

 block range index, BRIN
block range index, BRIN
 adaptive radix tree, ART
adaptive radix tree, ART


To download the necessary dataset for this project, please follow these instructions:
1. Go to https://www.kaggle.com/datasets/mohamedbakhet/amazon-books-reviews.
2. Click on the Download button.
3. Kaggle will prompt you to sign in or to register. If you do not have a Kaggle account, you can register for one.
4. Upon signing in, the download will start automatically.
5. After the download is complete, unzip the archive zip into the chapter_04 directory.
Once downloaded and unzipped, you should have two data files called Books_rating.csv and books_data.csv.

D CREATE OR REPLACE SEQUENCE book_reviews_seq;
Once created, we can use the book_reviews_seq sequence in our next data preparation step.
In the below query, we’re using DuckDB to both read the source CSV file and copy it to a local file using a single COPY command that has a nested query:

D COPY ( SELECT nextval('book_reviews_seq') AS book_reviews_id, Id AS book_id, Title AS book_title, Price AS price, User_id AS user_id, region, to_timestamp("review/time") AS review_time, cast(datepart('year', review_time) AS VARCHAR) AS review_year, "review/summary" AS review_summary, "review/text" AS review_text, "review/score" AS review_score FROM read_csv('Books_rating.csv') CROSS JOIN ( SELECT range, CASE WHEN range = 0 THEN 'JP' ELSE 'US' END AS region FROM range (0, 2) ) ) TO 'book_reviews.parquet'; 100% ▕████████████████████████████████████████████████████████████▏

D CREATE OR REPLACE TABLE book_reviews AS SELECT * FROM read_parquet('book_reviews.parquet'); 100% ▕████████████████████████████████████████████████████████████▏

D DESCRIBE SELECT * FROM (SUMMARIZE book_reviews); ┌─────────────────┬──────────────┬─────────┬─────────┬─────────┬─────────┐ │ column_name │ column_type │ null │ key │ default │ extra │ │ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │ ├─────────────────┼──────────────┼─────────┼─────────┼─────────┼─────────┤ │ column_name │ VARCHAR │ YES │ │ │ │ │ column_type │ VARCHAR │ YES │ │ │ │ │ min │ VARCHAR │ YES │ │ │ │ │ max │ VARCHAR │ YES │ │ │ │ │ approx_unique │ BIGINT │ YES │ │ │ │ │ avg │ VARCHAR │ YES │ │ │ │ │ std │ VARCHAR │ YES │ │ │ │ │ q25 │ VARCHAR │ YES │ │ │ │ │ q50 │ VARCHAR │ YES │ │ │ │ │ q75 │ VARCHAR │ YES │ │ │ │ │ count │ BIGINT │ YES │ │ │ │ │ null_percentage │ DECIMAL(9,2) │ YES │ │ │ │ ├─────────────────┴──────────────┴─────────┴─────────┴─────────┴─────────┤ │ 12 rows 6 columns │ └────────────────────────────────────────────────────────────────────────┘
D SELECT column_name, column_type, min, max, count, approx_unique FROM (SUMMARIZE book_reviews); 100% ▕████████████████████████████████████████████████████████████▏ ┌─────────────────┬──────────────────────┬──────────────────────┬──────────────────────────────────────────────────────────┬─────────┬───────────────┐ │ column_name │ column_type │ min │ max │ count │ approx_unique │ │ varchar │ varchar │ varchar │ varchar │ int64 │ int64 │ ├─────────────────┼──────────────────────┼──────────────────────┼──────────────────────────────────────────────────────────┼─────────┼───────────────┤ │ book_reviews_id │ BIGINT │ 1 │ 6000000 │ 6000000 │ 5956397 │ │ book_id │ VARCHAR │ 0001047604 │ B0064P287I │ 6000000 │ 195123 │ │ book_title │ VARCHAR │ " Film technique, … │ you can do anything with crepes │ 6000000 │ 200024 │ │ price │ DOUBLE │ 1.0 │ 995.0 │ 6000000 │ 5180 │ │ user_id │ VARCHAR │ A00109803PZJ91RLT7… │ AZZZZW74AAX75 │ 6000000 │ 1182731 │ │ region │ VARCHAR │ JP │ US │ 6000000 │ 2 │ │ review_time │ TIMESTAMP WITH TIM… │ 1970-01-01 07:59:5… │ 2013-03-04 08:00:00+08 │ 6000000 │ 6590 │ │ review_year │ VARCHAR │ 1970 │ 2013 │ 6000000 │ 21 │ │ review_summary │ VARCHAR │ ! │ ~~~~~~~~~~~~~~~~~~~~~~~~~~ │ 6000000 │ 1433008 │ │ review_text │ VARCHAR │ \17The Tao of Muha… │ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~… │ 6000000 │ 1632331 │ │ review_score │ DOUBLE │ 1.0 │ 5.0 │ 6000000 │ 5 │ ├─────────────────┴──────────────────────┴──────────────────────┴──────────────────────────────────────────────────────────┴─────────┴───────────────┤ │ 11 rows 6 columns │ └────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘

