from pyspark.sql.functions import flatten, collect_list # create a DataFrame with an array of arrays column df = spark.createDataFrame([ (1, [[1, 2], [3, 4], [5, 6]]), (2, [[7, 8], [9, 10], [11, 12]]) ], ["id", "data"]) # use collect_list() function to group by specified columns collect_df = df.select(collect_list("data").alias("data")) collect_df.show(truncate=False)
collect_list groups rows randomly, sometimes the result is this:
+-------------------------------------------------------+ |data | +-------------------------------------------------------+ |[[[1, 2], [3, 4], [5, 6]], [[7, 8], [9, 10], [11, 12]]]| +-------------------------------------------------------+
sometimes the result is this:
+-------------------------------------------------------+ |data | +-------------------------------------------------------+ |[[[7, 8], [9, 10], [11, 12]], [[1, 2], [3, 4], [5, 6]]]| +-------------------------------------------------------+
from pyspark.sql.functions import explode, flatten, collect_list # create a DataFrame with nested array column df = spark.createDataFrame([ (1, [[[1, 2], [3, 4]], [[5, 6], [7, 8]]]), (2, [[[9, 10], [11, 12]], [[13, 14], [15, 16]]]) ], ["id", "data"]) # explode the outermost array to flatten the structure exploded_df = df.select(col("id"),explode("data").alias("inner_data")) exploded_df.show()
+---+--------------------+ | id| inner_data| +---+--------------------+ | 1| [[1, 2], [3, 4]]| | 1| [[5, 6], [7, 8]]| | 2| [[9, 10], [11, 12]]| | 2|[[13, 14], [15, 16]]| +---+--------------------+
# # use collect_list() to group all the inner arrays together grouped_df = exploded_df.groupBy("id").agg(collect_list("inner_data").alias("merged_data")) grouped_df.show(truncate=False)
+---+-------------------------------------------+ |id |merged_data | +---+-------------------------------------------+ |2 |[[[9, 10], [11, 12]], [[13, 14], [15, 16]]]| |1 |[[[1, 2], [3, 4]], [[5, 6], [7, 8]]] | +---+-------------------------------------------+
# # use flatten() to merge all the elements of the inner arrays flattened_df = grouped_df.select(flatten("merged_data").alias("final_data")) flattened_df.show(truncate=False)
+---------------------------------------+ |final_data | +---------------------------------------+ |[[9, 10], [11, 12], [13, 14], [15, 16]]| |[[1, 2], [3, 4], [5, 6], [7, 8]] | +---------------------------------------+
# Sample DataFrame data = [(1, "Alice"), (2, "Bob")] df = spark.createDataFrame(data, ["id", "name"]) # Renaming columns using alias() in select df_new = df.select(col("id").alias("user_id"), col("name").alias("full_name")) # Show the result df_new.show()
+-------+---------+ |user_id|full_name| +-------+---------+ | 1| Alice| | 2| Bob| +-------+---------+
# Read XML file into a DataFrame df = (spark.read.format("com.databricks.spark.xml") .option("rowTag", "row") .load("../data/nobel_prizes.xml"))
Why "xml" alone won’t work?
Unlike formats like "csv", "json", or "parquet", which are natively supported in Spark, XML processing requires an external package (spark-xml). The "com.databricks.spark.xml" identifier is necessary to access the library’s functionalities.

df_exploded = ( df.select("title", explode("paragraphs").alias("paragraphs")) .select("title", col("paragraphs.context").alias ("context"), explode(col("paragraphs.qas")).alias("questions"))) df_array_distinct = ( df_exploded.select("title","context",
col("questions.id").alias("question_id"),
col("questions.question").alias("question_text"),
array_distinct("questions.answers").alias("answers"))) df_array_distinct.show(5, truncate=40)
+-------------+----------------------------------------+------------------------+----------------------------------------+----------------------------------------+
| title| context| question_id| question_text| answers|
+-------------+----------------------------------------+------------------------+----------------------------------------+----------------------------------------+
|Super_Bowl_50|Super Bowl 50 was an American footbal...|56be4db0acb8001400a502ec|Which NFL team represented the AFC at...| [{177, Denver Broncos}]|
|Super_Bowl_50|Super Bowl 50 was an American footbal...|56be4db0acb8001400a502ed|Which NFL team represented the NFC at...| [{249, Carolina Panthers}]|
|Super_Bowl_50|Super Bowl 50 was an American footbal...|56be4db0acb8001400a502ee| Where did Super Bowl 50 take place?|[{403, Santa Clara, California}, {355...|
|Super_Bowl_50|Super Bowl 50 was an American footbal...|56be4db0acb8001400a502ef| Which NFL team won Super Bowl 50?| [{177, Denver Broncos}]|
|Super_Bowl_50|Super Bowl 50 was an American footbal...|56be4db0acb8001400a502f0|What color was used to emphasize the ...| [{488, gold}, {521, gold}]|
+-------------+----------------------------------------+------------------------+----------------------------------------+----------------------------------------+
only showing top 5 rows

