



from delta import configure_spark_with_delta_pip, DeltaTable from pyspark.sql import SparkSession from pyspark.sql.functions import col, from_json from pyspark.sql.types import StructType, StructField, IntegerType, StringType builder = (SparkSession.builder .appName("delta-write-streaming") .master("spark://ZZHPC:7077") .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")) spark = configure_spark_with_delta_pip(builder,['org.apache.spark:spark-sql-kafka-0-10_2.12:3.4.1']).getOrCreate() spark.sparkContext.setLogLevel("ERROR") get_ipython().run_line_magic('load_ext', 'sparksql_magic') get_ipython().run_line_magic('config', 'SparkSql.limit=20')
%%sparksql CREATE OR REPLACE TABLE default.users ( id INT, name STRING, age INT, gender STRING, country STRING ) USING DELTA LOCATION '/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/delta-write-streaming/users';
df = (spark.readStream.format("kafka") .option("kafka.bootstrap.servers", "localhost:9092") .option("subscribe", "users") .option("startingOffsets", "earliest") .load())
schema = StructType([ StructField('id', IntegerType(), True), StructField('name', StringType(), True), StructField('age', IntegerType(), True), StructField('gender', StringType(), True), StructField('country', StringType(), True)]) df = df.withColumn('value', from_json(col('value').cast("STRING"), schema))
df = df.select( col('value.id').alias('id'), col('value.name').alias('name'), col('value.age').alias('age'), col('value.gender').alias('gender'), col('value.country').alias('country'))
query = (df.writeStream.format("delta") .outputMode("append") .option("checkpointLocation", "/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/delta-write-streaming/users/_checkpoints/") .start("/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/delta-write-streaming/users"))
%%sparksql SELECT COUNT(*) FROM delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/delta-write-streaming/users`;

%%sparksql SELECT COUNT(*) FROM delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/delta-write-streaming/users`;

query.stop()
spark.stop()

%%sparksql CREATE OR REPLACE TABLE default.users ( id INT, name STRING, age INT, gender STRING, country STRING ) USING DELTA LOCATION '/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/idempotent-stream-write-delta/users';
df = (spark.readStream.format("kafka") .option("kafka.bootstrap.servers", "localhost:9092") .option("subscribe", "users") .option("startingOffsets", "earliest") .load())
schema = StructType([ StructField('id', IntegerType(), Tru.e), StructField('name', StringType(), True), StructField('age', IntegerType(), True), StructField('gender', StringType(), True), StructField('country', StringType(), True)]) df = df.withColumn('value', from_json(col('value').cast("STRING"), schema))
df = df.select( col('value.id').alias('id'), col('value.name').alias('name'), col('value.age').alias('age'), col('value.gender').alias('gender'), col('value.country').alias('country'))
query = (df.writeStream .format("delta") .outputMode("append") .option("checkpointLocation", "/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/idempotent-stream-write-delta/users/_checkpoints/") .start("/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/idempotent-stream-write-delta/users"))

# Define a function writing to two destinations app_id = 'idempotent-stream-write-delta' def writeToDeltaLakeTableIdempotent(batch_df, batch_id): # location 1 (batch_df.filter("country IN ('India','China')") .write.format("delta") .mode("append") .option("txnVersion", batch_id) .option("txnAppId", app_id) .save("/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/idempotent-stream-write-delta/user_asia")) # location 2 (batch_df.filter("country IN ('USA','Canada','Brazil')") .write.format("delta") .mode("append") .option("txnVersion", batch_id) .option("txnAppId", app_id) .save("/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/idempotent-stream-write-delta/user_americas"))
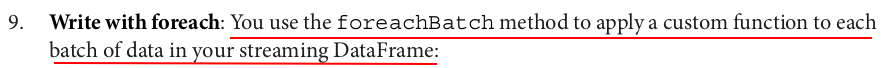
# Apply the function against the micro-batches using ‘foreachBatch’ write_query = (df.writeStream.format("delta") .queryName("Users By Region") .foreachBatch(writeToDeltaLakeTableIdempotent) .start())

%%sparksql SELECT COUNT(*) FROM delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/idempotent-stream-write-delta/user_asia`;

%%sparksql SELECT COUNT(*) FROM delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/idempotent-stream-write-delta/user_americas`;

%%sparksql SELECT COUNT(*) FROM delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/idempotent-stream-write-delta/user_asia`;
%%sparksql SELECT COUNT(*) FROM delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/idempotent-stream-write-delta/user_americas`;

query.stop()
write_query.stop()
spark.stop()

