

Requirements:

duckdb emoji ibis-framework ibis-framework[duckdb] jupysql jupyter-lsp jupyterlab pandas plotly polars-lts-cpu pyarrow sqlparse


pi_relation = duckdb.sql("SELECT pi() AS pi") type(pi_relation) # duckdb.duckdb.DuckDBPyRelation

pi_relation.show()
┌───────────────────┐ │ pi │ │ double │ ├───────────────────┤ │ 3.141592653589793 │ └───────────────────┘
pi_relation
┌───────────────────┐ │ pi │ │ double │ ├───────────────────┤ │ 3.141592653589793 │ └───────────────────┘
duckdb.sql( """ SELECT * FROM read_csv('data/C08/Seattle_Pet_Licenses.csv') """ )
As our call to duckdb.sql() is the only expression in this cell, it is evaluated, and the resulting relation object is displayed:
┌────────────────────┬────────────────┬───────────────┬─────────┬──────────────────────┬─────────────────┬──────────┐ │ License Issue Date │ License Number │ Animal's Name │ Species │ Primary Breed │ Secondary Breed │ ZIP Code │ │ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │ ├────────────────────┼────────────────┼───────────────┼─────────┼──────────────────────┼─────────────────┼──────────┤ │ December 18 2015 │ S107948 │ Zen │ Cat │ Domestic Longhair │ Mix │ 98117 │ │ June 14 2016 │ S116503 │ Misty │ Cat │ Siberian │ NULL │ 98117 │ │ August 04 2016 │ S119301 │ Lyra │ Cat │ Mix │ NULL │ 98121 │ │ February 13 2019 │ 962273 │ Veronica │ Cat │ Domestic Longhair │ NULL │ 98107 │ │ August 10 2019 │ S133113 │ Spider │ Cat │ LaPerm │ NULL │ 98115 │ │ November 21 2019 │ 8002549 │ Maxx │ Cat │ American Shorthair │ NULL │ 98125 │ │ May 24 2020 │ S142869 │ Mickey │ Cat │ Domestic Longhair │ NULL │ 98126 │ │ July 03 2020 │ S112835 │ Diamond │ Cat │ Domestic Shorthair │ Mix │ 98103 │ │ July 21 2020 │ S131986 │ Nacho │ Cat │ Domestic Shorthair │ Mix │ 98126 │ │ August 18 2020 │ 8019541 │ Gracie │ Cat │ Domestic Medium Hair │ Mix │ 98133 │ │ · │ · │ · │ · │ · │ · │ · │ │ · │ · │ · │ · │ · │ · │ · │ │ · │ · │ · │ · │ · │ · │ · │ │ November 22 2023 │ S148106 │ Gibbs │ Cat │ Domestic Shorthair │ Mix │ 98116 │ │ November 22 2023 │ 8042587 │ Barry │ Cat │ American Shorthair │ Mix │ 98109 │ │ November 22 2023 │ 8042588 │ Penny │ Cat │ American Shorthair │ Mix │ 98109 │ │ November 22 2023 │ 8050533 │ Sabine │ Cat │ Domestic Medium Hair │ York Chocolate │ 98144 │ │ November 22 2023 │ 8050534 │ Milo │ Cat │ Domestic Medium Hair │ Mix │ 98144 │ │ November 22 2023 │ S137987 │ Spike │ Cat │ Domestic Medium Hair │ NULL │ 98117 │ │ November 22 2023 │ S137986 │ Scout │ Cat │ Domestic Shorthair │ NULL │ 98117 │ │ November 22 2023 │ 8013084 │ Honeybee │ Cat │ American Shorthair │ Mix │ 98106 │ │ November 22 2023 │ S157559 │ Bug │ Cat │ Ragdoll │ Siamese │ 98144 │ │ November 22 2023 │ 8042668 │ Beerus │ Cat │ Domestic Shorthair │ Mix │ 98125 │ ├────────────────────┴────────────────┴───────────────┴─────────┴──────────────────────┴─────────────────┴──────────┤ │ ? rows (>9999 rows, 20 shown) 7 columns │ └───────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘

