






from pyspark.sql import SparkSession spark = SparkSession.builder.appName("HDFS Read Example").getOrCreate() # Define the HDFS path hdfs_path = "hdfs://namenode:port/path/to/your/file.csv" # Read the CSV file into a DataFrame df = spark.read.csv(hdfs_path, header=True, inferSchema=True) # Show the DataFrame df.show()

from pyspark.sql import SparkSession # Initialize a SparkSession spark = SparkSession.builder \ .appName("Read Data from S3") \ .config("spark.hadoop.fs.s3a.access.key", "YOUR_ACCESS_KEY") \ .config("spark.hadoop.fs.s3a.secret.key", "YOUR_SECRET_KEY") \ .config("spark.hadoop.fs.s3a.impl", "org.apache.hadoop.fs.s3a.S3AFileSystem") \ .getOrCreate() # Replace 's3a://your-bucket-name/your-data-file' with your S3 bucket and file s3_file_path = "s3a://your-bucket-name/your-data-file" # Read the data into a DataFrame df = spark.read.csv(s3_file_path, header=True, inferSchema=True) # Show the DataFrame df.show() # Stop the SparkSession spark.stop()

from pyspark.sql import SparkSession # Initialize a SparkSession spark = SparkSession.builder \ .appName("Read Data from Azure Blob Storage") \ .config("fs.azure", "org.apache.hadoop.fs.azure.NativeAzureFileSystem") \ .config("fs.azure.account.key.YOUR_STORAGE_ACCOUNT_NAME.blob.core.windows.net", "YOUR_STORAGE_ACCOUNT_ACCESS_KEY") \ .getOrCreate() # Replace with your Azure Storage account details storage_account_name = "YOUR_STORAGE_ACCOUNT_NAME" container_name = "YOUR_CONTAINER_NAME" file_path = "YOUR_FILE_PATH" # e.g., "folder/data.csv" # Construct the full Azure Blob Storage path blob_file_path = f"wasbs://{container_name}@{storage_account_name}.blob.core.windows.net/{file_path}" # Read the data into a DataFrame # Replace 'spark.read.csv' with the appropriate method for your data format # Use "spark.read.parquet" for parquet files # Use "spark.read.json" for JSON files df = spark.read.csv(blob_file_path, header=True, inferSchema=True) # Show the DataFrame df.show() # Stop the SparkSession spark.stop()

from pyspark.sql import SparkSession # Initialize a SparkSession spark = SparkSession.builder \ .appName("Read Data from PostgreSQL") \ .getOrCreate() # PostgreSQL database details jdbc_url = "jdbc:postgresql://hostname:port/database_name" properties = { "user": "username", "password": "password", "driver": "org.postgresql.Driver" } # Name of the table you want to read table_name = "your_table" # Read data from PostgreSQL into a DataFrame df = spark.read.jdbc(url=jdbc_url, table=table_name, properties=properties) # Show the DataFrame df.show() # Stop the SparkSession spark.stop()

from pyspark.sql import SparkSession # Configure the Spark session to use the Spark Cassandra Connector # Replace with the correct version connector_package = "com.datastax.spark:spark-cassandra-connector_2.12:3.0.0" spark = SparkSession.builder \ .appName("PySpark Cassandra Example") \ .config("spark.jars.packages", connector_package) \ .config("spark.cassandra.connection.host", "cassandra_host") \ .config("spark.cassandra.connection.port", "cassandra_port") \ .config("spark.cassandra.auth.username", "username") \ .config("spark.cassandra.auth.password", "password") \ .getOrCreate() # Now you can use the Spark session to read from or write to Cassandra # Example: Reading data from a Cassandra table keyspace = "your_keyspace" table = "your_table" df = spark.read \ .format("org.apache.spark.sql.cassandra") \ .options(keyspace=keyspace, table=table) \ .load() df.show() # Remember to stop the Spark session spark.stop()




