



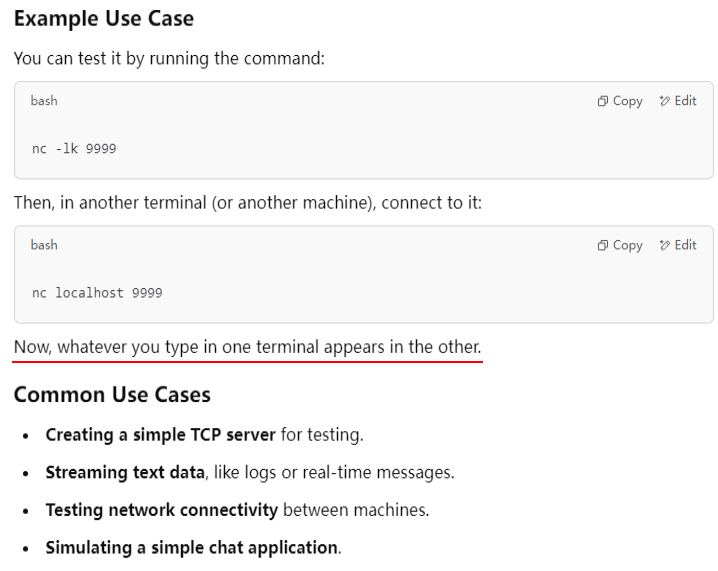
nc -lk 9999

from pyspark.sql import SparkSession from pyspark.sql.functions import explode, split spark = (SparkSession.builder .appName("config-streaming") .master("spark://ZZHPC:7077") .getOrCreate()) spark.sparkContext.setLogLevel("ERROR")

# Create DataFrame representing the stream of input lines from connection to localhost:9999 lines = (spark.readStream.format("socket") .option("host", "localhost") .option("port", 9999) .load())

# Split the lines into words words = lines.select(explode(split(lines.value, " ")).alias("word"))
words.printSchema()
root |-- word: string (nullable = false)
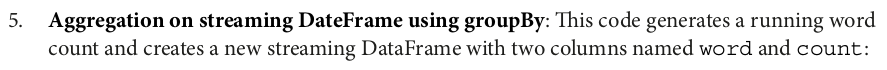
wordCounts = words.groupBy("word").count()

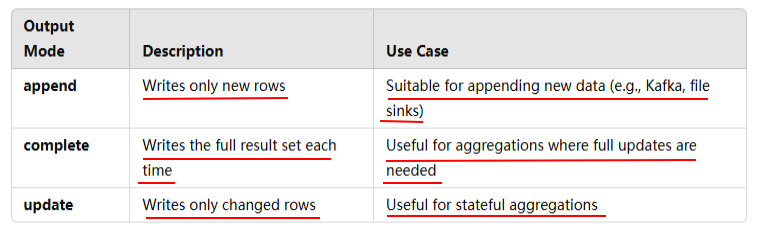
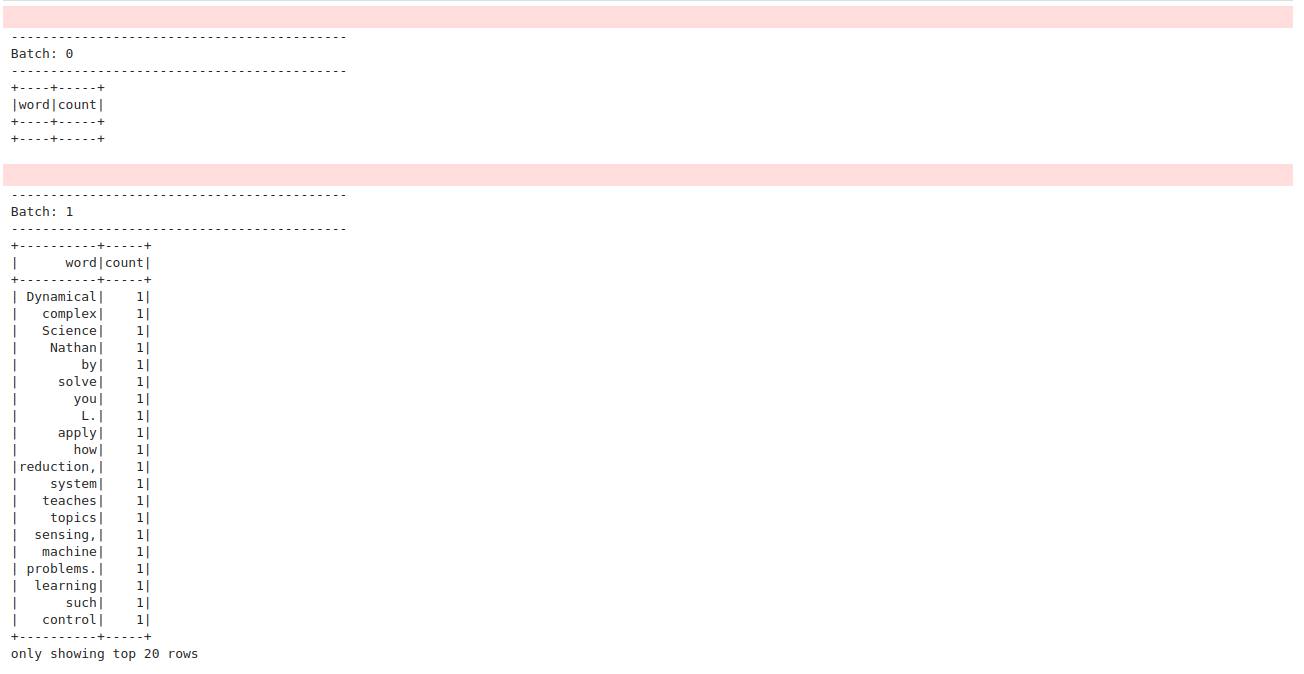
# Start running the query that prints the running counts to the console query = (wordCounts.writeStream.format("console") .outputMode("complete") .start())
------------------------------------------- Batch: 0 ------------------------------------------- +----+-----+ |word|count| +----+-----+ +----+-----+

