

MATCH
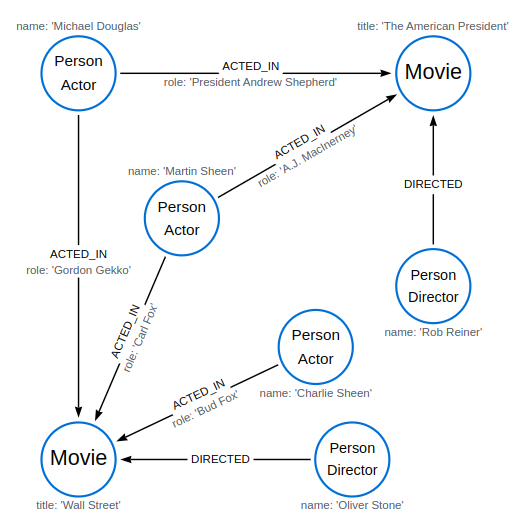
Find nodes
Find all nodes in a graph
MATCH (n) RETURN n
Find nodes with a specific label
MATCH (movie:Movie) RETURN movie.title
MATCH using node label expressions
Node pattern using the OR (|) label expression
MATCH (n:Movie|Person) RETURN n.name AS name, n.title AS title
Node pattern using negation (!) label expression
MATCH (n:!Movie) RETURN labels(n) AS label, count(n) AS count
Find relationships
The MATCH clause allows you to specify relationship patterns of varying complexity to retrieve from a graph. Unlike a node pattern, a relationship pattern cannot be used in a MATCH clause without node patterns at both ends. For more information about relationship patterns, see Patterns → Relationship patterns.

Empty relationship patterns
By applying --, a pattern will be matched for a relationship with any direction and without any filtering on relationship types or properties.
MATCH (:Person {name: 'Oliver Stone'})--(n)
RETURN n AS connectedNodes
╒═══════════════════════════════╕
│connectedNodes │
╞═══════════════════════════════╡
│(:Movie {title: "Wall Street"})│
└───────────────────────────────┘
Directed relationship patterns
The direction of a relationship in a pattern is indicated by arrows: --> or <--.
Relationship variables
It is possible to introduce a variable to a pattern, either for filtering on relationship properties or to return a relationship.
Find the types of an aliased relationship
MATCH (:Person {name: 'Oliver Stone'})-[r]->()
RETURN type(r) AS relType
MATCH on an undirected relationship
When a pattern contains a bound relationship, and that relationship pattern does not specify direction, Cypher will match the relationship in both directions.
Relationship pattern without direction
MATCH (a)-[:ACTED_IN {role: 'Bud Fox'}]-(b)
RETURN a, b
╒═══════════════════════════════════════╤═══════════════════════════════════════╕
│a │b │
╞═══════════════════════════════════════╪═══════════════════════════════════════╡
│(:Person:Actor {name: "Charlie Sheen"})│(:Movie {title: "Wall Street"}) │
├───────────────────────────────────────┼───────────────────────────────────────┤
│(:Movie {title: "Wall Street"}) │(:Person:Actor {name: "Charlie Sheen"})│
└───────────────────────────────────────┴───────────────────────────────────────┘
Filter on relationship types
It is possible to specify the type of a relationship in a relationship pattern by using a colon (:) before the relationship type.
MATCH (:Movie {title: 'Wall Street'})<-[:ACTED_IN]-(actor:Person)
RETURN actor.name AS actor
MATCH using relationship type expressions
It is possible to match a pattern containing one of several relationship types using the OR symbol, |.
Relationship pattern including either ACTED_IN or DIRECTED relationship types
MATCH (:Movie {title: 'Wall Street'})<-[:ACTED_IN|DIRECTED]-(person:Person)
RETURN person.name AS person
As relationships can only have exactly one type each, ()-[:A&B]→() will never match a relationship.
Find multiple relationships
A graph pattern can contain several relationship patterns.
MATCH (:Person {name: 'Charlie Sheen'})-[:ACTED_IN]->(movie:Movie)<-[:DIRECTED]-(director:Person)
RETURN movie.title AS movieTitle, director.name AS director
MATCH with WHERE predicates
MATCH (charlie:Person)-[:ACTED_IN]->(movie:Movie) WHERE charlie.name = 'Charlie Sheen' RETURN movie.title AS movieTitle
MATCH (martin:Person)-[:ACTED_IN]->(movie:Movie)
WHERE martin.name = 'Martin Sheen' AND NOT EXISTS {
MATCH (movie)<-[:DIRECTED]-(director:Person {name: 'Oliver Stone'})
}
RETURN movie.title AS movieTitle
Find paths
MATCH path = ()-[:ACTED_IN]->(movie:Movie) RETURN path
MATCH path = (:Person)-[:ACTED_IN]->(movie:Movie)<-[:DIRECTED]-(:Person) WHERE movie.title = 'Wall Street' RETURN path
Multiple MATCH clauses, the WITH clause, and clause composition
In Cypher, the behavior of a query is defined by its clauses. Each clause takes the current graph state and a table of intermediate results, processes them, and passes the updated graph state and results to the next clause. The first clause starts with the graph’s initial state and an empty table, while the final clause produces the query result.
Chaining consecutive MATCH clauses
MATCH (:Person {name: 'Martin Sheen'})-[:ACTED_IN]->(movie:Movie)
MATCH (director:Person)-[:DIRECTED]->(movie)
RETURN director.name AS director, movie.title AS movieTitle