%%sparksql CREATE OR REPLACE TABLE default.users ( id INT, name STRING, age INT, gender STRING, country STRING ) USING DELTA LOCATION '/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/merge-cdc-streaming/users';
df = (spark.readStream .format("kafka") .option("kafka.bootstrap.servers", "localhost:9092") .option("subscribe", "users") .option("startingOffsets", "earliest") .load())
schema = StructType([ StructField('id', IntegerType(), True), StructField('name', StringType(), True), StructField('age', IntegerType(), True), StructField('gender', StringType(), True), StructField('country', StringType(), True)]) df = df.withColumn('value', from_json(col('value').cast("STRING"), schema))
df = df.select( col('value.id').alias('id'), col('value.name').alias('name'), col('value.age').alias('age'), col('value.gender').alias('gender'), col('value.country').alias('country'))
def upsertToDelta(microBatchDf, batchId): deltaTable = DeltaTable.forPath(spark, "/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/merge-cdc-streaming/users" ) (deltaTable.alias("dt") .merge(source=microBatchDf.alias("sdf"), condition="sdf.id = dt.id") .whenMatchedUpdate(set={ "id": "sdf.id", "name": "sdf.name", "age": "sdf.gender", "country": "sdf.country" }) .whenNotMatchedInsert(values={ "id": "sdf.id", "name": "sdf.name", "age": "sdf.gender", "country": "sdf.country" }) .execute())
query = (df.writeStream.format("delta") .foreachBatch(upsertToDelta) .outputMode("update") .option("checkpointLocation", "/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/merge-cdc-streaming/users/_checkpoints/") .start("/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/merge-cdc-streaming/users"))
%%sparksql DESCRIBE HISTORY delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/merge-cdc-streaming/users`;
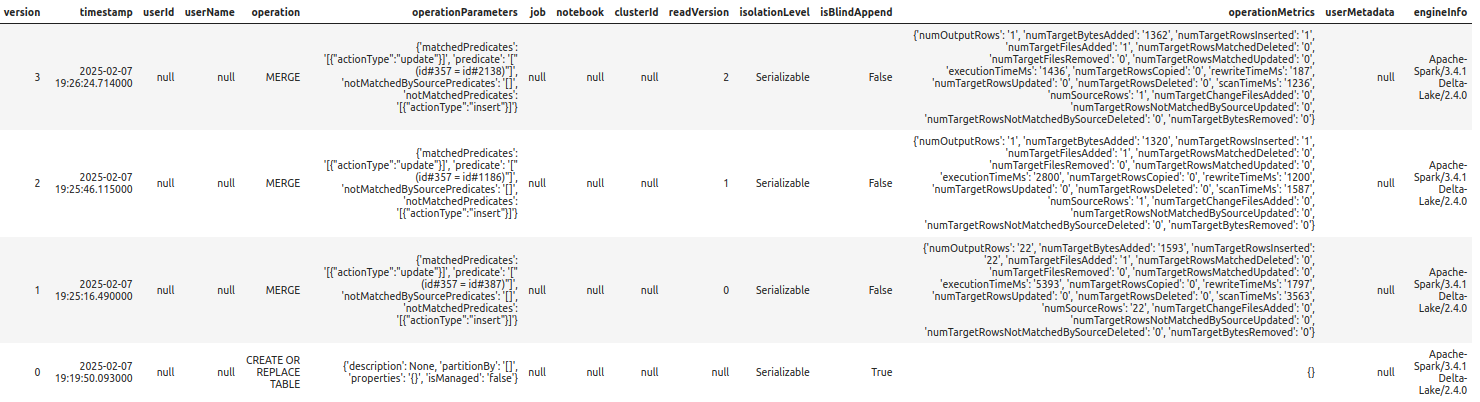
query.stop()
spark.stop()


import random import json from kafka import KafkaProducer import time import datetime bootstrap_servers = "localhost:9092" topic = "orders" producer = KafkaProducer(bootstrap_servers=bootstrap_servers) # Define the product IDs and the quantities product_ids = [1001, 1002, 1003, 1004, 1005] quantities = [1, 2, 3, 4, 5] # Define a function to generate random event data def generate_orders(): current_time = time.time() order_id = random.randint(100000, 999999) product_id = random.choice(product_ids) quantity = random.choice(quantities) timestamp = datetime.datetime.fromtimestamp(current_time).strftime("%m/%d/%Y, %H:%M:%S") # Create an order dictionary return {"order_id": order_id, "product_id": product_id, "quantity": quantity,"timestamp": timestamp} # Loop to generate and send events while True: # Generate a random event order = generate_orders() # Print the event to the console print(order) # Send the event to the Kafka topic producer.send(topic, value=json.dumps(order).encode('utf-8')) time.sleep(30)
from delta import configure_spark_with_delta_pip, DeltaTable from pyspark.sql import SparkSession from pyspark.sql.functions import col, from_json,to_timestamp from pyspark.sql.types import StructType, StructField, IntegerType, StringType builder = (SparkSession.builder .appName("joining-stream-static-data") .master("spark://ZZHPC:7077") .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")) spark = configure_spark_with_delta_pip(builder,['org.apache.spark:spark-sql-kafka-0-10_2.12:3.4.1']).getOrCreate() spark.sparkContext.setLogLevel("ERROR") get_ipython().run_line_magic('load_ext', 'sparksql_magic') get_ipython().run_line_magic('config', 'SparkSql.limit=20')
# Define the schema of the streaming data streaming_schema = StructType([ StructField("order_id", IntegerType()), StructField("product_id", IntegerType()), StructField("quantity", IntegerType()), StructField("timestamp", IntegerType()) ]) streaming_df = (spark.readStream.format("kafka") .option("kafka.bootstrap.servers", "localhost:9092") .option("subscribe", "orders") .option("startingOffsets", "earliest") .option("failOnDataLoss", "false") .load() .withColumn('value', from_json(col('value').cast("STRING"), streaming_schema))) streaming_df = (streaming_df .select( col('value.order_id').alias('order_id'), col('value.product_id').alias('product_id'), col('value.quantity').alias('quantity'), to_timestamp(col("timestamp"), "MM/dd/yyyy, HH:mm:ss" ).alias('timestamp')) )