from pyspark.sql import SparkSession spark = SparkSession.builder.appName("Python Spark SQL basic example").getOrCreate() df = spark.createDataFrame( [("tony", 25), ("tony", 25), ("mike", 40)], ["name", "age"]) df.dropDuplicates().show()
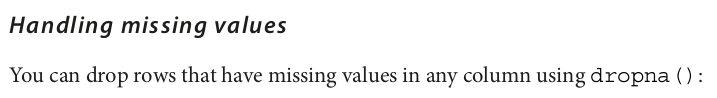
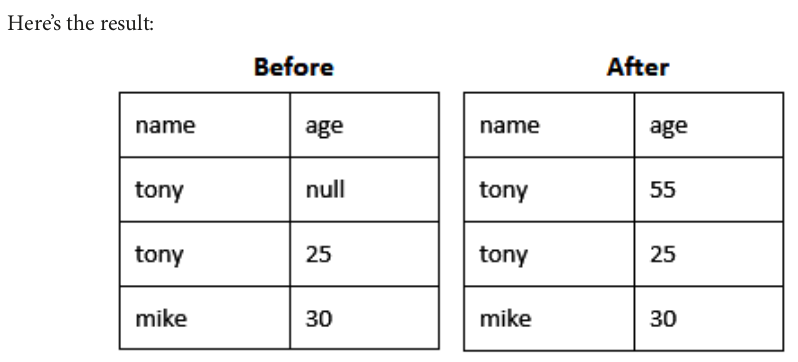
# Drops rows with any null values df = df.dropna(how='any')

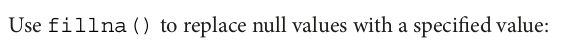
df = spark.createDataFrame( [('tony', None), ('tony', 25), ('mike', 40)], ["name", "age"]) df.na.fill({'age': 55}).show()

df = df.filter(df['age'] > 20)


df = spark.createDataFrame([('tony', 35), ('tony', 25), ('mike', 40)], ["name", "age"]) df # DataFrame[name: string, age: bigint]
df = df.withColumn("age", df["age"].cast("integer")) df # DataFrame[name: string, age: int]
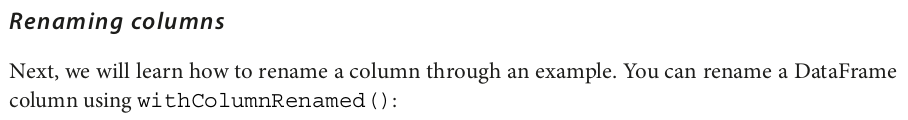
df = df.withColumnRenamed("name", "new_name")

from pyspark.sql.functions import trim df = df.withColumn("Name_new", trim(df["name"]))
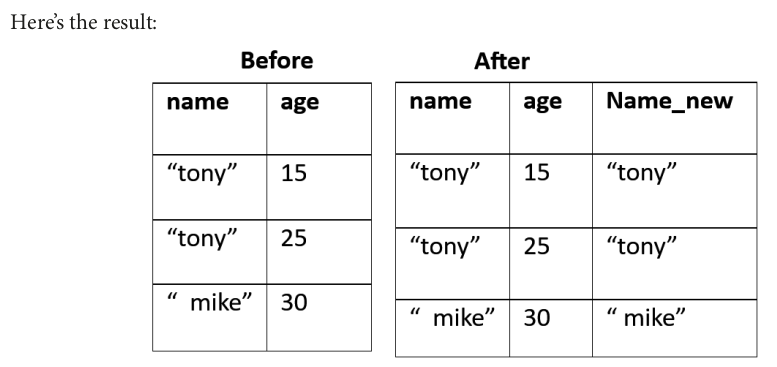

df = df.orderBy(df["age"].desc())


df = spark.createDataFrame( [(1,"north",100,"walmart"), (2,"south",300,"apple"), (3,"west",200,"google"), (1,"east",200,"google"), (2,"north",100,"walmart"), (3,"west",300,"apple"), (1,"north",200,"walmart"), (2,"east",500,"google"), (3,"west",400,"apple"),], ["emp_id","region","sales","customer"]) df.agg({"sales": "sum"}).show() df.agg({"sales": "min"}).show() df.agg({"sales": "max"}).show() df.agg({"sales": "count"}).show() df.agg({"sales": "mean"}).show() df.agg({"sales": "mean","customer":"count"}).show()



df.groupby("emp_id").agg({"sales": "sum"}).orderBy('emp_id').show()
df.groupby("emp_id").agg({"sales": "last"}).orderBy('emp_id').show()
Since Spark's last function does not guarantee order unless explicitly specified, we need to use window functions to ensure that the last value is correctly determined based on a specific order.
from pyspark.sql import SparkSession from pyspark.sql.window import Window from pyspark.sql.functions import last # Initialize Spark Session spark = SparkSession.builder.appName("SparkExample").getOrCreate() # Sample Data data = [ (1, "A", 10, "2024-01-01"), (2, "A", 20, "2024-01-02"), (3, "A", 30, "2024-01-03"), (4, "B", 40, "2024-01-01"), (5, "B", 50, "2024-01-02"), ] # Create DataFrame df = spark.createDataFrame(data, ["id", "group", "value", "date"]) # Define Window Specification window_spec = Window.partitionBy("group").orderBy("date").rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing) # Apply last function with ordering df = df.withColumn("last_value", last("value").over(window_spec)) df.show()