A variable can be implicitly carried over to the following clause by being referenced in another operation. A variable can also be explicitly passed to the following clause using the WITH clause. If a variable is neither implicitly nor explicitly carried over to its following clause, it will be discarded and is not available for reference later in the query.
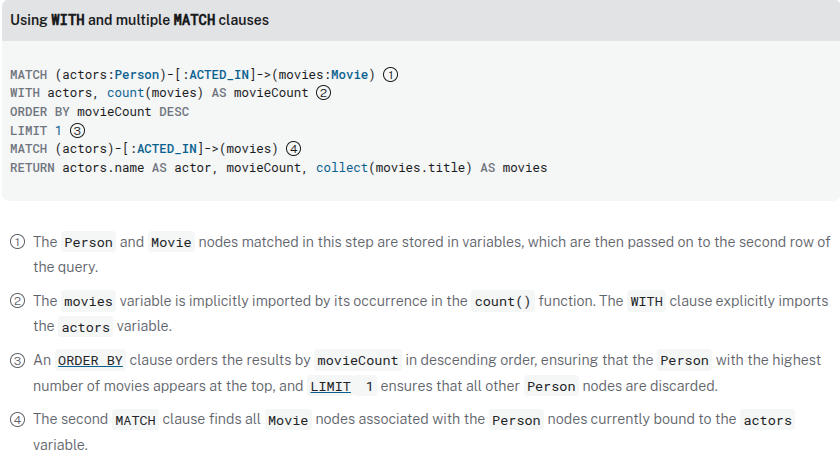
╒══════════════╤══════════╤═════════════════════════════════════════╕ │actor │movieCount│movies │ ╞══════════════╪══════════╪═════════════════════════════════════════╡ │"Martin Sheen"│2 │["Wall Street", "The American President"]│ └──────────────┴──────────┴─────────────────────────────────────────┘
MATCH using dynamic node labels and relationship types
Node labels and relationship types can be referenced dynamically in expressions, parameters, and variables when matching nodes and relationships. This allows for more flexible queries and mitigates the risk of Cypher injection.
Syntax for matching node labels dynamically
MATCH (n:$(<expr>)) MATCH (n:$any(<expr>)) MATCH (n:$all(<expr>))