# Define a list of tuples product_details = [ (1001, "Laptop", 999.99), (1002, "Mouse", 19.99), (1003, "Keyboard", 29.99), (1004, "Monitor", 199.99), (1005, "Speaker", 49.99) ] # Define a list of column names columns = ["product_id", "name", "price"] # Create a DataFrame from the list of tuples static_df = spark.createDataFrame(product_details, columns)
# Join the streaming data with the static data joined_df = (streaming_df.join(static_df, streaming_df.product_id == static_df.product_id, "inner") .drop(static_df.product_id) .withColumn('invoice_amount', streaming_df.quantity * static_df.price))
query = (joined_df.writeStream.format("delta") .outputMode("append") .option("failOnDataLoss", "true") .option("checkpointLocation", "/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/joining-stream-static/orders/_checkpoints/") .start("/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/joining-stream-static/orders") )
%%sparksql SELECT * FROM delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/joining-stream-static/orders`;
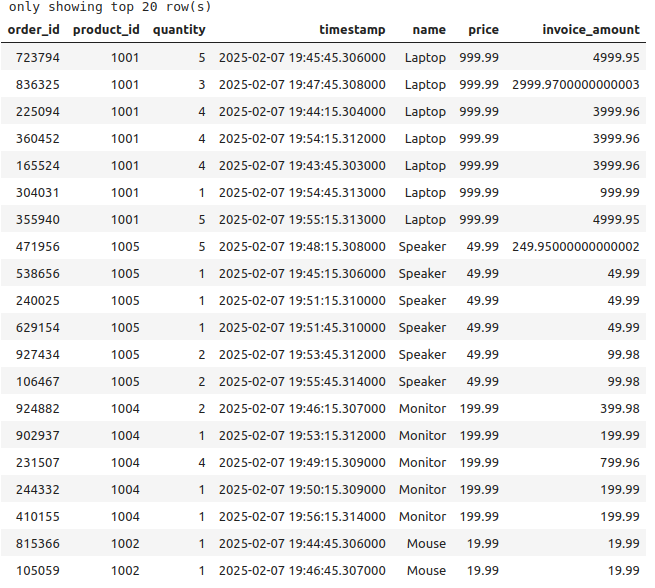
query.stop()
spark.stop()



schema = StructType([ StructField('id', IntegerType(), True), StructField('name', StringType(), True), StructField('age', IntegerType(), True), StructField('gender', StringType(), True), StructField('country', StringType(), True), StructField('timestamp', StringType(), True)]) users_df = (spark.readStream .format("kafka") .option("kafka.bootstrap.servers", "localhost:9092") .option("subscribe", "users") .option("startingOffsets", "latest") .load() .withColumn('value', from_json(col('value').cast("STRING"), schema))) users_df = users_df.select( col('value.id').alias('id'), col('value.name').alias('name'), col('value.age').alias('age'), col('value.gender').alias('gender'), col('value.country').alias('country'), to_timestamp(col('value.timestamp'), "MM/dd/yyyy, HH:mm:ss").alias('timestamp'))
schema = StructType([ StructField('user_id', IntegerType(), True), StructField('event_type', StringType(), True), StructField('event_time', StringType(), True), StructField('processing_time', StringType(), True)]) events_df = (spark.readStream .format("kafka") .option("kafka.bootstrap.servers", "localhost:9092") .option("subscribe", "events") .option("startingOffsets", "latest") .load() .withColumn('value', from_json(col('value').cast("STRING"), schema))) events_df = (events_df.select( col('value.user_id').alias('user_id'), col('value.event_type').alias('event_type'), col('value.event_time').alias('event_time'), col('value.processing_time').alias('processing_time')) .withColumn("event_time", to_timestamp(col("event_time"), "MM/dd/yyyy, HH:mm:ss" )) .withColumn("processing_time", to_timestamp(col("processing_time"), "MM/dd/yyyy, HH:mm:ss")))
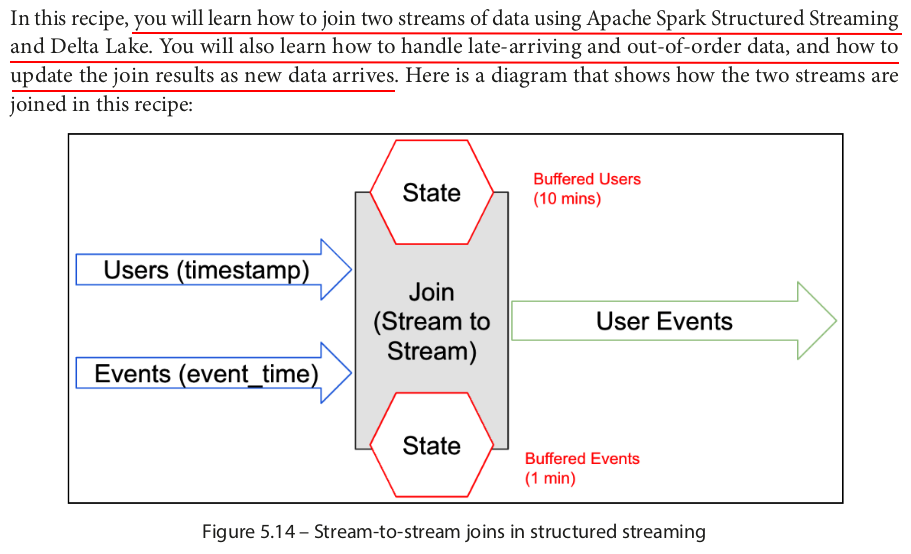
# Join the two streaming DataFrames on user join_df = (events_df.join(users_df.withWatermark("timestamp", "10 minutes"), # Define watermark for users stream events_df.user_id == users_df.id, # Join condition "inner") # Join type .withWatermark("event_time", "1 minutes") # Define watermark for events stream .drop(users_df.id))
query = (join_df.writeStream.format("delta") .outputMode("append") .option("failOnDataLoss", "true") .option("checkpointLocation", "/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/joining-stream-stream/user_events/_checkpoints/") .start("/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/joining-stream-stream/user_events"))

