

from delta import configure_spark_with_delta_pip, DeltaTable from pyspark.sql import SparkSession builder = (SparkSession.builder .appName("create-delta-table") .master("spark://ZZHPC:7077") .config("spark.executor.memory", "512m") .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")) spark = configure_spark_with_delta_pip(builder).getOrCreate() spark.sparkContext.setLogLevel("ERROR") get_ipython().run_line_magic('load_ext', 'sparksql_magic') get_ipython().run_line_magic('config', 'SparkSql.limit=20')
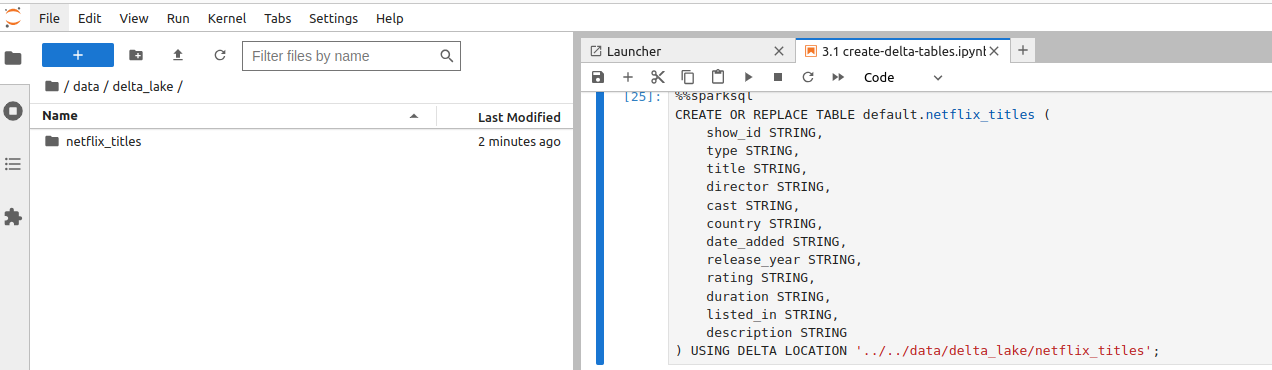
%%sparksql CREATE OR REPLACE TABLE default.netflix_titles ( show_id STRING, type STRING, title STRING, director STRING, cast STRING, country STRING, date_added STRING, release_year STRING, rating STRING, duration STRING, listed_in STRING, description STRING ) USING DELTA LOCATION '../data/delta_lake/netflix_titles';
This statement created the directory 'Chapter03/data/delta_lake/netflix_titles' instead of the expected location 'data/delta_lake/netflix_titles'.
Used absolute path for the location:
%%sparksql CREATE OR REPLACE TABLE default.netflix_titles ( show_id STRING, type STRING, title STRING, director STRING, cast STRING, country STRING, date_added STRING, release_year STRING, rating STRING, duration STRING, listed_in STRING, description STRING ) USING DELTA LOCATION '~/zd/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles';
This time, the directory was created under 'Chapter03/spark-warehouse':
zzh@ZZHPC:~/zd/Github/Data-Engineering-with-Databricks-Cookbook-main/data$ find ./ -type d -name netflix_titles zzh@ZZHPC:~/zd/Github/Data-Engineering-with-Databricks-Cookbook-main/data$ cd .. zzh@ZZHPC:~/zd/Github/Data-Engineering-with-Databricks-Cookbook-main$ find ./ -type d -name netflix_titles ./Chapter03/spark-warehouse/~/zd/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles
So I know the base of the relative path for the write operation is in the 'spark-warehouse' directory whose location is the same with the .ipynb file.
%%sparksql CREATE OR REPLACE TABLE default.netflix_titles ( show_id STRING, type STRING, title STRING, director STRING, cast STRING, country STRING, date_added STRING, release_year STRING, rating STRING, duration STRING, listed_in STRING, description STRING ) USING DELTA LOCATION '../../data/delta_lake/netflix_titles';
This time the target directory was created as expected.
Read your data:
df = (spark.read .format("csv") .option("header", "true") .load("../data/netflix_titles.csv"))
For the read operation, the base of the relative path is the directory where the .ipynb file is in.
Write the data to Delta Lake:
df.write.format("delta").mode("overwrite").saveAsTable("default.netflix_titles")

Query the Delta table:
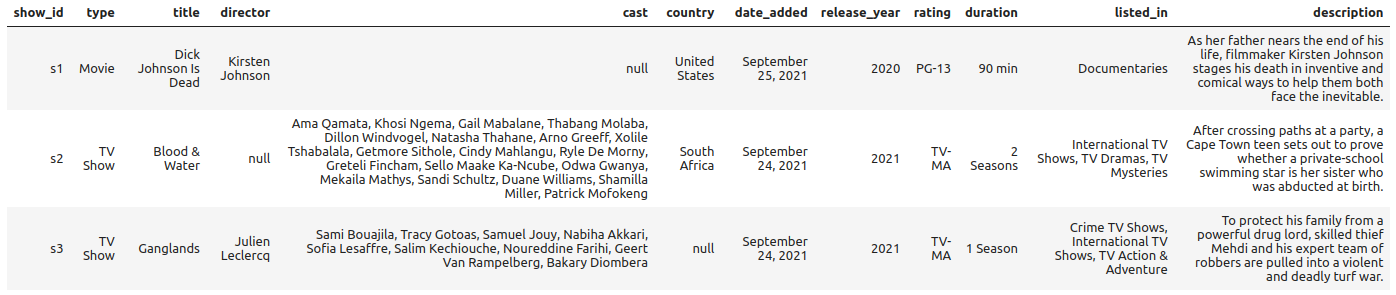
%%sparksql SELECT * FROM default.netflix_titles LIMIT 3;



