
Subqueries
CALL subqueries
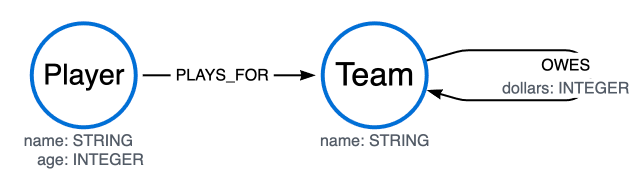
The CALL clause can be used to invoke subqueries that execute operations within a defined scope, thereby optimizing data handling and query efficiency. Unlike other subqueries in Cypher®, CALL subqueries can be used to perform changes to the database (e.g. CREATE new nodes).
Semantics and performance
A CALL subquery is executed once for each incoming row. The variables returned in a subquery are available to the outer scope of the enclosing query.
UNWIND [0, 1, 2] AS x
CALL () {
RETURN 'hello' AS innerReturn
}
RETURN innerReturn

╒═══════════╕ │innerReturn│ ╞═══════════╡ │"hello" │ ├───────────┤ │"hello" │ ├───────────┤ │"hello" │ └───────────┘
Incrementally update the age property of a Player:
UNWIND [1, 2, 3] AS x
CALL () {
MATCH (p:Player {name: 'Player A'})
SET p.age = p.age + 1
RETURN p.age AS newAge
}
MATCH (p:Player {name: 'Player A'})
RETURN x AS iteration, newAge, p.age AS totalAge
╒═════════╤══════╤════════╕ │iteration│newAge│totalAge│ ╞═════════╪══════╪════════╡ │1 │22 │24 │ ├─────────┼──────┼────────┤ │2 │23 │24 │ ├─────────┼──────┼────────┤ │3 │24 │24 │ └─────────┴──────┴────────┘
The scoping effect of a CALL subquery means that the work performed during each execution of each row can be cleaned up as soon its execution ends, before proceeding to the next row. This allows for efficient resource management and reduces memory overhead by ensuring that temporary data structures created during the subquery execution do not persist beyond their usefulness. As a result, CALL subqueries can help maintain optimal performance and scalability, especially in complex or large-scale queries.
Collect a list of all players playing for a particular team:
MATCH (t:Team)
CALL (t) {
MATCH (p:Player)-[:PLAYS_FOR]->(t)
RETURN collect(p) as players
}
RETURN t AS team, players
╒════════════════════════╤════════════════════════════════════════════════════════════════════════════╕
│team │players │
╞════════════════════════╪════════════════════════════════════════════════════════════════════════════╡
│(:Team {name: "Team A"})│[(:Player {name: "Player B",age: 23}), (:Player {name: "Player A",age: 24})]│
├────────────────────────┼────────────────────────────────────────────────────────────────────────────┤
│(:Team {name: "Team B"})│[(:Player {name: "Player D",age: 30})] │
├────────────────────────┼────────────────────────────────────────────────────────────────────────────┤
│(:Team {name: "Team C"})│[(:Player {name: "Player F",age: 35}), (:Player {name: "Player E",age: 25})]│
└────────────────────────┴────────────────────────────────────────────────────────────────────────────┘
The CALL subquery ensures that each Team is processed separately (one row per Team node), rather than having to hold every Team and Player node in heap memory simultaneously before collecting them into lists. Using a CALL subquery can therefore reduce the amount of heap memory required for an operation.
Importing variables
Variables from the outer scope must be explicitly imported into the inner scope of the CALL subquery, either by using a variable scope clause or an importing WITH clause (deprecated). As the subquery is evaluated for each incoming input row, the imported variables are assigned the corresponding values from that row.
The variable scope clause
Variables can be imported into a CALL subquery using a scope clause: CALL (<variable>). Using the scope clause disables the deprecated importing WITH clause.
A scope clause can be used to import all, specific, or none of the variables from the outer scope.