(df_array_distinct.select("title", "context", "question_text", col("answers").getItem(0).getField("text")).show())

(df_array_distinct.filter(col("answers").getItem(0).getField("text").isNotNull()).show())

from pyspark.sql.functions import array_contains df = spark.createDataFrame( [(["apple", "orange", "banana"],),
(["grape", "kiwi", "melon"],),
(["pear", "apple", "pineapple"],)],
["fruits"]
) (df.select("fruits", array_contains("fruits", "apple").alias("contains_apple")).show(truncate=False))
+------------------------+--------------+ |fruits |contains_apple| +------------------------+--------------+ |[apple, orange, banana] |true | |[grape, kiwi, melon] |false | |[pear, apple, pineapple]|true | +------------------------+--------------+

data = [ {"user_info": {"name": "Alice", "age": 28, "email": "alice@example.com"}}, {"user_info": {"name": "Bob", "age": 35, "email": "bob@example.com"}}, {"user_info": {"name": "Charlie", "age": 42, "email": "charlie@example.com"}} ] df = spark.createDataFrame(data) df.show(truncate=False)
+----------------------------------------------------------+
|user_info |
+----------------------------------------------------------+
|{name -> Alice, email -> alice@example.com, age -> 28} |
|{name -> Bob, email -> bob@example.com, age -> 35} |
|{name -> Charlie, email -> charlie@example.com, age -> 42}|
+----------------------------------------------------------+
(df.select("user_info",
map_keys("user_info").alias("user_info_keys"),
map_values("user_info").alias("user_info_values")) .show(truncate=False))
+----------------------------------------------------------+------------------+----------------------------------+
|user_info |user_info_keys |user_info_values |
+----------------------------------------------------------+------------------+----------------------------------+
|{name -> Alice, email -> alice@example.com, age -> 28} |[name, email, age]|[Alice, alice@example.com, 28] |
|{name -> Bob, email -> bob@example.com, age -> 35} |[name, email, age]|[Bob, bob@example.com, 35] |
|{name -> Charlie, email -> charlie@example.com, age -> 42}|[name, email, age]|[Charlie, charlie@example.com, 42]|
+----------------------------------------------------------+------------------+----------------------------------+

data = [ {"words": ["hello", "world"]}, {"words": ["foo", "bar", "baz"]}, {"words": None} ] df = spark.createDataFrame(data) (df.select(explode_outer("words").alias("word")) .show(truncate=False))
+-----+ |word | +-----+ |hello| |world| |foo | |bar | |baz | |null | +-----+
data = [ {"words": ["hello", "world"]}, {"words": ["foo", "bar", "baz"]}, {"words": None} ] df = spark.createDataFrame(data) df.selectExpr("posexplode(words) as (pos, word)").show(truncate=False)
+---+-----+ |pos|word | +---+-----+ |0 |hello| |1 |world| |0 |foo | |1 |bar | |2 |baz | +---+-----+


df_clean = (df .withColumn("Text", regexp_replace("Text", "[^a-zA-Z ]", "")) .withColumn("Text", regexp_replace("Text", " +", " "))) df_clean.show(5)

df_with_words = (df_clean.withColumn("words", split(df_clean.Text, "\\s+"))) df_with_words.select("Text", "words").show(5, truncate=80)
+--------------------------------------------------------------------------------+--------------------------------------------------------------------------------+ | Text| words| +--------------------------------------------------------------------------------+--------------------------------------------------------------------------------+ |I was interested in this food and so was my cat until she got ill from two ma...|[I, was, interested, in, this, food, and, so, was, my, cat, until, she, got, ...| |These cookies are both yummy and well priced I recommend them Other cookies I...|[These, cookies, are, both, yummy, and, well, priced, I, recommend, them, Oth...| |Ive been using Icebreakers as a breath freshener for some time now Almost by ...|[Ive, been, using, Icebreakers, as, a, breath, freshener, for, some, time, no...| |I love Frenchs Fried Onions but when I buy it locally it is usually around or...|[I, love, Frenchs, Fried, Onions, but, when, I, buy, it, locally, it, is, usu...| |I HAVE ORDERED TWO LEAVES AND A BUD TEA FROM AMAZON ON TWO OCCASIONS AND HAVE...|[I, HAVE, ORDERED, TWO, LEAVES, AND, A, BUD, TEA, FROM, AMAZON, ON, TWO, OCCA...| +--------------------------------------------------------------------------------+--------------------------------------------------------------------------------+ only showing top 5 rows
from pyspark.ml.feature import Tokenizer # Tokenize the text data tokenizer = Tokenizer(inputCol='Text', outputCol='words') df_with_words = tokenizer.transform(df_clean) df_with_words.select("Text", "words").show(5, truncate=80)
+--------------------------------------------------------------------------------+--------------------------------------------------------------------------------+ | Text| words| +--------------------------------------------------------------------------------+--------------------------------------------------------------------------------+ |I was interested in this food and so was my cat until she got ill from two ma...|[i, was, interested, in, this, food, and, so, was, my, cat, until, she, got, ...| |These cookies are both yummy and well priced I recommend them Other cookies I...|[these, cookies, are, both, yummy, and, well, priced, i, recommend, them, oth...| |Ive been using Icebreakers as a breath freshener for some time now Almost by ...|[ive, been, using, icebreakers, as, a, breath, freshener, for, some, time, no...| |I love Frenchs Fried Onions but when I buy it locally it is usually around or...|[i, love, frenchs, fried, onions, but, when, i, buy, it, locally, it, is, usu...| |I HAVE ORDERED TWO LEAVES AND A BUD TEA FROM AMAZON ON TWO OCCASIONS AND HAVE...|[i, have, ordered, two, leaves, and, a, bud, tea, from, amazon, on, two, occa...| +--------------------------------------------------------------------------------+--------------------------------------------------------------------------------+