%%sparksql SELECT event_type, gender, country, count(user_id) FROM delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/joining-stream-stream/user_events` GROUP BY ALL;
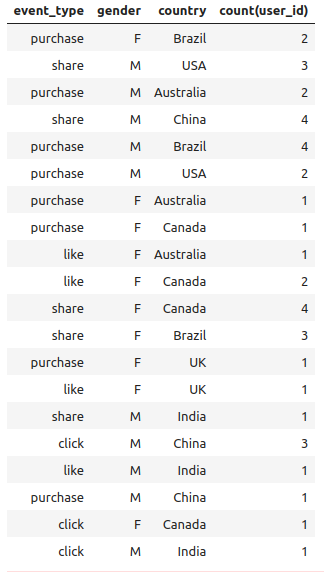
sparksql的执行结果是一个时点的结果,并不会实时更新。想要看到更新的结果,需要再次执行。
query.stop()
spark.stop()

schema = StructType([ StructField('id', IntegerType(), True), StructField('name', StringType(), True), StructField('age', IntegerType(), True), StructField('gender', StringType(), True), StructField('country', StringType(), True), StructField('timestamp', StringType(), True)]) users_df = (spark.readStream .format("kafka") .option("kafka.bootstrap.servers", "localhost:9092") .option("subscribe", "users") .option("startingOffsets", "latest") .load() .withColumn('value', from_json(col('value').cast("STRING"), schema))) users_df = users_df.select( col('value.id').alias('id'), col('value.name').alias('name'), col('value.age').alias('age'), col('value.gender').alias('gender'), col('value.country').alias('country'), to_timestamp(col('value.timestamp'), "MM/dd/yyyy, HH:mm:ss").alias('timestamp'))
query = (users_df.writeStream.format("delta") .queryName("user-kafka-stream") .outputMode("append") .option("checkpointLocation", "/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/monitor-streams/users/_checkpoints/") .start("/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/monitor-streams/users"))
query.status
{'message': 'Waiting for data to arrive',
'isDataAvailable': False,
'isTriggerActive': False}
query.status
{'message': 'Processing new data',
'isDataAvailable': True,
'isTriggerActive': True}
query.recentProgress
[{'id': '24ff8275-0172-4aae-96a7-aff88a4882e7',
'runId': '808e2e6e-d777-4809-8f11-1c8a75135883',
'name': 'user-kafka-stream',
'timestamp': '2025-02-08T04:09:31.533Z',
'batchId': 0,
'numInputRows': 0,
'inputRowsPerSecond': 0.0,
'processedRowsPerSecond': 0.0,
'durationMs': {'addBatch': 8919,
'commitOffsets': 31,
'getBatch': 12,
'latestOffset': 510,
'queryPlanning': 279,
'triggerExecution': 9798,
'walCommit': 30},
'stateOperators': [],
'sources': [{'description': 'KafkaV2[Subscribe[users]]',
'startOffset': None,
'endOffset': {'users': {'2': 0, '1': 0, '0': 0}},
'latestOffset': {'users': {'2': 0, '1': 0, '0': 0}},
'numInputRows': 0,
'inputRowsPerSecond': 0.0,
'processedRowsPerSecond': 0.0,
'metrics': {'avgOffsetsBehindLatest': '0.0',
'maxOffsetsBehindLatest': '0',
'minOffsetsBehindLatest': '0'}}],
'sink': {'description': 'DeltaSink[/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/monitor-streams/users]',
'numOutputRows': -1}},
{'id': '24ff8275-0172-4aae-96a7-aff88a4882e7',
'runId': '808e2e6e-d777-4809-8f11-1c8a75135883',
'name': 'user-kafka-stream',
'timestamp': '2025-02-08T04:09:51.347Z',
'batchId': 1,
'numInputRows': 0,
'inputRowsPerSecond': 0.0,
'processedRowsPerSecond': 0.0,
'durationMs': {'latestOffset': 2, 'triggerExecution': 2},
'stateOperators': [],
'sources': [{'description': 'KafkaV2[Subscribe[users]]',
'startOffset': {'users': {'2': 0, '1': 0, '0': 0}},
'endOffset': {'users': {'2': 0, '1': 0, '0': 0}},
'latestOffset': {'users': {'2': 0, '1': 0, '0': 0}},
'numInputRows': 0,
'inputRowsPerSecond': 0.0,
'processedRowsPerSecond': 0.0,
'metrics': {'avgOffsetsBehindLatest': '0.0',
'maxOffsetsBehindLatest': '0',
'minOffsetsBehindLatest': '0'}}],
'sink': {'description': 'DeltaSink[/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/monitor-streams/users]',
'numOutputRows': -1}},
{'id': '24ff8275-0172-4aae-96a7-aff88a4882e7',
'runId': '808e2e6e-d777-4809-8f11-1c8a75135883',
'name': 'user-kafka-stream',
'timestamp': '2025-02-08T04:10:01.349Z',
'batchId': 1,
'numInputRows': 0,
'inputRowsPerSecond': 0.0,
'processedRowsPerSecond': 0.0,
'durationMs': {'latestOffset': 1, 'triggerExecution': 1},
'stateOperators': [],
'sources': [{'description': 'KafkaV2[Subscribe[users]]',
'startOffset': {'users': {'2': 0, '1': 0, '0': 0}},
'endOffset': {'users': {'2': 0, '1': 0, '0': 0}},
'latestOffset': {'users': {'2': 0, '1': 0, '0': 0}},
'numInputRows': 0,
'inputRowsPerSecond': 0.0,
'processedRowsPerSecond': 0.0,
'metrics': {'avgOffsetsBehindLatest': '0.0',