MATCH (p:Player), (t:Team)
CALL (p) {
WITH rand() AS random
SET p.rating = random
RETURN p.name AS playerName, p.rating AS rating
}
RETURN playerName, rating, t.name AS team
ORDER BY playerName, team
╒══════════╤════════════════════╤════════╕ │playerName│rating │team │ ╞══════════╪════════════════════╪════════╡ │"Player A"│0.034997604512386205│"Team A"│ ├──────────┼────────────────────┼────────┤ │"Player A"│0.4015905767341509 │"Team B"│ ├──────────┼────────────────────┼────────┤ │"Player A"│0.42979253602062717 │"Team C"│ ├──────────┼────────────────────┼────────┤ │"Player B"│0.25000811308300397 │"Team A"│ ├──────────┼────────────────────┼────────┤ │"Player B"│0.40406862509580077 │"Team B"│ ├──────────┼────────────────────┼────────┤ │"Player B"│0.5325840042358735 │"Team C"│ ├──────────┼────────────────────┼────────┤ │"Player C"│0.24117595612104115 │"Team A"│ ├──────────┼────────────────────┼────────┤ │"Player C"│0.7879965287359265 │"Team B"│ ├──────────┼────────────────────┼────────┤ │"Player C"│0.664434157705136 │"Team C"│ ├──────────┼────────────────────┼────────┤ │"Player D"│0.005022302305862536│"Team A"│ ├──────────┼────────────────────┼────────┤ │"Player D"│0.684610290762187 │"Team B"│ ├──────────┼────────────────────┼────────┤ │"Player D"│0.2534054901839624 │"Team C"│ ├──────────┼────────────────────┼────────┤ │"Player E"│0.3837709074218547 │"Team A"│ ├──────────┼────────────────────┼────────┤ │"Player E"│0.737259434906008 │"Team B"│ ├──────────┼────────────────────┼────────┤ │"Player E"│0.9678799128197515 │"Team C"│ ├──────────┼────────────────────┼────────┤ │"Player F"│0.348585126623145 │"Team A"│ ├──────────┼────────────────────┼────────┤ │"Player F"│0.9855839542934964 │"Team B"│ ├──────────┼────────────────────┼────────┤ │"Player F"│0.6684034304724364 │"Team C"│ └──────────┴────────────────────┴────────┘
Import all variables from the outer scope:
MATCH (p:Player), (t:Team)
CALL (*) {
SET p.lastUpdated = timestamp()
SET t.lastUpdated = timestamp()
}
RETURN p.name AS playerName,
p.lastUpdated AS playerUpdated,
t.name AS teamName,
t.lastUpdated AS teamUpdated
ORDER BY playerName, teamName
╒══════════╤═════════════╤════════╤═════════════╕ │playerName│playerUpdated│teamName│teamUpdated │ ╞══════════╪═════════════╪════════╪═════════════╡ │"Player A"│1741165716321│"Team A"│1741165716321│ ├──────────┼─────────────┼────────┼─────────────┤ │"Player A"│1741165716321│"Team B"│1741165716321│ ├──────────┼─────────────┼────────┼─────────────┤ │"Player A"│1741165716321│"Team C"│1741165716321│ ├──────────┼─────────────┼────────┼─────────────┤ │"Player B"│1741165716321│"Team A"│1741165716321│ ├──────────┼─────────────┼────────┼─────────────┤ │"Player B"│1741165716321│"Team B"│1741165716321│ ├──────────┼─────────────┼────────┼─────────────┤ │"Player B"│1741165716321│"Team C"│1741165716321│ ├──────────┼─────────────┼────────┼─────────────┤ │"Player C"│1741165716321│"Team A"│1741165716321│ ├──────────┼─────────────┼────────┼─────────────┤ │"Player C"│1741165716321│"Team B"│1741165716321│ ├──────────┼─────────────┼────────┼─────────────┤ │"Player C"│1741165716321│"Team C"│1741165716321│ ├──────────┼─────────────┼────────┼─────────────┤ │"Player D"│1741165716321│"Team A"│1741165716321│ ├──────────┼─────────────┼────────┼─────────────┤ │"Player D"│1741165716321│"Team B"│1741165716321│ ├──────────┼─────────────┼────────┼─────────────┤ │"Player D"│1741165716321│"Team C"│1741165716321│ ├──────────┼─────────────┼────────┼─────────────┤ │"Player E"│1741165716321│"Team A"│1741165716321│ ├──────────┼─────────────┼────────┼─────────────┤ │"Player E"│1741165716321│"Team B"│1741165716321│ ├──────────┼─────────────┼────────┼─────────────┤ │"Player E"│1741165716321│"Team C"│1741165716321│ ├──────────┼─────────────┼────────┼─────────────┤ │"Player F"│1741165716321│"Team A"│1741165716321│ ├──────────┼─────────────┼────────┼─────────────┤ │"Player F"│1741165716321│"Team B"│1741165716321│ ├──────────┼─────────────┼────────┼─────────────┤ │"Player F"│1741165716321│"Team C"│1741165716321│ └──────────┴─────────────┴────────┴─────────────┘
To import no variables from the outer scope, use CALL ().