Syntax for matching relationship types dynamically
MATCH ()-[r:$(<expr>))]->() MATCH ()-[r:$any(<expr>)]->() MATCH ()-[r:$all(<expr>))]->()
Match labels dynamically
WITH ["Person", "Director"] AS labels MATCH (directors:$(labels)) RETURN directors
Match nodes dynamically using any()
MATCH (n:$any(["Movie", "Actor"])) RETURN n AS nodes
Match nodes dynamically using a parameter
:param {
"label": "Movie"
}
MATCH (movie:$($label))
RETURN movie.title AS movieTitle
Match relationships dynamically using a variable
CALL db.relationshipTypes() YIELD relationshipType MATCH ()-[r:$(relationshipType)]->() RETURN relationshipType, count(r) AS relationshipCount
Performance caveats
MATCH queries using dynamic values may not be as performant as those using static values. This is because the Cypher planner uses statically available information when planning queries to determine whether to use an index or not, and this is not possible when using dynamic values.
As a result, MATCH queries using dynamic values cannot leverage index scans or seeks and must instead use the AllNodesScan operator, which reads all nodes from the node store and is therefore more costly.
MERGE
The MERGE clause either matches existing node patterns in the graph and binds them or, if not present, creates new data and binds that. In this way, it acts as a combination of MATCH and CREATE that allows for specific actions depending on whether the specified data was matched or created.
For example, MERGE can be used to specify that a graph must contain a node with a Person label and a specific name property. If there isn’t a node with the specific name property, a new node will be created with that name property.

When using MERGE on full patterns, the behavior is that either the whole pattern matches, or the whole pattern is created. MERGE will not partially use existing patterns. If partial matches are needed, this can be accomplished by splitting a pattern into multiple MERGE clauses.
Similar to MATCH, MERGE can match multiple occurrences of a pattern. If there are multiple matches, they will all be passed on to later stages of the query.
The last part of a MERGE clause is the ON CREATE and/or ON MATCH operators. These allow a query to express additional changes to the properties of a node or relationship, depending on whether the element was matched (MATCH) in the database or if it was created (CREATE).
Merge nodes
Merge single node with a label
MERGE (robert:Critic) RETURN labels(robert)
A new node is created because there are no nodes labeled Critic in the database.
Merge single node with multiple labels
MERGE (robert:Critic:Viewer) RETURN labels(robert)
A new node is created because there are no nodes labeled both Critic and Viewer in the database.
Merge single node with properties
MERGE (charlie {name: 'Charlie Sheen', age: 10})
RETURN charlie

MERGE (martin:Person {name: 'Martin Sheen', age: null})
RETURN martin

Merge single node specifying both label and property
Merge single node derived from an existing node property
MATCH (person:Person)
MERGE (location:Location {name: person.bornIn})
RETURN person.name, person.bornIn, location
Merge with ON CREATE
Merge a node and set properties if the node needs to be created:
MERGE (keanu:Person {name: 'Keanu Reeves', bornIn: 'Beirut', chauffeurName: 'Eric Brown'})
ON CREATE
SET keanu.created = timestamp()
RETURN keanu.name, keanu.created
Merge with ON MATCH
Merging nodes and setting properties on found nodes:
MERGE (person:Person) ON MATCH SET person.found = true RETURN person.name, person.found
Merge with ON CREATE and ON MATCH
Merge with ON MATCH setting multiple properties
MERGE (person:Person)
ON MATCH
SET
person.found = true,
person.lastAccessed = timestamp()
RETURN person.name, person.found, person.lastAccessed
Merge relationships
Merge on a relationship
MATCH
(charlie:Person {name: 'Charlie Sheen'}),
(wallStreet:Movie {title: 'Wall Street'})
MERGE (charlie)-[r:ACTED_IN]->(wallStreet)
RETURN charlie.name, type(r), wallStreet.title

MERGE (martin:Person {name: 'Martin Sheen'})-[r:FATHER_OF {since: null}]->(charlie:Person {name: 'Charlie Sheen'})
RETURN type(r)