from delta import configure_spark_with_delta_pip, DeltaTable from pyspark.sql import SparkSession builder = (SparkSession.builder .appName("read-delta-table") .master("spark://ZZHPC:7077") .config("spark.executor.memory", "512m") .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog"))
Ivy Default Cache set to: /home/zzh/.ivy2/cache The jars for the packages stored in: /home/zzh/.ivy2/jars io.delta#delta-core_2.12 added as a dependency :: resolving dependencies :: org.apache.spark#spark-submit-parent-50abd92f-2c69-46f4-b5da-18ff6217d96a;1.0 confs: [default] found io.delta#delta-core_2.12;2.4.0 in central found io.delta#delta-storage;2.4.0 in central found org.antlr#antlr4-runtime;4.9.3 in central :: resolution report :: resolve 148ms :: artifacts dl 8ms :: modules in use: io.delta#delta-core_2.12;2.4.0 from central in [default] io.delta#delta-storage;2.4.0 from central in [default] org.antlr#antlr4-runtime;4.9.3 from central in [default] --------------------------------------------------------------------- | | modules || artifacts | | conf | number| search|dwnlded|evicted|| number|dwnlded| --------------------------------------------------------------------- | default | 3 | 0 | 0 | 0 || 3 | 0 | --------------------------------------------------------------------- :: retrieving :: org.apache.spark#spark-submit-parent-50abd92f-2c69-46f4-b5da-18ff6217d96a confs: [default] 0 artifacts copied, 3 already retrieved (0kB/8ms) 25/02/04 10:37:15 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
spark = configure_spark_with_delta_pip(builder).getOrCreate() spark.sparkContext.setLogLevel("ERROR") get_ipython().run_line_magic('load_ext', 'sparksql_magic') get_ipython().run_line_magic('config', 'SparkSql.limit=20')
df = spark.read.format("delta").load("../data/delta_lake/netflix_titles") df.show(3)
+-------+-------+--------------------+---------------+--------------------+-------------+------------------+------------+------+---------+--------------------+--------------------+ |show_id| type| title| director| cast| country| date_added|release_year|rating| duration| listed_in| description| +-------+-------+--------------------+---------------+--------------------+-------------+------------------+------------+------+---------+--------------------+--------------------+ | s1| Movie|Dick Johnson Is Dead|Kirsten Johnson| null|United States|September 25, 2021| 2020| PG-13| 90 min| Documentaries|As her father nea...| | s2|TV Show| Blood & Water| null|Ama Qamata, Khosi...| South Africa|September 24, 2021| 2021| TV-MA|2 Seasons|International TV ...|After crossing pa...| | s3|TV Show| Ganglands|Julien Leclercq|Sami Bouajila, Tr...| null|September 24, 2021| 2021| TV-MA| 1 Season|Crime TV Shows, I...|To protect his fa...| +-------+-------+--------------------+---------------+--------------------+-------------+------------------+------------+------+---------+--------------------+--------------------+ only showing top 3 rows
%%sparksql SELECT * FROM delta.`../data/delta_lake/netflix_titles` LIMIT 3;
---------------------------------------------------------------------------
AnalysisException Traceback (most recent call last)
Cell In[6], line 1
----> 1 get_ipython().run_cell_magic('sparksql', '', 'SELECT * FROM delta.`../data/delta_lake/netflix_titles` LIMIT 3;\n')
File ~/venvs/zpy311/lib/python3.11/site-packages/IPython/core/interactiveshell.py:2543, in InteractiveShell.run_cell_magic(self, magic_name, line, cell)
2541 with self.builtin_trap:
2542 args = (magic_arg_s, cell)
-> 2543 result = fn(*args, **kwargs)
2545 # The code below prevents the output from being displayed
2546 # when using magics with decorator @output_can_be_silenced
2547 # when the last Python token in the expression is a ';'.
2548 if getattr(fn, magic.MAGIC_OUTPUT_CAN_BE_SILENCED, False):
File ~/venvs/zpy311/lib/python3.11/site-packages/sparksql_magic/sparksql.py:40, in SparkSql.sparksql(self, line, cell, local_ns)
37 print("active spark session is not found")
38 return
---> 40 df = spark.sql(bind_variables(cell, user_ns))
41 if args.cache or args.eager:
42 print('cache dataframe with %s load' % ('eager' if args.eager else 'lazy'))
File ~/venvs/zpy311/lib/python3.11/site-packages/pyspark/sql/session.py:1440, in SparkSession.sql(self, sqlQuery, args, **kwargs)
1438 try:
1439 litArgs = {k: _to_java_column(lit(v)) for k, v in (args or {}).items()}
-> 1440 return DataFrame(self._jsparkSession.sql(sqlQuery, litArgs), self)
1441 finally:
1442 if len(kwargs) > 0:
File ~/venvs/zpy311/lib/python3.11/site-packages/py4j/java_gateway.py:1322, in JavaMember.__call__(self, *args)
1316 command = proto.CALL_COMMAND_NAME +\
1317 self.command_header +\
1318 args_command +\
1319 proto.END_COMMAND_PART
1321 answer = self.gateway_client.send_command(command)
-> 1322 return_value = get_return_value(
1323 answer, self.gateway_client, self.target_id, self.name)
1325 for temp_arg in temp_args:
1326 if hasattr(temp_arg, "_detach"):
File ~/venvs/zpy311/lib/python3.11/site-packages/pyspark/errors/exceptions/captured.py:175, in capture_sql_exception.<locals>.deco(*a, **kw)
171 converted = convert_exception(e.java_exception)
172 if not isinstance(converted, UnknownException):
173 # Hide where the exception came from that shows a non-Pythonic
174 # JVM exception message.
--> 175 raise converted from None
176 else:
177 raise
AnalysisException: Unsupported data source type for direct query on files: delta.; line 1 pos 14
Changed the files location:
%%sparksql SELECT * FROM delta.`../../data/delta_lake/netflix_titles` LIMIT 3;
Still got the same error.
Changed the files location again:
%%sparksql SELECT * FROM delta.`data/delta_lake/netflix_titles` LIMIT 3;
Still got the same error.
Changed the files location to absolute path:
%%sparksql SELECT * FROM delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles` LIMIT 3;
It succeeded:
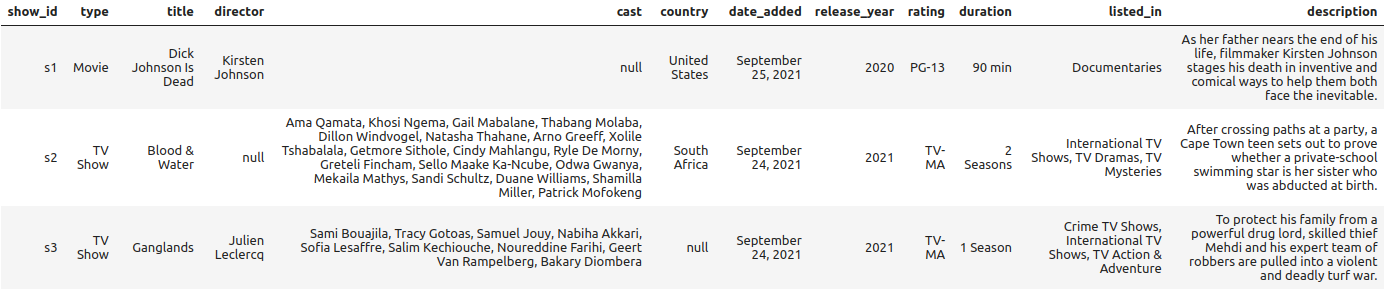

%%sparksql DESCRIBE HISTORY '/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles'


