

In this section, we are going to explore some of the DuckDB niceties – little shortcuts and tweaks to make your use of DuckDB easier.
D CREATE OR REPLACE TABLE skiers AS SELECT * FROM read_csv('skiers.csv');
A very common SQL shortcut is the SELECT * syntax. Like in many databases, * is a SQL shortcut that’s interpreted by DuckDB as a request to return all the columns.
One small but very useful affordance of DuckDB is the use of a final trailing comma in a multi-column selection; this does not raise a syntax error.
DuckDB can also explicitly omit columns with the EXCLUDE syntax. To ignore the skiers’ ages and heights, we can simply specify these as columns to exclude:
SELECT s.* EXCLUDE(skier_age, skier_height) FROM skiers AS s;


D SELECT s.* REPLACE(round(skier_age / 10) * 10)::INTEGER AS skier_age FROM skiers AS s; ┌──────────────────┬─────────────────┬───────────┬──────────────┬────────────────────┬─────────────────┐ │ skier_first_name │ skier_last_name │ skier_age │ skier_height │ skier_helmet_color │ skier_bib_color │ │ varchar │ varchar │ int32 │ int64 │ varchar │ varchar │ ├──────────────────┼─────────────────┼───────────┼──────────────┼────────────────────┼─────────────────┤ │ Alice │ Smith │ 10 │ 152 │ red │ black │ │ Bob │ Blaese │ 20 │ 178 │ blue │ yellow │ │ Carol │ Wilson │ 30 │ 159 │ yellow │ pink │ │ Dan │ Jones │ 50 │ 182 │ red │ yellow │ │ Erin │ Taylor │ 20 │ 168 │ black │ green │ │ Frank │ Williams │ 20 │ 187 │ yellow │ red │ │ Grace │ Miller │ 20 │ 172 │ pink │ black │ │ Heidi │ Johnson │ 20 │ 178 │ yellow │ yellow │ │ Ivan │ Brown │ 20 │ 185 │ green │ pink │ │ Judy │ Moore │ 30 │ 160 │ red │ black │ ├──────────────────┴─────────────────┴───────────┴──────────────┴────────────────────┴─────────────────┤ │ 10 rows 6 columns │ └──────────────────────────────────────────────────────────────────────────────────────────────────────┘

D SELECT skier_first_name, COLUMNS('.*color$') FROM skiers; ┌──────────────────┬────────────────────┬─────────────────┐ │ skier_first_name │ skier_helmet_color │ skier_bib_color │ │ varchar │ varchar │ varchar │ ├──────────────────┼────────────────────┼─────────────────┤ │ Alice │ red │ black │ │ Bob │ blue │ yellow │ │ Carol │ yellow │ pink │ │ Dan │ red │ yellow │ │ Erin │ black │ green │ │ Frank │ yellow │ red │ │ Grace │ pink │ black │ │ Heidi │ yellow │ yellow │ │ Ivan │ green │ pink │ │ Judy │ red │ black │ ├──────────────────┴────────────────────┴─────────────────┤ │ 10 rows 3 columns │ └─────────────────────────────────────────────────────────┘

D SELECT skier_first_name, COLUMNS('.*color.*') FROM skiers WHERE COLUMNS('.*color.*') = 'yellow'; ┌──────────────────┬────────────────────┬─────────────────┐ │ skier_first_name │ skier_helmet_color │ skier_bib_color │ │ varchar │ varchar │ varchar │ ├──────────────────┼────────────────────┼─────────────────┤ │ Heidi │ yellow │ yellow │ └──────────────────┴────────────────────┴─────────────────┘
This is equivalent to combining the candidate columns in a where clause, such as skier_helmet_color='yellow' AND skier_bib_color='yellow'. This is a powerful capability where you can apply the same predicate to a large collection of fields, without the need to list each one individually.