A new batch for the stream query is triggered, and the output is updated as shown:
query.stop()
spark.stop()



import json import random import time from kafka import KafkaProducer import datetime producer = KafkaProducer(bootstrap_servers='localhost:9092') countries = ['USA', 'UK', 'India', 'China', 'Brazil', 'Canada', 'Australia'] genders = ['M', 'F'] while True: current_time = time.time() message = { 'id': random.randint(1, 100), 'name': f'user{random.randint(1, 100)}', 'age': random.randint(18, 65), 'gender': random.choice(genders), 'country': random.choice(countries), 'timestamp':datetime.datetime.fromtimestamp(current_time).strftime("%m/%d/%Y, %H:%M:%S") } producer.send('users', value=json.dumps(message).encode('utf-8')) print(message) time.sleep(30)
{'id': 48, 'name': 'user13', 'age': 34, 'gender': 'F', 'country': 'UK', 'timestamp': '02/05/2025, 19:32:31'}
{'id': 63, 'name': 'user39', 'age': 31, 'gender': 'M', 'country': 'China', 'timestamp': '02/05/2025, 19:32:41'}
{'id': 24, 'name': 'user34', 'age': 60, 'gender': 'M', 'country': 'Australia', 'timestamp': '02/05/2025, 19:32:51'}
{'id': 33, 'name': 'user23', 'age': 27, 'gender': 'M', 'country': 'Brazil', 'timestamp': '02/05/2025, 19:33:01'}
{'id': 21, 'name': 'user23', 'age': 62, 'gender': 'M', 'country': 'Brazil', 'timestamp': '02/05/2025, 19:33:11'}
zzh@ZZHPC:~$ kafka-console-consumer.sh --topic users --bootstrap-server localhost:9092 --from-beginning
zzh
{"id": 48, "name": "user13", "age": 34, "gender": "F", "country": "UK", "timestamp": "02/05/2025, 19:32:31"}
{"id": 63, "name": "user39", "age": 31, "gender": "M", "country": "China", "timestamp": "02/05/2025, 19:32:41"}
{"id": 24, "name": "user34", "age": 60, "gender": "M", "country": "Australia", "timestamp": "02/05/2025, 19:32:51"}
{"id": 33, "name": "user23", "age": 27, "gender": "M", "country": "Brazil", "timestamp": "02/05/2025, 19:33:01"}
{"id": 21, "name": "user23", "age": 62, "gender": "M", "country": "Brazil", "timestamp": "02/05/2025, 19:33:11"}
from delta import configure_spark_with_delta_pip from pyspark.sql import SparkSession from pyspark.sql.functions import col, from_json from pyspark.sql.types import StructType, StructField, IntegerType, StringType builder = (SparkSession.builder .appName("connect-kafka-streaming") .master("spark://ZZHPC:7077") .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")) spark = configure_spark_with_delta_pip(builder,['org.apache.spark:spark-sql-kafka-0-10_2.12:3.4.1']).getOrCreate() spark.sparkContext.setLogLevel("ERROR")

df = (spark.readStream.format("kafka") .option("kafka.bootstrap.servers", "localhost:9092") .option("subscribe", "users") .option("startingOffsets", "earliest") .load())

schema = StructType([ StructField('id', IntegerType(), True), StructField('name', StringType(), True), StructField('age', IntegerType(), True), StructField('gender', StringType(), True), StructField('country', StringType(), True)]) df = df.withColumn('value', from_json(col('value').cast("STRING"), schema))

df = df.select( col('value.id').alias('id'), col('value.name').alias('name'), col('value.age').alias('age'), col('value.gender').alias('gender'), col('value.country').alias('country'))

query = (df.writeStream.format('console') .outputMode('append') .start())
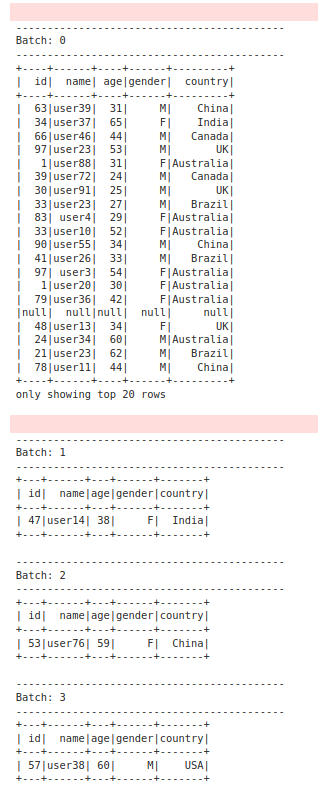
......
query.stop()