%%sparksql ALTER TABLE delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles` SET TBLPROPERTIES ( delta.logRetentionDuration = 'interval 60 days', delta.deletedFileRetentionDuration = 'interval 14 days' );

from delta import configure_spark_with_delta_pip, DeltaTable from pyspark.sql import SparkSession from pyspark.sql.functions import expr, lit builder = (SparkSession.builder .appName("upsert-delta-table") .master("spark://ZZHPC:7077") .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") .config("spark.sql.catalogImplementation", "in-memory")) spark = configure_spark_with_delta_pip(builder).getOrCreate() spark.sparkContext.setLogLevel("ERROR")
%load_ext sparksql_magic %config SparkSql.limit=20
# For PySpark: deltaTable = DeltaTable.forPath(spark, "/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles")
deltaTable.toDF().show(3)
+-------+-------+--------------------+---------------+--------------------+-------------+------------------+------------+------+---------+--------------------+--------------------+ |show_id| type| title| director| cast| country| date_added|release_year|rating| duration| listed_in| description| +-------+-------+--------------------+---------------+--------------------+-------------+------------------+------------+------+---------+--------------------+--------------------+ | s1| Movie|Dick Johnson Is Dead|Kirsten Johnson| null|United States|September 25, 2021| 2020| PG-13| 90 min| Documentaries|As her father nea...| | s2|TV Show| Blood & Water| null|Ama Qamata, Khosi...| South Africa|September 24, 2021| 2021| TV-MA|2 Seasons|International TV ...|After crossing pa...| | s3|TV Show| Ganglands|Julien Leclercq|Sami Bouajila, Tr...| null|September 24, 2021| 2021| TV-MA| 1 Season|Crime TV Shows, I...|To protect his fa...| +-------+-------+--------------------+---------------+--------------------+-------------+------------------+------------+------+---------+--------------------+--------------------+ only showing top 3 rows
# Update director to not have nulls deltaTable.update( condition = expr("director IS NULL"), set = { "director": lit("") }) deltaTable.toDF().show(3)
+-------+-------+--------------------+---------------+--------------------+-------------+------------------+------------+------+---------+--------------------+--------------------+ |show_id| type| title| director| cast| country| date_added|release_year|rating| duration| listed_in| description| +-------+-------+--------------------+---------------+--------------------+-------------+------------------+------------+------+---------+--------------------+--------------------+ | s1| Movie|Dick Johnson Is Dead|Kirsten Johnson| null|United States|September 25, 2021| 2020| PG-13| 90 min| Documentaries|As her father nea...| | s2|TV Show| Blood & Water| |Ama Qamata, Khosi...| South Africa|September 24, 2021| 2021| TV-MA|2 Seasons|International TV ...|After crossing pa...| | s3|TV Show| Ganglands|Julien Leclercq|Sami Bouajila, Tr...| null|September 24, 2021| 2021| TV-MA| 1 Season|Crime TV Shows, I...|To protect his fa...| +-------+-------+--------------------+---------------+--------------------+-------------+------------------+------------+------+---------+--------------------+--------------------+ only showing top 3 rows
%%sparksql UPDATE delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles` SET director = "" WHERE director IS NULL;

from delta import configure_spark_with_delta_pip, DeltaTable from pyspark.sql import SparkSession builder = (SparkSession.builder .appName("merge-delta-table") .master("spark://ZZHPC:7077") .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")) spark = configure_spark_with_delta_pip(builder).getOrCreate() spark.sparkContext.setLogLevel("ERROR")
%load_ext sparksql_magic %config SparkSql.limit=20
%%sparksql CREATE OR REPLACE TABLE default.movie_and_show_titles ( show_id STRING, type STRING, title STRING, director STRING, cast STRING, country STRING, date_added STRING, release_year STRING, rating STRING, duration STRING, listed_in STRING, description STRING ) USING DELTA LOCATION '/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/movie_and_show_titles';
deltaTable_titles = DeltaTable.forPath(spark, "/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/movie_and_show_titles")
deltaTable_titles.toDF().show(5)
+-------+----+-----+--------+----+-------+----------+------------+------+--------+---------+-----------+ |show_id|type|title|director|cast|country|date_added|release_year|rating|duration|listed_in|description| +-------+----+-----+--------+----+-------+----------+------------+------+--------+---------+-----------+ +-------+----+-----+--------+----+-------+----------+------------+------+--------+---------+-----------+

df_netflix = spark.read.format("delta").load("/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles") df_netflix_deduped = df_netflix.dropDuplicates(["type", "title", "director", "date_added"])
(deltaTable_titles.alias('movie_and_show_titles') .merge(df_netflix_deduped.alias('updates'), """lower(movie_and_show_titles.type) = lower(updates.type) AND lower(movie_and_show_titles.title) = lower(updates.title) AND lower(movie_and_show_titles.director) = lower(updates.director) AND movie_and_show_titles.date_added = updates.date_added""") .whenMatchedUpdate(set = { "show_id": "updates.show_id", "type": "updates.type", "title" : "updates.title", "director" : "updates.director", "cast" : "updates.cast", "country" : "updates.country", "date_added" : "updates.date_added", "release_year" : "updates.release_year", "rating" : "updates.rating", "duration" : "updates.duration", "listed_in" : "updates.listed_in", "description" : "updates.description"}) .whenNotMatchedInsert(values = { "show_id": "updates.show_id", "type": "updates.type", "title" : "updates.title", "director" : "updates.director", "cast" : "updates.cast", "country" : "updates.country", "date_added" : "updates.date_added", "release_year" : "updates.release_year", "rating" : "updates.rating", "duration" : "updates.duration", "listed_in" : "updates.listed_in", "description" : "updates.description"}) .execute())
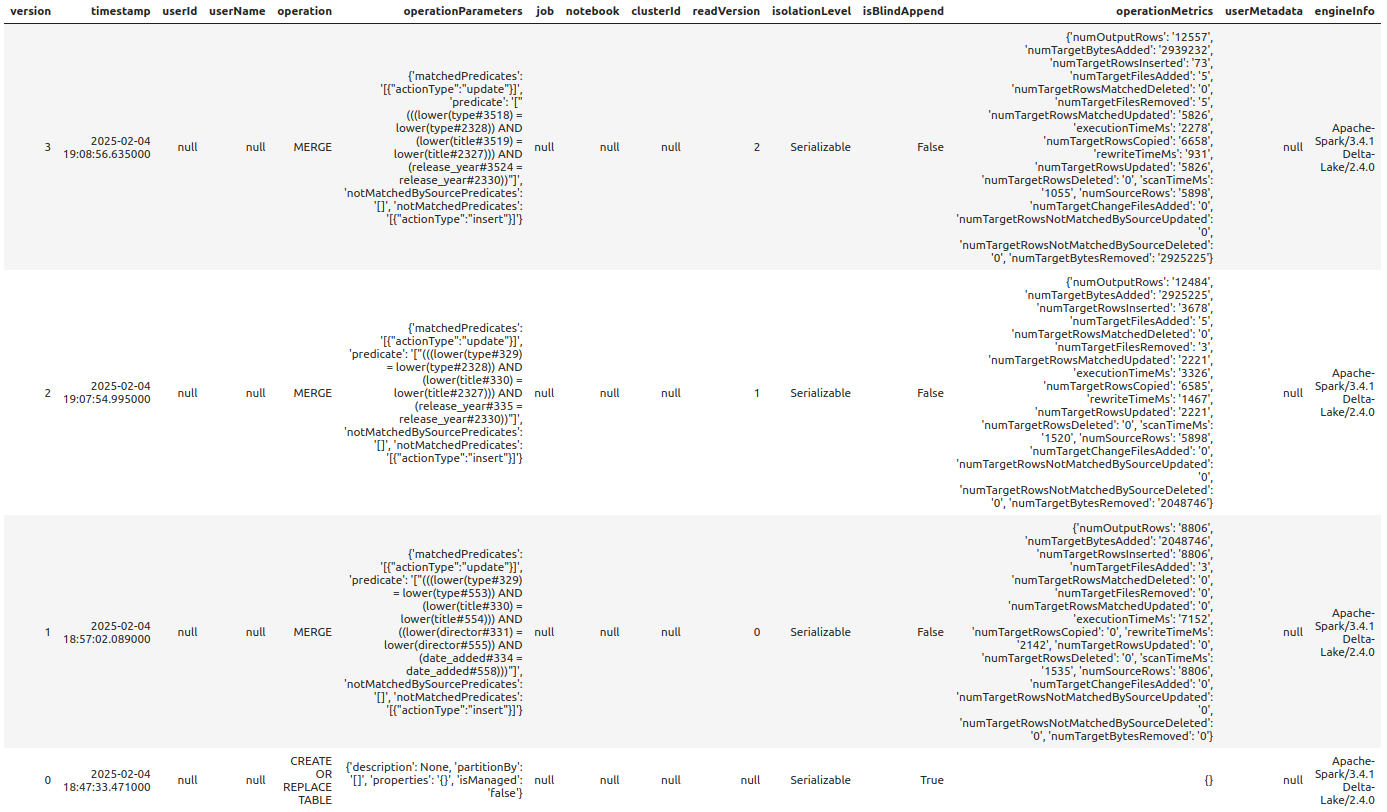
%%sparksql DESCRIBE HISTORY "/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/movie_and_show_titles"