Merge on multiple relationships
MATCH
(oliver:Person {name: 'Oliver Stone'}),
(reiner:Person {name: 'Rob Reiner'})
MERGE (oliver)-[:DIRECTED]->(movie:Movie)<-[:DIRECTED]-(reiner)
RETURN movie
Merge on an undirected relationship
MERGE can also be used without specifying the direction of a relationship. Cypher® will first try to match the relationship in both directions. If the relationship does not exist in either direction, it will create one left to right.
MATCH
(charlie:Person {name: 'Charlie Sheen'}),
(oliver:Person {name: 'Oliver Stone'})
MERGE (charlie)-[r:KNOWS]-(oliver)
RETURN r
As Charlie Sheen and Oliver Stone do not know each other in the example graph, this MERGE query will create a KNOWS relationship between them. The direction of the created relationship is left to right.
Merge on a relationship between two existing nodes
MERGE can be used in conjunction with preceding MATCH and MERGE clauses to create a relationship between two bound nodes m and n, where m is returned by MATCH and n is created or matched by the earlier MERGE.
MATCH (person:Person)
MERGE (location:Location {name: person.bornIn})
MERGE (person)-[r:BORN_IN]->(location)
RETURN person.name, person.bornIn, location
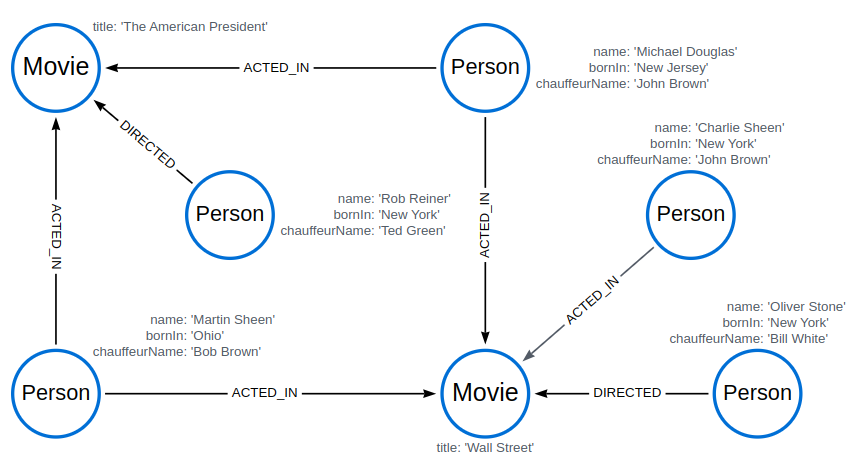
Merge on a relationship between an existing node and a merged node derived from a node property
MERGE can be used to simultaneously create both a new node n and a relationship between a bound node m and n:
MATCH (person:Person)
MERGE (person)-[r:HAS_CHAUFFEUR]->(chauffeur:Chauffeur {name: person.chauffeurName})
RETURN person.name, person.chauffeurName, chauffeur
As MERGE found no matches — in the example graph, there are no nodes labeled with Chauffeur and no HAS_CHAUFFEUR relationships — MERGE creates six nodes labeled with Chauffeur, each of which contains a name property whose value corresponds to each matched Person node’s chauffeurName property value. MERGE also creates a HAS_CHAUFFEUR relationship between each Person node and the newly-created corresponding Chauffeur node.

