








import pandas as pd # 示例数据 data = { "X1": [1, 2, 3, 4, 5], "X2": [2, 4, 6, 8, 10], # X2 是 X1 的两倍,完全共线 "X3": [5, 3, 4, 2, 1] } df = pd.DataFrame(data) # 计算相关系数矩阵 correlation_matrix = df.corr() print(correlation_matrix)
X1 X2 X3 X1 1.0 1.0 -0.9 X2 1.0 1.0 -0.9 X3 -0.9 -0.9 1.0

from statsmodels.stats.outliers_influence import variance_inflation_factor import numpy as np X = df[['X1', 'X2', 'X3']] X['Intercept'] = 1 # 添加截距项 # 计算 VIF vif_data = pd.DataFrame() vif_data["Feature"] = X.columns
vif_data
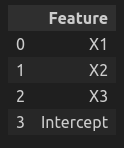
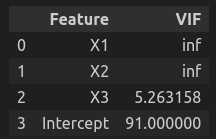
vif_data["VIF"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])] vif_data
/zdata/anaconda3/lib/python3.12/site-packages/statsmodels/stats/outliers_influence.py:197: RuntimeWarning: divide by zero encountered in scalar divide vif = 1. / (1. - r_squared_i)

from sklearn.linear_model import Ridge ridge = Ridge(alpha=1.0) ridge.fit(X.drop(columns=["Intercept"]), df["X3"]) print("Ridge coefficients:", ridge.coef_)











































from pyspark.sql import SparkSession spark = SparkSession.builder.appName("Regression").getOrCreate() from pyspark.ml.feature import VectorAssembler from pyspark.ml.regression import ( LinearRegression, GeneralizedLinearRegression, DecisionTreeRegressor, RandomForestRegressor, GBTRegressor, ) from pyspark.ml import Pipeline from pyspark.ml.evaluation import RegressionEvaluator from sklearn.datasets import fetch_california_housing import pandas as pd df = pd.read_csv("housing.csv", header=0) df.head(5)

df_data = spark.createDataFrame(df) df_data = df_data.select(df_data.columns[:-1]).withColumnRenamed("median_house_value", "label") df_data.show(5)
+---------+--------+------------------+-----------+--------------+----------+----------+-------------+--------+ |longitude|latitude|housing_median_age|total_rooms|total_bedrooms|population|households|median_income| label| +---------+--------+------------------+-----------+--------------+----------+----------+-------------+--------+ | -122.23| 37.88| 41.0| 880.0| 129.0| 322.0| 126.0| 8.3252|452600.0| | -122.22| 37.86| 21.0| 7099.0| 1106.0| 2401.0| 1138.0| 8.3014|358500.0| | -122.24| 37.85| 52.0| 1467.0| 190.0| 496.0| 177.0| 7.2574|352100.0| | -122.25| 37.85| 52.0| 1274.0| 235.0| 558.0| 219.0| 5.6431|341300.0| | -122.25| 37.85| 52.0| 1627.0| 280.0| 565.0| 259.0| 3.8462|342200.0| +---------+--------+------------------+-----------+--------------+----------+----------+-------------+--------+ only showing top 5 rows

feature_cols = df_data.columns[:-1]
assembler = VectorAssembler(inputCols=feature_cols, outputCol="features", handleInvalid="skip")
df_data = assembler.transform(df_data)
df_data.show(5, 100) # truncate column values to 100 characters
+---------+--------+------------------+-----------+--------------+----------+----------+-------------+--------+-------------------------------------------------------+ |longitude|latitude|housing_median_age|total_rooms|total_bedrooms|population|households|median_income| label| features| +---------+--------+------------------+-----------+--------------+----------+----------+-------------+--------+-------------------------------------------------------+ | -122.23| 37.88| 41.0| 880.0| 129.0| 322.0| 126.0| 8.3252|452600.0| [-122.23,37.88,41.0,880.0,129.0,322.0,126.0,8.3252]| | -122.22| 37.86| 21.0| 7099.0| 1106.0| 2401.0| 1138.0| 8.3014|358500.0|[-122.22,37.86,21.0,7099.0,1106.0,2401.0,1138.0,8.3014]| | -122.24| 37.85| 52.0| 1467.0| 190.0| 496.0| 177.0| 7.2574|352100.0| [-122.24,37.85,52.0,1467.0,190.0,496.0,177.0,7.2574]| | -122.25| 37.85| 52.0| 1274.0| 235.0| 558.0| 219.0| 5.6431|341300.0| [-122.25,37.85,52.0,1274.0,235.0,558.0,219.0,5.6431]| | -122.25| 37.85| 52.0| 1627.0| 280.0| 565.0| 259.0| 3.8462|342200.0| [-122.25,37.85,52.0,1627.0,280.0,565.0,259.0,3.8462]| +---------+--------+------------------+-----------+--------------+----------+----------+-------------+--------+-------------------------------------------------------+ only showing top 5 rows