df_titles = (spark.read.format("csv") .option("header", "true") .load("../data/titles.csv"))
df_titles_deduped = df_titles.dropDuplicates(["type", "title"])
df_titles_deduped.createOrReplaceTempView("titles_deduped")
The createOrReplaceTempView() function in PySpark is used to create a temporary view of a DataFrame, which can then be queried using SQL syntax. It essentially registers the DataFrame as a temporary table in the Spark session, allowing you to run SQL queries against it.
(deltaTable_titles.alias('movie_and_show_titles') .merge(df_titles_deduped.alias('updates'), """lower(movie_and_show_titles.type) = lower(updates.type) AND lower(movie_and_show_titles.title) = lower(updates.title) AND movie_and_show_titles.release_year = updates.release_year""") .whenMatchedUpdate(set ={ "show_id" : "updates.id", "type" : "updates.type", "title" : "updates.title", "country" : "updates.production_countries", "release_year" : "updates.release_year", "rating" : "updates.age_certification", "duration" : "updates.runtime", "listed_in" : "updates.genres", "description" : "updates.description"}) .whenNotMatchedInsert(values = { "show_id" : "updates.id", "type" : "updates.type", "title" : "updates.title", "country" : "updates.production_countries", "release_year" : "updates.release_year", "rating" : "updates.age_certification", "duration" : "updates.runtime", "listed_in" : "updates.genres", "description" : "updates.description"}) .execute())
%%sparksql MERGE INTO default.movie_and_show_titles USING titles_deduped ON lower(default.movie_and_show_titles.type) = lower(titles_deduped.type) AND lower(default.movie_and_show_titles.title) = lower(titles_deduped.title) AND default.movie_and_show_titles.release_year = titles_deduped.release_year WHEN MATCHED THEN UPDATE SET show_id = titles_deduped.id, type = titles_deduped.type, title = titles_deduped.title, country = titles_deduped.production_countries, release_year = titles_deduped.release_year, rating = titles_deduped.age_certification, duration = titles_deduped.runtime, listed_in = titles_deduped.genres, description = titles_deduped.description WHEN NOT MATCHED THEN
INSERT ( show_id, type, title, country, release_year, rating, duration, listed_in, description ) VALUES ( titles_deduped.id, titles_deduped.type, titles_deduped.title, titles_deduped.production_countries, titles_deduped.release_year, titles_deduped.age_certification, titles_deduped.runtime, titles_deduped.genres, titles_deduped.description )

%%sparksql DESCRIBE HISTORY "/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/movie_and_show_titles"

from delta import configure_spark_with_delta_pip, DeltaTable from pyspark.sql import SparkSession builder = (SparkSession.builder .appName("change-data-feed-delta-table") .master("spark://ZZHPC:7077") .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")) spark = configure_spark_with_delta_pip(builder).getOrCreate() spark.sparkContext.setLogLevel("ERROR")
%load_ext sparksql_magic %config SparkSql.limit=20
3.

Create Bronze Table
(as an appendOnly table)
%%sparksql CREATE OR REPLACE TABLE default.movie_and_show_titles_cdf ( show_id STRING, type STRING, title STRING, director STRING, cast STRING, country STRING, date_added STRING, release_year STRING, rating STRING, duration STRING, listed_in STRING, description STRING ) USING DELTA LOCATION '/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/movie_and_show_titles_cdf' TBLPROPERTIES (delta.enableChangeDataFeed = true, medallionLevel = 'bronze');

4. Write data into the bronze table:
df = (spark.read.format("csv") .option("header", "true") .load("../data/netflix_titles.csv")); df.write.format("delta").mode("append").saveAsTable("default.movie_and_show_titles_cdf")
5.

%%sparksql CREATE OR REPLACE TABLE default.movie_and_show_titles_cleansed ( show_id STRING, type STRING, title STRING, director STRING, cast STRING, country STRING, date_added STRING, release_year STRING, rating STRING, duration STRING, listed_in STRING, description STRING ) USING DELTA LOCATION '/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/movie_and_show_titles_cleansed' TBLPROPERTIES (delta.enableChangeDataFeed = true, medallionLevel = 'silver', updatedFromTable= 'default.movie_and_show_titles_cdf', updatedFromTableVersion= '-1');
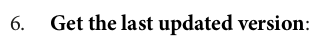
lastUpdateVersion = int(spark.sql("SHOW TBLPROPERTIES default.movie_and_show_titles_cleansed ('updatedFromTableVersion')").first()["value"])+1 lastUpdateVersion # 0

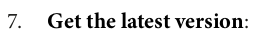
latestVersion = spark.sql("DESCRIBE HISTORY default.movie_and_show_titles_cdf").first()["version"] latestVersion # 1
8.

%%sparksql CREATE OR REPLACE TEMPORARY VIEW bronzeTable_latest_version as SELECT * FROM ( SELECT *, RANK() OVER (PARTITION BY (lower(type), lower(title), lower(director), date_added) ORDER BY _commit_version DESC) as rank FROM table_changes('default.movie_and_show_titles_cdf', {lastUpdateVersion}, {latestVersion}) WHERE type IS NOT NULL AND title IS NOT NULL AND director IS NOT NULL AND _change_type != 'update_preimage' ) WHERE rank = 1;
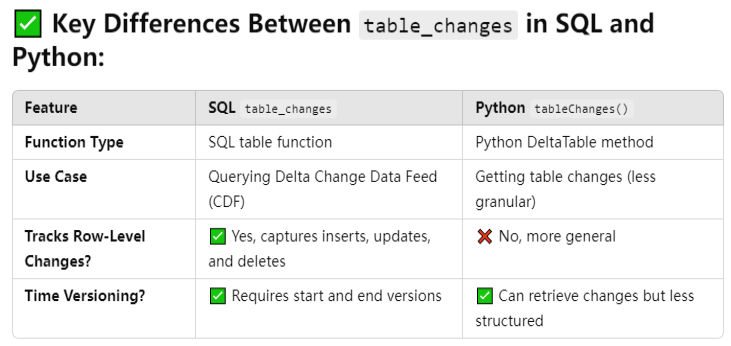
The table_changes function in SQL is used to retrieve row-level changes from a Delta table between two specific versions. It is part of Delta Change Data Feed (CDF), which allows users to track inserts, updates, and deletes over time.
SELECT * FROM table_changes('<schema>.<table_name>', startVersion, endVersion)


9.