'maxOffsetsBehindLatest': '0',
'minOffsetsBehindLatest': '0'}}],
'sink': {'description': 'DeltaSink[/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/monitor-streams/users]',
'numOutputRows': -1}},
{'id': '24ff8275-0172-4aae-96a7-aff88a4882e7',
'runId': '808e2e6e-d777-4809-8f11-1c8a75135883',
'name': 'user-kafka-stream',
'timestamp': '2025-02-08T04:10:11.358Z',
'batchId': 1,
'numInputRows': 0,
'inputRowsPerSecond': 0.0,
'processedRowsPerSecond': 0.0,
'durationMs': {'latestOffset': 1, 'triggerExecution': 1},
'stateOperators': [],
'sources': [{'description': 'KafkaV2[Subscribe[users]]',
'startOffset': {'users': {'2': 0, '1': 0, '0': 0}},
'endOffset': {'users': {'2': 0, '1': 0, '0': 0}},
'latestOffset': {'users': {'2': 0, '1': 0, '0': 0}},
'numInputRows': 0,
'inputRowsPerSecond': 0.0,
'processedRowsPerSecond': 0.0,
'metrics': {'avgOffsetsBehindLatest': '0.0',
'maxOffsetsBehindLatest': '0',
'minOffsetsBehindLatest': '0'}}],
'sink': {'description': 'DeltaSink[/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/monitor-streams/users]',
'numOutputRows': -1}},
{'id': '24ff8275-0172-4aae-96a7-aff88a4882e7',
'runId': '808e2e6e-d777-4809-8f11-1c8a75135883',
'name': 'user-kafka-stream',
'timestamp': '2025-02-08T04:10:21.362Z',
'batchId': 1,
'numInputRows': 0,
'inputRowsPerSecond': 0.0,
'processedRowsPerSecond': 0.0,
'durationMs': {'latestOffset': 1, 'triggerExecution': 1},
'stateOperators': [],
'sources': [{'description': 'KafkaV2[Subscribe[users]]',
'startOffset': {'users': {'2': 0, '1': 0, '0': 0}},
'endOffset': {'users': {'2': 0, '1': 0, '0': 0}},
'latestOffset': {'users': {'2': 0, '1': 0, '0': 0}},
'numInputRows': 0,
'inputRowsPerSecond': 0.0,
'processedRowsPerSecond': 0.0,
'metrics': {'avgOffsetsBehindLatest': '0.0',
'maxOffsetsBehindLatest': '0',
'minOffsetsBehindLatest': '0'}}],
'sink': {'description': 'DeltaSink[/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/monitor-streams/users]',
'numOutputRows': -1}},
{'id': '24ff8275-0172-4aae-96a7-aff88a4882e7',
'runId': '808e2e6e-d777-4809-8f11-1c8a75135883',
'name': 'user-kafka-stream',
'timestamp': '2025-02-08T04:10:31.370Z',
'batchId': 1,
'numInputRows': 0,
'inputRowsPerSecond': 0.0,
'processedRowsPerSecond': 0.0,
'durationMs': {'latestOffset': 0, 'triggerExecution': 1},
'stateOperators': [],
'sources': [{'description': 'KafkaV2[Subscribe[users]]',
'startOffset': {'users': {'2': 0, '1': 0, '0': 0}},
'endOffset': {'users': {'2': 0, '1': 0, '0': 0}},
'latestOffset': {'users': {'2': 0, '1': 0, '0': 0}},
'numInputRows': 0,
'inputRowsPerSecond': 0.0,
'processedRowsPerSecond': 0.0,
'metrics': {'avgOffsetsBehindLatest': '0.0',
'maxOffsetsBehindLatest': '0',
'minOffsetsBehindLatest': '0'}}],
'sink': {'description': 'DeltaSink[/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/monitor-streams/users]',
'numOutputRows': -1}},
{'id': '24ff8275-0172-4aae-96a7-aff88a4882e7',
'runId': '808e2e6e-d777-4809-8f11-1c8a75135883',
'name': 'user-kafka-stream',
'timestamp': '2025-02-08T04:10:38.085Z',
'batchId': 1,
'numInputRows': 1,
'inputRowsPerSecond': 76.92307692307692,
'processedRowsPerSecond': 0.3155569580309246,
'durationMs': {'addBatch': 3052,
'commitOffsets': 53,
'getBatch': 0,
'latestOffset': 3,
'queryPlanning': 15,
'triggerExecution': 3169,
'walCommit': 45},
'stateOperators': [],
'sources': [{'description': 'KafkaV2[Subscribe[users]]',
'startOffset': {'users': {'2': 0, '1': 0, '0': 0}},
'endOffset': {'users': {'2': 1, '1': 0, '0': 0}},
'latestOffset': {'users': {'2': 1, '1': 0, '0': 0}},
'numInputRows': 1,
'inputRowsPerSecond': 76.92307692307692,
'processedRowsPerSecond': 0.3155569580309246,
'metrics': {'avgOffsetsBehindLatest': '0.0',
'maxOffsetsBehindLatest': '0',
'minOffsetsBehindLatest': '0'}}],
'sink': {'description': 'DeltaSink[/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/monitor-streams/users]',
'numOutputRows': -1}},
{'id': '24ff8275-0172-4aae-96a7-aff88a4882e7',
'runId': '808e2e6e-d777-4809-8f11-1c8a75135883',
'name': 'user-kafka-stream',
'timestamp': '2025-02-08T04:10:51.257Z',
'batchId': 2,
'numInputRows': 0,
'inputRowsPerSecond': 0.0,
'processedRowsPerSecond': 0.0,
