


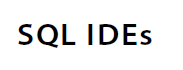


(zpy310) frank@ZZHUBT:~$ pip install duckdb (zpy310) frank@ZZHUBT:~$ pip install harlequin ...... Successfully installed MarkupSafe-3.0.2 click-8.1.8 harlequin-1.25.2 jinja2-3.1.5 linkify-it-py-2.0.3 markdown-it-py-3.0.0 mdit-py-plugins-0.4.2 mdurl-0.1.2 numpy-1.26.4 platformdirs-4.3.6 prompt_toolkit-3.0.48 pyarrow-19.0.0 pygments-2.19.1 pyperclip-1.9.0 questionary-2.1.0 rich-13.9.4 rich-click-1.8.5 shandy-sqlfmt-0.24.0 textual-0.85.0 textual-fastdatatable-0.10.0 textual-textarea-0.14.4 tomli-2.2.1 tomlkit-0.13.2 tqdm-4.67.1 tree-sitter-0.20.4 tree-sitter-languages-1.10.2 typing-extensions-4.12.2 uc-micro-py-1.0.3 wcwidth-0.2.13
Installing Harlequin
After installing Python 3.8 or above, install Harlequin using pip or pipx with:
$ pipx install harlequinYou may want to install Harlequin with one or more extras, which provide additional features like additional database support or remote file viewing. That would look like this:
$ pipx install harlequin[postgres,s3]Using Harlequin with DuckDB
Harlequin defaults to using its DuckDB database adapter.
From any shell, to open one or more DuckDB database files:
$ harlequin "path/to/duck.db" "another_duck.db"To open an in-memory DuckDB session, run Harlequin with no arguments:
$ harlequinIf you want to control the version of DuckDB that Harlequin uses, see the Troubleshooting page.
Using Harlequin with SQLite and Other Adapters
Harlequin also ships with a SQLite3 adapter. You can open one or more SQLite database files with:
$ harlequin -a sqlite "path/to/sqlite.db" "another_sqlite.db"Like DuckDB, you can also open an in-memory database by omitting the paths:
$ harlequin -a sqliteOther adapters can be installed using pip install <adapter package> or pipx inject harlequin <adapter package>, depending on how you installed Harlequin. Several adapters are under active development; for a list of known adapters provided either by the Harlequin maintainers or the broader community, see the adapters page.
Using Harlequin with Django
django-harlequin provides a command to launch Harlequin using Django’s database configuration, like:
$ ./manage.py harlequin
(zpy310) frank@ZZHUBT:~$ harlequin
 Tad
Tad
 Visidata, vdsql, Ibis
Visidata, vdsql, Ibis
 Tableau
Tableau
 Metabase, Superset
Metabase, Superset
 Rill, Evidence
Rill, Evidence


 Colab
Colab

 Kaggle
Kaggle
 Binder
Binder






 Substrait
Substrait












import ibis
conn = ibis.duckdb.connect()
licenses = conn.read_csv( "data/C12/NYC_Dog_Licensing_Dataset.csv", ignore_errors=True )
To readily build Table expressions that define operations over columns, Ibis supports the convenient creation of column expressions using its underscore (_) API:
from ibis import _
distinct_cols = [ "AnimalName", "AnimalGender", "AnimalBirthYear", "BreedName", "ZipCode", ] unique_dogs = ( licenses[distinct_cols] .filter(_.AnimalName.notin(["UNKNOWN", "NAME NOT PROVIDED", "NAME", "NONE"])) .filter(_.BreedName.notin(["Unknown", "Not Provided"])) .distinct() )

dogs_by_year = ( unique_dogs.group_by("AnimalBirthYear") .aggregate(Count=_.count()) .order_by(ibis.desc("AnimalBirthYear")) )
ibis.options.interactive = True
dogs_by_year.head(10)
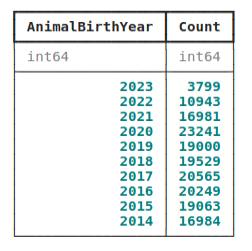
dogs_by_year_df = dogs_by_year.to_pandas()
 Fugue
Fugue







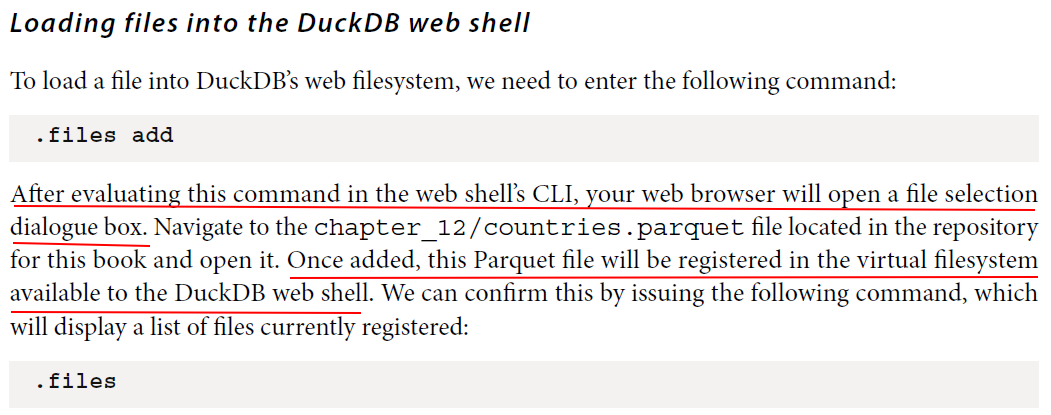
duckdb> .files add Added 1 files duckdb> .files ┌───────────────────┬───────────┬──────────┬────────────┐ │ File Name ┆ File Size┆ Protocol┆ Statistics │ ╞═══════════════════╪═══════════╪══════════╪════════════╡ │ countries.parquet ┆ unknown ┆ Http ┆ false │ └───────────────────┴───────────┴──────────┴────────────┘
With the countries.parquet file now registered in DuckDB’s web filesystem, we can now run DuckDB SQL queries, just as if we were using the DuckDB CLI.
duckdb> FROM 'countries.parquet' LIMIT 10; ┌─────────┬──────────────────────┐ │ country ┆ name │ ╞═════════╪══════════════════════╡ │ AD ┆ Andorra │ │ AE ┆ United Arab Emirates │ │ AF ┆ Afghanistan │ │ AG ┆ Antigua and Barbuda │ │ AI ┆ Anguilla │ │ AL ┆ Albania │ │ AM ┆ Armenia │ │ AN ┆ Netherlands Antilles │ │ AO ┆ Angola │ │ AQ ┆ Antarctica │ └─────────┴──────────────────────┘


 Streamlit
Streamlit
 Gradio
Gradio




 浙公网安备 33010602011771号
浙公网安备 33010602011771号