pets_csv_relation = duckdb.read_csv( "data/C08/Seattle_Pet_Licenses.csv" )
pets_csv_relation.types # [VARCHAR, VARCHAR, VARCHAR, VARCHAR, VARCHAR, VARCHAR, VARCHAR]

pets_csv_relation = duckdb.read_csv( "data/C08/Seattle_Pet_Licenses.csv", dtype={"License Issue Date": "DATE"}, date_format="%B %d %Y", ) pets_csv_relation.types # [DATE, VARCHAR, VARCHAR, VARCHAR, VARCHAR, VARCHAR, VARCHAR]
pets_csv_relation.limit(5)
┌────────────────────┬────────────────┬───────────────┬─────────┬───────────────────┬─────────────────┬──────────┐ │ License Issue Date │ License Number │ Animal's Name │ Species │ Primary Breed │ Secondary Breed │ ZIP Code │ │ date │ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │ ├────────────────────┼────────────────┼───────────────┼─────────┼───────────────────┼─────────────────┼──────────┤ │ 2015-12-18 │ S107948 │ Zen │ Cat │ Domestic Longhair │ Mix │ 98117 │ │ 2016-06-14 │ S116503 │ Misty │ Cat │ Siberian │ NULL │ 98117 │ │ 2016-08-04 │ S119301 │ Lyra │ Cat │ Mix │ NULL │ 98121 │ │ 2019-02-13 │ 962273 │ Veronica │ Cat │ Domestic Longhair │ NULL │ 98107 │ │ 2019-08-10 │ S133113 │ Spider │ Cat │ LaPerm │ NULL │ 98115 │ └────────────────────┴────────────────┴───────────────┴─────────┴───────────────────┴─────────────────┴──────────┘
print(pets_csv_relation.sql_query())
SELECT * FROM read_csv_auto( ['data/C08/Seattle_Pet_Licenses.csv'], (auto_detect = false), (delim = ','), ("quote" = '"'), (null_padding = false), ("escape" = '"'), (dateformat = '%B %d %Y'), (all_varchar = false), ( "columns" = { 'License Issue Date': 'DATE', 'License Number': 'VARCHAR', 'Animal' s Name ': ' VARCHAR ', ' Species ': ' VARCHAR ', ' Primary Breed ': ' VARCHAR ', ' Secondary Breed ': ' VARCHAR ', ' ZIP Code ': ' VARCHAR ' } ), (max_line_size = 2097152), (normalize_names = false), ("header" = true), ("skip" = 0), ("parallel" = true), (maximum_line_size = 2097152) )