from delta import configure_spark_with_delta_pip from pyspark.sql import SparkSession from pyspark.sql.functions import col, from_json, avg from pyspark.sql.types import StructType, StructField, IntegerType, StringType builder = (SparkSession.builder .appName("transform-filter-streaming") .master("spark://ZZHPC:7077") .config("spark.executor.memory", "512m") .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")) spark = configure_spark_with_delta_pip(builder,['org.apache.spark:spark-sql-kafka-0-10_2.12:3.4.1']).getOrCreate() spark.sparkContext.setLogLevel("ERROR")
25/02/06 10:24:41 WARN Utils: Your hostname, ZZHPC resolves to a loopback address: 127.0.1.1; using 192.168.1.16 instead (on interface wlo1) 25/02/06 10:24:41 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address :: loading settings :: url = jar:file:/home/zzh/Downloads/sfw/spark-3.4.1-bin-hadoop3/jars/ivy-2.5.1.jar!/org/apache/ivy/core/settings/ivysettings.xml Ivy Default Cache set to: /home/zzh/.ivy2/cache The jars for the packages stored in: /home/zzh/.ivy2/jars io.delta#delta-core_2.12 added as a dependency org.apache.spark#spark-sql-kafka-0-10_2.12 added as a dependency :: resolving dependencies :: org.apache.spark#spark-submit-parent-acdab19a-0418-4169-814d-6f0620da624d;1.0 confs: [default] found io.delta#delta-core_2.12;2.4.0 in central found io.delta#delta-storage;2.4.0 in central found org.antlr#antlr4-runtime;4.9.3 in central found org.apache.spark#spark-sql-kafka-0-10_2.12;3.4.1 in central found org.apache.spark#spark-token-provider-kafka-0-10_2.12;3.4.1 in central found org.apache.kafka#kafka-clients;3.3.2 in central found org.lz4#lz4-java;1.8.0 in central found org.xerial.snappy#snappy-java;1.1.10.1 in central found org.slf4j#slf4j-api;2.0.6 in central found org.apache.hadoop#hadoop-client-runtime;3.3.4 in central found org.apache.hadoop#hadoop-client-api;3.3.4 in central found commons-logging#commons-logging;1.1.3 in central found com.google.code.findbugs#jsr305;3.0.0 in central found org.apache.commons#commons-pool2;2.11.1 in central :: resolution report :: resolve 428ms :: artifacts dl 19ms :: modules in use: com.google.code.findbugs#jsr305;3.0.0 from central in [default] commons-logging#commons-logging;1.1.3 from central in [default] io.delta#delta-core_2.12;2.4.0 from central in [default] io.delta#delta-storage;2.4.0 from central in [default] org.antlr#antlr4-runtime;4.9.3 from central in [default] org.apache.commons#commons-pool2;2.11.1 from central in [default] org.apache.hadoop#hadoop-client-api;3.3.4 from central in [default] org.apache.hadoop#hadoop-client-runtime;3.3.4 from central in [default] org.apache.kafka#kafka-clients;3.3.2 from central in [default] org.apache.spark#spark-sql-kafka-0-10_2.12;3.4.1 from central in [default] org.apache.spark#spark-token-provider-kafka-0-10_2.12;3.4.1 from central in [default] org.lz4#lz4-java;1.8.0 from central in [default] org.slf4j#slf4j-api;2.0.6 from central in [default] org.xerial.snappy#snappy-java;1.1.10.1 from central in [default] --------------------------------------------------------------------- | | modules || artifacts | | conf | number| search|dwnlded|evicted|| number|dwnlded| --------------------------------------------------------------------- | default | 14 | 0 | 0 | 0 || 14 | 0 | --------------------------------------------------------------------- :: retrieving :: org.apache.spark#spark-submit-parent-acdab19a-0418-4169-814d-6f0620da624d confs: [default] 0 artifacts copied, 14 already retrieved (0kB/10ms) 25/02/06 10:24:42 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
df = (spark.readStream .format("kafka") .option("kafka.bootstrap.servers", "localhost:9092") .option("subscribe", "users") .option("startingOffsets", "earliest") .load())
schema = StructType([ StructField('id', IntegerType(), True), StructField('name', StringType(), True), StructField('age', IntegerType(), True), StructField('gender', StringType(), True), StructField('country', StringType(), True)]) df = df.withColumn('value', from_json(col('value').cast("STRING"), schema))
df = df.select( col('value.id').alias('id'), col('value.name').alias('name'), col('value.age').alias('age'), col('value.gender').alias('gender'), col('value.country').alias('country'))
df = (df.select('age','country', 'gender').filter("age >= 21").groupBy('country', 'gender').agg(avg('age').alias('avg_age')))
query = (df.writeStream .outputMode('complete') .format('console') .start())
-------------------------------------------
Batch: 0
-------------------------------------------
+---------+------+-------+
| country|gender|avg_age|
+---------+------+-------+
| Brazil| F| 36.0|
| Brazil| M| 63.0|
|Australia| F| 40.0|
| Canada| M| 61.0|
| UK| M| 50.0|
| India| M| 52.0|
| China| M| 51.0|
| China| F| 27.5|
| Canada| F| 30.5|
|Australia| M| 49.0|
| India| F| 44.75|
| UK| F| 38.0|
+---------+------+-------+
-------------------------------------------
Batch: 1
-------------------------------------------
+---------+------+-------+
| country|gender|avg_age|
+---------+------+-------+
| Brazil| F| 36.0|
| Brazil| M| 63.0|
|Australia| F| 40.0|
| Canada| M| 61.0|
| UK| M| 50.0|
| India| M| 52.0|
| China| M| 51.0|
| China| F| 27.5|
| Canada| F| 33.0|
|Australia| M| 49.0|
| India| F| 44.75|
| UK| F| 38.0|
+---------+------+-------+
-------------------------------------------
Batch: 2
-------------------------------------------
+---------+------+-------+
| country|gender|avg_age|
+---------+------+-------+
| Brazil| F| 36.0|
| Brazil| M| 63.0|
|Australia| F| 40.0|
| Canada| M| 61.0|
| UK| M| 50.0|
| India| M| 52.0|
| China| M| 51.0|
| China| F| 27.5|
| Canada| F| 33.0|
|Australia| M| 46.0|
| India| F| 44.75|
| UK| F| 38.0|
+---------+------+-------+
query.stop() spark.stop()