df = spark.createDataFrame( [("sales", 10, 6000), ("hr", 7, 3000), ("it", 5, 5000), ("sales", 2, 6000), ("hr", 3, 2000), ("hr", 4, 6000), ("it", 8, 8000), ("sales", 9, 5000), ("sales", 1, 7000), ("it", 6, 6000)], ["dept_name", "emp_id", "salary"] ) df.show()
+---------+------+------+ |dept_name|emp_id|salary| +---------+------+------+ | sales| 10| 6000| | hr| 7| 3000| | it| 5| 5000| | sales| 2| 6000| | hr| 3| 2000| | hr| 4| 6000| | it| 8| 8000| | sales| 9| 5000| | sales| 1| 7000| | it| 6| 6000| +---------+------+------+

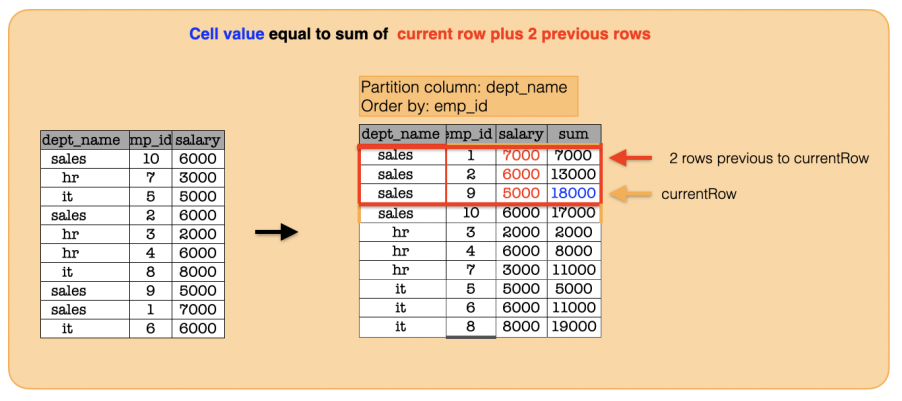
We will now create a new column, named sum, using the aggregate sum function and the window function defined in the previous line of code:
from pyspark.sql import functions as func from pyspark.sql import Window window = Window.partitionBy("dept_name").orderBy("emp_id").rowsBetween(-2, 0) df.withColumn("sum", func.sum("salary").over(window)).show()
+---------+------+------+-----+ |dept_name|emp_id|salary| sum| +---------+------+------+-----+ | hr| 3| 2000| 2000| | hr| 4| 6000| 8000| | hr| 7| 3000|11000| | it| 5| 5000| 5000| | it| 6| 6000|11000| | it| 8| 8000|19000| | sales| 1| 7000| 7000| | sales| 2| 6000|13000| | sales| 9| 5000|18000| | sales| 10| 6000|17000| +---------+------+------+-----+

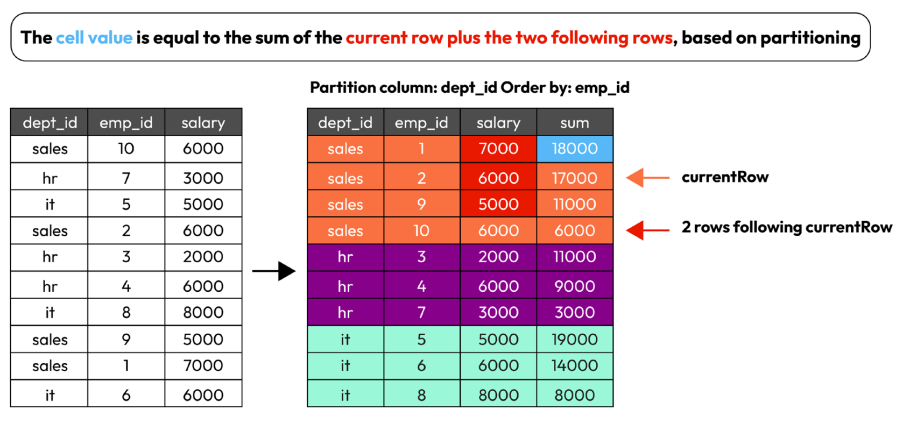
window = Window.partitionBy("dept_name").orderBy("emp_id").rowsBetween(0, 2) df.withColumn("sum", func.sum("salary").over(window)).show()
+---------+------+------+-----+ |dept_name|emp_id|salary| sum| +---------+------+------+-----+ | hr| 3| 2000|11000| | hr| 4| 6000| 9000| | hr| 7| 3000| 3000| | it| 5| 5000|19000| | it| 6| 6000|14000| | it| 8| 8000| 8000| | sales| 1| 7000|18000| | sales| 2| 6000|17000| | sales| 9| 5000|11000| | sales| 10| 6000| 6000| +---------+------+------+-----+