D SELECT * FROM book_reviews USING SAMPLE 10; ┌─────────────────┬────────────┬──────────────────────┬────────┬───┬─────────────┬──────────────────────┬──────────────────────┬──────────────┐ │ book_reviews_id │ book_id │ book_title │ price │ … │ review_year │ review_summary │ review_text │ review_score │ │ int64 │ varchar │ varchar │ double │ │ varchar │ varchar │ varchar │ double │ ├─────────────────┼────────────┼──────────────────────┼────────┼───┼─────────────┼──────────────────────┼──────────────────────┼──────────────┤ │ 5380921 │ 0060539844 │ Party Crashers │ │ … │ 2013 │ Loved it!!! │ My first book by S… │ 4.0 │ │ 2352516 │ B0000YSH56 │ The Witch of Black… │ │ … │ 2000 │ The Witch of Black… │ The Witch of Black… │ 5.0 │ │ 3269004 │ 1576734978 │ More than a Savior… │ │ … │ 2003 │ Excellent Insights │ Wonderfully differ… │ 5.0 │ │ 1072078 │ B000GR1U2E │ Blood and Money │ │ … │ 2001 │ A very "Gripp… │ I read "Blood… │ 4.0 │ │ 4753031 │ 0786166363 │ Persuasion │ 63.0 │ … │ 2010 │ love the book, hat… │ When I saw that th… │ 1.0 │ │ 361828 │ 0460112872 │ Jane Eyre (Everyma… │ │ … │ 2005 │ Outstanding in Eve… │ Jane Eyre is the u… │ 5.0 │ │ 2605832 │ B000NSKD74 │ The Eagle Has Landed │ │ … │ 1999 │ WILL ME YOU BREATH… │ A class by itself,… │ 5.0 │ │ 4569993 │ B000QC9JQ8 │ Man's Search for M… │ │ … │ 2009 │ Touching Story │ Man's Search for M… │ 5.0 │ │ 2497396 │ B000GQG5MA │ The Hobbit; Or, Th… │ │ … │ 2012 │ 75th Anniversary E… │ Our 11-year-old so… │ 5.0 │ │ 916140 │ B0007E9LAE │ The posthumous pap… │ │ … │ 2013 │ The Pickwick Papers │ Hard to follow and… │ 1.0 │ ├─────────────────┴────────────┴──────────────────────┴────────┴───┴─────────────┴──────────────────────┴──────────────────────┴──────────────┤ │ 10 rows 11 columns (8 shown) │ └─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘


D EXPLAIN SELECT count(*) FROM book_reviews WHERE user_id = 'A1WQVN65FTJCJ6'; ┌─────────────────────────────┐ │┌───────────────────────────┐│ ││ Physical Plan ││ │└───────────────────────────┘│ └─────────────────────────────┘ ┌───────────────────────────┐ │ UNGROUPED_AGGREGATE │ │ ──────────────────── │ │ Aggregates: │ │ count_star() │ └─────────────┬─────────────┘ ┌─────────────┴─────────────┐ │ SEQ_SCAN │ │ ──────────────────── │ │ book_reviews │ │ │ │ Filters: │ │ user_id='A1WQVN65FTJCJ6' │ │ AND user_id IS NOT NULL │ │ │ │ ~21 Rows │ └───────────────────────────┘
D EXPLAIN SELECT count(*) FROM book_reviews WHERE review_year = '2012'; ┌─────────────────────────────┐ │┌───────────────────────────┐│ ││ Physical Plan ││ │└───────────────────────────┘│ └─────────────────────────────┘ ┌───────────────────────────┐ │ UNGROUPED_AGGREGATE │ │ ──────────────────── │ │ Aggregates: │ │ count_star() │ └─────────────┬─────────────┘ ┌─────────────┴─────────────┐ │ SEQ_SCAN │ │ ──────────────────── │ │ book_reviews │ │ │ │ Filters: │ │ review_year='2012' AND │ │ review_year IS NOT NULL │ │ │ │ ~300000 Rows │ └───────────────────────────┘