D SELECT CONCAT( LPAD( UPPER( CONCAT_WS(' ', skier_first_name, skier_last_name) ), 20, '>' ), '.' ) AS skier_name FROM skiers; ┌───────────────────────┐ │ skier_name │ │ varchar │ ├───────────────────────┤ │ >>>>>>>>>ALICE SMITH. │ │ >>>>>>>>>>BOB BLAESE. │ │ >>>>>>>>CAROL WILSON. │ │ >>>>>>>>>>>DAN JONES. │ │ >>>>>>>>>ERIN TAYLOR. │ │ >>>>>>FRANK WILLIAMS. │ │ >>>>>>>>GRACE MILLER. │ │ >>>>>>>HEIDI JOHNSON. │ │ >>>>>>>>>>IVAN BROWN. │ │ >>>>>>>>>>JUDY MOORE. │ ├───────────────────────┤ │ 10 rows │ └───────────────────────┘
D SELECT CONCAT_WS(' ', skier_first_name, skier_last_name) .UPPER() .LPAD(20, '>') .CONCAT('.') AS skier_name FROM skiers; ┌───────────────────────┐ │ skier_name │ │ varchar │ ├───────────────────────┤ │ >>>>>>>>>ALICE SMITH. │ │ >>>>>>>>>>BOB BLAESE. │ │ >>>>>>>>CAROL WILSON. │ │ >>>>>>>>>>>DAN JONES. │ │ >>>>>>>>>ERIN TAYLOR. │ │ >>>>>>FRANK WILLIAMS. │ │ >>>>>>>>GRACE MILLER. │ │ >>>>>>>HEIDI JOHNSON. │ │ >>>>>>>>>>IVAN BROWN. │ │ >>>>>>>>>>JUDY MOORE. │ ├───────────────────────┤ │ 10 rows │ └───────────────────────┘

D CREATE UNIQUE INDEX skier_unique ON skiers (skier_first_name);
D INSERT INTO skiers(skier_first_name, skier_helmet_color) SELECT 'Kim' AS skier_first_name, 'blue' AS skier_helmet_color;


D INSERT INTO skiers BY NAME SELECT 'green' AS skier_helmet_color, 'red' AS skier_bib_color, 'Liam' AS skier_first_name;

D INSERT OR REPLACE INTO skiers BY NAME SELECT 'Liam' AS skier_first_name, 'black' AS skier_helmet_color;


D CREATE OR REPLACE TABLE scores AS SELECT * FROM read_csv('skier_scores.csv');
D SELECT df1.skier_first_name, df1.skier_last_name, df2.score FROM skiers AS df1 POSITIONAL JOIN scores AS df2; ┌──────────────────┬─────────────────┬───────┐ │ skier_first_name │ skier_last_name │ score │ │ varchar │ varchar │ int64 │ ├──────────────────┼─────────────────┼───────┤ │ Alice │ Smith │ 8 │ │ Bob │ Blaese │ 9 │ │ Carol │ Wilson │ 4 │ │ Dan │ Jones │ 7 │ │ Erin │ Taylor │ 6 │ │ Frank │ Williams │ 9 │ │ Grace │ Miller │ 9 │ │ Heidi │ Johnson │ 5 │ │ Ivan │ Brown │ 7 │ │ Judy │ Moore │ 8 │ │ Kim │ │ │ │ Liam │ │ │ ├──────────────────┴─────────────────┴───────┤ │ 12 rows 3 columns │ └────────────────────────────────────────────┘
The result of POSITIONAL JOIN gives us a query result that matches the skier to the correct score.

D CREATE OR REPLACE TABLE weather AS SELECT * FROM read_csv('weather.csv', timestampformat='%Y-%m-%d %H:%M:%S');
D SELECT * FROM weather LIMIT 10; ┌─────────────────────┬────────────┬───────┐ │ measurement_time │ wind_speed │ temp │ │ timestamp │ int64 │ int64 │ ├─────────────────────┼────────────┼───────┤ │ 2023-12-01 10:00:00 │ 7 │ -9 │ │ 2023-12-01 11:00:00 │ 19 │ -8 │ │ 2023-12-01 12:00:00 │ 8 │ -6 │ │ 2023-12-01 13:00:00 │ 9 │ -3 │ │ 2023-12-01 14:00:00 │ 10 │ -2 │ │ 2023-12-01 15:00:00 │ 10 │ -2 │ │ 2023-12-01 16:00:00 │ 12 │ -2 │ │ 2023-12-01 17:00:00 │ 12 │ -3 │ │ 2023-12-01 18:00:00 │ 12 │ -3 │ │ 2023-12-01 19:00:00 │ 11 │ -4 │ ├─────────────────────┴────────────┴───────┤ │ 10 rows 3 columns │ └──────────────────────────────────────────┘

D WITH weather_cte AS( SELECT measurement_time, wind_speed, temp, LEAD(measurement_time, 1) OVER ( ORDER BY measurement_time ) AS measurement_end FROM weather ORDER BY measurement_time ) SELECT * FROM weather_cte WHERE TIMESTAMP '2023-12-01 10:01:00' BETWEEN measurement_time AND measurement_end; ┌─────────────────────┬────────────┬───────┬─────────────────────┐ │ measurement_time │ wind_speed │ temp │ measurement_end │ │ timestamp │ int64 │ int64 │ timestamp │ ├─────────────────────┼────────────┼───────┼─────────────────────┤ │ 2023-12-01 10:00:00 │ 7 │ -9 │ 2023-12-01 11:00:00 │ └─────────────────────┴────────────┴───────┴─────────────────────┘