%%sparksql MERGE INTO default.movie_and_show_titles_cleansed t USING bronzeTable_latest_version s ON lower(t.type) = lower(s.type) AND lower(t.title) = lower(s.title) AND lower(t.director) = lower(s.director) AND t.date_added = s.date_added WHEN MATCHED AND s._change_type='update_postimage' OR s._change_type='update_preimage' THEN UPDATE SET * WHEN MATCHED AND s._change_type='delete' THEN DELETE WHEN NOT MATCHED AND s._change_type='insert' THEN INSERT *

10.
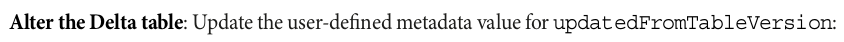
%%sparksql ALTER TABLE default.movie_and_show_titles_cleansed SET TBLPROPERTIES(updatedFromTableVersion = {latestVersion});
11.

%%sparksql DROP VIEW bronzeTable_latest_version
12.
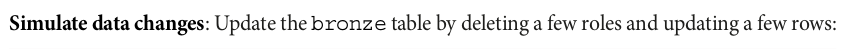
%%sparksql DELETE FROM default.movie_and_show_titles_cdf WHERE country is NULL

%%sparksql UPDATE default.movie_and_show_titles_cdf SET director = '' WHERE director is NULL

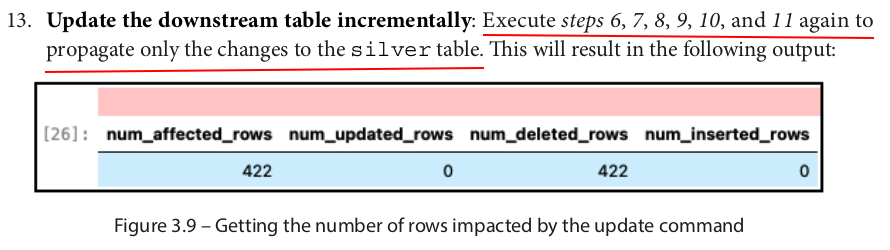
6.
#get the value of the last Updated Version from the silver table lastUpdateVersion = int(spark.sql("SHOW TBLPROPERTIES default.movie_and_show_titles_cleansed ('updatedFromTableVersion')").first()["value"])+1 lastUpdateVersion # 2
7.
#get the value of the last Updated Version from the bronze table latestVersion = spark.sql("DESCRIBE HISTORY default.movie_and_show_titles_cdf").first()["version"] latestVersion # 3
8.
%%sparksql CREATE OR REPLACE TEMPORARY VIEW bronzeTable_latest_version as SELECT * FROM ( SELECT *, RANK() OVER (PARTITION BY (lower(type), lower(title), lower(director), date_added) ORDER BY _commit_version DESC) as rank FROM table_changes('default.movie_and_show_titles_cdf', {lastUpdateVersion}, {latestVersion}) WHERE type IS NOT NULL AND title IS NOT NULL AND director IS NOT NULL AND _change_type != 'update_preimage' ) WHERE rank = 1;
9.
%%sparksql MERGE INTO default.movie_and_show_titles_cleansed t USING bronzeTable_latest_version s ON lower(t.type) = lower(s.type) AND lower(t.title) = lower(s.title) AND lower(t.director) = lower(s.director) AND t.date_added = s.date_added WHEN MATCHED AND s._change_type='update_postimage' OR s._change_type='update_preimage' THEN UPDATE SET * WHEN MATCHED AND s._change_type='delete' THEN DELETE WHEN NOT MATCHED AND s._change_type='insert' THEN INSERT *

10.
%%sparksql ALTER TABLE default.movie_and_show_titles_cleansed SET TBLPROPERTIES(updatedFromTableVersion = {latestVersion});
11.
%%sparksql DROP VIEW bronzeTable_latest_version


from delta import configure_spark_with_delta_pip, DeltaTable from pyspark.sql import SparkSession builder = (SparkSession.builder .appName("optimize-delta-table") .master("spark://ZZHPC:7077") .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")) spark = configure_spark_with_delta_pip(builder).getOrCreate() spark.sparkContext.setLogLevel("ERROR")
%load_ext sparksql_magic %config SparkSql.limit=20
df = spark.read.format("delta").load("/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles")
%%sparksql DESCRIBE HISTORY "/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles"


Optimize performance with file management - Compaction (bin-packing)
deltaTable = DeltaTable.forPath(spark, "/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles") # For Hive metastore-based tables: deltaTable = DeltaTable.forName(spark, tableName) deltaTable.optimize().executeCompaction()
DataFrame[path: string, metrics: struct<numFilesAdded:bigint,numFilesRemoved:bigint,filesAdded:struct<min:bigint,max:bigint,avg:double,totalFiles:bigint,totalSize:bigint>,filesRemoved:struct<min:bigint,max:bigint,avg:double,totalFiles:bigint,totalSize:bigint>,partitionsOptimized:bigint,zOrderStats:struct<strategyName:string,inputCubeFiles:struct<num:bigint,size:bigint>,inputOtherFiles:struct<num:bigint,size:bigint>,inputNumCubes:bigint,mergedFiles:struct<num:bigint,size:bigint>,numOutputCubes:bigint,mergedNumCubes:bigint>,numBatches:bigint,totalConsideredFiles:bigint,totalFilesSkipped:bigint,preserveInsertionOrder:boolean,numFilesSkippedToReduceWriteAmplification:bigint,numBytesSkippedToReduceWriteAmplification:bigint,startTimeMs:bigint,endTimeMs:bigint,totalClusterParallelism:bigint,totalScheduledTasks:bigint,autoCompactParallelismStats:struct<maxClusterActiveParallelism:bigint,minClusterActiveParallelism:bigint,maxSessionActiveParallelism:bigint,minSessionActiveParallelism:bigint>,deletionVectorStats:struct<numDeletionVectorsRemoved:bigint,numDeletionVectorRowsRemoved:bigint>,numTableColumns:bigint,numTableColumnsWithStats:bigint>]

%%sparksql -- Optimizes the path-based Delta Lake table OPTIMIZE "/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles"