╒═════════════════╤════════════════════╤═════════════════════════════════╕
│person.name │person.chauffeurName│chauffeur │
╞═════════════════╪════════════════════╪═════════════════════════════════╡
│"Charlie Sheen" │"John Brown" │(:Chauffeur {name: "John Brown"})│
├─────────────────┼────────────────────┼─────────────────────────────────┤
│"Martin Sheen" │"Bob Brown" │(:Chauffeur {name: "Bob Brown"}) │
├─────────────────┼────────────────────┼─────────────────────────────────┤
│"Michael Douglas"│"John Brown" │(:Chauffeur {name: "John Brown"})│
├─────────────────┼────────────────────┼─────────────────────────────────┤
│"Oliver Stone" │"Bill White" │(:Chauffeur {name: "Bill White"})│
├─────────────────┼────────────────────┼─────────────────────────────────┤
│"Rob Reiner" │"Ted Green" │(:Chauffeur {name: "Ted Green"}) │
└─────────────────┴────────────────────┴─────────────────────────────────┘
Using node property uniqueness constraints with MERGE
Cypher prevents getting conflicting results from MERGE when using patterns that involve property uniqueness constraints. In this case, there must be at most one node that matches that pattern.
For example, given two property node uniqueness constraints on :Person(id) and :Person(ssn), a query such as MERGE (n:Person {id: 12, ssn: 437}) will fail, if there are two different nodes (one with id 12 and one with ssn 437), or if there is only one node with only one of the properties. In other words, there must be exactly one node that matches the pattern, or no matching nodes.
Using relationship property uniqueness constraints with MERGE
All that has been said above about node uniqueness constraints also applies to relationship uniqueness constraints. However, for relationship uniqueness constraints there are some additional things to consider.
MERGE (charlie:Person {name: 'Charlie Sheen'})-[r:ACTED_IN {year: 1987}]->(wallStreet:Movie {title: 'Wall Street'})
RETURN charlie.name, type(r), wallStreet.title
This is due to the all-or-nothing semantics of MERGE, which causes the query to fail if there exists a relationship with the given year property but there is no match for the full pattern. In this example, since no match was found for the pattern, MERGE will try to create the full pattern including a relationship with {year: 1987}, which will lead to constraint violation error.
Therefore, it is advised - especially when relationship uniqueness constraints exist - to always use bound nodes in the MERGE pattern. The following would, therefore, be a more appropriate composition of the query:
MATCH
(charlie:Person {name: 'Charlie Sheen'}),
(wallStreet:Movie {title: 'Wall Street'})
MERGE (charlie)-[r:ACTED_IN {year: 1987}]->(wallStreet)
RETURN charlie.name, type(r), wallStreet.title
OPTIONAL MATCH
OPTIONAL MATCH matches patterns against a graph database, just as MATCH does. The difference is that if no matches are found, OPTIONAL MATCH will use a null for missing parts of the pattern. OPTIONAL MATCH could therefore be considered the Cypher® equivalent of the outer join in SQL.
When using OPTIONAL MATCH, either the whole pattern is matched, or nothing is matched. The WHERE clause is part of the pattern description, and its predicates will be considered while looking for matches, not after. This matters especially in the case of multiple (OPTIONAL) MATCH clauses, where it is crucial to put WHERE together with the MATCH it belongs to.
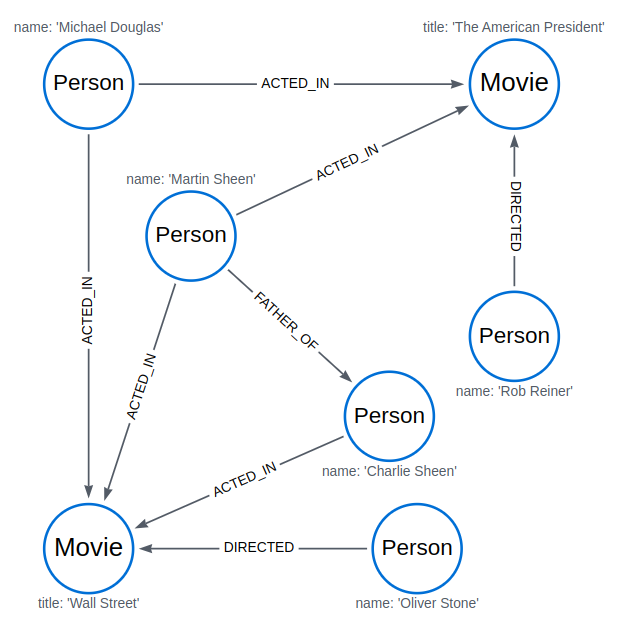
MATCH (a:Person {name: 'Martin Sheen'})
MATCH (a)-[r:DIRECTED]->()
RETURN a.name, r
(no changes, no records)
