
Built-in databases in Neo4j
All Neo4j servers contain a built-in database called system, which behaves differently than all other databases. The system database stores system data and you can not perform graph queries against it.
A fresh installation of Neo4j includes two databases:
-
system- the system database described above, containing meta-data on the DBMS and security configuration. -
neo4j- the default database, named using the config optiondbms.default_database=neo4j.
Query considerations
Most of the time Cypher queries are reading or updating queries, which are run against a graph. There are also administrative commands that apply to a database, or to the entire DBMS. Administrative commands cannot be run in a session connected to a normal user database, but instead need to be run within a session connected to the system database. Administrative commands execute on the system database. If an administrative command is submitted to a user database, it is rerouted to the system database.
Cypher and Neo4j transactions
All Cypher queries run within transactions. Modifications done by updating queries are held in memory by the transaction until it is committed, at which point the changes are persisted to disk and become visible to other transactions. If an error occurs - either during query evaluation, such as division by zero, or during commit, such as constraint violations - the transaction is automatically rolled back, and no changes are persisted in the graph.
In short, an updating query always either fully succeeds or does not succeed at all.
Explicit and implicit transactions
Transactions in Neo4j can be either explicit or implicit.
| Explicit | Implicit |
|---|---|
|
Opened by the user. |
Opened automatically. |
|
Can execute multiple Cypher queries in sequence. |
Can execute a single Cypher query. |
|
Committed, or rolled back, by the user. |
Committed automatically when a transactions finishes successfully. |
Queries that start separate transactions themselves, such as queries using CALL { ... } IN TRANSACTIONS, are only allowed in implicit mode. Explicit transactions cannot be managed directly from queries, they must be managed via APIs or tools.
DBMS transactions
Beginning a transaction while connected to a DBMS will start a DBMS-level transaction. A DBMS-level transaction is a container for database transactions.
A database transaction is started when the first query to a specific database is issued. Database transactions opened inside a DBMS-level transaction are committed or rolled back when the DBMS-level transaction is committed or rolled back.
DBMS transactions have the following limitations:
-
Only one database can be written to in a DBMS transaction.
-
Cypher operations fall into the following main categories:
-
Operations on graphs.
-
Schema commands.
-
Administration commands.
-
It is not possible to combine any of these workloads in a single DBMS transaction.
ACID compliance
Neo4j is fully ACID compliant. This means that:
-
Atomicity - If a part of a transaction fails, the database state is left unchanged.
-
Consistency — Every transaction leaves the database in a consistent state.
-
Isolation — During a transaction, modified data cannot be accessed by other operations.
-
Durability — The DBMS can always recover the results of a committed transaction.
Core concepts
Nodes
MATCH (n:Person {name:'Anna'})
RETURN n.born AS birthYear
Relationships
MATCH (:Person {name: 'Anna'})-[r:KNOWS WHERE r.since < 2020]->(friend:Person)
RETURN count(r) As numberOfFriends
Paths
MATCH (n:Person {name: 'Anna'})-[:KNOWS]-{1,5}(friend:Person WHERE n.born < friend.born)
RETURN DISTINCT friend.name AS olderConnections
This example uses a quantified relationship to find all paths up to 5 hops away。
Paths can also be assigned variables. For example, the below query binds a whole path pattern, which matches the SHORTEST path from Anna to another Person node in the graph with a nationality property set to Canadian. In this case, the RETURN clause returns the full path between the two nodes.
MATCH p = SHORTEST 1 (:Person {name: 'Anna'})-[:KNOWS]-+(:Person {nationality: 'Canadian'})
RETURN p
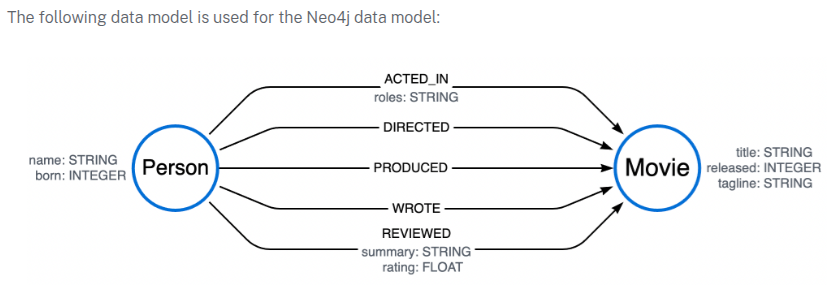
The below query searches the graph for outgoing relationships from the Tom Hanks node to any Movie nodes, and returns the relationships and the titles of the movies connected to him.