from pyspark.ml.feature import StopWordsRemover remover = StopWordsRemover(inputCol="words", outputCol="filtered_words") df_stop_words_removed = remover.transform(df_with_words) df_stop_words_removed.select("words", "filtered_words").show(5, truncate=80)
+--------------------------------------------------------------------------------+--------------------------------------------------------------------------------+ | words| filtered_words| +--------------------------------------------------------------------------------+--------------------------------------------------------------------------------+ |[i, was, interested, in, this, food, and, so, was, my, cat, until, she, got, ...|[interested, food, cat, got, ill, two, magical, ingredientsbr, br, corn, star...| |[these, cookies, are, both, yummy, and, well, priced, i, recommend, them, oth...|[cookies, yummy, well, priced, recommend, cookies, like, mrs, fieldspackaged,...| |[ive, been, using, icebreakers, as, a, breath, freshener, for, some, time, no...|[ive, using, icebreakers, breath, freshener, time, almost, accident, gave, on...| |[i, love, frenchs, fried, onions, but, when, i, buy, it, locally, it, is, usu...|[love, frenchs, fried, onions, buy, locally, usually, around, dollars, sixoun...| |[i, have, ordered, two, leaves, and, a, bud, tea, from, amazon, on, two, occa...|[ordered, two, leaves, bud, tea, amazon, two, occasions, satisfied, product, ...| +--------------------------------------------------------------------------------+--------------------------------------------------------------------------------+ only showing top 5 rows

df_exploded = (df_stop_words_removed .select(explode(df_stop_words_removed.filtered_words).alias("word"))) word_count = (df_exploded .groupBy("word") .count() .orderBy("count", ascending=False)) word_count.show(n=10)
+-------+-----+ | word|count| +-------+-----+ | like| 2856| | br| 2761| | good| 2278| | great| 1979| | one| 1938| | taste| 1909| |product| 1733| | coffee| 1663| | flavor| 1614| | love| 1537| +-------+-----+ only showing top 10 rows


from pyspark.ml.feature import CountVectorizer # Convert the text data into numerical features vectorizer = CountVectorizer(inputCol='filtered_words', outputCol='features') vectorized_data = vectorizer.fit(df_stop_words_removed).transform(df_stop_words_removed) vectorized_data.select('filtered_words', 'features').show(10, truncate=80)
+--------------------------------------------------------------------------------+--------------------------------------------------------------------------------+ | filtered_words| features| +--------------------------------------------------------------------------------+--------------------------------------------------------------------------------+ |[interested, food, cat, got, ill, two, magical, ingredientsbr, br, corn, star...|(19655,[1,2,11,12,13,17,27,45,55,76,83,84,91,101,170,188,221,229,237,239,259,...| |[cookies, yummy, well, priced, recommend, cookies, like, mrs, fieldspackaged,...|(19655,[0,29,59,110,148,380,411,662,851,3344,4832,5408,6143,6408,14648,17748]...| |[ive, using, icebreakers, breath, freshener, time, almost, accident, gave, on...|(19655,[0,1,4,8,19,20,25,29,38,42,50,53,58,71,78,79,103,109,172,212,221,232,2...| |[love, frenchs, fried, onions, buy, locally, usually, around, dollars, sixoun...|(19655,[6,9,12,14,18,23,24,42,55,166,222,427,669,1022,1187,1259,1512,8968,142...| |[ordered, two, leaves, bud, tea, amazon, two, occasions, satisfied, product, ...|(19655,[6,10,18,45,74,408,467,800,4066,4672],[1.0,1.0,1.0,2.0,1.0,1.0,1.0,1.0...| |[mom, concerned, bpa, wanted, find, something, safely, use, freezer, found, o...|(19655,[0,4,11,12,13,14,16,30,42,49,58,89,99,129,144,156,184,191,220,221,264,...| |[bought, product, needed, freezer, trays, trying, use, remainder, gift, card,...|(19655,[0,1,2,4,6,11,13,14,15,16,17,20,22,24,26,27,28,41,43,48,49,62,65,75,82...| |[purchased, go, new, keurig, im, tea, drinker, one, first, kcups, ordered, go...|(19655,[2,4,10,12,26,28,32,38,55,62,74,100,119,145,167,209,234,256,320,354,36...| |[ordered, coffee, whole, bean, form, flavorful, coffee, unfortunately, smelle...|(19655,[0,7,16,41,46,48,74,102,117,180,244,270,386,433,482,515,568,580,629,64...| |[picture, color, salt, smells, taste, like, fish, also, tiny, rocks, hurt, ev...|(19655,[0,5,17,27,31,48,74,85,124,131,341,452,463,536,541,548,571,691,843,844...| +--------------------------------------------------------------------------------+--------------------------------------------------------------------------------+ only showing top 10 rows