'durationMs': {'latestOffset': 0, 'triggerExecution': 0},
'stateOperators': [],
'sources': [{'description': 'KafkaV2[Subscribe[users]]',
'startOffset': {'users': {'2': 1, '1': 0, '0': 0}},
'endOffset': {'users': {'2': 1, '1': 0, '0': 0}},
'latestOffset': {'users': {'2': 1, '1': 0, '0': 0}},
'numInputRows': 0,
'inputRowsPerSecond': 0.0,
'processedRowsPerSecond': 0.0,
'metrics': {'avgOffsetsBehindLatest': '0.0',
'maxOffsetsBehindLatest': '0',
'minOffsetsBehindLatest': '0'}}],
'sink': {'description': 'DeltaSink[/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/monitor-streams/users]',
'numOutputRows': -1}},
{'id': '24ff8275-0172-4aae-96a7-aff88a4882e7',
'runId': '808e2e6e-d777-4809-8f11-1c8a75135883',
'name': 'user-kafka-stream',
'timestamp': '2025-02-08T04:10:58.046Z',
'batchId': 2,
'numInputRows': 1,
'inputRowsPerSecond': 90.90909090909092,
'processedRowsPerSecond': 0.4564125969876769,
'durationMs': {'addBatch': 2113,
'commitOffsets': 45,
'getBatch': 0,
'latestOffset': 2,
'queryPlanning': 9,
'triggerExecution': 2191,
'walCommit': 21},
'stateOperators': [],
'sources': [{'description': 'KafkaV2[Subscribe[users]]',
'startOffset': {'users': {'2': 1, '1': 0, '0': 0}},
'endOffset': {'users': {'2': 2, '1': 0, '0': 0}},
'latestOffset': {'users': {'2': 2, '1': 0, '0': 0}},
'numInputRows': 1,
'inputRowsPerSecond': 90.90909090909092,
'processedRowsPerSecond': 0.4564125969876769,
'metrics': {'avgOffsetsBehindLatest': '0.0',
'maxOffsetsBehindLatest': '0',
'minOffsetsBehindLatest': '0'}}],
'sink': {'description': 'DeltaSink[/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/monitor-streams/users]',
'numOutputRows': -1}},
{'id': '24ff8275-0172-4aae-96a7-aff88a4882e7',
'runId': '808e2e6e-d777-4809-8f11-1c8a75135883',
'name': 'user-kafka-stream',
'timestamp': '2025-02-08T04:11:10.238Z',
'batchId': 3,
'numInputRows': 0,
'inputRowsPerSecond': 0.0,
'processedRowsPerSecond': 0.0,
'durationMs': {'latestOffset': 1, 'triggerExecution': 1},
'stateOperators': [],
'sources': [{'description': 'KafkaV2[Subscribe[users]]',
'startOffset': {'users': {'2': 2, '1': 0, '0': 0}},
'endOffset': {'users': {'2': 2, '1': 0, '0': 0}},
'latestOffset': {'users': {'2': 2, '1': 0, '0': 0}},
'numInputRows': 0,
'inputRowsPerSecond': 0.0,
'processedRowsPerSecond': 0.0,
'metrics': {'avgOffsetsBehindLatest': '0.0',
'maxOffsetsBehindLatest': '0',
'minOffsetsBehindLatest': '0'}}],
'sink': {'description': 'DeltaSink[/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/monitor-streams/users]',
'numOutputRows': -1}},
{'id': '24ff8275-0172-4aae-96a7-aff88a4882e7',
'runId': '808e2e6e-d777-4809-8f11-1c8a75135883',
'name': 'user-kafka-stream',
'timestamp': '2025-02-08T04:11:18.055Z',
'batchId': 3,
'numInputRows': 1,
'inputRowsPerSecond': 90.90909090909092,
'processedRowsPerSecond': 0.3972983710766786,
'durationMs': {'addBatch': 2445,
'commitOffsets': 25,
'getBatch': 0,
'latestOffset': 1,
'queryPlanning': 16,
'triggerExecution': 2517,
'walCommit': 29},
'stateOperators': [],
'sources': [{'description': 'KafkaV2[Subscribe[users]]',
'startOffset': {'users': {'2': 2, '1': 0, '0': 0}},
'endOffset': {'users': {'2': 2, '1': 1, '0': 0}},
'latestOffset': {'users': {'2': 2, '1': 1, '0': 0}},
'numInputRows': 1,
'inputRowsPerSecond': 90.90909090909092,
'processedRowsPerSecond': 0.3972983710766786,
'metrics': {'avgOffsetsBehindLatest': '0.0',
'maxOffsetsBehindLatest': '0',
'minOffsetsBehindLatest': '0'}}],
'sink': {'description': 'DeltaSink[/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/monitor-streams/users]',
'numOutputRows': -1}},
{'id': '24ff8275-0172-4aae-96a7-aff88a4882e7',
'runId': '808e2e6e-d777-4809-8f11-1c8a75135883',
'name': 'user-kafka-stream',
'timestamp': '2025-02-08T04:11:30.581Z',
'batchId': 4,
'numInputRows': 0,
'inputRowsPerSecond': 0.0,
'processedRowsPerSecond': 0.0,
'durationMs': {'latestOffset': 1, 'triggerExecution': 1},
'stateOperators': [],
'sources': [{'description': 'KafkaV2[Subscribe[users]]',
'startOffset': {'users': {'2': 2, '1': 1, '0': 0}},
'endOffset': {'users': {'2': 2, '1': 1, '0': 0}},
'latestOffset': {'users': {'2': 2, '1': 1, '0': 0}},
'numInputRows': 0,