MATCH (tom:Person {name:'Tom Hanks'})-[r]->(m:Movie)
RETURN type(r) AS type, m.title AS movie
The below query uses a NOT label expression (!) to return all relationships connected to Tom Hanks that are not of type ACTED_IN.
MATCH (:Person {name:'Tom Hanks'})-[r:!ACTED_IN]->(m:Movie)
Return type(r) AS type, m.title AS movies
Finding paths
To search for patterns of a fixed length, specify the distance (hops) between the nodes in the pattern by using a quantifier ({n}).
For example, the following query matches all Person nodes exactly 2 hops away from Tom Hanks and returns the first five rows.
MATCH (tom:Person {name:'Tom Hanks'}) -- {2} (colleagues:Person)
RETURN DISTINCT colleagues.name AS name, colleagues.born AS bornIn
ORDER BY bornIn
LIMIT 5
It is also possible to match a graph for patterns of a variable length. The below query matches all Person nodes between 1 and 4 hops away from Tom Hanks and returns the first five rows.
MATCH (p:Person {name:'Tom Hanks'}) -- {1,4} (colleagues:Person)
RETURN DISTINCT colleagues.name AS name, colleagues.born AS bornIn
ORDER BY bornIn, name
LIMIT 5

The SHORTEST keyword can be used to find a variation of the shortest paths between two nodes. In this example, ALL SHORTEST paths between the two nodes Keanu Reeves and Tom Cruise are found.
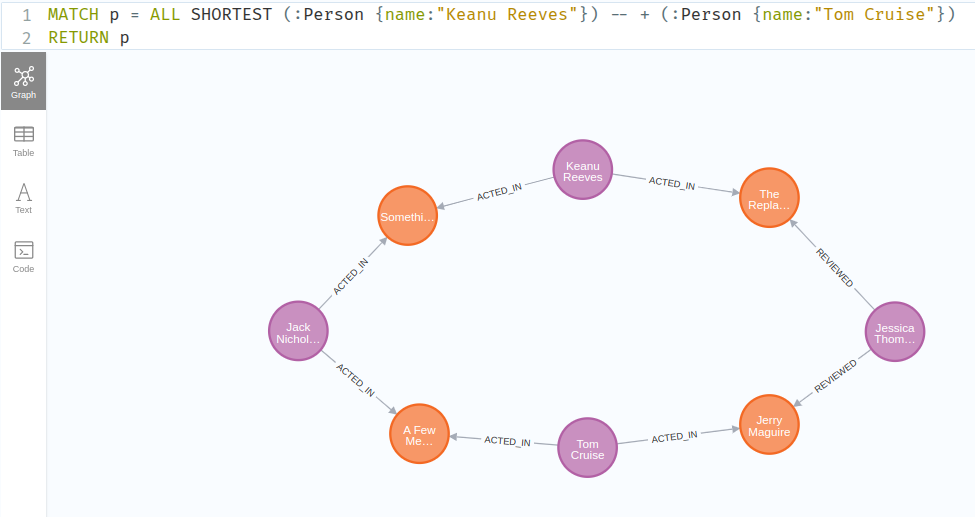
The count() function calculates the number of these shortest paths.
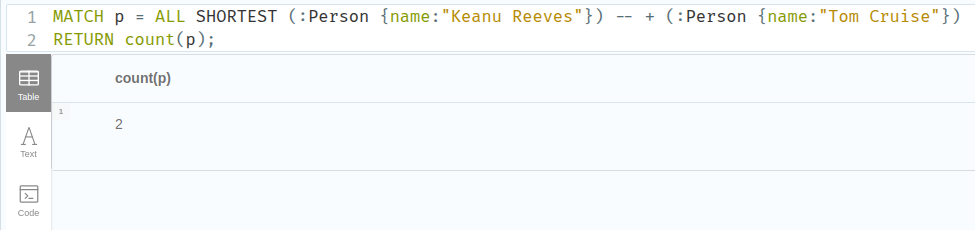
The length() function calculates the length of each path in terms of traversed relationships.


Finding recommendations
The following query tries to recommend co-actors for Keanu Reeves, who he has yet to work with but who his co-actors have worked with. The query then orders the results by how frequently a matched co-co-actor has collaborated with one of Keanu Reeves' co-actors.