Data skipping - Z-Ordering (multi-dimensional clustering)
deltaTable = DeltaTable.forPath(spark, "/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles") # path-based table # For Hive metastore-based tables: deltaTable = DeltaTable.forName(spark, tableName) deltaTable.optimize().executeZOrderBy("country")
DataFrame[path: string, metrics: struct<numFilesAdded:bigint,numFilesRemoved:bigint,filesAdded:struct<min:bigint,max:bigint,avg:double,totalFiles:bigint,totalSize:bigint>,filesRemoved:struct<min:bigint,max:bigint,avg:double,totalFiles:bigint,totalSize:bigint>,partitionsOptimized:bigint,zOrderStats:struct<strategyName:string,inputCubeFiles:struct<num:bigint,size:bigint>,inputOtherFiles:struct<num:bigint,size:bigint>,inputNumCubes:bigint,mergedFiles:struct<num:bigint,size:bigint>,numOutputCubes:bigint,mergedNumCubes:bigint>,numBatches:bigint,totalConsideredFiles:bigint,totalFilesSkipped:bigint,preserveInsertionOrder:boolean,numFilesSkippedToReduceWriteAmplification:bigint,numBytesSkippedToReduceWriteAmplification:bigint,startTimeMs:bigint,endTimeMs:bigint,totalClusterParallelism:bigint,totalScheduledTasks:bigint,autoCompactParallelismStats:struct<maxClusterActiveParallelism:bigint,minClusterActiveParallelism:bigint,maxSessionActiveParallelism:bigint,minSessionActiveParallelism:bigint>,deletionVectorStats:struct<numDeletionVectorsRemoved:bigint,numDeletionVectorRowsRemoved:bigint>,numTableColumns:bigint,numTableColumnsWithStats:bigint>]

%%sparksql OPTIMIZE "/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles" ZORDER BY (country)


%%sparksql DESCRIBE HISTORY "/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles"
Partitioning
df = (spark.read.format("json") .option("multiLine", "true") .load("../data/nobel_prizes.json"))
df.printSchema()
root |-- category: string (nullable = true) |-- laureates: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- firstname: string (nullable = true) | | |-- id: string (nullable = true) | | |-- motivation: string (nullable = true) | | |-- share: string (nullable = true) | | |-- surname: string (nullable = true) |-- overallMotivation: string (nullable = true) |-- year: string (nullable = true)
# Write the data to a Delta Lake table with partitioning (df.write.format("delta") .mode("overwrite") .partitionBy("year") .save("/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/nobel_prizes"))
# Query the partitioned table df = spark.read.format("delta").load("/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/nobel_prizes") df.show(10, truncate=60)
+----------+------------------------------------------------------------+------------------------------------------------------------+----+
| category| laureates| overallMotivation|year|
+----------+------------------------------------------------------------+------------------------------------------------------------+----+
| chemistry|[{Paul J., 281, "for their work in atmospheric chemistry,...| null|1995|
| economics|[{Robert E., 714, "for having developed and applied the h...| null|1995|
|literature|[{Seamus, 672, "for works of lyrical beauty and ethical d...| null|1995|
| peace|[{Joseph, 560, "for their efforts to diminish the part pl...| null|1995|
| physics|[{Martin L., 147, "for the discovery of the tau lepton", ...|"for pioneering experimental contributions to lepton phys...|1995|
| medicine|[{Edward B., 452, "for their discoveries concerning the g...| null|1995|
| chemistry|[{Otto, 169, "in recognition of his services to organic c...| null|1910|
|literature|[{Paul, 580, "as a tribute to the consummate artistry, pe...| null|1910|
| peace|[{Permanent International Peace Bureau, 477, "for acting ...| null|1910|
| physics|[{Johannes Diderik, 15, "for his work on the equation of ...| null|1910|
+----------+------------------------------------------------------------+------------------------------------------------------------+----+
only showing top 10 rows

from delta import configure_spark_with_delta_pip, DeltaTable from pyspark.sql import SparkSession builder = (SparkSession.builder .appName("time-travel-delta-table") .master("spark://ZZHPC:7077") .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")) spark = configure_spark_with_delta_pip(builder).getOrCreate() spark.sparkContext.setLogLevel("ERROR")
%load_ext sparksql_magic %config SparkSql.limit=20
%%sparksql DESCRIBE DETAIL delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles`

df = spark.read.format("delta").option("versionAsOf", 1).load("/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles") df.show(5, truncate=15)
+-------+-------+---------------+---------------+---------------+-------------+---------------+------------+------+---------+---------------+---------------+ |show_id| type| title| director| cast| country| date_added|release_year|rating| duration| listed_in| description| +-------+-------+---------------+---------------+---------------+-------------+---------------+------------+------+---------+---------------+---------------+ | s1| Movie|Dick Johnson...|Kirsten Johnson| null|United States|September 25...| 2020| PG-13| 90 min| Documentaries|As her fathe...| | s2|TV Show| Blood & Water| null|Ama Qamata, ...| South Africa|September 24...| 2021| TV-MA|2 Seasons|Internationa...|After crossi...| | s3|TV Show| Ganglands|Julien Leclercq|Sami Bouajil...| null|September 24...| 2021| TV-MA| 1 Season|Crime TV Sho...|To protect h...| | s4|TV Show|Jailbirds Ne...| null| null| null|September 24...| 2021| TV-MA| 1 Season|Docuseries, ...|Feuds, flirt...| | s5|TV Show| Kota Factory| null|Mayur More, ...| India|September 24...| 2021| TV-MA|2 Seasons|Internationa...|In a city of...| +-------+-------+---------------+---------------+---------------+-------------+---------------+------------+------+---------+---------------+---------------+ only showing top 5 rows
Alternatively, you could do this in SQL:
%%sparksql SELECT * FROM delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles` VERSION AS OF 1 LIMIT 5;