pets_csv_relation.to_table("seattle_pets_dataset")
duckdb.sql("SHOW TABLES")
┌──────────────────────┐ │ name │ │ varchar │ ├──────────────────────┤ │ seattle_pets_dataset │ └──────────────────────┘
Now, we can make a relation from this table we’ve just created using the DuckDBPyConnection.table() method:
pets_table_relation = duckdb.table("seattle_pets_dataset")
We can now use this relation to work with this table via the Relational API. For example, the DuckDBPyRelation.describe() method is equivalent to issuing a SQL DESCRIBE statement:
pets_table_relation.describe()
┌─────────┬────────────────────┬────────────────┬────────────────────┬─────────┬───────────────────┬───────────────────┬──────────┐ │ aggr │ License Issue Date │ License Number │ Animal's Name │ Species │ Primary Breed │ Secondary Breed │ ZIP Code │ │ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │ ├─────────┼────────────────────┼────────────────┼────────────────────┼─────────┼───────────────────┼───────────────────┼──────────┤ │ count │ 42567 │ 42567 │ 42526 │ 42567 │ 42567 │ 28373 │ 42440 │ │ mean │ NULL │ NULL │ NULL │ NULL │ NULL │ NULL │ NULL │ │ stddev │ NULL │ NULL │ NULL │ NULL │ NULL │ NULL │ NULL │ │ min │ 2015-10-21 │ 015352 │ !zzy │ Cat │ Abruzzese Mastiff │ Abruzzese Mastiff │ 22308 │ │ max │ 2024-04-05 │ s124879 │ “Dr.” Noah Pickles │ Pig │ Xoloitzcuintli │ York Chocolate │ V5J 1P8 │ │ median │ NULL │ NULL │ NULL │ NULL │ NULL │ NULL │ NULL │ └─────────┴────────────────────┴────────────────┴────────────────────┴─────────┴───────────────────┴───────────────────┴──────────┘
duckdb.sql("DESCRIBE TABLE seattle_pets_dataset")
┌────────────────────┬─────────────┬─────────┬─────────┬─────────┬─────────┐ │ column_name │ column_type │ null │ key │ default │ extra │ │ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │ ├────────────────────┼─────────────┼─────────┼─────────┼─────────┼─────────┤ │ License Issue Date │ DATE │ YES │ NULL │ NULL │ NULL │ │ License Number │ VARCHAR │ YES │ NULL │ NULL │ NULL │ │ Animal's Name │ VARCHAR │ YES │ NULL │ NULL │ NULL │ │ Species │ VARCHAR │ YES │ NULL │ NULL │ NULL │ │ Primary Breed │ VARCHAR │ YES │ NULL │ NULL │ NULL │ │ Secondary Breed │ VARCHAR │ YES │ NULL │ NULL │ NULL │ │ ZIP Code │ VARCHAR │ YES │ NULL │ NULL │ NULL │ └────────────────────┴─────────────┴─────────┴─────────┴─────────┴─────────┘
pets_table_relation.count("*")
┌──────────────┐ │ count_star() │ │ int64 │ ├──────────────┤ │ 42567 │ └──────────────┘
duckdb.sql("SELECT count(*) FROM seattle_pets_dataset")
┌──────────────┐ │ count_star() │ │ int64 │ ├──────────────┤ │ 42567 │ └──────────────┘
duckdb.sql("DROP TABLE seattle_pets_dataset")

pets_cleaned_relation = duckdb.sql( """ SELECT "License Issue Date" AS issue_date, "Animal's Name" AS pet_name, "Species" AS species, "Primary Breed" AS breed FROM pets_csv_relation """ ) pets_cleaned_relation.limit(5)
┌────────────┬──────────┬─────────┬───────────────────┐ │ issue_date │ pet_name │ species │ breed │ │ date │ varchar │ varchar │ varchar │ ├────────────┼──────────┼─────────┼───────────────────┤ │ 2015-12-18 │ Zen │ Cat │ Domestic Longhair │ │ 2016-06-14 │ Misty │ Cat │ Siberian │ │ 2016-08-04 │ Lyra │ Cat │ Mix │ │ 2019-02-13 │ Veronica │ Cat │ Domestic Longhair │ │ 2019-08-10 │ Spider │ Cat │ LaPerm │ └────────────┴──────────┴─────────┴───────────────────┘
min_max_relation = duckdb.sql( """ SELECT min(issue_date), max(issue_date) FROM pets_cleaned_relation """ ) min_max_relation
┌─────────────────┬─────────────────┐ │ min(issue_date) │ max(issue_date) │ │ date │ date │ ├─────────────────┼─────────────────┤ │ 2015-10-21 │ 2024-04-05 │ └─────────────────┴─────────────────┘
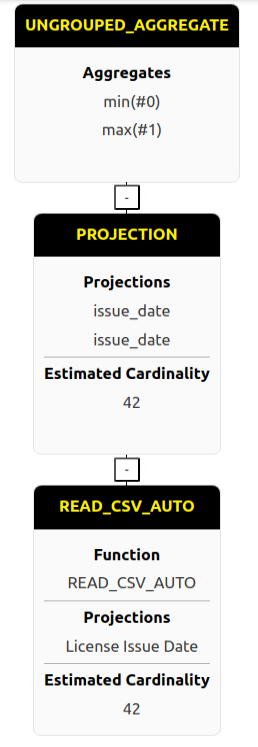
print(min_max_relation.explain())


duckdb.sql( """ SELECT * FROM pets_cleaned_relation WHERE species = 'Pig' """ )