This is because the second MATCH clause returns no data (there are no DIRECTED relationships connected to Martin Sheen in the graph) to pass on to the RETURN clause.
However, replacing the second MATCH clause with OPTIONAL MATCH does return results. This is because, unlike MATCH, OPTIONAL MATCH enables the value null to be passed between clauses.
MATCH (p:Person {name: 'Martin Sheen'})
OPTIONAL MATCH (p)-[r:DIRECTED]->()
RETURN p.name, r
╒══════════════╤════╕ │p.name │r │ ╞══════════════╪════╡ │"Martin Sheen"│null│ └──────────────┴────┘
Optional relationships
If the existence of a relationship is optional, use the OPTIONAL MATCH clause. If the relationship exists, it is returned. If it does not, null is returned in its place.
MATCH (a:Movie {title: 'Wall Street'})
OPTIONAL MATCH (a)-->(x)
RETURN x
Returns null, since the Movie node Wall Street has no outgoing relationships.
Properties on optional elements
If the existence of a property is optional, use the OPTIONAL MATCH clause. null will be returned if the specified property does not exist.
MATCH (a:Movie {title: 'Wall Street'})
OPTIONAL MATCH (a)-->(x)
RETURN x, x.name
Returns the element x (null in this query), and null for its name property, because the Movie node Wall Street has no outgoing relationships.
╒════╤══════╕ │x │x.name│ ╞════╪══════╡ │null│null │ └────┴──────┘
ORDER BY
Order nodes by expression
MATCH (n) RETURN n.name, n.age, n.length ORDER BY keys(n)
The keys() function is used to retrieve a list of all property keys of a node or relationship.
MATCH (n:Person {name: 'Charlie Sheen'})
RETURN keys(n);
╒════════╕ │keys(n) │ ╞════════╡ │["name"]│ └────────┘
Ordering null
When sorting the result set, null will always come at the end of the result set for ascending sorting, and first when doing descending sort.
Ordering in a WITH clause
When ORDER BY is present on a WITH clause , the immediately following clause will receive records in the specified order. The order is not guaranteed to be retained after the following clause, unless that also has an ORDER BY subclause.
MATCH (n) WITH n ORDER BY n.age RETURN collect(n.name) AS names
Ordering aggregated or DISTINCT results
In terms of scope of variables, ORDER BY follows special rules, depending on if the projecting RETURN or WITH clause is either aggregating or DISTINCT. If it is an aggregating or DISTINCT projection, only the variables available in the projection are available. If the projection does not alter the output cardinality (which aggregation and DISTINCT do), variables available from before the projecting clause are also available. When the projection clause shadows already existing variables, only the new variables are available.
It is also not allowed to use aggregating expressions in the ORDER BY sub-clause if they are not also listed in the projecting clause. This rule is to make sure that ORDER BY does not change the results, only the order of them.
ORDER BY and indexes
The performance of Cypher queries using ORDER BY on node properties can be influenced by the existence and use of an index for finding the nodes. If the index can provide the nodes in the order requested in the query, Cypher can avoid the use of an expensive Sort operation.
UsingORDER BYas a standalone clause
ORDER BY can be used as a standalone clause, or in conjunction with SKIP/OFFSET or LIMIT.
MATCH (n) ORDER BY n.name RETURN collect(n.name) AS names
ORDER BY used in conjunction with SKIP and LIMIT
MATCH (n) ORDER BY n.name DESC SKIP 1 LIMIT 1 RETURN n.name AS name
REMOVE
The REMOVE clause is used to remove properties from nodes and relationships, and to remove labels from nodes.