MATCH (t:Team)
CALL () {
MATCH (p:Player)
RETURN count(p) AS totalPlayers
}
RETURN count(t) AS totalTeams, totalPlayers
╒══════════╤════════════╕ │totalTeams│totalPlayers│ ╞══════════╪════════════╡ │3 │6 │ └──────────┴────────────┘
Rules
-
The scope clause’s variables can be globally referenced in the subquery. A subsequent
WITHwithin the subquery cannot delist an imported variable. The deprecated importingWITHclause behaves differently because imported variables can only be referenced from the first line and can be delisted by subsequent clauses. -
Variables cannot be aliased in the scope clause. Only simple variable references are allowed.
MATCH (t:Team)
CALL (t AS teams) {
MATCH (p:Player)-[:PLAYS_FOR]->(teams)
RETURN collect(p) as players
}
RETURN t AS teams, players-
The scope clause’s variables cannot be re-declared in the subquery.
MATCH (t:Team)
CALL (t) {
WITH 'New team' AS t
MATCH (p:Player)-[:PLAYS_FOR]->(t)
RETURN collect(p) as players
}
RETURN t AS team, players-
The subquery cannot return a variable name which already exists in the outer scope. To return imported variables they must be renamed.
MATCH (t:Team)
CALL (t) {
RETURN t
}
RETURN tOptional subquery calls
OPTIONAL CALL allows for optional execution of a CALL subquery. Similar to OPTIONAL MATCH any empty rows produced by the OPTIONAL CALL subquery will return null.
MATCH (p:Player)
OPTIONAL CALL (p) {
MATCH (p)-[:PLAYS_FOR]->(team:Team)
RETURN team
}
RETURN p.name AS playerName, team.name AS team
╒══════════╤════════╕ │playerName│team │ ╞══════════╪════════╡ │"Player A"│"Team A"│ ├──────────┼────────┤ │"Player B"│"Team A"│ ├──────────┼────────┤ │"Player C"│null │ ├──────────┼────────┤ │"Player D"│"Team B"│ ├──────────┼────────┤ │"Player E"│"Team C"│ ├──────────┼────────┤ │"Player F"│"Team C"│ └──────────┴────────┘
Execution order of CALL subqueries
The order in which rows from the outer scope are passed into subqueries is not defined. If the results of the subquery depend on the order of these rows, use an ORDER BY clause before the CALL clause to guarantee a specific processing order for the rows.
MATCH (player:Player)
WITH player
ORDER BY player.age ASC LIMIT 1
SET player:ListHead
WITH *
MATCH (nextPlayer: Player&!ListHead)
WITH nextPlayer
ORDER BY nextPlayer.age
CALL (nextPlayer) {
MATCH (current:ListHead)
REMOVE current:ListHead
SET nextPlayer:ListHead
CREATE(current)-[:IS_YOUNGER_THAN]->(nextPlayer)
RETURN current AS from, nextPlayer AS to
}
RETURN
from.name AS name,
from.age AS age,
to.name AS closestOlderName,
to.age AS closestOlderAge
╒══════════╤═══╤════════════════╤═══════════════╕ │name │age│closestOlderName│closestOlderAge│ ╞══════════╪═══╪════════════════╪═══════════════╡ │"Player C"│19 │"Player B" │23 │ ├──────────┼───┼────────────────┼───────────────┤ │"Player B"│23 │"Player A" │24 │ ├──────────┼───┼────────────────┼───────────────┤ │"Player A"│24 │"Player E" │25 │ ├──────────┼───┼────────────────┼───────────────┤ │"Player E"│25 │"Player D" │30 │ ├──────────┼───┼────────────────┼───────────────┤ │"Player D"│30 │"Player F" │35 │ └──────────┴───┴────────────────┴───────────────┘
Post-union processing
Call subqueries can be used to further process the results of a UNION query.