from pyspark.ml.feature import StandardScaler scaler = StandardScaler(inputCol="features", outputCol="scaledFeatures", withStd=True, withMean=True) scalerModel = scaler.fit(df_data) scaledData = scalerModel.transform(df_data) scaledData.select("features", "scaledFeatures").show(5, False)
+-------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------+ |features |scaledFeatures | +-------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------+ |[-122.23,37.88,41.0,880.0,129.0,322.0,126.0,8.3252] |[-1.327281270317632,1.0516915273824956,0.9821392783837126,-0.8037929324103482,-0.9703014690713382,-0.9732956984921931,-0.976809368656565,2.3451055230711657] | |[-122.22,37.86,21.0,7099.0,1106.0,2401.0,1138.0,8.3014]|[-1.3222901990714544,1.0423297552726631,-0.6061953312187979,2.042080223916712,1.3482429440668697,0.8613181601349221,1.670331748783506,2.3325745328880148] | |[-122.24,37.85,52.0,1467.0,190.0,496.0,177.0,7.2574] |[-1.3322723415638025,1.0376488692177488,1.8557233136650935,-0.5351761865084372,-0.8255407636451041,-0.8197493726619295,-0.8434060119476285,1.7828958038456209] | |[-122.25,37.85,52.0,1274.0,235.0,558.0,219.0,5.6431] |[-1.33726341280998,1.0376488692177488,1.8557233136650935,-0.6234948099480775,-0.7187500793142757,-0.7650374634580425,-0.7335444240696809,0.9329471713809304] | |[-122.25,37.85,52.0,1627.0,280.0,565.0,259.0,3.8462] |[-1.33726341280998,1.0376488692177488,1.8557233136650935,-0.46195867484863185,-0.6119593949834473,-0.758860312418894,-0.6289143403763975,-0.013142587446921749]| +-------------------------------------------------------+---------------------------------------------------------------------------------------------------------------------------------------------------------------+ only showing top 5 rows


(trainingData, testData) = scaledData.randomSplit([0.8, 0.2])

lr = LinearRegression(featuresCol="scaledFeatures", labelCol="label") glr = GeneralizedLinearRegression(featuresCol="scaledFeatures", labelCol="label") dt = DecisionTreeRegressor(featuresCol="scaledFeatures", labelCol="label") rf = RandomForestRegressor(featuresCol="scaledFeatures", labelCol="label") gbt = GBTRegressor(featuresCol="scaledFeatures", labelCol="label")

pipeline_lr = Pipeline(stages=[lr]) pipeline_glr = Pipeline(stages=[glr]) pipeline_dt = Pipeline(stages=[dt]) pipeline_rf = Pipeline(stages=[rf]) pipeline_gbt = Pipeline(stages=[gbt])
In this case, the pipeline contains only one stage: the regression models themselves.

model_lr = pipeline_lr.fit(trainingData) model_glr = pipeline_glr.fit(trainingData) model_dt = pipeline_dt.fit(trainingData) model_rf = pipeline_rf.fit(trainingData) model_gbt = pipeline_gbt.fit(trainingData)

predictions_lr = model_lr.transform(testData) predictions_glr = model_glr.transform(testData) predictions_dt = model_dt.transform(testData) predictions_rf = model_rf.transform(testData) predictions_gbt = model_gbt.transform(testData)
predictions_lr.select("label", "prediction").show(10)
+--------+------------------+ | label| prediction| +--------+------------------+ |106700.0| 189582.3337713698| | 73200.0| 74889.09173658115| | 66900.0| 66703.94893464397| | 64600.0| 97928.74516377911| |105900.0| 81276.61383549181| | 81800.0| 202144.0626034448| | 85400.0|157911.41046513937| | 75500.0| 97284.90756230641| | 90000.0|175088.55039269704| | 92800.0|174737.98595747046| +--------+------------------+ only showing top 10 rows