Remove a property
MATCH (a {name: 'Andy'})
REMOVE a.age
RETURN a.name, a.age
Remove all properties
REMOVE cannot be used to remove all existing properties from a node or relationship. Instead, using SET with = and an empty map as the right operand will clear all properties from the node or relationship.
Dynamically remove a property
REMOVE can be used to remove a property on a node or relationship even when the property key name is not statically known. This allows for more flexible queries and mitigates the risk of Cypher® injection.
REMOVE n[key]
The dynamically calculated key must evaluate to a STRING value.
MATCH (n) WITH n, [k IN keys(n) WHERE k CONTAINS "Test" | k] as propertyKeys FOREACH (i IN propertyKeys | REMOVE n[i]) RETURN n.name, keys(n);

Remove a label from a node
MATCH (n {name: 'Peter'})
REMOVE n:German
RETURN n.name, labels(n)
Dynamically remove a node label
Introduced in 5.24
MATCH (n) REMOVE n:$(expr)
The expression must evaluate to a STRING NOT NULL | LIST<STRING NOT NULL> NOT NULL value.
MATCH (n {name: 'Peter'})
UNWIND labels(n) AS label
REMOVE n:$(label)
RETURN n.name, labels(n)
Remove multiple labels from a node
MATCH (n {name: 'Peter'})
REMOVE n:German:Swedish
RETURN n.name, labels(n)
Remove multiple labels dynamically from a node
MATCH (n {name: 'Peter'})
REMOVE n:$(labels(n))
RETURN n.name, labels(n)
RETURN
Return nodes
Return relationships
Return property
Return all elements
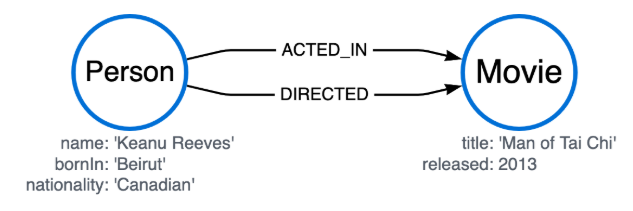
MATCH p = (keanu:Person {name: 'Keanu Reeves'})-[r]->(m)
RETURN *
This returns the two nodes, and the two possible paths between them.
╒════════════════════════════════════════════════╤════════════════════════════════════════════════╤════════════════════════════════════════════════╤═══════════╕
│keanu │m │p │r │
╞════════════════════════════════════════════════╪════════════════════════════════════════════════╪════════════════════════════════════════════════╪═══════════╡
│(:Person {bornIn: "Beirut",nationality: "Canadia│(:Movie {title: "Man of Tai Chi",released: 2013}│(:Person {bornIn: "Beirut",nationality: "Canadia│[:ACTED_IN]│
│n",name: "Keanu Reeves"}) │) │n",name: "Keanu Reeves"})-[:ACTED_IN]->(:Movie {│ │
│ │ │title: "Man of Tai Chi",released: 2013}) │ │
├────────────────────────────────────────────────┼────────────────────────────────────────────────┼────────────────────────────────────────────────┼───────────┤
│(:Person {bornIn: "Beirut",nationality: "Canadia│(:Movie {title: "Man of Tai Chi",released: 2013}│(:Person {bornIn: "Beirut",nationality: "Canadia│[:DIRECTED]│
│n",name: "Keanu Reeves"}) │) │n",name: "Keanu Reeves"})-[:DIRECTED]->(:Movie {│ │
│ │ │title: "Man of Tai Chi",released: 2013}) │ │
└────────────────────────────────────────────────┴────────────────────────────────────────────────┴────────────────────────────────────────────────┴───────────┘
Variable with uncommon characters
To introduce a variable made up of characters not contained in the English alphabet, use ` to enclose the variable:
MATCH (`/uncommon variable\`) WHERE `/uncommon variable\`.name = 'Keanu Reeves' RETURN `/uncommon variable\`.bornIn
Other expressions
Any expression can be used as a return item — literals, predicates, properties, functions, and so on.
MATCH (m:Movie {title: 'Man of Tai Chi'})
RETURN m.released < 2012, "I'm a literal",[p=(m)--() | p] AS `(m)--()`
╒═════════════════╤═══════════════╤═════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╕
│m.released < 2012│"I'm a literal"│(m)--() │
╞═════════════════╪═══════════════╪═════════════════════════════════════════════════════════════════════════════════════════════════════════════════════════╡
│false │"I'm a literal"│[(:Movie {title: "Man of Tai Chi",released: 2013})<-[:ACTED_IN]-(:Person {bornIn: "Beirut",nationality: "Canadian",name: │
│ │ │"Keanu Reeves"}), (:Movie {title: "Man of Tai Chi",released: 2013})<-[:DIRECTED]-(:Person {bornIn: "Beirut",nationality: │
│ │ │"Canadian",name: "Keanu Reeves"})] │
└─────────────────┴───────────────┴─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
Unique results
DISTINCT retrieves only unique rows for the columns that have been selected for output.
SET
The SET clause is used to update labels on nodes and properties on nodes and relationships.
The SET clause can be used with a map — provided as a literal or a parameter — to set properties.