CALL () {
MATCH (p:Player)
RETURN p
ORDER BY p.age ASC
LIMIT 1
UNION
MATCH (p:Player)
RETURN p
ORDER BY p.age DESC
LIMIT 1
}
RETURN p.name AS playerName, p.age AS age
╒══════════╤═══╕ │playerName│age│ ╞══════════╪═══╡ │"Player C"│19 │ ├──────────┼───┤ │"Player F"│35 │ └──────────┴───┘
Find how much every team is owed:
MATCH (t:Team)
CALL (t) {
OPTIONAL MATCH (t)-[o:OWES]->(other:Team)
RETURN o.dollars * -1 AS moneyOwed
UNION ALL
OPTIONAL MATCH (other)-[o:OWES]->(t)
RETURN o.dollars AS moneyOwed
}
RETURN t.name AS team, sum(moneyOwed) AS amountOwed
ORDER BY amountOwed DESC
╒════════╤══════════╕ │team │amountOwed│ ╞════════╪══════════╡ │"Team B"│7800 │ ├────────┼──────────┤ │"Team C"│-3300 │ ├────────┼──────────┤ │"Team A"│-4500 │ └────────┴──────────┘
Aggregations
Returning subqueries change the number of results of the query. The result of the CALL subquery is the combined result of evaluating the subquery for each input row.
CALL subquery changing returned rows of outer queryThe following example finds the name of each Player and the team they play for. No rows are returned for Player C, since they are not connected to a Team with a PLAYS_FOR relationship. The number of results of the subquery thus changed the number of results of the enclosing query.
MATCH (p:Player)
CALL (p) {
MATCH (p)-[:PLAYS_FOR]->(team:Team)
RETURN team.name AS team
}
RETURN p.name AS playerName, team
╒══════════╤════════╕ │playerName│team │ ╞══════════╪════════╡ │"Player A"│"Team A"│ ├──────────┼────────┤ │"Player B"│"Team A"│ ├──────────┼────────┤ │"Player D"│"Team B"│ ├──────────┼────────┤ │"Player E"│"Team C"│ ├──────────┼────────┤ │"Player F"│"Team C"│ └──────────┴────────┘
CALL subqueries and isolated aggregationsSubqueries can also perform isolated aggregations. The below example uses the sum() function to count how much money is owed between the Team nodes in the graph. Note that the owedAmount for Team A is the aggregated results of two OWES relationships to Team B.
MATCH (t:Team)
CALL (t) {
MATCH (t)-[o:OWES]->(t2:Team)
RETURN sum(o.dollars) AS owedAmount, t2.name AS owedTeam
}
RETURN t.name AS owingTeam, owedAmount, owedTeam
╒═════════╤══════════╤════════╕ │owingTeam│owedAmount│owedTeam│ ╞═════════╪══════════╪════════╡ │"Team A" │4500 │"Team B"│ ├─────────┼──────────┼────────┤ │"Team B" │1700 │"Team C"│ ├─────────┼──────────┼────────┤ │"Team C" │5000 │"Team B"│ └─────────┴──────────┴────────┘
Note on returning subqueries and unit subqueries
The examples above have all used subqueries which end with a RETURN clause. These subqueries are called returning subqueries.
A subquery is evaluated for each incoming input row. Every output row of a returning subquery is combined with the input row to build the result of the subquery. That means that a returning subquery will influence the number of rows. If the subquery does not return any rows, there will be no rows available after the subquery.
Subqueries without a RETURN statement are called unit subqueries. Unit subqueries are used for their ability to alter the graph with clauses such as CREATE, MERGE, SET, and DELETE. They do not explicitly return anything, and this means that the number of rows present after the subquery is the same as was going into the subquery.
Unit subqueries
Unit subqueries are used for their ability to alter the graph with updating clauses. They do not impact the amount of rows returned by the enclosing query.
MATCH (p:Player)
CALL (p) {
UNWIND range (1, 3) AS i
CREATE (:Person {name: p.name})
}
RETURN count(*)
╒════════╕ │count(*)│ ╞════════╡ │6 │ └────────┘
CALL subqueries in transactions
CALL subqueries can be made to execute in separate, inner transactions, producing intermediate commits. This can be useful when doing large write operations, like batch updates, imports, and deletes.