from delta import configure_spark_with_delta_pip from pyspark.sql import SparkSession from pyspark.sql.functions import col, from_json from pyspark.sql.types import StructType, StructField, IntegerType, StringType builder = (SparkSession.builder .appName("config-checkpoints") .master("spark://ZZHPC:7077") .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")) spark = configure_spark_with_delta_pip(builder,['org.apache.spark:spark-sql-kafka-0-10_2.12:3.4.1']).getOrCreate() spark.sparkContext.setLogLevel("ERROR")
25/02/06 10:47:28 WARN Utils: Your hostname, ZZHPC resolves to a loopback address: 127.0.1.1; using 192.168.1.16 instead (on interface wlo1) 25/02/06 10:47:28 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address :: loading settings :: url = jar:file:/home/zzh/Downloads/sfw/spark-3.4.1-bin-hadoop3/jars/ivy-2.5.1.jar!/org/apache/ivy/core/settings/ivysettings.xml Ivy Default Cache set to: /home/zzh/.ivy2/cache The jars for the packages stored in: /home/zzh/.ivy2/jars io.delta#delta-core_2.12 added as a dependency org.apache.spark#spark-sql-kafka-0-10_2.12 added as a dependency :: resolving dependencies :: org.apache.spark#spark-submit-parent-2172143e-be74-4efa-8d11-0235ebe436cb;1.0 confs: [default] found io.delta#delta-core_2.12;2.4.0 in central found io.delta#delta-storage;2.4.0 in central found org.antlr#antlr4-runtime;4.9.3 in central found org.apache.spark#spark-sql-kafka-0-10_2.12;3.4.1 in central found org.apache.spark#spark-token-provider-kafka-0-10_2.12;3.4.1 in central found org.apache.kafka#kafka-clients;3.3.2 in central found org.lz4#lz4-java;1.8.0 in central found org.xerial.snappy#snappy-java;1.1.10.1 in central found org.slf4j#slf4j-api;2.0.6 in central found org.apache.hadoop#hadoop-client-runtime;3.3.4 in central found org.apache.hadoop#hadoop-client-api;3.3.4 in central found commons-logging#commons-logging;1.1.3 in central found com.google.code.findbugs#jsr305;3.0.0 in central found org.apache.commons#commons-pool2;2.11.1 in central :: resolution report :: resolve 455ms :: artifacts dl 17ms :: modules in use: com.google.code.findbugs#jsr305;3.0.0 from central in [default] commons-logging#commons-logging;1.1.3 from central in [default] io.delta#delta-core_2.12;2.4.0 from central in [default] io.delta#delta-storage;2.4.0 from central in [default] org.antlr#antlr4-runtime;4.9.3 from central in [default] org.apache.commons#commons-pool2;2.11.1 from central in [default] org.apache.hadoop#hadoop-client-api;3.3.4 from central in [default] org.apache.hadoop#hadoop-client-runtime;3.3.4 from central in [default] org.apache.kafka#kafka-clients;3.3.2 from central in [default] org.apache.spark#spark-sql-kafka-0-10_2.12;3.4.1 from central in [default] org.apache.spark#spark-token-provider-kafka-0-10_2.12;3.4.1 from central in [default] org.lz4#lz4-java;1.8.0 from central in [default] org.slf4j#slf4j-api;2.0.6 from central in [default] org.xerial.snappy#snappy-java;1.1.10.1 from central in [default] --------------------------------------------------------------------- | | modules || artifacts | | conf | number| search|dwnlded|evicted|| number|dwnlded| --------------------------------------------------------------------- | default | 14 | 0 | 0 | 0 || 14 | 0 | --------------------------------------------------------------------- :: retrieving :: org.apache.spark#spark-submit-parent-2172143e-be74-4efa-8d11-0235ebe436cb confs: [default] 0 artifacts copied, 14 already retrieved (0kB/9ms) 25/02/06 10:47:29 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
get_ipython().run_line_magic('load_ext', 'sparksql_magic') get_ipython().run_line_magic('config', 'SparkSql.limit=20')
df = (spark.readStream .format("kafka") .option("kafka.bootstrap.servers", "localhost:9092") .option("subscribe", "users") .option("startingOffsets", "earliest") .load())
schema = StructType([ StructField('id', IntegerType(), True), StructField('name', StringType(), True), StructField('age', IntegerType(), True), StructField('gender', StringType(), True), StructField('country', StringType(), True)]) df = df.withColumn('value', from_json(col('value').cast("STRING"), schema))
df = df.select( col('value.id').alias('id'), col('value.name').alias('name'), col('value.age').alias('age'), col('value.gender').alias('gender'), col('value.country').alias('country'))

query = (df.writeStream .format("console") .outputMode("append") .option("checkpointLocation", "/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/checkpoint") .start())
-------------------------------------------
Batch: 0
-------------------------------------------
+---+------+---+------+---------+
| id| name|age|gender| country|
+---+------+---+------+---------+
| 41| user4| 40| F|Australia|
| 27|user30| 39| F| Canada|
| 19|user80| 30| F| China|
| 44|user95| 51| F| USA|
| 31| user6| 22| M| China|
| 52| user5| 62| M| Brazil|
| 36|user73| 57| M| UK|
| 86|user18| 62| M| Canada|
| 22|user66| 18| M| UK|
| 42| user8| 22| F| Canada|
| 37|user38| 51| M| China|
| 98|user85| 62| M|Australia|
| 22| user8| 50| M| UK|
| 48|user64| 21| F| Brazil|
| 41|user98| 26| F| India|
| 97|user90| 38| F| UK|
| 64|user12| 38| F| Canada|
| 47|user33| 40| M|Australia|
| 9|user89| 62| F|Australia|
| 91|user42| 54| F| Brazil|
+---+------+---+------+---------+
only showing top 20 rows
-------------------------------------------
Batch: 1
-------------------------------------------
+---+------+---+------+-------+
| id| name|age|gender|country|
+---+------+---+------+-------+
| 4|user16| 21| M| India|
+---+------+---+------+-------+
-------------------------------------------
Batch: 2
-------------------------------------------
+---+------+---+------+-------+
| id| name|age|gender|country|
+---+------+---+------+-------+
| 67|user57| 40| F| Brazil|
+---+------+---+------+-------+