pets_cleaned_relation.filter("species = 'Pig'")
Same result:
┌────────────┬──────────┬─────────┬─────────────┐ │ issue_date │ pet_name │ species │ breed │ │ date │ varchar │ varchar │ varchar │ ├────────────┼──────────┼─────────┼─────────────┤ │ 2022-11-03 │ Millie │ Pig │ Pot-Bellied │ │ 2023-06-01 │ Calvin │ Pig │ Pot-Bellied │ └────────────┴──────────┴─────────┴─────────────┘

from duckdb import ColumnExpression, ConstantExpression species_col = ColumnExpression("species") pig_constant = ConstantExpression("Pig") pets_cleaned_relation.filter(species_col == pig_constant)
Got the same result as above.
pets_cleaned_relation.filter( "species = 'Cat' AND pet_name = 'Leeloo'" )
name_col = ColumnExpression("pet_name") is_cat = species_col == ConstantExpression("Cat") is_leeloo = name_col == ConstantExpression("Leeloo") pets_cleaned_relation.filter(is_cat & is_leeloo)
Same result:
┌────────────┬──────────┬─────────┬────────────────────┐ │ issue_date │ pet_name │ species │ breed │ │ date │ varchar │ varchar │ varchar │ ├────────────┼──────────┼─────────┼────────────────────┤ │ 2022-04-13 │ Leeloo │ Cat │ Domestic Shorthair │ │ 2022-08-15 │ Leeloo │ Cat │ Domestic Shorthair │ │ 2022-08-21 │ Leeloo │ Cat │ Domestic Shorthair │ │ 2022-10-20 │ Leeloo │ Cat │ American Shorthair │ └────────────┴──────────┴─────────┴────────────────────┘
pets_cleaned_relation.filter(is_cat).limit(5)
num_cat_names_rel = ( pets_cleaned_relation .filter(is_cat) .select("pet_name") .distinct() .count("*") ) num_cat_names_rel
alt_num_cat_names_rel = ( pets_cleaned_relation .filter(is_cat) .unique("pet_name") .count("*") ) alt_num_cat_names_rel
Same result:
┌──────────────┐ │ count_star() │ │ int64 │ ├──────────────┤ │ 6321 │ └──────────────┘
num_unique_cats_sql = alt_num_cat_names_rel.sql_query() print(num_unique_cats_sql)
SELECT count_star() FROM (SELECT DISTINCT pet_name FROM (SELECT * FROM (WITH pets_csv_relation AS (SELECT * FROM (SELECT * FROM read_csv_auto(['data/C08/Seattle_Pet_Licenses.csv'], (auto_detect = false), (delim = ','), ("quote" = '"'), (null_padding = false), ("escape" = '"'), (dateformat = '%B %d %Y'), (all_varchar = false), ("columns" = {'License Issue Date': 'DATE', 'License Number': 'VARCHAR', 'Animal's Name': 'VARCHAR', 'Species': 'VARCHAR', 'Primary Breed': 'VARCHAR', 'Secondary Breed': 'VARCHAR', 'ZIP Code': 'VARCHAR'}), (max_line_size = 2097152), (normalize_names = false), ("header" = true), ("skip" = 0), ("parallel" = true), (maximum_line_size = 2097152))))SELECT "License Issue Date" AS issue_date, "Animal's Name" AS pet_name, Species AS species, "Primary Breed" AS breed FROM pets_csv_relation) AS unnamed_relation_a6705feef22a1dde WHERE (species = 'Cat')) AS unnamed_relation_a6705feef22a1dde) AS unnamed_relation_a6705feef22a1dde GROUP BY ALL
import sqlparse formatted_sql = sqlparse.format( num_unique_cats_sql, reindent=True ) print(formatted_sql)