To execute a CALL subquery in separate transactions, add the modifier IN TRANSACTIONS after the subquery. An outer transaction is opened to report back the accumulated statistics for the inner transactions (created and deleted nodes, relationships, etc.) and it will succeed or fail depending on the results of those inner transactions. By default, inner transactions group together batches of 1000 rows. Cancelling the outer transaction will cancel the inner ones as well.

CALL {
subQuery
} IN [[concurrency] CONCURRENT] TRANSACTIONS
[OF batchSize ROW[S]]
[REPORT STATUS AS statusVar]
[ON ERROR {CONTINUE | BREAK | FAIL}];
Loading CSV data
friends.csv:
1,Bill,26 2,Max,27 3,Anna,22 4,Gladys,29 5,Summer,24
LOAD CSV FROM 'file:///friends.csv' AS line
CALL (line) {
CREATE (:Person {name: line[1], age: toInteger(line[2])})
} IN TRANSACTIONS
Deleting a large volume of data
Using CALL { … } IN TRANSACTIONS is the recommended way of deleting a large volume of data.
MATCH (n)
CALL (n) {
DETACH DELETE n
} IN TRANSACTIONS
The CALL { … } IN TRANSACTIONS subquery should not be modified.
Any necessary filtering can be done before the subquery.
MATCH (n:Label) WHERE n.prop > 100
CALL (n) {
DETACH DELETE n
} IN TRANSACTIONS
Batching
The amount of work to do in each separate transaction can be specified in terms of how many input rows to process before committing the current transaction and starting a new one. The number of input rows is set with the modifier OF n ROWS (or OF n ROW). If omitted, the default batch size is 1000 rows. The number of rows can be expressed using any expression that evaluates to a positive integer and does not refer to nodes or relationships.
LOAD CSV FROM 'file:///friends.csv' AS line
CALL (line) {
CREATE (:Person {name: line[1], age: toInteger(line[2])})
} IN TRANSACTIONS OF 2 ROWS
Composite databases
As of Neo4j 5.18, CALL { … } IN TRANSACTIONS can be used with composite databases.
Even though composite databases allow accessing multiple graphs in a single query, only one graph can be modified in a single transaction. CALL { … } IN TRANSACTIONS offers a way of constructing queries which modify multiple graphs.
Create Person nodes on all constituents, drawing data from friends.csv:
UNWIND graph.names() AS graphName
LOAD CSV FROM 'file:///friends.csv' AS line
CALL (*) {
USE graph.byName( graphName )
CREATE (:Person {name: line[1], age: toInteger(line[2])})
} IN TRANSACTIONS
Example 4. Remove all nodes and relationships from all constituents:
UNWIND graph.names() AS graphName
CALL (*) {
USE graph.byName( graphName )
MATCH (n)
RETURN elementId(n) AS id
}
CALL (*) {
USE graph.byName( graphName )
MATCH (n)
WHERE elementId(n) = id
DETACH DELETE n
} IN TRANSACTIONS


Batch size in composite databases
Because CALL { … } IN TRANSACTIONS subqueries targeting different graphs can’t be interleaved, if a USE clause evaluates to a different target than the current one, the current batch is committed and the next batch is created.
The batch size declared with IN TRANSACTIONS OF … ROWS represents an upper limit of the batch size, but the real batch size depends on how many input rows target one database in sequence. Every time the target database changes, the batch is committed.
IN TRANSACTIONS OF ROWS on composite databasesThe next example assumes the existence of two constituents remoteGraph1 and remoteGraph2 for the composite database composite.
While the declared batch size is 3, only the first 2 rows act on composite.remoteGraph1, so the batch size for the first transaction is 2. That is followed by 3 rows on composite.remoteGraph2, 1 on composite.remoteGraph2 and finally 2 on composite.remoteGraph1.
WITH ['composite.remoteGraph1', 'composite.remoteGraph2'] AS graphs
UNWIND [0, 0, 1, 1, 1, 1, 0, 0] AS i
WITH graphs[i] AS g
CALL (g) {
USE graph.byName( g )
CREATE ()
} IN TRANSACTIONS OF 3 ROWS
Error behavior
Users can choose one of three different option flags to control the behavior in case of an error occurring in any of the inner transactions of CALL { … } IN TRANSACTIONS:
-
ON ERROR CONTINUEto ignore a recoverable error and continue the execution of subsequent inner transactions. The outer transaction succeeds. It will cause the expected variables from the failed inner query to be bound as null for that specific transaction. -
ON ERROR BREAKto ignore a recoverable error and stop the execution of subsequent inner transactions. The outer transaction succeeds. It will cause expected variables from the failed inner query to be bound as null for all onward transactions (including the failed one). -
ON ERROR FAILto acknowledge a recoverable error and stop the execution of subsequent inner transactions. The outer transaction fails. This is the default behavior if no flag is explicitly specified.