evaluator = RegressionEvaluator(labelCol="label", predictionCol="prediction", metricName="rmse") rmse_lr = evaluator.evaluate(predictions_lr) rmse_glr = evaluator.evaluate(predictions_glr) rmse_dt = evaluator.evaluate(predictions_dt) rmse_rf = evaluator.evaluate(predictions_rf) rmse_gbt = evaluator.evaluate(predictions_gbt) print("Linear Regression RMSE:", rmse_lr) print("General Linear Regression RMSE:", rmse_glr) print("Decision Tree Regression RMSE:", rmse_dt) print("Random Forest Regression RMSE:", rmse_rf) print("Gradient Boosted Tree Regression RMSE:", rmse_gbt)
Linear Regression RMSE: 71242.00490029654 General Linear Regression RMSE: 71242.00490029654 Decision Tree Regression RMSE: 74459.85103183787 Random Forest Regression RMSE: 72652.30837912999 Gradient Boosted Tree Regression RMSE: 59374.7366785645

from pyspark.ml.tuning import ParamGridBuilder, CrossValidator paramGrid_lr = ( ParamGridBuilder() .addGrid(lr.regParam, [0.1, 0.01]) .addGrid(lr.elasticNetParam, [0.0, 0.5, 1.0]) .build() ) paramGrid_glr = ( ParamGridBuilder() .addGrid(glr.regParam, [0.1, 0.01]) .addGrid(glr.maxIter, [10, 20]) .build() ) paramGrid_dt = ( ParamGridBuilder() .addGrid(dt.maxDepth, [5, 10, 20]) .addGrid(dt.maxBins, [16, 32, 64]) .build() ) paramGrid_rf = ( ParamGridBuilder() .addGrid(rf.numTrees, [5, 10, 20]) .addGrid(rf.maxDepth, [4, 6, 8]) .build() ) paramGrid_gbt = ( ParamGridBuilder() .addGrid(gbt.maxDepth, [4, 6, 8]) .addGrid(gbt.maxIter, [2, 4, 6]) .build() )




# Define evaluator evaluator = RegressionEvaluator( labelCol="label", predictionCol="prediction", metricName="rmse" ) # Define CrossValidator for each algorithm cv_lr = CrossValidator( estimator=pipeline_lr, estimatorParamMaps=paramGrid_lr, evaluator=evaluator, numFolds=3, ) cv_glr = CrossValidator( estimator=pipeline_glr, estimatorParamMaps=paramGrid_glr, evaluator=evaluator, numFolds=3, ) cv_dt = CrossValidator( estimator=pipeline_dt, estimatorParamMaps=paramGrid_dt, evaluator=evaluator, numFolds=3, ) cv_rf = CrossValidator( estimator=pipeline_rf, estimatorParamMaps=paramGrid_rf, evaluator=evaluator, numFolds=3, ) cv_gbt = CrossValidator( estimator=pipeline_gbt, estimatorParamMaps=paramGrid_gbt, evaluator=evaluator, numFolds=3, )

cvModel_lr = cv_lr.fit(trainingData) cvModel_glr = cv_glr.fit(trainingData) cvModel_dt = cv_dt.fit(trainingData) cvModel_rf = cv_rf.fit(trainingData) cvModel_gbt = cv_gbt.fit(trainingData)
2m27.9s

predictions_lr = cvModel_lr.transform(testData) predictions_glr = cvModel_glr.transform(testData) predictions_dt = cvModel_dt.transform(testData) predictions_rf = cvModel_rf.transform(testData) predictions_gbt = cvModel_gbt.transform(testData)

rmse_lr = evaluator.evaluate(predictions_lr) rmse_glr = evaluator.evaluate(predictions_glr) rmse_dt = evaluator.evaluate(predictions_dt) rmse_rf = evaluator.evaluate(predictions_rf) rmse_gbt = evaluator.evaluate(predictions_gbt) print("Linear Regression RMSE:", rmse_lr) print("General Linear Regression RMSE:", rmse_glr) print("Decision Tree Regression RMSE:", rmse_dt) print("Random Forest Regression RMSE:", rmse_rf) print("Gradient Boosted Tree Regression RMSE:", rmse_gbt)
Linear Regression RMSE: 68190.58581667057 General Linear Regression RMSE: 68190.40250330207 Decision Tree Regression RMSE: 60997.57749479734 Random Forest Regression RMSE: 61009.33248041223 Gradient Boosted Tree Regression RMSE: 60215.51775661658



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律