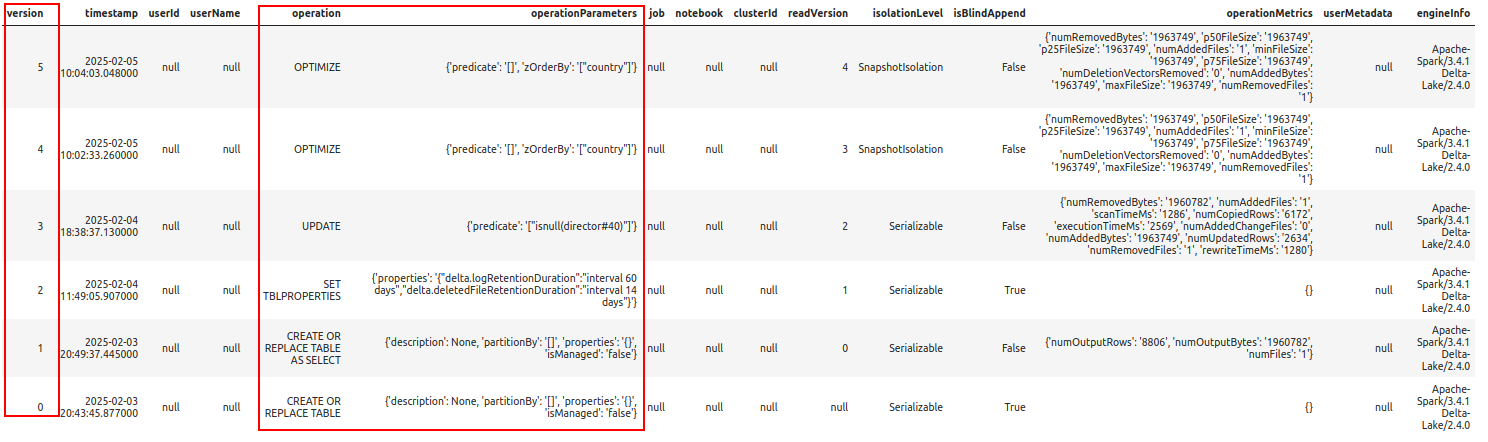
%%sparksql DESCRIBE HISTORY delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles`;
deltaTable = DeltaTable.forPath(spark, "/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles") # path-based tables, or deltaTable.restoreToVersion(3)
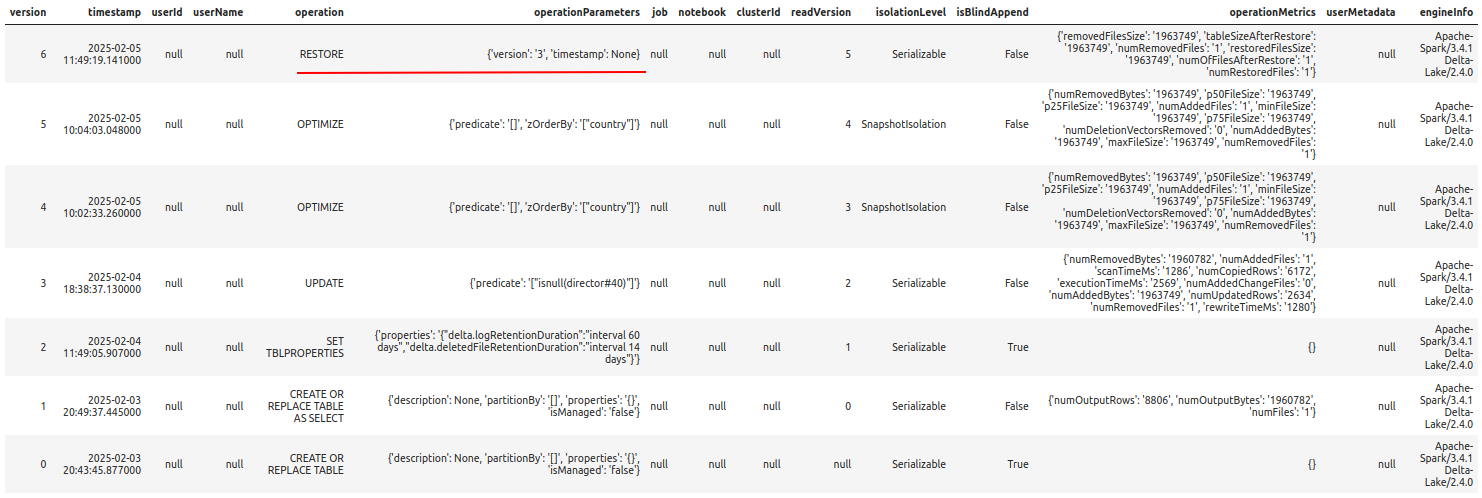
Alternatively, you could do this in SQL:
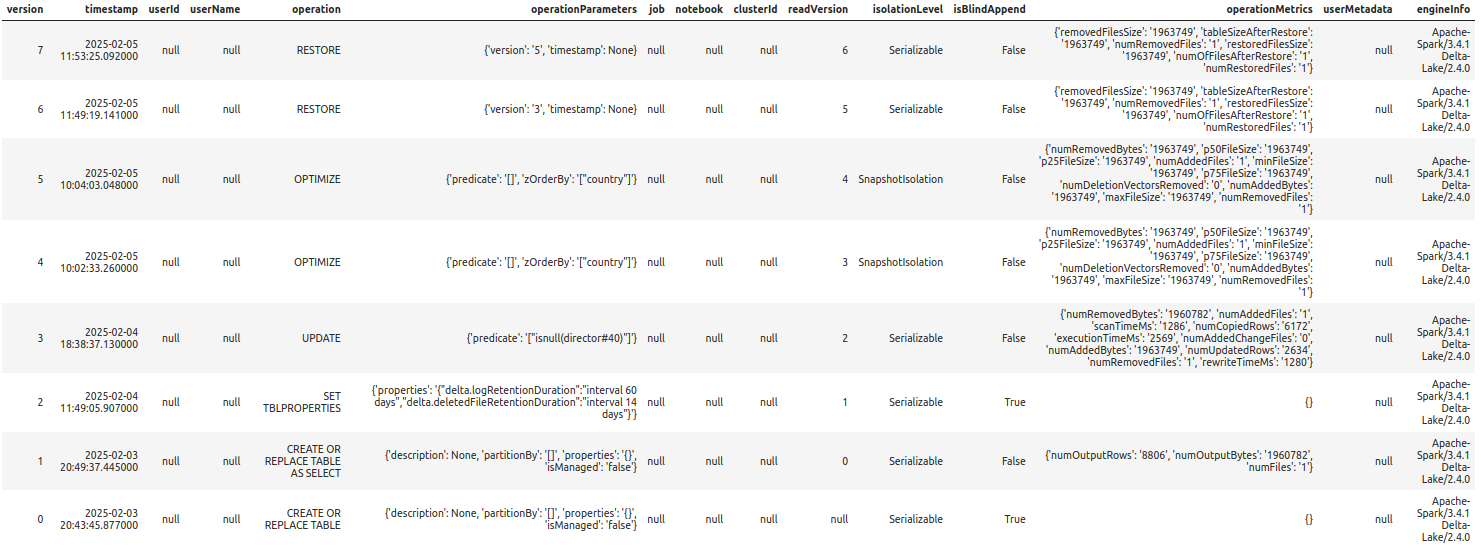
%%sparksql RESTORE TABLE delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles` TO VERSION AS OF 5;