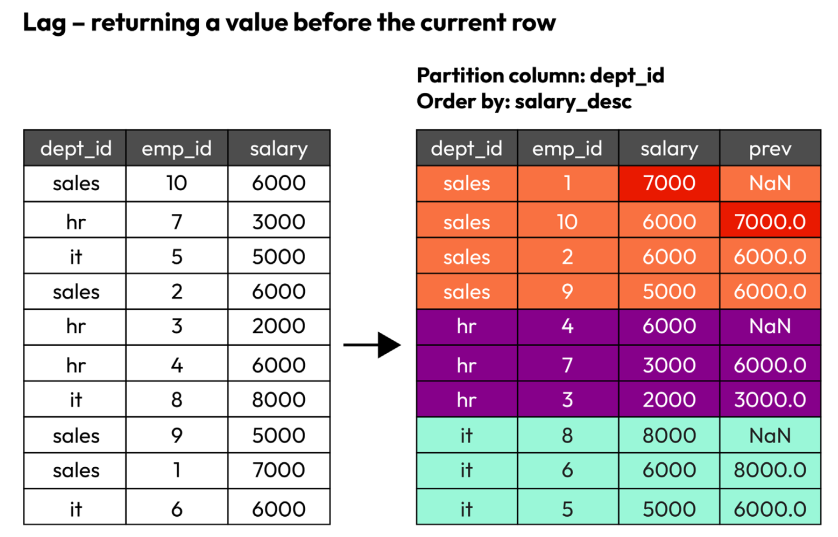
window = Window.partitionBy("dept_name").orderBy(func.col("salary").desc()) df.withColumn("previous_salary", func.lag("salary", 1).over(window)).show()
+---------+------+------+---------------+ |dept_name|emp_id|salary|previous_salary| +---------+------+------+---------------+ | hr| 4| 6000| NULL| | hr| 7| 3000| 6000| | hr| 3| 2000| 3000| | it| 8| 8000| NULL| | it| 6| 6000| 8000| | it| 5| 5000| 6000| | sales| 1| 7000| NULL| | sales| 10| 6000| 7000| | sales| 2| 6000| 6000| | sales| 9| 5000| 6000| +---------+------+------+---------------+

df_left = spark.createDataFrame( [(1001,1,100), (1002,2,200), (1003,3,300), (1004,1,200), (1005,6,200)], ["order_id","customer_id","amount"]) df_left.show()
+--------+-----------+------+ |order_id|customer_id|amount| +--------+-----------+------+ | 1001| 1| 100| | 1002| 2| 200| | 1003| 3| 300| | 1004| 1| 200| | 1005| 6| 200| +--------+-----------+------+
df_right = spark.createDataFrame( [(1,"john"), (2,"mike"), (3,"tony"), (4,"kent")], ["customer_id","name"]) df_right.show()
+-----------+----+ |customer_id|name| +-----------+----+ | 1|john| | 2|mike| | 3|tony| | 4|kent| +-----------+----+

df_left.join(df_right,on="customer_id",how="inner").show()
+-----------+--------+------+----+ |customer_id|order_id|amount|name| +-----------+--------+------+----+ | 1| 1001| 100|john| | 1| 1004| 200|john| | 2| 1002| 200|mike| | 3| 1003| 300|tony| +-----------+--------+------+----+

df_left.join(df_right,on="customer_id",how="left").show() df_left.join(df_right,on="customer_id",how="left_outer").show() df_left.join(df_right,on="customer_id",how="leftouter").show()
+-----------+--------+------+----+ |customer_id|order_id|amount|name| +-----------+--------+------+----+ | 1| 1001| 100|john| | 2| 1002| 200|mike| | 3| 1003| 300|tony| | 1| 1004| 200|john| | 6| 1005| 200|NULL| +-----------+--------+------+----+