Set a property
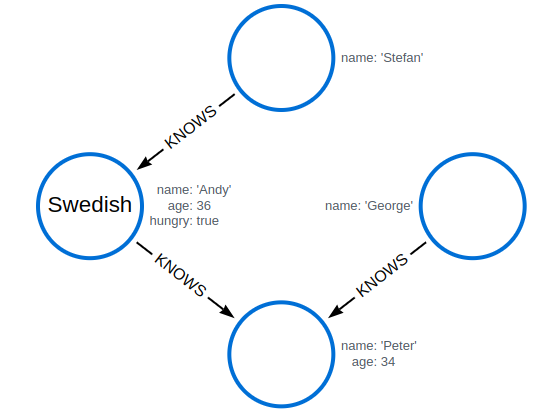
MATCH (n {name: 'Andy'})
SET n.surname = 'Taylor'
RETURN n.name, n.surname
It is possible to set a property on a node or relationship using more complex expressions. For instance, in contrast to specifying the node directly, the following query shows how to set a property for a node selected by an expression:
MATCH (n {name: 'Andy'})
SET (CASE WHEN n.age = 36 THEN n END).worksIn = 'Malmo'
RETURN n.name, n.worksIn
No action will be taken if the node expression evaluates to null.
Update a property
MATCH (n {name: 'Andy'})
SET n.age = toString(n.age)
RETURN n.name, n.age
Dynamically set or update a property
SET can be used to set or update a property on a node or relationship even when the property key name is not statically known. This allows for more flexible queries and mitigates the risk of Cypher® injection.
SET n[key] = expression
The dynamically calculated key must evaluate to a STRING value.

Remove a property
Although REMOVE is normally used to remove a property, it is sometimes convenient to do it using the SET command. A case in point is if the property is provided by a parameter.
MATCH (n {name: 'Andy'})
SET n.name = null
RETURN n.name, n.age
Copy properties between nodes and relationships
SET can be used to copy all properties from one node or relationship to another using the properties() function. This will remove all other properties on the node or relationship being copied to.
MATCH
(at {name: 'Andy'}),
(pn {name: 'Peter'})
SET at = properties(pn)
RETURN at.name, at.age, at.hungry, pn.name, pn.age
The 'Andy' node has had all its properties replaced by the properties of the 'Peter' node.
╒═══════╤══════╤═════════╤═══════╤══════╕ │at.name│at.age│at.hungry│pn.name│pn.age│ ╞═══════╪══════╪═════════╪═══════╪══════╡ │"Peter"│34 │null │"Peter"│34 │ └───────┴──────┴─────────┴───────┴──────┘
Replace all properties using a map and =
The property replacement operator = can be used with SET to replace all existing properties on a node or relationship with those provided by a map:
MATCH (p {name: 'Peter'})
SET p = {name: 'Peter Smith', position: 'Entrepreneur'}
RETURN p.name, p.age, p.position
This query updated the name property from Peter to Peter Smith, deleted the age property, and added the position property to the 'Peter' node.
Remove all properties using an empty map and =
MATCH (p {name: 'Peter'})
SET p = {}
RETURN p.name, p.age
Mutate specific properties using a map and +=
The property mutation operator += can be used with SET to mutate properties from a map in a fine-grained fashion:
-
Any properties in the map that are not on the node or relationship will be added.
-
Any properties not in the map that are on the node or relationship will be left as is.
-
Any properties that are in both the map and the node or relationship will be replaced in the node or relationship. However, if any property in the map is
null, it will be removed from the node or relationship.
MATCH (p {name: 'Peter'})
SET p += {age: 38, hungry: true, position: 'Entrepreneur'}
RETURN p.name, p.age, p.hungry, p.position
In contrast to the property replacement operator =, providing an empty map as the right operand to += will not remove any existing properties from a node or relationship:
MATCH (p {name: 'Peter'})
SET p += {}
RETURN p.name, p.age
Set multiple properties using one SET clause
MATCH (n {name: 'Andy'})
SET n.position = 'Developer', n.surname = 'Taylor'
Set a label on a node
MATCH (n {name: 'Stefan'})
SET n:German
RETURN n.name, labels(n) AS labels
Dynamically set a node label
MATCH (n) SET n:$(<expr>)
MATCH (n:Swedish) SET n:$(n.name) RETURN n.name, labels(n) AS labels



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通