zzh@ZZHPC:/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/checkpoint$ tree .
.
├── commits
│ ├── 0
│ ├── 1
│ └── 2
├── metadata
├── offsets
│ ├── 0
│ ├── 1
│ └── 2
└── sources
└── 0
└── 0

query.stop()

query = (df.writeStream .format("console") .outputMode("append") .option("checkpointLocation", "/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/checkpoint") .start())
-------------------------------------------
Batch: 3
-------------------------------------------
+---+-------+---+------+---------+
| id| name|age|gender| country|
+---+-------+---+------+---------+
| 71| user94| 48| M| Brazil|
| 27| user91| 52| M| India|
| 30| user14| 57| F| Brazil|
| 40| user40| 20| M| China|
| 88| user84| 29| F| USA|
| 68| user35| 22| F| Brazil|
| 18| user85| 63| F| Brazil|
| 69| user15| 51| M| Canada|
| 83| user35| 47| F|Australia|
| 58| user37| 54| F| China|
| 14|user100| 53| M|Australia|
| 21| user68| 48| F| Brazil|
+---+-------+---+------+---------+
-------------------------------------------
Batch: 4
-------------------------------------------
+---+------+---+------+-------+
| id| name|age|gender|country|
+---+------+---+------+-------+
| 21|user29| 21| F| UK|
+---+------+---+------+-------+
query.stop()
spark.stop()

from delta import configure_spark_with_delta_pip from pyspark.sql import SparkSession from pyspark.sql.functions import col, from_json from pyspark.sql.types import StructType, StructField, IntegerType, StringType builder = (SparkSession.builder .appName("config-triggers") .master("spark://ZZHPC:7077") .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")) spark = configure_spark_with_delta_pip(builder,['org.apache.spark:spark-sql-kafka-0-10_2.12:3.4.1']).getOrCreate() spark.sparkContext.setLogLevel("ERROR") get_ipython().run_line_magic('load_ext', 'sparksql_magic') get_ipython().run_line_magic('config', 'SparkSql.limit=20')
df = (spark.readStream .format("kafka") .option("kafka.bootstrap.servers", "localhost:9092") .option("subscribe", "users") .option("startingOffsets", "earliest") .load())
schema = StructType([ StructField('id', IntegerType(), True), StructField('name', StringType(), True), StructField('age', IntegerType(), True), StructField('gender', StringType(), True), StructField('country', StringType(), True)]) df = df.withColumn('value', from_json(col('value').cast("STRING"), schema))
df = df.select( col('value.id').alias('id'), col('value.name').alias('name'), col('value.age').alias('age'), col('value.gender').alias('gender'), col('value.country').alias('country'))

query = (df.writeStream .format("console") .outputMode("append") .start())
-------------------------------------------
Batch: 0
-------------------------------------------
+----+--------------------+-----+---------+------+--------------------+-------------+
| key| value|topic|partition|offset| timestamp|timestampType|
+----+--------------------+-----+---------+------+--------------------+-------------+
|null|[7B 22 69 64 22 3...|users| 1| 0|2025-02-06 10:32:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 1|2025-02-06 10:35:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 2|2025-02-06 10:38:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 3|2025-02-06 10:44:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 4|2025-02-06 10:45:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 5|2025-02-06 10:46:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 6|2025-02-06 10:49:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 7|2025-02-06 10:51:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 8|2025-02-06 10:53:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 9|2025-02-06 10:54:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 10|2025-02-06 10:58:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 11|2025-02-06 10:59:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 12|2025-02-06 11:04:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 13|2025-02-06 11:05:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 14|2025-02-06 11:07:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 15|2025-02-06 11:08:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 16|2025-02-06 11:09:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 17|2025-02-06 11:10:...| 0|
|null|[7B 22 69 64 22 3...|users| 0| 0|2025-02-06 10:29:...| 0|
|null|[7B 22 69 64 22 3...|users| 0| 1|2025-02-06 10:35:...| 0|
+----+--------------------+-----+---------+------+--------------------+-------------+
only showing top 20 rows
-------------------------------------------
Batch: 1
-------------------------------------------
+----+--------------------+-----+---------+------+--------------------+-------------+
| key| value|topic|partition|offset| timestamp|timestampType|
+----+--------------------+-----+---------+------+--------------------+-------------+
|null|[7B 22 69 64 22 3...|users| 1| 18|2025-02-06 11:21:...| 0|
+----+--------------------+-----+---------+------+--------------------+-------------+
-------------------------------------------
Batch: 2
-------------------------------------------
+----+--------------------+-----+---------+------+--------------------+-------------+
| key| value|topic|partition|offset| timestamp|timestampType|
+----+--------------------+-----+---------+------+--------------------+-------------+
|null|[7B 22 69 64 22 3...|users| 1| 19|2025-02-06 11:22:...| 0|
+----+--------------------+-----+---------+------+--------------------+-------------+
-------------------------------------------
Batch: 3
-------------------------------------------
+----+--------------------+-----+---------+------+--------------------+-------------+
| key| value|topic|partition|offset| timestamp|timestampType|
+----+--------------------+-----+---------+------+--------------------+-------------+
|null|[7B 22 69 64 22 3...|users| 1| 20|2025-02-06 11:23:...| 0|
+----+--------------------+-----+---------+------+--------------------+-------------+
query.stop()