(vectorized_data.repartition(1) .write.mode("overwrite") .json("../data/data_lake/reviews_vectorized.json"))

from pyspark.sql.functions import regexp_extract, regexp_extract_all # Extract all words starting with "f"
df_f_words = (vectorized_data .withColumn("f_word", regexp_extract("text", r"\b(f\w+)\b", 1)) .withColumn("f_words", regexp_extract_all("text", lit(r"\b(f\w+)\b")))) df_f_words.select("text", "f_word", "f_words").show(10, truncate=80)
+--------------------------------------------------------------------------------+---------+--------------------------------------------------------------------------------+ | text| f_word| f_words| +--------------------------------------------------------------------------------+---------+--------------------------------------------------------------------------------+ |I was interested in this food and so was my cat until she got ill from two ma...| food| [food, from, for, food, flavors, feeding, feeding, food]| |These cookies are both yummy and well priced I recommend them Other cookies I...| fig| [fig]| |Ive been using Icebreakers as a breath freshener for some time now Almost by ...|freshener| [freshener, for, for, from, free, found, first, flavor, freshener, favoritesbr]| |I love Frenchs Fried Onions but when I buy it locally it is usually around or...| for| [for, found]| |I HAVE ORDERED TWO LEAVES AND A BUD TEA FROM AMAZON ON TWO OCCASIONS AND HAVE...| | []| |I am a mom concerned about BPA and wanted to find something I could safely us...| find|[find, freezer, found, freezing, frozen, form, freeze, flexible, flexes, food...| |I bought this product because I needed freezer trays and was trying to use up...| freezer|[freezer, feel, food, for, feel, fit, for, feed, food, freezer, freezer, free...| |Purchased to go with my new Keurig and as Im a tea drinker this was one of th...| first| [first, for]| |I ordered this on this same coffee in whole bean form This is a very flavorfu...| form| [form, flavorful]| |The picture is NOT the color of the salt It smells and taste like fish It als...| fish| [fish, from]| +--------------------------------------------------------------------------------+---------+--------------------------------------------------------------------------------+ only showing top 10 rows
df = spark.createDataFrame([('aaaac',)], ['str']) df.select(regexp_extract('str', '(a+)(b)?(c)', 3).alias('d')).show()
+---+ | d| +---+ | c| +---+
# Check if text data contains the word "good" df_good_word = (vectorized_data.withColumn("contains_good", expr("text rlike 'good'"))) df_good_word.select("text", "contains_good").show(10, truncate=100)
+----------------------------------------------------------------------------------------------------+-------------+ | text|contains_good| +----------------------------------------------------------------------------------------------------+-------------+ |I was interested in this food and so was my cat until she got ill from two magical ingredientsbr ...| true| |These cookies are both yummy and well priced I recommend them Other cookies I like are Mrs Fields...| false| |Ive been using Icebreakers as a breath freshener for some time now Almost by accident I gave one ...| false| |I love Frenchs Fried Onions but when I buy it locally it is usually around or dollars for a sixou...| false| |I HAVE ORDERED TWO LEAVES AND A BUD TEA FROM AMAZON ON TWO OCCASIONS AND HAVE BEEN VERY SATISFIED...| false| |I am a mom concerned about BPA and wanted to find something I could safely use in the freezer and...| false| |I bought this product because I needed freezer trays and was trying to use up the remainder of a ...| true| |Purchased to go with my new Keurig and as Im a tea drinker this was one of the first kcups I orde...| true| |I ordered this on this same coffee in whole bean form This is a very flavorful coffee Unfortunate...| false| |The picture is NOT the color of the salt It smells and taste like fish It also has tiny rocks in ...| false| +----------------------------------------------------------------------------------------------------+-------------+ only showing top 10 rows