D SELECT * FROM scores AS s ASOF JOIN weather AS w ON s.score_time >= w.measurement_time; ┌─────────────────────┬───────┬─────────────────────┬────────────┬───────┐ │ score_time │ score │ measurement_time │ wind_speed │ temp │ │ timestamp │ int64 │ timestamp │ int64 │ int64 │ ├─────────────────────┼───────┼─────────────────────┼────────────┼───────┤ │ 2023-12-01 10:01:00 │ 8 │ 2023-12-01 10:00:00 │ 7 │ -9 │ │ 2023-12-01 10:42:00 │ 9 │ 2023-12-01 10:00:00 │ 7 │ -9 │ │ 2023-12-01 11:24:00 │ 4 │ 2023-12-01 11:00:00 │ 19 │ -8 │ │ 2023-12-01 14:23:00 │ 7 │ 2023-12-01 14:00:00 │ 10 │ -2 │ │ 2023-12-01 15:22:00 │ 6 │ 2023-12-01 15:00:00 │ 10 │ -2 │ │ 2023-12-01 15:41:00 │ 9 │ 2023-12-01 15:00:00 │ 10 │ -2 │ │ 2023-12-02 10:21:00 │ 9 │ 2023-12-02 10:00:00 │ 8 │ -4 │ │ 2023-12-02 11:01:00 │ 5 │ 2023-12-02 11:00:00 │ 8 │ -2 │ │ 2023-12-02 12:23:00 │ 7 │ 2023-12-02 12:00:00 │ 10 │ -1 │ │ 2023-12-02 13:06:00 │ 8 │ 2023-12-02 13:00:00 │ 10 │ 0 │ ├─────────────────────┴───────┴─────────────────────┴────────────┴───────┤ │ 10 rows 5 columns │ └────────────────────────────────────────────────────────────────────────┘


D SELECT s.*, bar(w.wind_speed, 0, 20, 20) AS wind_bar_plot, w.wind_speed FROM scores AS s ASOF JOIN weather AS w ON s.score_time >= w.measurement_time; ┌─────────────────────┬───────┬─────────────────────┬────────────┐ │ score_time │ score │ wind_bar_plot │ wind_speed │ │ timestamp │ int64 │ varchar │ int64 │ ├─────────────────────┼───────┼─────────────────────┼────────────┤ │ 2023-12-01 10:01:00 │ 8 │ ███████ │ 7 │ │ 2023-12-01 10:42:00 │ 9 │ ███████ │ 7 │ │ 2023-12-01 11:24:00 │ 4 │ ███████████████████ │ 19 │ │ 2023-12-01 14:23:00 │ 7 │ ██████████ │ 10 │ │ 2023-12-01 15:22:00 │ 6 │ ██████████ │ 10 │ │ 2023-12-01 15:41:00 │ 9 │ ██████████ │ 10 │ │ 2023-12-02 10:21:00 │ 9 │ ████████ │ 8 │ │ 2023-12-02 11:01:00 │ 5 │ ████████ │ 8 │ │ 2023-12-02 12:23:00 │ 7 │ ██████████ │ 10 │ │ 2023-12-02 13:06:00 │ 8 │ ██████████ │ 10 │ ├─────────────────────┴───────┴─────────────────────┴────────────┤ │ 10 rows 4 columns │ └────────────────────────────────────────────────────────────────┘