MATCH (keanu:Person {name: "Keanu Reeves"}) - [:ACTED_IN] -> (m1:Movie) <- [:ACTED_IN] - (coActors:Person),
(coActors:Person) - [:ACTED_IN] -> (m2:Movie) <- [:ACTED_IN] - (coCoActors:Person)
WHERE NOT (keanu) - [:ACTED_IN] -> () <- [:ACTED_IN] - (coCoActors) AND keanu <> coCoActors
RETURN coCoActors.name AS recomended, count(coCoActors) AS strength
ORDER BY strength DESC
LIMIT 7

╒═════════════════╤════════╕ │recomended │strength│ ╞═════════════════╪════════╡ │"Tom Hanks" │4 │ ├─────────────────┼────────┤ │"Natalie Portman"│3 │ ├─────────────────┼────────┤ │"Stephen Rea" │3 │ ├─────────────────┼────────┤ │"John Hurt" │3 │ ├─────────────────┼────────┤ │"Halle Berry" │3 │ ├─────────────────┼────────┤ │"Jim Broadbent" │3 │ ├─────────────────┼────────┤ │"Ben Miles" │3 │ └─────────────────┴────────┘
There are several connections between the Keanu Reeves and Tom Hanks nodes in the movie database, but the two have never worked together in a film. The following query matches coactors who could introduce the two, by looking for co-actors who have worked with both of them in separate movies:
MATCH (keanu:Person {name: "Keanu Reeves"}) - [:ACTED_IN] -> (:Movie) <- [:ACTED_IN] - (coActors:Person),
(tom:Person {name: "Tom Hanks"}) - [:ACTED_IN] -> (:Movie) <- [:ACTED_IN] - (coActors:Person)
RETURN coActors.name AS coActors, count(coActors) AS strength
ORDER BY strength DESC
╒═════════════════╤════════╕ │coActors │strength│ ╞═════════════════╪════════╡ │"Hugo Weaving" │3 │ ├─────────────────┼────────┤ │"Charlize Theron"│1 │ └─────────────────┴────────┘
Cypher expressions
General
-
A variable:
n,x,rel,myFancyVariable,`A name with special characters in it[]!`. -
A property:
n.prop,x.prop,rel.thisProperty,myFancyVariable.`(special property name)`. -
A dynamic property:
n["prop"],rel[n.city + n.zip],map[coll[0]]. -
A parameter:
$param,$0. -
A list of expressions:
['a', 'b'],[1, 2, 3],['a', 2, n.property, $param],[]. -
A function call:
length(p),nodes(p). -
An aggregate function call:
avg(x.prop),count(*). -
A path-pattern:
(a)-[r]->(b),(a)-[r]-(b),(a)--(b),(a)-->()<--(b). -
An operator application:
1 + 2,3 < 4. -
A subquery expression:
COUNT {},COLLECT {},EXISTS {},CALL {}. -
A regular expression:
a.name =~ 'Tim.*'. -
A
CASEexpression. -
null.

String literal escape sequences
String literals can contain the following escape sequences:
| Escape sequence | Character |
|---|---|
|
|
Tab |
|
|
Backspace |
|
|
Newline |
|
|
Carriage return |
|
|
Form feed |
|
|
Single quote |
|
|
Double quote |
|
|
Backslash |
|
|
Unicode UTF-16 code point (4 hex digits must follow the |
Conditional expressions (CASE)
Generic conditional expressions can be expressed in Cypher® using the CASE construct. Two variants of CASE exist within Cypher: the simple form, to compare a single expression against multiple values, and the generic form, to express multiple conditional statements.

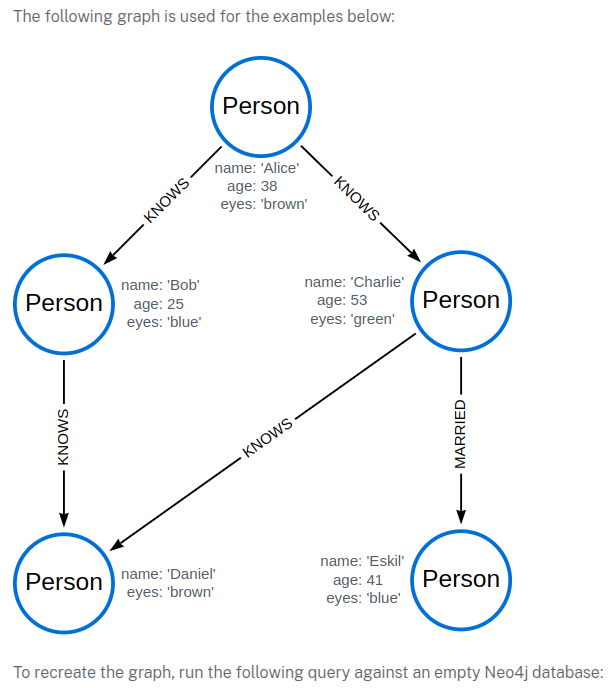
CREATE
(alice:Person {name:'Alice', age: 38, eyes: 'brown'}),
(bob:Person {name: 'Bob', age: 25, eyes: 'blue'}),
(charlie:Person {name: 'Charlie', age: 53, eyes: 'green'}),
(daniel:Person {name: 'Daniel', eyes: 'brown'}),
(eskil:Person {name: 'Eskil', age: 41, eyes: 'blue'}),
(alice)-[:KNOWS]->(bob),
(alice)-[:KNOWS]->(charlie),
(bob)-[:KNOWS]->(daniel),
(charlie)-[:KNOWS]->(daniel),
(bob)-[:MARRIED]->(eskil)
Simple CASE
The simple CASE form is used to compare a single expression against multiple values, and is analogous to the switch construct of programming languages. The expressions are evaluated by the WHEN operator until a match is found. If no match is found, the expression in the ELSE operator is returned. If there is no ELSE case and no match is found, null will be returned.