df_left.join(df_right,on="customer_id",how="right").show() df_left.join(df_right,on="customer_id",how="right_outer").show() df_left.join(df_right,on="customer_id",how="rightouter").show()
+-----------+--------+------+----+ |customer_id|order_id|amount|name| +-----------+--------+------+----+ | 1| 1004| 200|john| | 1| 1001| 100|john| | 2| 1002| 200|mike| | 3| 1003| 300|tony| | 4| NULL| NULL|kent| +-----------+--------+------+----+

df_left.join(df_right,on="customer_id",how="full").show() df_left.join(df_right,on="customer_id",how="fullouter").show() df_left.join(df_right,on="customer_id",how="full_outer").show()
+-----------+--------+------+----+ |customer_id|order_id|amount|name| +-----------+--------+------+----+ | 1| 1001| 100|john| | 1| 1004| 200|john| | 2| 1002| 200|mike| | 3| 1003| 300|tony| | 4| NULL| NULL|kent| | 6| 1005| 200|NULL| +-----------+--------+------+----+

spark.conf.set("spark.sql.crossJoin.enabled", "true") df_left.crossJoin(df_right).show()
+--------+-----------+------+-----------+----+ |order_id|customer_id|amount|customer_id|name| +--------+-----------+------+-----------+----+ | 1001| 1| 100| 1|john| | 1001| 1| 100| 2|mike| | 1001| 1| 100| 3|tony| | 1001| 1| 100| 4|kent| | 1002| 2| 200| 1|john| | 1002| 2| 200| 2|mike| | 1002| 2| 200| 3|tony| | 1002| 2| 200| 4|kent| | 1003| 3| 300| 1|john| | 1003| 3| 300| 2|mike| | 1003| 3| 300| 3|tony| | 1003| 3| 300| 4|kent| | 1004| 1| 200| 1|john| | 1004| 1| 200| 2|mike| | 1004| 1| 200| 3|tony| | 1004| 1| 200| 4|kent| | 1005| 6| 200| 1|john| | 1005| 6| 200| 2|mike| | 1005| 6| 200| 3|tony| | 1005| 6| 200| 4|kent| +--------+-----------+------+-----------+----+
df_left.join(df_right,on="customer_id",how="semi").show() df_left.join(df_right,on="customer_id",how="leftsemi").show() df_left.join(df_right,on="customer_id",how="left_semi").show()
+-----------+--------+------+ |customer_id|order_id|amount| +-----------+--------+------+ | 1| 1001| 100| | 1| 1004| 200| | 2| 1002| 200| | 3| 1003| 300| +-----------+--------+------+

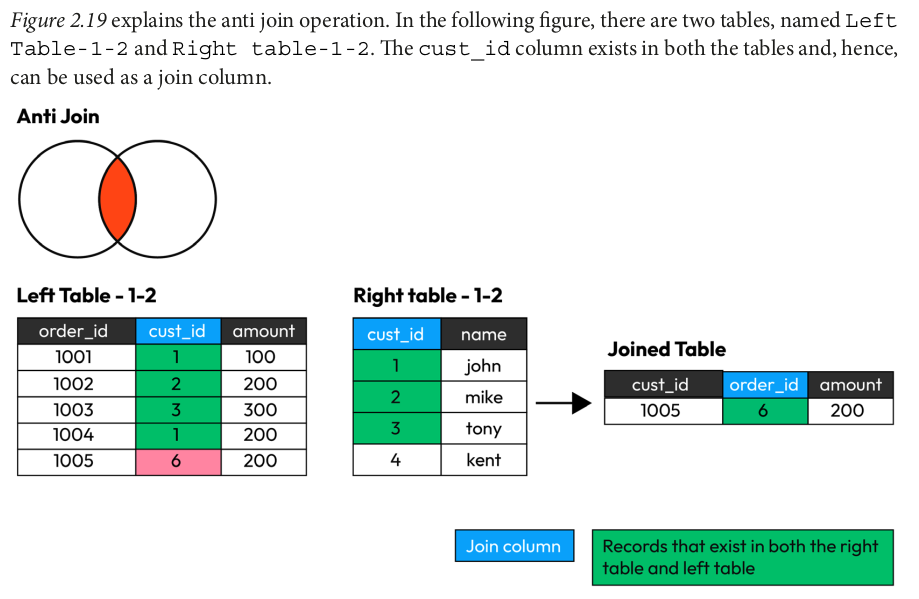
df_left.join(df_right,on="customer_id",how="anti").show() df_left.join(df_right,on="customer_id",how="leftanti").show() df_left.join(df_right,on="customer_id",how="left_anti").show()
+-----------+--------+------+ |customer_id|order_id|amount| +-----------+--------+------+ | 6| 1005| 200| +-----------+--------+------+



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律