Status report
Users can also report the execution status of the inner transactions by using REPORT STATUS AS var. This flag is disallowed for ON ERROR FAIL. For more information, see Error behavior.
After each execution of the inner query finishes (successfully or not), a status value is created that records information about the execution and the transaction that executed it:
-
If the inner execution produces one or more rows as output, then a binding to this status value is added to each row, under the selected variable name.
-
If the inner execution fails then a single row is produced containing a binding to this status value under the selected variable, and null bindings for all variables that should have been returned by the inner query (if any).
The status value is a map value with the following fields:
-
started:truewhen the inner transaction was started,falseotherwise. -
committed,truewhen the inner transaction changes were successfully committed,falseotherwise. -
transactionId: the inner transaction id, ornullif the transaction was not started. -
errorMessage, the inner transaction error message, ornullin case of no error.
:auto
UNWIND [1, 0, 2, 4] AS i CALL (i) { CREATE (n:Person {num: 100/i}) // Note, fails when i = 0 RETURN n } IN TRANSACTIONS OF 1 ROW ON ERROR CONTINUE REPORT STATUS AS s RETURN n.num, s;
╒═════╤═════════════════════════════════════════════════════════════════════════════════════════════════════╕
│n.num│s │
╞═════╪═════════════════════════════════════════════════════════════════════════════════════════════════════╡
│100 │{errorMessage: null, transactionId: "neo4j-transaction-1291", committed: true, started: true} │
├─────┼─────────────────────────────────────────────────────────────────────────────────────────────────────┤
│null │{errorMessage: "/ by zero", transactionId: "neo4j-transaction-1292", committed: false, started: true}│
├─────┼─────────────────────────────────────────────────────────────────────────────────────────────────────┤
│50 │{errorMessage: null, transactionId: "neo4j-transaction-1293", committed: true, started: true} │
├─────┼─────────────────────────────────────────────────────────────────────────────────────────────────────┤
│25 │{errorMessage: null, transactionId: "neo4j-transaction-1294", committed: true, started: true} │
└─────┴─────────────────────────────────────────────────────────────────────────────────────────────────────┘
:auto
UNWIND [1, 0, 2, 4] AS i
CALL (i) {
CREATE (n:Person {num: 100/i}) // Note, fails when i = 0
RETURN n
} IN TRANSACTIONS
OF 1 ROW
ON ERROR BREAK
REPORT STATUS AS s
RETURN n.num, s.started, s.committed, s.errorMessage;
╒═════╤═════════╤═══════════╤══════════════╕ │n.num│s.started│s.committed│s.errorMessage│ ╞═════╪═════════╪═══════════╪══════════════╡ │100 │true │true │null │ ├─────┼─────────┼───────────┼──────────────┤ │null │true │false │"/ by zero" │ ├─────┼─────────┼───────────┼──────────────┤ │null │false │false │null │ ├─────┼─────────┼───────────┼──────────────┤ │null │false │false │null │ └─────┴─────────┴───────────┴──────────────┘
Concurrent transactions
By default, CALL { … } IN TRANSACTIONS is single-threaded; one CPU core is used to sequentially execute batches.
However, CALL subqueries can also execute batches in parallel by appending IN [n] CONCURRENT TRANSACTIONS, where n is a concurrency value used to set the maximum number of transactions that can be executed in parallel. This allows CALL subqueries to utilize multiple CPU cores simultaneously, which can significantly reduce the time required to execute a large, outer transaction.

CALL { … } IN CONCURRENT TRANSACTIONS is particularly suitable for importing data without dependencies. This example creates Person nodes from a unique tmdbId value assigned to each person row in the CSV file (444 in total) in 3 concurrent transactions.