custom_stopwords = ["br", "get", "im", "ive", "the"] stopwords_remover = StopWordsRemover(inputCol="words", outputCol="filtered_words", stopWords=custom_stopwords) stopwords_remover.setStopWords(custom_stopwords) df_stop_words_removed = stopwords_remover.transform(df_with_words) df_stop_words_removed.select("words", "filtered_words").show(10, truncate=80)
+--------------------------------------------------------------------------------+--------------------------------------------------------------------------------+ | words| filtered_words| +--------------------------------------------------------------------------------+--------------------------------------------------------------------------------+ |[i, was, interested, in, this, food, and, so, was, my, cat, until, she, got, ...|[i, was, interested, in, this, food, and, so, was, my, cat, until, she, got, ...| |[these, cookies, are, both, yummy, and, well, priced, i, recommend, them, oth...|[these, cookies, are, both, yummy, and, well, priced, i, recommend, them, oth...| |[ive, been, using, icebreakers, as, a, breath, freshener, for, some, time, no...|[been, using, icebreakers, as, a, breath, freshener, for, some, time, now, al...| |[i, love, frenchs, fried, onions, but, when, i, buy, it, locally, it, is, usu...|[i, love, frenchs, fried, onions, but, when, i, buy, it, locally, it, is, usu...| |[i, have, ordered, two, leaves, and, a, bud, tea, from, amazon, on, two, occa...|[i, have, ordered, two, leaves, and, a, bud, tea, from, amazon, on, two, occa...| |[i, am, a, mom, concerned, about, bpa, and, wanted, to, find, something, i, c...|[i, am, a, mom, concerned, about, bpa, and, wanted, to, find, something, i, c...| |[i, bought, this, product, because, i, needed, freezer, trays, and, was, tryi...|[i, bought, this, product, because, i, needed, freezer, trays, and, was, tryi...| |[purchased, to, go, with, my, new, keurig, and, as, im, a, tea, drinker, this...|[purchased, to, go, with, my, new, keurig, and, as, a, tea, drinker, this, wa...| |[i, ordered, this, on, this, same, coffee, in, whole, bean, form, this, is, a...|[i, ordered, this, on, this, same, coffee, in, whole, bean, form, this, is, a...| |[the, picture, is, not, the, color, of, the, salt, it, smells, and, taste, li...|[picture, is, not, color, of, salt, it, smells, and, taste, like, fish, it, a...| +--------------------------------------------------------------------------------+--------------------------------------------------------------------------------+ only showing top 10 rows