query = (df.writeStream .format("console") .outputMode("append") .trigger(processingTime='30 seconds') .start())
-------------------------------------------
Batch: 0
-------------------------------------------
+----+--------------------+-----+---------+------+--------------------+-------------+
| key| value|topic|partition|offset| timestamp|timestampType|
+----+--------------------+-----+---------+------+--------------------+-------------+
|null|[7B 22 69 64 22 3...|users| 1| 0|2025-02-06 10:32:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 1|2025-02-06 10:35:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 2|2025-02-06 10:38:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 3|2025-02-06 10:44:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 4|2025-02-06 10:45:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 5|2025-02-06 10:46:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 6|2025-02-06 10:49:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 7|2025-02-06 10:51:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 8|2025-02-06 10:53:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 9|2025-02-06 10:54:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 10|2025-02-06 10:58:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 11|2025-02-06 10:59:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 12|2025-02-06 11:04:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 13|2025-02-06 11:05:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 14|2025-02-06 11:07:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 15|2025-02-06 11:08:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 16|2025-02-06 11:09:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 17|2025-02-06 11:10:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 18|2025-02-06 11:21:...| 0|
|null|[7B 22 69 64 22 3...|users| 1| 19|2025-02-06 11:22:...| 0|
+----+--------------------+-----+---------+------+--------------------+-------------+
only showing top 20 rows
-------------------------------------------
Batch: 1
-------------------------------------------
+----+--------------------+-----+---------+------+--------------------+-------------+
| key| value|topic|partition|offset| timestamp|timestampType|
+----+--------------------+-----+---------+------+--------------------+-------------+
|null|[7B 22 69 64 22 3...|users| 1| 22|2025-02-06 11:29:...| 0|
|null|[7B 22 69 64 22 3...|users| 2| 19|2025-02-06 11:29:...| 0|
+----+--------------------+-----+---------+------+--------------------+-------------+
-------------------------------------------
Batch: 2
-------------------------------------------
+----+--------------------+-----+---------+------+--------------------+-------------+
| key| value|topic|partition|offset| timestamp|timestampType|
+----+--------------------+-----+---------+------+--------------------+-------------+
|null|[7B 22 69 64 22 3...|users| 1| 23|2025-02-06 11:29:...| 0|
|null|[7B 22 69 64 22 3...|users| 2| 20|2025-02-06 11:29:...| 0|
|null|[7B 22 69 64 22 3...|users| 2| 21|2025-02-06 11:29:...| 0|
+----+--------------------+-----+---------+------+--------------------+-------------+
query.stop()

query = (df.writeStream .format("console") .outputMode("append") .trigger(once=True) .start())
------------------------------------------- Batch: 0 ------------------------------------------- +----+--------------------+-----+---------+------+--------------------+-------------+ | key| value|topic|partition|offset| timestamp|timestampType| +----+--------------------+-----+---------+------+--------------------+-------------+ |null|[7B 22 69 64 22 3...|users| 1| 0|2025-02-06 10:32:...| 0| |null|[7B 22 69 64 22 3...|users| 1| 1|2025-02-06 10:35:...| 0| |null|[7B 22 69 64 22 3...|users| 1| 2|2025-02-06 10:38:...| 0| |null|[7B 22 69 64 22 3...|users| 1| 3|2025-02-06 10:44:...| 0| |null|[7B 22 69 64 22 3...|users| 1| 4|2025-02-06 10:45:...| 0| |null|[7B 22 69 64 22 3...|users| 1| 5|2025-02-06 10:46:...| 0| |null|[7B 22 69 64 22 3...|users| 1| 6|2025-02-06 10:49:...| 0| |null|[7B 22 69 64 22 3...|users| 1| 7|2025-02-06 10:51:...| 0| |null|[7B 22 69 64 22 3...|users| 1| 8|2025-02-06 10:53:...| 0| |null|[7B 22 69 64 22 3...|users| 1| 9|2025-02-06 10:54:...| 0| |null|[7B 22 69 64 22 3...|users| 1| 10|2025-02-06 10:58:...| 0| |null|[7B 22 69 64 22 3...|users| 1| 11|2025-02-06 10:59:...| 0| |null|[7B 22 69 64 22 3...|users| 1| 12|2025-02-06 11:04:...| 0| |null|[7B 22 69 64 22 3...|users| 1| 13|2025-02-06 11:05:...| 0| |null|[7B 22 69 64 22 3...|users| 1| 14|2025-02-06 11:07:...| 0| |null|[7B 22 69 64 22 3...|users| 1| 15|2025-02-06 11:08:...| 0| |null|[7B 22 69 64 22 3...|users| 1| 16|2025-02-06 11:09:...| 0| |null|[7B 22 69 64 22 3...|users| 1| 17|2025-02-06 11:10:...| 0| |null|[7B 22 69 64 22 3...|users| 1| 18|2025-02-06 11:21:...| 0| |null|[7B 22 69 64 22 3...|users| 1| 19|2025-02-06 11:22:...| 0| +----+--------------------+-----+---------+------+--------------------+-------------+ only showing top 20 rows
query.stop()
spark.stop()