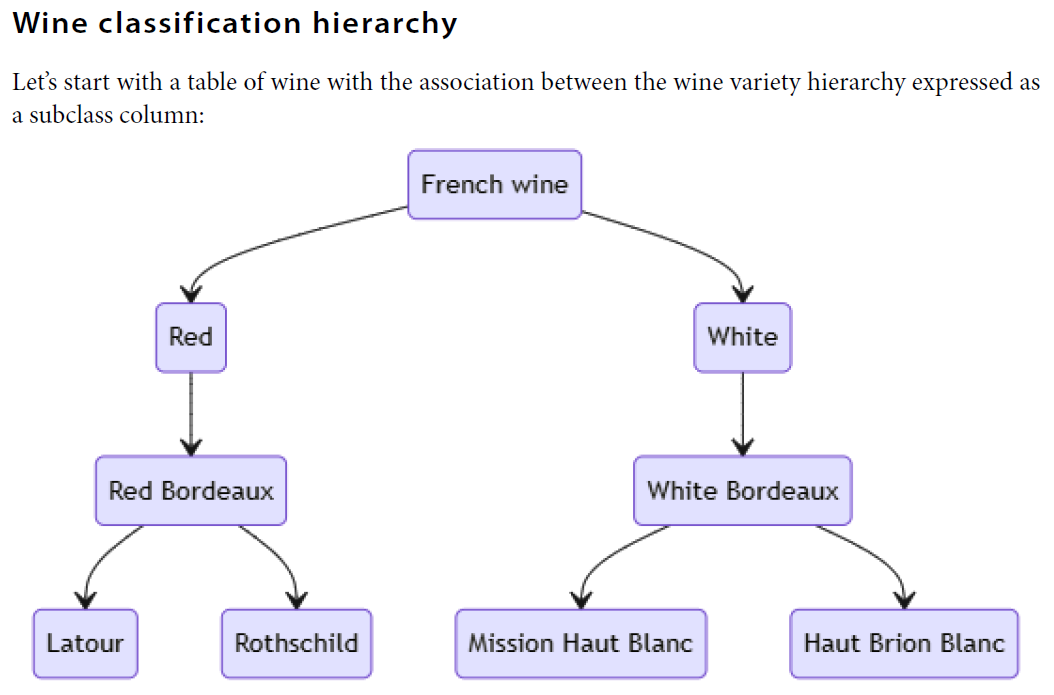
D CREATE OR REPLACE TABLE wines AS SELECT * FROM read_csv('wines.csv');
D SELECT * FROM wines ORDER BY wine_id; ┌─────────┬────────────────────┬──────────────┐ │ wine_id │ wine_name │ sub_class_of │ │ int64 │ varchar │ int64 │ ├─────────┼────────────────────┼──────────────┤ │ 1 │ French wine │ │ │ 2 │ Red │ 1 │ │ 3 │ White │ 1 │ │ 4 │ White Bordeaux │ 3 │ │ 5 │ Mission Haut Blanc │ 4 │ │ 6 │ Haut Brion Blanc │ 4 │ │ 7 │ Red Bordeaux │ 2 │ │ 8 │ Latour │ 7 │ │ 9 │ Rothschild │ 7 │ └─────────┴────────────────────┴──────────────┘

D WITH RECURSIVE wine_hierarchy(wine_id, start_with, wine_path) AS( SELECT wine_id, wine_name, [wine_name] AS wine_path FROM wines WHERE sub_class_of IS NULL UNION ALL SELECT wines.wine_id, wines.wine_name, list_prepend(wines.wine_name, wine_hierarchy.wine_path) FROM wines, wine_hierarchy WHERE wines.sub_class_of = wine_hierarchy.wine_id ) SELECT wine_path FROM wine_hierarchy WHERE start_with = 'Rothschild'; ┌──────────────────────────────────────────────┐ │ wine_path │ │ varchar[] │ ├──────────────────────────────────────────────┤ │ [Rothschild, Red Bordeaux, Red, French wine] │ └──────────────────────────────────────────────┘

D CREATE OR REPLACE MACRO unit_price(price, capacity) AS round(price / capacity, 3);
D CREATE OR REPLACE TABLE wine_prices AS SELECT * FROM read_csv('wine_prices.csv');
D SELECT wine_name, price, capacity_ml FROM wine_prices; ┌───────────────────┬────────┬─────────────┐ │ wine_name │ price │ capacity_ml │ │ varchar │ double │ int64 │ ├───────────────────┼────────┼─────────────┤ │ French Rose │ 16.5 │ 750 │ │ French Pinot Noir │ 17.0 │ 750 │ │ Rose │ 18.4 │ 1000 │ └───────────────────┴────────┴─────────────┘
D SELECT wine_name, price, capacity_ml, unit_price(price, capacity_ml) AS price_ml FROM wine_prices; ┌───────────────────┬────────┬─────────────┬──────────┐ │ wine_name │ price │ capacity_ml │ price_ml │ │ varchar │ double │ int64 │ double │ ├───────────────────┼────────┼─────────────┼──────────┤ │ French Rose │ 16.5 │ 750 │ 0.022 │ │ French Pinot Noir │ 17.0 │ 750 │ 0.023 │ │ Rose │ 18.4 │ 1000 │ 0.018 │ └───────────────────┴────────┴─────────────┴──────────┘
The calculation for unit_price has been applied to each column. Macros can be considered a useful mechanism for encapsulation logic that can be shared.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2024-01-16 Redis - List Use Cases
2024-01-16 Redis - HyperLogLog Use Cases
2024-01-16 Redis - SORT