g).invoke();} |
并行排序的性能在多核心CPU环境下,肯定是优于普通排序的,并且排序规模越大优势越显著。






【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!