SELECT count_star() FROM ( SELECT DISTINCT pet_name FROM ( SELECT * FROM ( WITH pets_csv_relation AS ( SELECT * FROM ( SELECT * FROM read_csv_auto( ['data/C08/Seattle_Pet_Licenses.csv'], (auto_detect = false), (delim = ','), ("quote" = '"'), (null_padding = false), ("escape" = '"'), (dateformat = '%B %d %Y'), (all_varchar = false), ( "columns" = { 'License Issue Date': 'DATE', 'License Number': 'VARCHAR', 'Animal' s Name ': ' VARCHAR ', ' Species ': ' VARCHAR ', ' Primary Breed ': ' VARCHAR ', ' Secondary Breed ': ' VARCHAR ', ' ZIP Code ': ' VARCHAR '}), (max_line_size = 2097152), (normalize_names = false), ("header" = true), ("skip" = 0), ("parallel" = true), (maximum_line_size = 2097152)))) SELECT "License Issue Date" AS issue_date, "Animal' s Name " AS pet_name, Species AS species, " Primary Breed " AS breed FROM pets_csv_relation) AS unnamed_relation_a6705feef22a1dde WHERE (species = 'Cat')) AS unnamed_relation_a6705feef22a1dde) AS unnamed_relation_a6705feef22a1dde GROUP BY ALL
duckdb.sql( """ SELECT *, length(pet_name) AS name_length FROM pets_cleaned_relation ORDER BY name_length DESC LIMIT 10 """ )
from duckdb import ColumnExpression, FunctionExpression, StarExpression star = StarExpression() name_col = ColumnExpression("pet_name") name_length_col = FunctionExpression("length", name_col).alias("name_length") name_length_sort = ColumnExpression("name_length").desc() longest_names_relation = ( pets_cleaned_relation .select(star, name_length_col) .sort(name_length_sort) .limit(10) ) longest_names_relation
Same result:
┌────────────┬────────────────────────────────────────────────────┬─────────┬────────────────────────────┬─────────────┐ │ issue_date │ pet_name │ species │ breed │ name_length │ │ date │ varchar │ varchar │ varchar │ int64 │ ├────────────┼────────────────────────────────────────────────────┼─────────┼────────────────────────────┼─────────────┤ │ 2023-08-04 │ Nuit Ahathoor Hecate Sappho Jezebel Lilith Crowley │ Dog │ Chihuahua, Short Coat │ 50 │ │ 2024-02-10 │ Lady Kassandra Yu Countess of Wallingford DBE │ Dog │ Border Collie │ 45 │ │ 2024-02-01 │ KingKing SirBeastmodeEsquire Stella Jr Sr II │ Dog │ Terrier, American Pit Bull │ 44 │ │ 2024-01-09 │ Alyeska Juniper Cocoa Luna Taber O'Kelley │ Cat │ Domestic Shorthair │ 41 │ │ 2024-01-22 │ WINTERDAWG PRINCESS BUTTERCUP FROSTY JANE │ Dog │ Alaskan Malamute │ 41 │ │ 2022-12-01 │ Cascade Mountain's Out of a Dream (BRIA) │ Dog │ Retriever, Golden │ 40 │ │ 2023-11-01 │ Houlene "Hula" Elizabeth Honeybee Jacobs │ Dog │ Coonhound, Bluetick │ 40 │ │ 2023-02-10 │ Agnes "Aggie" Snowball Pineapple Clark │ Dog │ Retriever, Labrador │ 38 │ │ 2024-02-01 │ Snapdragon Caylee Reid Gramila O'Keefe │ Dog │ Terrier, Jack Russell │ 38 │ │ 2023-02-07 │ Moose Donut Franswa Cuddlewuddle Post │ Dog │ Bulldog, French │ 37 │ ├────────────┴────────────────────────────────────────────────────┴─────────┴────────────────────────────┴─────────────┤ │ 10 rows 5 columns │ └──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘


pets_cleaned_relation.write_csv("seattle_pets.csv") pets_cleaned_relation.write_parquet("seattle_pets.parquet")
duckdb.sql("COPY pets_cleaned_relation TO 'seattle_pets.csv'") duckdb.sql("COPY pets_cleaned_relation TO 'seattle_pets.parquet'")
As we write this, there is no DuckDBPyRelation.write_json() Relational API method; however, you can export to JSON files using SQL:
duckdb.sql("COPY pets_cleaned_relation TO 'seattle_pets.json'")

conn = duckdb.connect("seattle_pets.db") conn.read_parquet("seattle_pets.parquet").to_table("pets") conn.sql("SHOW TABLES")
┌─────────┐ │ name │ │ varchar │ ├─────────┤ │ pets │ └─────────┘
conn.table("pets").count("*")
┌──────────────┐ │ count_star() │ │ int64 │ ├──────────────┤ │ 42567 │ └──────────────┘
new_dog1 = (
"2024-05-19",
"Monty",
"Dog",
"Border Collie",
)
conn.table("pets").insert(new_dog1)

new_dog2 = ( "2024-05-19", "Pixie", "Dog", "Australian Kelpie", ) new_dog_rel = conn.values(new_dog2) new_dog_rel.insert_into("pets")
conn.table("pets").filter("issue_date = '2024-05-19'")
┌────────────┬──────────┬─────────┬───────────────────┐ │ issue_date │ pet_name │ species │ breed │ │ date │ varchar │ varchar │ varchar │ ├────────────┼──────────┼─────────┼───────────────────┤ │ 2024-05-19 │ Monty │ Dog │ Border Collie │ │ 2024-05-19 │ Pixie │ Dog │ Australian Kelpie │ └────────────┴──────────┴─────────┴───────────────────┘
conn.close()


conn = duckdb.connect()

conn.execute(
"""
CREATE OR REPLACE TABLE seattle_pets AS
SELECT * FROM 'seattle_pets.parquet'
"""
)
conn.fetchone() # (42567,) conn.fetchmany() # [] conn.fetchall() # []
conn.execute("SELECT * FROM seattle_pets")
conn.fetchone() # (datetime.date(2015, 12, 18), 'Zen', 'Cat', 'Domestic Longhair') conn.fetchmany() # [(datetime.date(2016, 6, 14), 'Misty', 'Cat', 'Siberian')] conn.fetchall() # [(datetime.date(2016, 8, 4), 'Lyra', 'Cat', 'Mix'), # (datetime.date(2019, 2, 13), 'Veronica', 'Cat', 'Domestic Longhair'), # (datetime.date(2019, 8, 10), 'Spider', 'Cat', 'LaPerm'), # (datetime.date(2019, 11, 21), 'Maxx', 'Cat', 'American Shorthair'), # (datetime.date(2020, 5, 24), 'Mickey', 'Cat', 'Domestic Longhair'), # ......
conn.description
[('issue_date', 'Date', None, None, None, None, None),
('pet_name', 'STRING', None, None, None, None, None),
('species', 'STRING', None, None, None, None, None),
('breed', 'STRING', None, None, None, None, None)]
[conn.fetchone() for i in range(3)] # [None, None, None]
conn.execute("SELECT * FROM seattle_pets") [conn.fetchone() for i in range(3)]
[(datetime.date(2015, 12, 18), 'Zen', 'Cat', 'Domestic Longhair'), (datetime.date(2016, 6, 14), 'Misty', 'Cat', 'Siberian'), (datetime.date(2016, 8, 4), 'Lyra', 'Cat', 'Mix')]
conn.fetchmany(3)
[(datetime.date(2019, 2, 13), 'Veronica', 'Cat', 'Domestic Longhair'), (datetime.date(2019, 8, 10), 'Spider', 'Cat', 'LaPerm'), (datetime.date(2019, 11, 21), 'Maxx', 'Cat', 'American Shorthair')]
rest_rows = conn.fetchall() len(rest_rows) # 42561

import datetime new_pet1 = ( datetime.date.today(), "Ned", "Dog", "Border Collie", ) conn.execute("INSERT INTO seattle_pets VALUES (?, ?, ?, ?)", parameters=new_pet1)
new_pet2 = { "name": "Simon", "species": "Cat", "breed": "Bombay", "issue_date": datetime.date.today(), } conn.execute( """ INSERT INTO seattle_pets VALUES ($issue_date, $name, $species, $breed) """, new_pet2, )
conn.execute( """ SELECT * FROM seattle_pets WHERE issue_date = ?; """, [datetime.date.today()], ).fetchall()
[(datetime.date(2025, 1, 15), 'Ned', 'Dog', 'Border Collie'), (datetime.date(2025, 1, 15), 'Simon', 'Cat', 'Bombay')]