Syntax
CASE test WHEN value [, value]* THEN result [WHEN ...] [ELSE default] END
Example
MATCH (n:Person) RETURN CASE n.eyes WHEN 'blue' THEN 1 WHEN 'brown', 'hazel' THEN 2 ELSE 3 END AS result, n.eyes
Extended SimpleCASE
The extended simple CASE form allows the comparison operator to be specified explicitly. The simple CASE uses an implied equals (=) comparator.
The supported comparators are:
-
Regular Comparison Operators:
=,<>,<,>,<=,>= -
IS NULLOperator:IS [NOT] NULL -
Type Predicate Expression:
IS [NOT] TYPED <TYPE>(Note that the formIS [NOT] :: <TYPE>is not accepted) -
Normalization Predicate Expression:
IS [NOT] NORMALIZED -
String Comparison Operators:
STARTS WITH,ENDS WITH,=~(regex matching)
Syntax
CASE test WHEN [comparisonOperator] value [, [comparisonOperator] value ]* THEN result [WHEN ...] [ELSE default] END
Example
MATCH (n:Person) RETURN n.name, CASE n.age WHEN IS NULL, IS NOT TYPED INTEGER | FLOAT THEN "Unknown" WHEN = 0, = 1, = 2 THEN "Baby" WHEN <= 13 THEN "Child" WHEN < 20 THEN "Teenager" WHEN < 30 THEN "Young Adult" WHEN > 1000 THEN "Immortal" ELSE "Adult" END AS result
Generic CASE
The generic CASE expression supports multiple conditional statements, and is analogous to the if-elseif-else construct of programming languages. Each row is evaluated in order until a true value is found. If no match is found, the expression in the ELSE operator is returned. If there is no ELSE case and no match is found, null will be returned.
Syntax
CASE WHEN predicate THEN result [WHEN ...] [ELSE default] END
Example
MATCH (n:Person) RETURN CASE WHEN n.eyes = 'blue' THEN 1 WHEN n.age < 40 THEN 2 ELSE 3 END AS result, n.eyes, n.age
CASE with null values
When working with null values, you may be forced to use the generic CASE form. The two examples below use the age property of the Daniel node (which has a null value for that property) to clarify the difference.
CASEMATCH (n:Person) RETURN n.name, CASE n.age WHEN null THEN -1 ELSE n.age - 10 END AS age_10_years_ago

╒═════════╤════════════════╕ │n.name │age_10_years_ago│ ╞═════════╪════════════════╡ │"Alice" │28 │ ├─────────┼────────────────┤ │"Bob" │15 │ ├─────────┼────────────────┤ │"Charlie"│43 │ ├─────────┼────────────────┤ │"Daniel" │null │ ├─────────┼────────────────┤ │"Eskil" │31 │ └─────────┴────────────────┘
Generic CASE
MATCH (n:Person) RETURN n.name, CASE WHEN n.age IS NULL THEN -1 ELSE n.age - 10 END AS age_10_years_ago

╒═════════╤════════════════╕ │n.name │age_10_years_ago│ ╞═════════╪════════════════╡ │"Alice" │28 │ ├─────────┼────────────────┤ │"Bob" │15 │ ├─────────┼────────────────┤ │"Charlie"│43 │ ├─────────┼────────────────┤ │"Daniel" │-1 │ ├─────────┼────────────────┤ │"Eskil" │31 │ └─────────┴────────────────┘
CASE expressions and succeeding clauses
The results of a CASE expression can be used to set properties on a node or relationship.
MATCH (n:Person) WITH n, CASE n.eyes WHEN 'blue' THEN 1 WHEN 'brown' THEN 2 ELSE 3 END AS colorCode SET n.colorCode = colorCode RETURN n.name, n.colorCode
Further considerations
CASE result branches are statically checked prior to execution. This means that if a branch is not semantically correct, it will still throw an exception, even if that branch may never be executed during runtime.