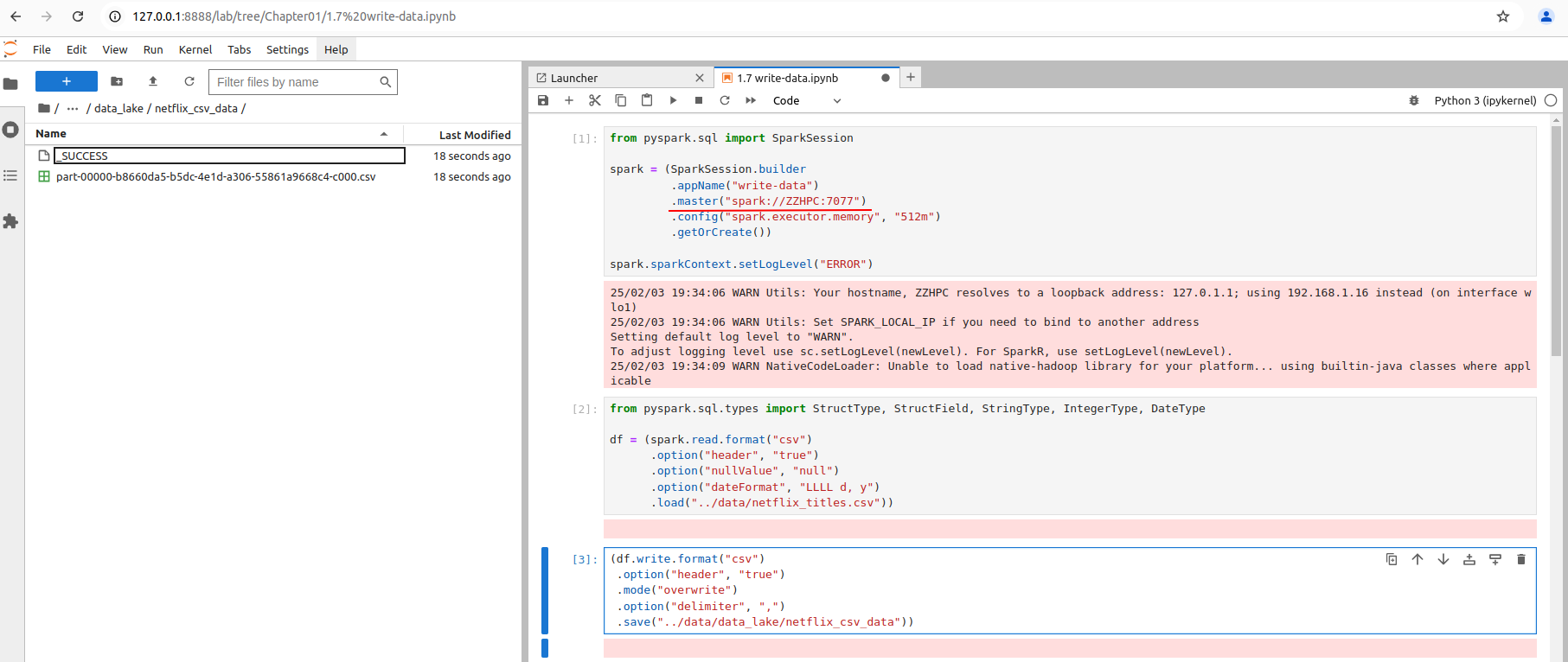
from pyspark.sql import SparkSession spark = (SparkSession.builder .appName("write-data") .master("spark://spark-master:7077") .config("spark.executor.memory", "512m") .getOrCreate()) spark.sparkContext.setLogLevel("ERROR")
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, DateType df = (spark.read.format("csv") .option("header", "true") .option("nullValue", "null") .option("dateFormat", "LLLL d, y") .load("../data/netflix_titles.csv"))
(df.write.format("csv") .option("header", "true") .mode("overwrite") .option("delimiter", ",") .save("../data/data_lake/netflix_csv_data"))
The write operation failed:
---------------------------------------------------------------------------
Py4JJavaError Traceback (most recent call last)
Cell In[10], line 5
1 (df.write.format("csv")
2 .option("header", "true")
3 .mode("overwrite")
4 .option("delimiter", ",")
----> 5 .save("../data/data_lake/netflix_csv_data"))
File /opt/myenv/lib/python3.12/site-packages/pyspark/sql/readwriter.py:1463, in DataFrameWriter.save(self, path, format, mode, partitionBy, **options)
1461 self._jwrite.save()
1462 else:
-> 1463 self._jwrite.save(path)
File /opt/myenv/lib/python3.12/site-packages/py4j/java_gateway.py:1322, in JavaMember.__call__(self, *args)
1316 command = proto.CALL_COMMAND_NAME +\
1317 self.command_header +\
1318 args_command +\
1319 proto.END_COMMAND_PART
1321 answer = self.gateway_client.send_command(command)
-> 1322 return_value = get_return_value(
1323 answer, self.gateway_client, self.target_id, self.name)
1325 for temp_arg in temp_args:
1326 if hasattr(temp_arg, "_detach"):
File /opt/myenv/lib/python3.12/site-packages/pyspark/errors/exceptions/captured.py:179, in capture_sql_exception.<locals>.deco(*a, **kw)
177 def deco(*a: Any, **kw: Any) -> Any:
178 try:
--> 179 return f(*a, **kw)
180 except Py4JJavaError as e:
181 converted = convert_exception(e.java_exception)
File /opt/myenv/lib/python3.12/site-packages/py4j/protocol.py:326, in get_return_value(answer, gateway_client, target_id, name)
324 value = OUTPUT_CONVERTER[type](answer[2:], gateway_client)
325 if answer[1] == REFERENCE_TYPE:
--> 326 raise Py4JJavaError(
327 "An error occurred while calling {0}{1}{2}.\n".
328 format(target_id, ".", name), value)
329 else:
330 raise Py4JError(
331 "An error occurred while calling {0}{1}{2}. Trace:\n{3}\n".
332 format(target_id, ".", name, value))
Py4JJavaError: An error occurred while calling o82.save.
: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 7.0 failed 4 times, most recent failure: Lost task 0.3 in stage 7.0 (TID 25) (172.18.0.5 executor 1): java.io.IOException: Mkdirs failed to create file:/opt/workspace/data/data_lake/netflix_csv_data/_temporary/0/_temporary/attempt_202502030330311036025662540133274_0007_m_000000_25 (exists=false, cwd=file:/usr/bin/spark-3.5.4-bin-hadoop3/work/app-20250203025559-0000/1)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:515)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:500)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:1195)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:1175)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:1064)
at org.apache.spark.sql.execution.datasources.CodecStreams$.createOutputStream(CodecStreams.scala:81)
at org.apache.spark.sql.execution.datasources.CodecStreams$.createOutputStreamWriter(CodecStreams.scala:92)
at org.apache.spark.sql.execution.datasources.csv.CsvOutputWriter.<init>(CsvOutputWriter.scala:38)
at org.apache.spark.sql.execution.datasources.csv.CSVFileFormat$$anon$1.newInstance(CSVFileFormat.scala:84)
at org.apache.spark.sql.execution.datasources.SingleDirectoryDataWriter.newOutputWriter(FileFormatDataWriter.scala:161)
at org.apache.spark.sql.execution.datasources.SingleDirectoryDataWriter.<init>(FileFormatDataWriter.scala:146)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.executeTask(FileFormatWriter.scala:389)
at org.apache.spark.sql.execution.datasources.WriteFilesExec.$anonfun$doExecuteWrite$1(WriteFiles.scala:100)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:893)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:893)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:367)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:331)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:93)