'inputRowsPerSecond': 0.0,
'processedRowsPerSecond': 0.0,
'metrics': {'avgOffsetsBehindLatest': '0.0',
'maxOffsetsBehindLatest': '0',
'minOffsetsBehindLatest': '0'}}],
'sink': {'description': 'DeltaSink[/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/monitor-streams/users]',
'numOutputRows': -1}},
{'id': '24ff8275-0172-4aae-96a7-aff88a4882e7',
'runId': '808e2e6e-d777-4809-8f11-1c8a75135883',
'name': 'user-kafka-stream',
'timestamp': '2025-02-08T04:11:38.048Z',
'batchId': 4,
'numInputRows': 1,
'inputRowsPerSecond': 90.90909090909092,
'processedRowsPerSecond': 0.48995590396864286,
'durationMs': {'addBatch': 1982,
'commitOffsets': 32,
'getBatch': 0,
'latestOffset': 0,
'queryPlanning': 7,
'triggerExecution': 2041,
'walCommit': 19},
'stateOperators': [],
'sources': [{'description': 'KafkaV2[Subscribe[users]]',
'startOffset': {'users': {'2': 2, '1': 1, '0': 0}},
'endOffset': {'users': {'2': 2, '1': 1, '0': 1}},
'latestOffset': {'users': {'2': 2, '1': 1, '0': 1}},
'numInputRows': 1,
'inputRowsPerSecond': 90.90909090909092,
'processedRowsPerSecond': 0.48995590396864286,
'metrics': {'avgOffsetsBehindLatest': '0.0',
'maxOffsetsBehindLatest': '0',
'minOffsetsBehindLatest': '0'}}],
'sink': {'description': 'DeltaSink[/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/monitor-streams/users]',
'numOutputRows': -1}},
{'id': '24ff8275-0172-4aae-96a7-aff88a4882e7',
'runId': '808e2e6e-d777-4809-8f11-1c8a75135883',
'name': 'user-kafka-stream',
'timestamp': '2025-02-08T04:11:50.095Z',
'batchId': 5,
'numInputRows': 0,
'inputRowsPerSecond': 0.0,
'processedRowsPerSecond': 0.0,
'durationMs': {'latestOffset': 1, 'triggerExecution': 1},
'stateOperators': [],
'sources': [{'description': 'KafkaV2[Subscribe[users]]',
'startOffset': {'users': {'2': 2, '1': 1, '0': 1}},
'endOffset': {'users': {'2': 2, '1': 1, '0': 1}},
'latestOffset': {'users': {'2': 2, '1': 1, '0': 1}},
'numInputRows': 0,
'inputRowsPerSecond': 0.0,
'processedRowsPerSecond': 0.0,
'metrics': {'avgOffsetsBehindLatest': '0.0',
'maxOffsetsBehindLatest': '0',
'minOffsetsBehindLatest': '0'}}],
'sink': {'description': 'DeltaSink[/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/monitor-streams/users]',
'numOutputRows': -1}},
{'id': '24ff8275-0172-4aae-96a7-aff88a4882e7',
'runId': '808e2e6e-d777-4809-8f11-1c8a75135883',
'name': 'user-kafka-stream',
'timestamp': '2025-02-08T04:11:58.055Z',
'batchId': 5,
'numInputRows': 1,
'inputRowsPerSecond': 90.90909090909092,
'processedRowsPerSecond': 0.5817335660267597,
'durationMs': {'addBatch': 1670,
'commitOffsets': 22,
'getBatch': 0,
'latestOffset': 0,
'queryPlanning': 8,
'triggerExecution': 1719,
'walCommit': 19},
'stateOperators': [],
'sources': [{'description': 'KafkaV2[Subscribe[users]]',
'startOffset': {'users': {'2': 2, '1': 1, '0': 1}},
'endOffset': {'users': {'2': 2, '1': 2, '0': 1}},
'latestOffset': {'users': {'2': 2, '1': 2, '0': 1}},
'numInputRows': 1,
'inputRowsPerSecond': 90.90909090909092,
'processedRowsPerSecond': 0.5817335660267597,
'metrics': {'avgOffsetsBehindLatest': '0.0',
'maxOffsetsBehindLatest': '0',
'minOffsetsBehindLatest': '0'}}],
'sink': {'description': 'DeltaSink[/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/monitor-streams/users]',
'numOutputRows': -1}},
{'id': '24ff8275-0172-4aae-96a7-aff88a4882e7',
'runId': '808e2e6e-d777-4809-8f11-1c8a75135883',
'name': 'user-kafka-stream',
'timestamp': '2025-02-08T04:12:09.775Z',
'batchId': 6,
'numInputRows': 0,
'inputRowsPerSecond': 0.0,
'processedRowsPerSecond': 0.0,
'durationMs': {'latestOffset': 2, 'triggerExecution': 2},
'stateOperators': [],
'sources': [{'description': 'KafkaV2[Subscribe[users]]',
'startOffset': {'users': {'2': 2, '1': 2, '0': 1}},
'endOffset': {'users': {'2': 2, '1': 2, '0': 1}},
'latestOffset': {'users': {'2': 2, '1': 2, '0': 1}},
'numInputRows': 0,
'inputRowsPerSecond': 0.0,
'processedRowsPerSecond': 0.0,
'metrics': {'avgOffsetsBehindLatest': '0.0',
'maxOffsetsBehindLatest': '0',
'minOffsetsBehindLatest': '0'}}],
'sink': {'description': 'DeltaSink[/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/monitor-streams/users]',
'numOutputRows': -1}}]