%%sparksql DESCRIBE HISTORY "/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles"


from delta import configure_spark_with_delta_pip, DeltaTable from pyspark.sql import SparkSession builder = (SparkSession.builder .appName("manage-delta-table") .master("spark://ZZHPC:7077") .config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") .config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")) spark = configure_spark_with_delta_pip(builder).getOrCreate() spark.sparkContext.setLogLevel("ERROR")
%load_ext sparksql_magic %config SparkSql.limit=20
df = spark.read.format("delta").load("/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles") df.show(5, truncate=25)
+-------+-------+---------------------+---------------+-------------------------+-------------+------------------+------------+------+---------+-------------------------+-------------------------+ |show_id| type| title| director| cast| country| date_added|release_year|rating| duration| listed_in| description| +-------+-------+---------------------+---------------+-------------------------+-------------+------------------+------------+------+---------+-------------------------+-------------------------+ | s1| Movie| Dick Johnson Is Dead|Kirsten Johnson| null|United States|September 25, 2021| 2020| PG-13| 90 min| Documentaries|As her father nears th...| | s2|TV Show| Blood & Water| |Ama Qamata, Khosi Ngem...| South Africa|September 24, 2021| 2021| TV-MA|2 Seasons|International TV Shows...|After crossing paths a...| | s3|TV Show| Ganglands|Julien Leclercq|Sami Bouajila, Tracy G...| null|September 24, 2021| 2021| TV-MA| 1 Season|Crime TV Shows, Intern...|To protect his family ...| | s4|TV Show|Jailbirds New Orleans| | null| null|September 24, 2021| 2021| TV-MA| 1 Season| Docuseries, Reality TV|Feuds, flirtations and...| | s5|TV Show| Kota Factory| |Mayur More, Jitendra K...| India|September 24, 2021| 2021| TV-MA|2 Seasons|International TV Shows...|In a city of coaching ...| +-------+-------+---------------------+---------------+-------------------------+-------------+------------------+------------+------+---------+-------------------------+-------------------------+ only showing top 5 rows

%%sparksql ALTER TABLE delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles` ALTER COLUMN title NOT NULL
%%sparksql ALTER TABLE delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles` ADD CONSTRAINT validType CHECK (type IN ('Movie', 'Show','TV Show'));

%%sparksql CREATE OR REPLACE TABLE delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles_shallow_clone` SHALLOW CLONE delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles`;

Immutability: Both DataFrames and RDDs in Spark are immutable. Shallow cloning essentially just keeps references to the original data, and changes to the clone will not affect the original data.

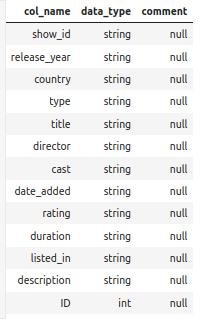
%%sparksql ALTER TABLE delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles` ADD COLUMNS (ID INT)

%%sparksql ALTER TABLE delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles` ALTER COLUMN country AFTER show_id;
%%sparksql ALTER TABLE delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles` ALTER COLUMN release_year AFTER show_id;

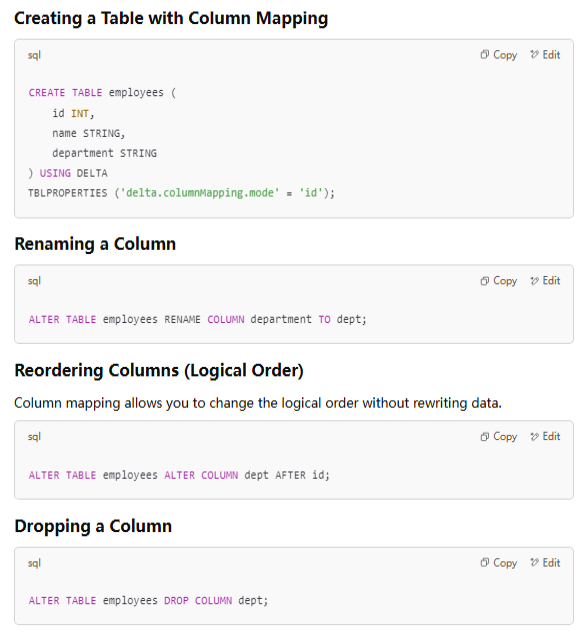
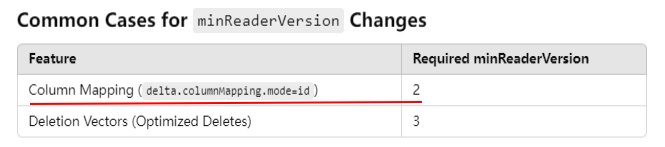
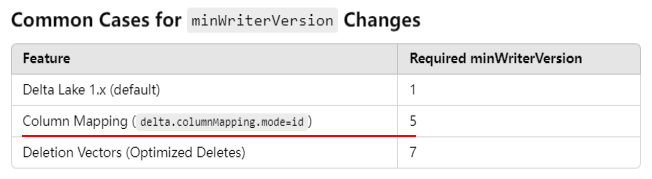
%%sparksql ALTER TABLE delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles` SET TBLPROPERTIES ( 'delta.minReaderVersion' = '2', 'delta.minWriterVersion' = '5', 'delta.columnMapping.mode' = 'name' )


%%sparksql DESCRIBE TABLE delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles`;
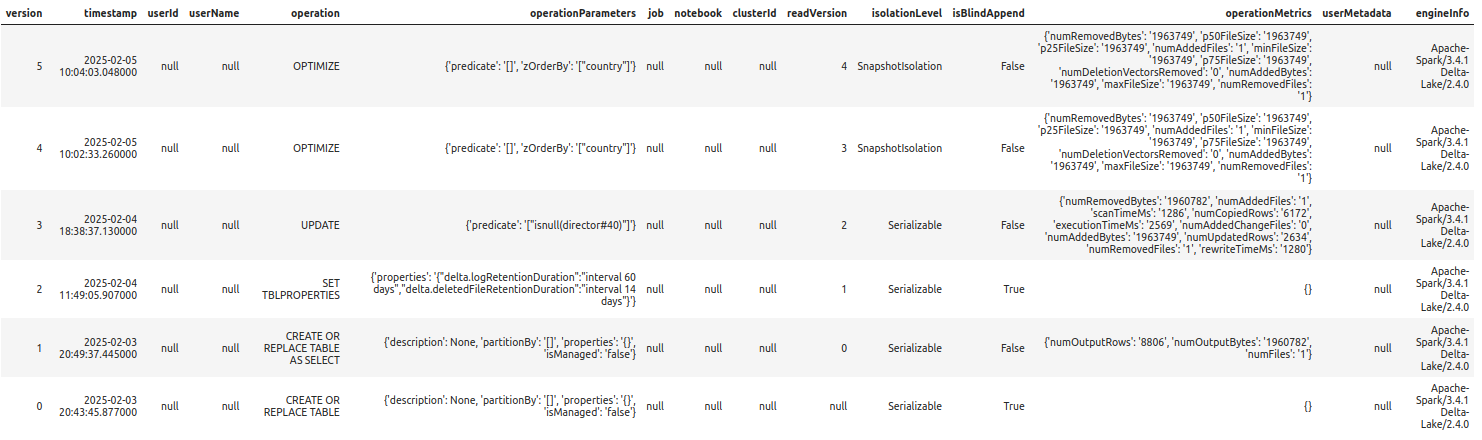
%%sparksql DESCRIBE DETAIL delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles`;



%%sparksql ALTER TABLE delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles` RENAME COLUMN listed_in TO genres
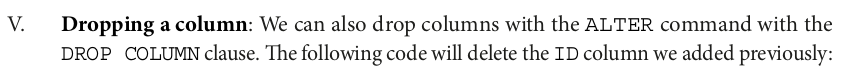
%%sparksql ALTER TABLE delta.`/zdata/Github/Data-Engineering-with-Databricks-Cookbook-main/data/delta_lake/netflix_titles` DROP COLUMN ID


 浙公网安备 33010602011771号
浙公网安备 33010602011771号