at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:166)
at org.apache.spark.scheduler.Task.run(Task.scala:141)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$4(Executor.scala:620)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally(SparkErrorUtils.scala:64)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally$(SparkErrorUtils.scala:61)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:94)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:623)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.base/java.lang.Thread.run(Unknown Source)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2856)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2792)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2791)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2791)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1247)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1247)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1247)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:3060)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2994)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2983)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:989)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2393)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.$anonfun$executeWrite$4(FileFormatWriter.scala:307)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.writeAndCommit(FileFormatWriter.scala:271)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.executeWrite(FileFormatWriter.scala:304)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.write(FileFormatWriter.scala:190)
at org.apache.spark.sql.execution.datasources.InsertIntoHadoopFsRelationCommand.run(InsertIntoHadoopFsRelationCommand.scala:190)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult$lzycompute(commands.scala:113)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.sideEffectResult(commands.scala:111)
at org.apache.spark.sql.execution.command.DataWritingCommandExec.executeCollect(commands.scala:125)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.$anonfun$applyOrElse$1(QueryExecution.scala:107)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$6(SQLExecution.scala:125)
at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:201)
at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:108)
at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:900)
at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:66)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.applyOrElse(QueryExecution.scala:107)
at org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.applyOrElse(QueryExecution.scala:98)
at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$1(TreeNode.scala:461)
at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(origin.scala:76)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:461)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan.scala:32)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:267)
at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:263)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:32)
at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:32)
at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:437)
at org.apache.spark.sql.execution.QueryExecution.eagerlyExecuteCommands(QueryExecution.scala:98)
at org.apache.spark.sql.execution.QueryExecution.commandExecuted$lzycompute(QueryExecution.scala:85)
at org.apache.spark.sql.execution.QueryExecution.commandExecuted(QueryExecution.scala:83)
at org.apache.spark.sql.execution.QueryExecution.assertCommandExecuted(QueryExecution.scala:142)
at org.apache.spark.sql.DataFrameWriter.runCommand(DataFrameWriter.scala:869)
at org.apache.spark.sql.DataFrameWriter.saveToV1Source(DataFrameWriter.scala:391)
at org.apache.spark.sql.DataFrameWriter.saveInternal(DataFrameWriter.scala:364)
at org.apache.spark.sql.DataFrameWriter.save(DataFrameWriter.scala:243)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(Unknown Source)