conn.execute("COPY seattle_pets TO 'seattle_pets_updates.csv'") conn.execute("COPY seattle_pets TO 'seattle_pets_updates.parquet'")

conn.close()

conn = duckdb.connect()
new_conn = conn.cursor()




import pandas as pd pets_df = pd.read_parquet("seattle_pets.parquet") duckdb.sql("SELECT * FROM pets_df USING SAMPLE 1")
┌────────────┬──────────┬─────────┬─────────────────────┐ │ issue_date │ pet_name │ species │ breed │ │ date │ varchar │ varchar │ varchar │ ├────────────┼──────────┼─────────┼─────────────────────┤ │ 2023-03-20 │ Winnie │ Dog │ Retriever, Labrador │ └────────────┴──────────┴─────────┴─────────────────────┘

pets_dict = { "seattle": pd.read_parquet("seattle_pets.parquet") } duckdb.register("pets_view", pets_dict["seattle"]) duckdb.sql("SELECT * FROM pets_view USING SAMPLE 1")
┌────────────┬──────────┬─────────┬─────────┐ │ issue_date │ pet_name │ species │ breed │ │ date │ varchar │ varchar │ varchar │ ├────────────┼──────────┼─────────┼─────────┤ │ 2022-09-03 │ Scooter │ Dog │ Pug │ └────────────┴──────────┴─────────┴─────────┘

pets_df = pd.read_parquet("seattle_pets.parquet") duckdb.sql( """ CREATE OR REPLACE TABLE pets_table_from_df AS SELECT * FROM pets_df """ ) duckdb.sql("SELECT * FROM pets_table_from_df USING SAMPLE 1")
┌────────────┬──────────┬─────────┬─────────────────────┐ │ issue_date │ pet_name │ species │ breed │ │ date │ varchar │ varchar │ varchar │ ├────────────┼──────────┼─────────┼─────────────────────┤ │ 2022-07-08 │ Cleo │ Dog │ Australian Shepherd │ └────────────┴──────────┴─────────┴─────────────────────┘

Note that this is not an exhaustive list; see the DuckDB documentation for reference (https://duckdb.org/docs/api/python/result_conversion).
conn = duckdb.connect() seattle_pets = conn.from_parquet("seattle_pets.parquet") pandas_df = seattle_pets.df() pandas_df[ pandas_df["species"] == "Dog" ].value_counts("breed")[:5]
breed Retriever, Labrador 3034 Retriever, Golden 1488 Chihuahua, Short Coat 1443 German Shepherd 954 Poodle, Miniature 846 Name: count, dtype: int64
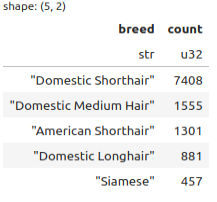
import polars as pl polars_df = seattle_pets.pl() polars_df.filter( pl.col("species") == "Cat" )["breed"].value_counts(sort=True)[:5]

conn = duckdb.connect() conn.execute("SELECT * FROM 'seattle_pets.parquet'") pets_table = conn.arrow() pets_table.schema
issue_date: date32[day] pet_name: string species: string breed: string

varchar_type = duckdb.typing.VARCHAR
bigint_type = duckdb.typing.BIGINT

varchar_type = duckdb.typing.DuckDBPyType(str)
bigint_type = duckdb.typing.DuckDBPyType(int)

import datetime duckdb.values( [ 10, 1_000_000, 0.95, "hello string", b"hello bytes", True, datetime.date.today(), None, ] )
┌───────┬─────────┬────────┬──────────────┬─────────────┬─────────┬────────────┬───────┐ │ col0 │ col1 │ col2 │ col3 │ col4 │ col5 │ col6 │ col7 │ │ int32 │ int32 │ double │ varchar │ blob │ boolean │ date │ int32 │ ├───────┼─────────┼────────┼──────────────┼─────────────┼─────────┼────────────┼───────┤ │ 10 │ 1000000 │ 0.95 │ hello string │ hello bytes │ true │ 2025-01-16 │ NULL │ └───────┴─────────┴────────┴──────────────┴─────────────┴─────────┴────────────┴───────┘
duckdb.values( [ (1, 2), ["hello", "world"], {"key1": 10, "key2": "quack!"} ] )
┌─────────┬────────────────┬────────────────────────────────────┐
│ col0 │ col1 │ col2 │
│ int32[] │ varchar[] │ struct(key1 integer, key2 varchar) │
├─────────┼────────────────┼────────────────────────────────────┤
│ [1, 2] │ [hello, world] │ {'key1': 10, 'key2': quack!} │
└─────────┴────────────────┴────────────────────────────────────┘