import random import json from kafka import KafkaProducer import time import datetime; # Define the bootstrap servers and the topic name bootstrap_servers = "localhost:9092" topic = "events" # Create a Kafka producer with JSON value serializer producer = KafkaProducer(bootstrap_servers=bootstrap_servers) # Define a function to generate random event data def generate_event(): current_time = time.time() user_id = random.randint(1, 100) event_type = random.choice(["click", "view", "purchase", "like", "share"]) event_time = datetime.datetime.fromtimestamp(current_time- abs(random.normalvariate(0, 10))).strftime("%m/%d/%Y, %H:%M:%S") processing_time =datetime.datetime.fromtimestamp(current_time).strftime("%m/%d/%Y, %H:%M:%S") return {"user_id": user_id, "event_type": event_type, "event_time": event_time, "processing_time": processing_time} while True: event = generate_event() print(event) producer.send(topic, value=json.dumps(event).encode('utf-8')) time.sleep(50)
from delta import configure_spark_with_delta_pip from pyspark.sql import SparkSession from pyspark.sql.functions import col, from_json, window, count, to_timestamp from pyspark.sql.types import StructType, StructField, IntegerType, StringType builder = (SparkSession.builder .appName("apply-window-aggregations") .master("spark://ZZHPC:7077") .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")) spark = configure_spark_with_delta_pip(builder,['org.apache.spark:spark-sql-kafka-0-10_2.12:3.4.1']).getOrCreate() spark.sparkContext.setLogLevel("ERROR")
df = (spark.readStream .format("kafka") .option("kafka.bootstrap.servers", "localhost:9092") .option("subscribe", "events") .option("startingOffsets", "earliest") .load())
schema = StructType([ StructField('user_id', IntegerType(), True), StructField('event_type', StringType(), True), StructField('event_time', StringType(), True), StructField('processing_time', StringType(), True)]) df = df.withColumn('value', from_json(col('value').cast("STRING"), schema))
df = (df .select( col('value.user_id').alias('user_id'), col('value.event_type').alias('event_type'), col('value.event_time').alias('event_time'), col('value.processing_time').alias('processing_time')) .withColumn("event_time", to_timestamp(col("event_time"), "MM/dd/yyyy, HH:mm:ss" )) .withColumn("processing_time", to_timestamp(col("processing_time"), "MM/dd/yyyy, HH:mm:ss")))
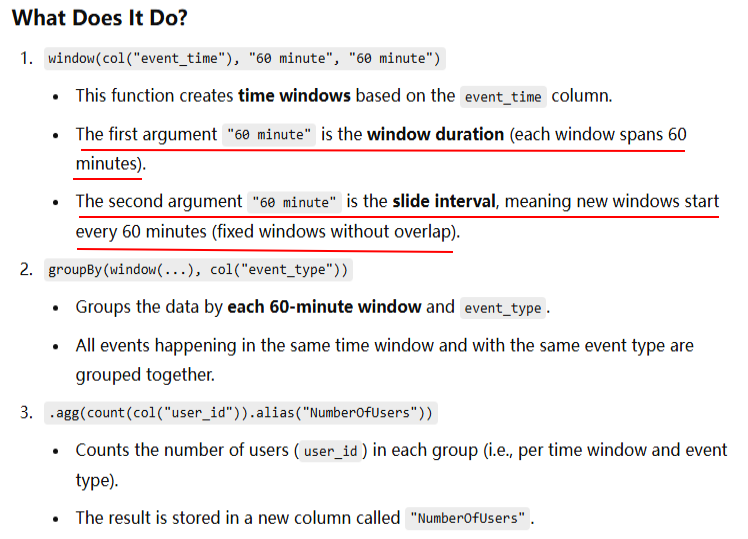
df = (df.groupBy( window(col("event_time"), "60 minute", "60 minute"), col("event_type")) .agg(count(col("user_id")).alias("NumberOfUsers")))
query = (df.writeStream .outputMode('complete') .format('console') .option("truncate", False) .start())
-------------------------------------------
Batch: 0
-------------------------------------------
+------------------------------------------+----------+-------------+
|window |event_type|NumberOfUsers|
+------------------------------------------+----------+-------------+
|{2025-02-06 16:00:00, 2025-02-06 17:00:00}|view |5 |
|{2025-02-06 16:00:00, 2025-02-06 17:00:00}|purchase |1 |
|{2025-02-06 16:00:00, 2025-02-06 17:00:00}|share |6 |
|{2025-02-06 16:00:00, 2025-02-06 17:00:00}|click |6 |
+------------------------------------------+----------+-------------+
-------------------------------------------
Batch: 1
-------------------------------------------
+------------------------------------------+----------+-------------+
|window |event_type|NumberOfUsers|
+------------------------------------------+----------+-------------+
|{2025-02-06 16:00:00, 2025-02-06 17:00:00}|view |5 |
|{2025-02-06 16:00:00, 2025-02-06 17:00:00}|like |1 |
|{2025-02-06 16:00:00, 2025-02-06 17:00:00}|purchase |1 |
|{2025-02-06 16:00:00, 2025-02-06 17:00:00}|share |6 |
|{2025-02-06 16:00:00, 2025-02-06 17:00:00}|click |6 |
+------------------------------------------+----------+-------------+
-------------------------------------------
Batch: 2
-------------------------------------------
+------------------------------------------+----------+-------------+
|window |event_type|NumberOfUsers|
+------------------------------------------+----------+-------------+
|{2025-02-06 16:00:00, 2025-02-06 17:00:00}|view |6 |
|{2025-02-06 16:00:00, 2025-02-06 17:00:00}|like |1 |
|{2025-02-06 16:00:00, 2025-02-06 17:00:00}|purchase |1 |
|{2025-02-06 16:00:00, 2025-02-06 17:00:00}|share |6 |
|{2025-02-06 16:00:00, 2025-02-06 17:00:00}|click |6 |
+------------------------------------------+----------+-------------+
query.stop()
# Update output mode query = (df.writeStream.outputMode("update") .format("console") .option("truncate", False) .start())
-------------------------------------------
Batch: 0
-------------------------------------------
+------------------------------------------+----------+-------------+
|window |event_type|NumberOfUsers|
+------------------------------------------+----------+-------------+
|{2025-02-06 16:00:00, 2025-02-06 17:00:00}|view |6 |
|{2025-02-06 16:00:00, 2025-02-06 17:00:00}|like |1 |
|{2025-02-06 16:00:00, 2025-02-06 17:00:00}|purchase |2 |
|{2025-02-06 16:00:00, 2025-02-06 17:00:00}|share |7 |
|{2025-02-06 16:00:00, 2025-02-06 17:00:00}|click |7 |
+------------------------------------------+----------+-------------+
-------------------------------------------
Batch: 1
-------------------------------------------
+------------------------------------------+----------+-------------+
|window |event_type|NumberOfUsers|
+------------------------------------------+----------+-------------+
|{2025-02-06 16:00:00, 2025-02-06 17:00:00}|share |8 |
+------------------------------------------+----------+-------------+
query.stop()
spark.stop()