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source)
at java.base/java.lang.reflect.Method.invoke(Unknown Source)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:374)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182)
at py4j.ClientServerConnection.run(ClientServerConnection.java:106)
at java.base/java.lang.Thread.run(Unknown Source)
Caused by: java.io.IOException: Mkdirs failed to create file:/opt/workspace/data/data_lake/netflix_csv_data/_temporary/0/_temporary/attempt_202502030330311036025662540133274_0007_m_000000_25 (exists=false, cwd=file:/usr/bin/spark-3.5.4-bin-hadoop3/work/app-20250203025559-0000/1)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:515)
at org.apache.hadoop.fs.ChecksumFileSystem.create(ChecksumFileSystem.java:500)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:1195)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:1175)
at org.apache.hadoop.fs.FileSystem.create(FileSystem.java:1064)
at org.apache.spark.sql.execution.datasources.CodecStreams$.createOutputStream(CodecStreams.scala:81)
at org.apache.spark.sql.execution.datasources.CodecStreams$.createOutputStreamWriter(CodecStreams.scala:92)
at org.apache.spark.sql.execution.datasources.csv.CsvOutputWriter.<init>(CsvOutputWriter.scala:38)
at org.apache.spark.sql.execution.datasources.csv.CSVFileFormat$$anon$1.newInstance(CSVFileFormat.scala:84)
at org.apache.spark.sql.execution.datasources.SingleDirectoryDataWriter.newOutputWriter(FileFormatDataWriter.scala:161)
at org.apache.spark.sql.execution.datasources.SingleDirectoryDataWriter.<init>(FileFormatDataWriter.scala:146)
at org.apache.spark.sql.execution.datasources.FileFormatWriter$.executeTask(FileFormatWriter.scala:389)
at org.apache.spark.sql.execution.datasources.WriteFilesExec.$anonfun$doExecuteWrite$1(WriteFiles.scala:100)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2(RDD.scala:893)
at org.apache.spark.rdd.RDD.$anonfun$mapPartitionsInternal$2$adapted(RDD.scala:893)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:52)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:367)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:331)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:93)
at org.apache.spark.TaskContext.runTaskWithListeners(TaskContext.scala:166)
at org.apache.spark.scheduler.Task.run(Task.scala:141)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$4(Executor.scala:620)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally(SparkErrorUtils.scala:64)
at org.apache.spark.util.SparkErrorUtils.tryWithSafeFinally$(SparkErrorUtils.scala:61)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:94)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:623)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
... 1 more
The error is related to the docker permission.
Abandoned the docker Spark environment.
Created a local Spark environment. See https://www.cnblogs.com/zhangzhihui/p/18697585 .
The write operation succeeded:
(df.write.format("json") .mode("overwrite") .save("../data/data_lake/netflix_json_data")) (df.write.format("parquet") .mode("overwrite") .save("../data/data_lake/netflix_parquet_data"))
Write Compressed Data
(df.write.format("csv") .mode("overwrite") .option("header", "true") .option("delimiter", ",") .option("codec", "org.apache.hadoop.io.compress.GzipCodec") .save("../data/data_lake/netflix_csv_data.gz"))
Specify the Number of Partitions
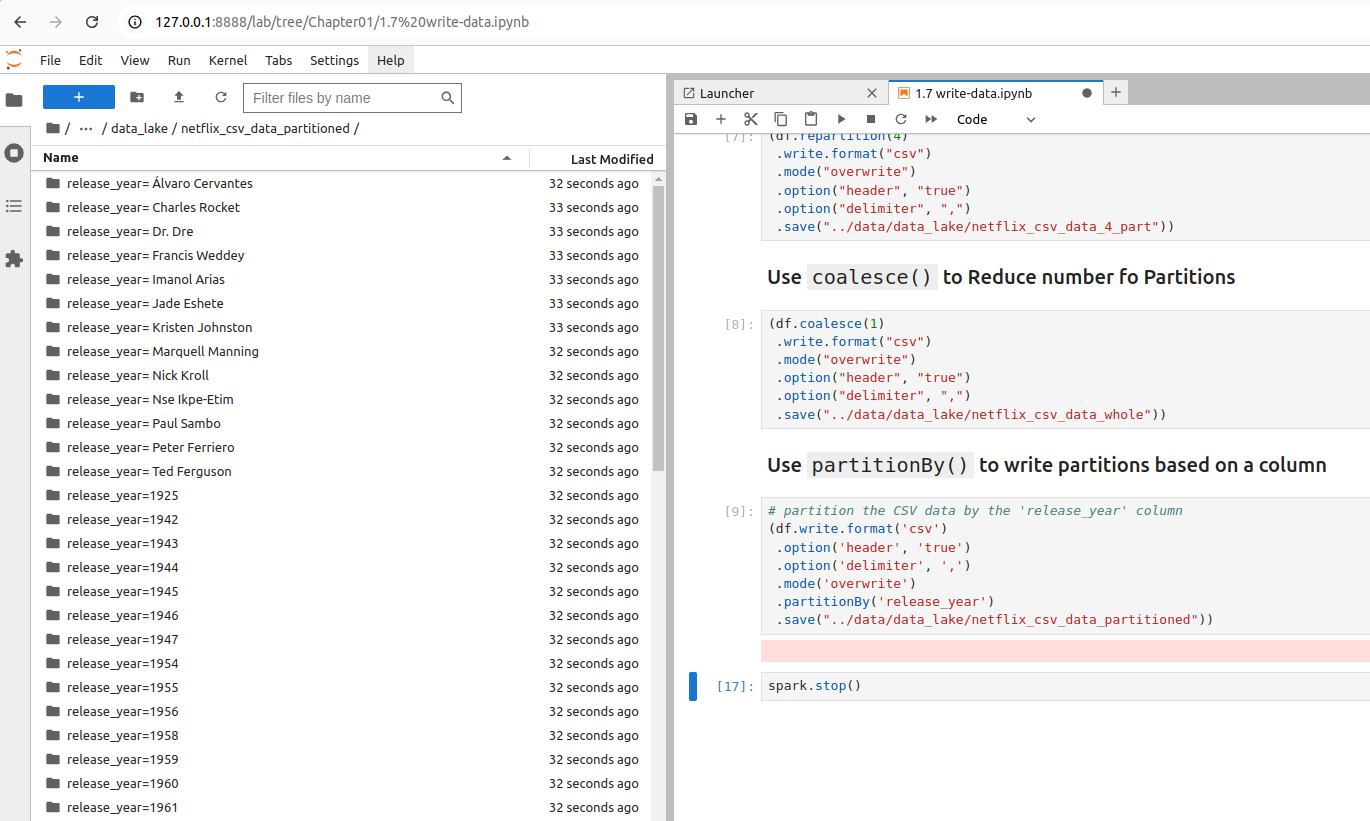
(df.repartition(4) .write.format("csv") .mode("overwrite") .option("header", "true") .option("delimiter", ",") .save("../data/data_lake/netflix_csv_data_4_part"))
Use coalesce() to Reduce number of Partitions
(df.coalesce(1) .write.format("csv") .mode("overwrite") .option("header", "true") .option("delimiter", ",") .save("../data/data_lake/netflix_csv_data_whole"))
Use partitionBy() to write partitions based on a column
# partition the CSV data by the 'release_year' column (df.write.format('csv') .option('header', 'true') .option('delimiter', ',') .mode('overwrite') .partitionBy('release_year') .save("../data/data_lake/netflix_csv_data_partitioned"))


 浙公网安备 33010602011771号
浙公网安备 33010602011771号