from pyspark.sql.streaming import StreamingQueryListener # Define a custom listener class class MyListener(StreamingQueryListener): # Override the onQueryStarted method def onQueryStarted(self, event): # Print the query name and id when it starts print(f"'{event.name}' [{event.id}] got started!") # Override the onQueryProgress method def onQueryProgress(self, event): # Print the input rate and processing rate when it progresses print(f"Query made progress: " + str(event.progress)) # Override the onQueryTerminated method def onQueryTerminated(self, event): # Print the exception message when it terminates if event.exception: print(f"Query with id {event.id} terminated with exception: {event}") else: print(f"Query with id {event.id} terminated normally") # Create an instance of the listener class listener = MyListener() # Register the listener with spark.streams spark.streams.addListener(listener)
Query made progress: {
"id" : "24ff8275-0172-4aae-96a7-aff88a4882e7",
"runId" : "808e2e6e-d777-4809-8f11-1c8a75135883",
"name" : "user-kafka-stream",
"timestamp" : "2025-02-08T04:31:11.695Z",
"batchId" : 18,
"numInputRows" : 1,
"inputRowsPerSecond" : 90.90909090909092,
"processedRowsPerSecond" : 0.5858230814294083,
"durationMs" : {
"addBatch" : 1654,
"commitOffsets" : 26,
"getBatch" : 0,
"latestOffset" : 0,
"queryPlanning" : 6,
"triggerExecution" : 1707,
"walCommit" : 20
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "KafkaV2[Subscribe[users]]",
"startOffset" : {
"users" : {
"2" : 8,
"1" : 4,
"0" : 5
}
},
"endOffset" : {
"users" : {
"2" : 8,
"1" : 5,
"0" : 5
}
},
"latestOffset" : {
"users" : {
"2" : 8,
"1" : 5,
"0" : 5
}
},
"numInputRows" : 1,
"inputRowsPerSecond" : 90.90909090909092,
"processedRowsPerSecond" : 0.5858230814294083,
"metrics" : {
"avgOffsetsBehindLatest" : "0.0",
"maxOffsetsBehindLatest" : "0",
"minOffsetsBehindLatest" : "0"
}
} ],
"sink" : {
"description" : "DeltaSink[/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/monitor-streams/users]",
"numOutputRows" : -1
}
}
Query made progress: {
"id" : "24ff8275-0172-4aae-96a7-aff88a4882e7",
"runId" : "808e2e6e-d777-4809-8f11-1c8a75135883",
"name" : "user-kafka-stream",
"timestamp" : "2025-02-08T04:31:21.700Z",
"batchId" : 19,
"numInputRows" : 1,
"inputRowsPerSecond" : 90.90909090909092,
"processedRowsPerSecond" : 0.6506180871828238,
"durationMs" : {
"addBatch" : 1492,
"commitOffsets" : 22,
"getBatch" : 0,
"latestOffset" : 0,
"queryPlanning" : 4,
"triggerExecution" : 1537,
"walCommit" : 18
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "KafkaV2[Subscribe[users]]",
"startOffset" : {
"users" : {
"2" : 8,
"1" : 5,
"0" : 5
}
},
"endOffset" : {
"users" : {
"2" : 9,
"1" : 5,
"0" : 5
}
},
"latestOffset" : {
"users" : {
"2" : 9,
"1" : 5,
"0" : 5
}
},
"numInputRows" : 1,
"inputRowsPerSecond" : 90.90909090909092,
"processedRowsPerSecond" : 0.6506180871828238,
"metrics" : {
"avgOffsetsBehindLatest" : "0.0",
"maxOffsetsBehindLatest" : "0",
"minOffsetsBehindLatest" : "0"
}
} ],
"sink" : {
"description" : "DeltaSink[/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/monitor-streams/users]",
"numOutputRows" : -1
}
}
Query made progress: {
"id" : "24ff8275-0172-4aae-96a7-aff88a4882e7",
"runId" : "808e2e6e-d777-4809-8f11-1c8a75135883",
"name" : "user-kafka-stream",
"timestamp" : "2025-02-08T04:31:31.697Z",
"batchId" : 20,
"numInputRows" : 1,
"inputRowsPerSecond" : 83.33333333333333,
"processedRowsPerSecond" : 0.5162622612287042,
"durationMs" : {
"addBatch" : 1895,
"commitOffsets" : 19,
"getBatch" : 0,
"latestOffset" : 0,
"queryPlanning" : 5,
"triggerExecution" : 1937,
"walCommit" : 18
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "KafkaV2[Subscribe[users]]",
"startOffset" : {
"users" : {
"2" : 9,
"1" : 5,
"0" : 5
}
},
"endOffset" : {
"users" : {
"2" : 9,
"1" : 6,
"0" : 5
}
},
"latestOffset" : {
"users" : {
"2" : 9,
"1" : 6,
"0" : 5
}
},
"numInputRows" : 1,
"inputRowsPerSecond" : 83.33333333333333,
"processedRowsPerSecond" : 0.5162622612287042,
"metrics" : {
"avgOffsetsBehindLatest" : "0.0",
"maxOffsetsBehindLatest" : "0",
"minOffsetsBehindLatest" : "0"
}
} ],
"sink" : {
"description" : "DeltaSink[/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/monitor-streams/users]",
"numOutputRows" : -1
}
}
......
Ran 'query.stop()' and the output updated:
...... Query with id 24ff8275-0172-4aae-96a7-aff88a4882e7 terminated normally
spark.stop()



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律