from delta import configure_spark_with_delta_pip from pyspark.sql import SparkSession from pyspark.sql.functions import col, from_json, window, count, to_timestamp from pyspark.sql.types import StructType, StructField, IntegerType, StringType builder = (SparkSession.builder .appName("handle-late-and-out-of-order-data") .master("spark://ZZHPC:7077") .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")) spark = configure_spark_with_delta_pip(builder,['org.apache.spark:spark-sql-kafka-0-10_2.12:3.4.1']).getOrCreate() spark.sparkContext.setLogLevel("ERROR")
df = (spark.readStream .format("kafka") .option("kafka.bootstrap.servers", "localhost:9092") .option("subscribe", "events") .option("startingOffsets", "latest") .load())
schema = StructType([ StructField('user_id', IntegerType(), True), StructField('event_type', StringType(), True), StructField('event_time', StringType(), True), StructField('processing_time', StringType(), True)]) df = df.withColumn('value', from_json(col('value').cast("STRING"), schema))
df = (df.select( col('value.user_id').alias('user_id'), col('value.event_type').alias('event_type'), col('value.event_time').alias('event_time'), col('value.processing_time').alias('processing_time')) .withColumn("event_time", to_timestamp(col("event_time"), "MM/dd/yyyy, HH:mm:ss" )) .withColumn("processing_time", to_timestamp(col("processing_time"), "MM/dd/yyyy, HH:mm:ss")))

df = df.withWatermark("event_time", "10 seconds")

df = (df .groupBy(window(col("event_time"), "1 minute", "1 minute"), col("user_id")) .count().alias("NumberOfEvents"))

query = (df.writeStream .outputMode('update') .format('console') .option("truncate", False) .start())
-------------------------------------------
Batch: 0
-------------------------------------------
+------+-------+-----+
|window|user_id|count|
+------+-------+-----+
+------+-------+-----+
-------------------------------------------
Batch: 1
-------------------------------------------
+------------------------------------------+-------+-----+
|window |user_id|count|
+------------------------------------------+-------+-----+
|{2025-02-06 17:17:00, 2025-02-06 17:18:00}|97 |1 |
+------------------------------------------+-------+-----+
-------------------------------------------
Batch: 2
-------------------------------------------
+------+-------+-----+
|window|user_id|count|
+------+-------+-----+
+------+-------+-----+
-------------------------------------------
Batch: 3
-------------------------------------------
+------------------------------------------+-------+-----+
|window |user_id|count|
+------------------------------------------+-------+-----+
|{2025-02-06 17:17:00, 2025-02-06 17:18:00}|97 |2 |
+------------------------------------------+-------+-----+
-------------------------------------------
Batch: 4
-------------------------------------------
+------+-------+-----+
|window|user_id|count|
+------+-------+-----+
+------+-------+-----+
-------------------------------------------
Batch: 5
-------------------------------------------
+------------------------------------------+-------+-----+
|window |user_id|count|
+------------------------------------------+-------+-----+
|{2025-02-06 17:17:00, 2025-02-06 17:18:00}|63 |1 |
+------------------------------------------+-------+-----+
-------------------------------------------
Batch: 6
-------------------------------------------
+------+-------+-----+
|window|user_id|count|
+------+-------+-----+
+------+-------+-----+
-------------------------------------------
Batch: 7
-------------------------------------------
+------------------------------------------+-------+-----+
|window |user_id|count|
+------------------------------------------+-------+-----+
|{2025-02-06 17:18:00, 2025-02-06 17:19:00}|77 |1 |
+------------------------------------------+-------+-----+
-------------------------------------------
Batch: 8
-------------------------------------------
+------+-------+-----+
|window|user_id|count|
+------+-------+-----+
+------+-------+-----+
-------------------------------------------
Batch: 9
-------------------------------------------
+------------------------------------------+-------+-----+
|window |user_id|count|
+------------------------------------------+-------+-----+
|{2025-02-06 17:18:00, 2025-02-06 17:19:00}|90 |1 |
+------------------------------------------+-------+-----+
-------------------------------------------
Batch: 10
-------------------------------------------
+------+-------+-----+
|window|user_id|count|
+------+-------+-----+
+------+-------+-----+
query.stop()
spark.stop()




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律