import emoji def emojify(species): """Converts a string into a single emoji.""" emoji_str = emoji.emojize(f":{species.lower()}:") if emoji.is_emoji(emoji_str): return emoji_str return None
emojify("goat")
'🐐'

duckdb.create_function( "emojify", emojify, [duckdb.typing.VARCHAR], duckdb.typing.VARCHAR )
/tmp/ipykernel_4851/4183955593.py:1: DeprecationWarning: numpy.core is deprecated and has been renamed to numpy._core. The numpy._core namespace contains private NumPy internals and its use is discouraged, as NumPy internals can change without warning in any release. In practice, most real-world usage of numpy.core is to access functionality in the public NumPy API. If that is the case, use the public NumPy API. If not, you are using NumPy internals. If you would still like to access an internal attribute, use numpy._core.multiarray. duckdb.create_function(
With the emoji function registered, we can now use it in a SQL query as if it were a DuckDB SQL function.
duckdb.sql( """ SELECT *, emojify(species) AS emoji FROM 'seattle_pets_updates.parquet' USING SAMPLE 10 """ )
┌────────────┬──────────┬─────────┬──────────────────────────────────────────────┬─────────┐ │ issue_date │ pet_name │ species │ breed │ emoji │ │ date │ varchar │ varchar │ varchar │ varchar │ ├────────────┼──────────┼─────────┼──────────────────────────────────────────────┼─────────┤ │ 2022-08-21 │ Bruce │ Dog │ Lhasa Apso │ 🐕 │ │ 2022-07-01 │ Nico │ Dog │ Terrier, Fox, Wire │ 🐕 │ │ 2022-11-08 │ Heera │ Cat │ Mix │ 🐈 │ │ 2023-07-24 │ Daisy │ Dog │ Mixed Breed, Large (over 44 lbs fully grown) │ 🐕 │ │ 2023-08-07 │ Ziva │ Dog │ Poodle, Standard │ 🐕 │ │ 2023-04-13 │ Winston │ Dog │ Welsh Corgi, Pembroke │ 🐕 │ │ 2023-01-12 │ Jamie │ Cat │ American Shorthair │ 🐈 │ │ 2022-04-27 │ Aurora │ Cat │ Domestic Shorthair │ 🐈 │ │ 2022-04-19 │ Josie │ Cat │ Domestic Longhair │ 🐈 │ │ 2023-02-12 │ Pepper │ Dog │ Terrier │ 🐕 │ ├────────────┴──────────┴─────────┴──────────────────────────────────────────────┴─────────┤ │ 10 rows 5 columns │ └──────────────────────────────────────────────────────────────────────────────────────────┘
In order to remove the UDF from the database, we just call the remove_function() method:
duckdb.remove_function("emojify")

duckdb.create_function("emojify", emojify, [str], str)

def emojify(species: str) -> str: """Converts a string into a single emoji.""" emoji_str = emoji.emojize(f":{species.lower()}:") if emoji.is_emoji(emoji_str): return emoji_str return None duckdb.remove_function("emojify") duckdb.create_function("emojify", emojify)

from duckdb import ConversionException try: duckdb.execute("SELECT '5,000'::INTEGER").fetchall() except ConversionException as error: print(error) # handle exception...
Conversion Error: Could not convert string '5,000' to INT32
LINE 1: SELECT '5,000'::INTEGER
^
from duckdb import CatalogException try: duckdb.sql("SELECT * from imaginary_table") except CatalogException as error: print(error) # handle exception...
Catalog Error: Table with name imaginary_table does not exist! Did you mean "pragma_database_list"?



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2024-01-15 Redis - Serialize and Deserialize