In the following example, date is statically known to be a STRING value, and therefore would fail if treated as a DATE value.
Not allowed
WITH "2024-08-05" AS date, "string" AS type
RETURN CASE type
WHEN "string" THEN datetime(date)
WHEN "date" THEN datetime({year: date.year, month: date.month, day: date.day})
ELSE datetime(date)
END AS dateTime
ERROR: Neo.ClientError.Statement.SyntaxError
Type mismatch: expected Map, Node, Relationship, Point, Duration, Date, Time, LocalTime, LocalDateTime or DateTime but was String (line 4, column 38 (offset: 136))
" WHEN "date" THEN datetime({year: date.year, month: date.month, day: date.day})"
Clauses
Reading clauses
| Clause | Description |
|---|---|
|
Specify the patterns to search for in the database. |
|
|
Specify the patterns to search for in the database while using |
Reading sub-clauses
These comprise sub-clauses that must operate as part of reading clauses.
| Sub-clause | Description |
|---|---|
|
Adds constraints to the patterns in a |
|
|
A sub-clause following |
|
|
Defines from which row to start including the rows in the output. As of Neo4j 5.24, it can be used as a standalone clause. |
|
|
Constrains the number of rows in the output. As of Neo4j 5.24, it can be used as a standalone clause. |
Projecting clauses
These comprise clauses that define which expressions to return in the result set. The returned expressions may all be aliased using AS.
| Clause | Description |
|---|---|
|
Defines what to include in the query result set. |
|
|
Allows query parts to be chained together, piping the results from one to be used as starting points or criteria in the next. |
|
|
Expands a list into a sequence of rows. |
|
|
Defines a query to have no result. |
Writing clauses
These comprise clauses that write the data to the database.
| Clause | Description |
|---|---|
|
Create nodes and relationships. |
|
|
Delete nodes, relationships or paths. Any node to be deleted must also have all associated relationships explicitly deleted. |
|
|
Delete a node or set of nodes. All associated relationships will automatically be deleted. |
|
|
Update labels on nodes and properties on nodes and relationships. |
|
|
Remove properties and labels from nodes and relationships. |
|
|
Update data within a list, whether components of a path, or the result of aggregation. |
Reading/Writing clauses
These comprise clauses that both read data from and write data to the database.
| Clause | Description |
|---|---|
|
Ensures that a pattern exists in the graph. Either the pattern already exists, or it needs to be created. |
|
|
|
Used in conjunction with |
|
|
Used in conjunction with |
|
Invokes a procedure deployed in the database and return any results. |
Subquery clauses
| Clause | Description |
|---|---|
|
Evaluates a subquery, typically used for post-union processing or aggregations. |
|
|
Evaluates a subquery in separate transactions. Typically used when modifying or importing large amounts of data. |
Set operations
Multiple graphs
| Clause | Description |
|---|---|
|
Determines which graph a query, or query part, is executed against. |
Importing data
| Clause | Description |
|---|---|
|
Use when importing data from CSV files. |
|
|
This clause may be used to prevent an out-of-memory error from occurring when importing large amounts of data using |
Listing functions and procedures
| Clause | Description |
|---|---|
|
List the available functions. |
|
|
List the available procedures. |
Configuration Commands
| Clause | Description |
|---|---|
|
List configuration settings. |
Transaction Commands
| Clause | Description |
|---|---|
|
List the available transactions. |
|
|
Terminate transactions by their IDs. |
Reading hints
These comprise clauses used to specify planner hints when tuning a query. More details regarding the usage of these — and query tuning in general — can be found in Planner hints and the USING keyword.
| Hint | Description |
|---|---|
|
Index hints are used to specify which index, if any, the planner should use as a starting point. |
|
|
Index seek hint instructs the planner to use an index seek for this clause. |
|
|
Scan hints are used to force the planner to do a label scan (followed by a filtering operation) instead of using an index. |
|
|
Join hints are used to enforce a join operation at specified points. |
Index and constraint clauses
These comprise clauses to create, show, and drop indexes and constraints.
| Clause | Description |
|---|---|
|
Create, show or drop an index. |
|
|
Create, show or drop a constraint. |
Administration clauses
Cypher includes commands to manage databases, aliases, servers, and role-based access control. To learn more about each of these, see:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2024-02-15 Go - map
2024-02-15 Go 100 mistakes - #26: Slices and memory leaks
2024-02-15 Go 100 mistakes - #25: Unexpected side effects using slice append
2024-02-15 Go 100 mistakes - #21: Inefficient slice initialization
2024-02-15 Go - slice