LOAD CSV WITH HEADERS FROM 'https://data.neo4j.com/importing-cypher/persons.csv' AS row
CALL (row) {
CREATE (p:Person {tmdbId: row.person_tmdbId})
SET p.name = row.name, p.born = row.born
} IN 3 CONCURRENT TRANSACTIONS OF 10 ROWS
RETURN count(*) AS personNodes
Concurrency and non-deterministic results
CALL { … } IN TRANSACTIONS uses ordered semantics by default, where batches are committed in a sequential row-by-row order. For example, in CALL { <I> } IN TRANSACTIONS, any writes done in the execution of <I1> must be observed by <I2>, and so on.
In contrast, CALL { … } IN CONCURRENT TRANSACTIONS uses concurrent semantics, where both the number of rows committed by a particular batch and the order of committed batches is undefined. That is, in CALL { <I> } IN CONCURRENT TRANSACTIONS, writes committed in the execution of <I1> may or may not be observed by <I2>, and so on.
The results of CALL subqueries executed in concurrent transactions may, therefore, not be deterministic. To guarantee deterministic results, ensure that the results of committed batches are not dependent on each other.

Deadlocks
When a write transaction occurs, Neo4j takes locks to preserve data consistency while updating. For example, when creating or deleting a relationship, a write lock is taken on both the specific relationship and its connected nodes.
A deadlock happens when two transactions are blocked by each other because they are attempting to concurrently modify a node or a relationship that is locked by the other transaction (for more information about locks and deadlocks in Neo4j, see Operations Manual → Concurrent data access.
A deadlock may occur when using CALL { … } IN CONCURRENT TRANSACTIONS if the transactions for two or more batches try to take the same locks in an order that results in a circular dependency between them. If so, the impacted transactions are always rolled back, and an error is thrown unless the query is appended with ON ERROR CONTINUE or ON ERROR BREAK.
The following query tries to create Movie and Year nodes connected by a RELEASED_IN relationship. Note that there are only three different years in the CSV file, meaning that only three Year nodes should be created.
Query with concurrent transaction causing a deadlock:
LOAD CSV WITH HEADERS FROM 'https://data.neo4j.com/importing-cypher/movies.csv' AS row
CALL (row) {
MERGE (m:Movie {movieId: row.movieId})
MERGE (y:Year {year: row.year})
MERGE (m)-[r:RELEASED_IN]->(y)
} IN 2 CONCURRENT TRANSACTIONS OF 10 ROWS
The deadlock occurs because the two transactions are simultaneously trying to lock and merge the same Year.
ForsetiClient[transactionId=64, clientId=12] can't acquire ExclusiveLock{owner=ForsetiClient[transactionId=63, clientId=9]} on NODE_RELATIONSHIP_GROUP_DELETE(98) because holders of that lock are waiting for ForsetiClient[transactionId=64, clientId=12].
Wait list:ExclusiveLock[
Client[63] waits for [ForsetiClient[transactionId=64, clientId=12]]]The following query uses ON ERROR CONTINUE to bypass any deadlocks and continue with the execution of subsequent inner transactions. It returns the transactionID, commitStatus and errorMessage of the failed transactions.
Query using ON ERROR CONTINUE to ignore deadlocks and complete outer transaction:
LOAD CSV WITH HEADERS FROM 'https://data.neo4j.com/importing-cypher/movies.csv' AS row
CALL (row) {
MERGE (m:Movie {movieId: row.movieId})
MERGE (y:Year {year: row.year})
MERGE (m)-[r:RELEASED_IN]->(y)
} IN 2 CONCURRENT TRANSACTIONS OF 10 ROWS ON ERROR CONTINUE REPORT STATUS as status
WITH status
WHERE status.errorMessage IS NOT NULL
RETURN status.transactionId AS transaction, status.committed AS commitStatus, status.errorMessage AS errorMessage
Restrictions
These are the restrictions on queries that use CALL { … } IN TRANSACTIONS:
-
A nested
CALL { … } IN TRANSACTIONSinside aCALL { … }clause is not supported. -
A
CALL { … } IN TRANSACTIONSin aUNIONis not supported. -
A
CALL { … } IN TRANSACTIONSafter a write clause is not supported, unless that write clause is inside aCALL { … } IN TRANSACTIONS.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2024-02-20 Go - range
2024-02-20 Go 100 mistakes - #29: Comparing values incorrectly
2024-02-20 Go 100 mistakes - #28: Maps and memory leaks