D CREATE INDEX book_reviews_idx_user_id ON book_reviews(user_id); 100% ▕████████████████████████████████████████████████████████████▏ D CREATE INDEX book_reviews_idx_year ON book_reviews(review_year);
D SELECT * FROM duckdb_indexes; ┌───────────────┬──────────────┬─────────────┬────────────┬──────────────────────┬───┬───────────┬────────────┬───────────────┬──────────────────────┐ │ database_name │ database_oid │ schema_name │ schema_oid │ index_name │ … │ is_unique │ is_primary │ expressions │ sql │ │ varchar │ int64 │ varchar │ int64 │ varchar │ │ boolean │ boolean │ varchar │ varchar │ ├───────────────┼──────────────┼─────────────┼────────────┼──────────────────────┼───┼───────────┼────────────┼───────────────┼──────────────────────┤ │ memory │ 1146 │ main │ 1148 │ book_reviews_idx_u… │ … │ false │ false │ [user_id] │ CREATE INDEX book_… │ │ memory │ 1146 │ main │ 1148 │ book_reviews_idx_y… │ … │ false │ false │ [review_year] │ CREATE INDEX book_… │ ├───────────────┴──────────────┴─────────────┴────────────┴──────────────────────┴───┴───────────┴────────────┴───────────────┴──────────────────────┤ │ 2 rows 14 columns (9 shown) │ └────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘

D EXPLAIN SELECT count(*) FROM book_reviews WHERE user_id = 'A1RRTLWXDOYER5'; ┌─────────────────────────────┐ │┌───────────────────────────┐│ ││ Physical Plan ││ │└───────────────────────────┘│ └─────────────────────────────┘ ┌───────────────────────────┐ │ UNGROUPED_AGGREGATE │ │ ──────────────────── │ │ Aggregates: │ │ count_star() │ └─────────────┬─────────────┘ ┌─────────────┴─────────────┐ │ FILTER │ │ ──────────────────── │ │ (user_id = 'A1RRTLWXDOYER5│ │ ') │ │ │ │ ~1200000 Rows │ └─────────────┬─────────────┘ ┌─────────────┴─────────────┐ │ INDEX_SCAN │ │ ──────────────────── │ │ book_reviews │ │ │ │ Projections: user_id │ │ │ │ ~6000000 Rows │ └───────────────────────────┘
D EXPLAIN SELECT count(*) FROM book_reviews WHERE review_year = 2012; ┌─────────────────────────────┐ │┌───────────────────────────┐│ ││ Physical Plan ││ │└───────────────────────────┘│ └─────────────────────────────┘ ┌───────────────────────────┐ │ UNGROUPED_AGGREGATE │ │ ──────────────────── │ │ Aggregates: │ │ count_star() │ └─────────────┬─────────────┘ ┌─────────────┴─────────────┐ │ FILTER │ │ ──────────────────── │ │ (CAST(review_year AS │ │ INTEGER) = 2012) │ │ │ │ ~1200000 Rows │ └─────────────┬─────────────┘ ┌─────────────┴─────────────┐ │ SEQ_SCAN │ │ ──────────────────── │ │ book_reviews │ │ │ │ Projections: │ │ review_year │ │ │ │ ~6000000 Rows │ └───────────────────────────┘


D PRAGMA database_size; ┌───────────────┬───────────────┬────────────┬──────────────┬─────────────┬─────────────┬──────────┬──────────────┬──────────────┐ │ database_name │ database_size │ block_size │ total_blocks │ used_blocks │ free_blocks │ wal_size │ memory_usage │ memory_limit │ │ varchar │ varchar │ int64 │ int64 │ int64 │ int64 │ varchar │ varchar │ varchar │ ├───────────────┼───────────────┼────────────┼──────────────┼─────────────┼─────────────┼──────────┼──────────────┼──────────────┤ │ memory │ 0 bytes │ 0 │ 0 │ 0 │ 0 │ 0 bytes │ 0 bytes │ 12.3 GiB │ └───────────────┴───────────────┴────────────┴──────────────┴─────────────┴─────────────┴──────────┴──────────────┴──────────────┘
As you might have suspected, we can see that our freshly created database does not use disks or memory.
Now, we use the same command we used previously to create our book_reviews table:
D CREATE OR REPLACE TABLE book_reviews AS SELECT * FROM read_parquet('book_reviews.parquet'); 100% ▕████████████████████████████████████████████████████████████▏ D PRAGMA database_size; ┌───────────────┬───────────────┬────────────┬──────────────┬─────────────┬─────────────┬──────────┬──────────────┬──────────────┐ │ database_name │ database_size │ block_size │ total_blocks │ used_blocks │ free_blocks │ wal_size │ memory_usage │ memory_limit │ │ varchar │ varchar │ int64 │ int64 │ int64 │ int64 │ varchar │ varchar │ varchar │ ├───────────────┼───────────────┼────────────┼──────────────┼─────────────┼─────────────┼──────────┼──────────────┼──────────────┤ │ memory │ 0 bytes │ 0 │ 0 │ 0 │ 0 │ 0 bytes │ 9.5 GiB │ 12.3 GiB │ └───────────────┴───────────────┴────────────┴──────────────┴─────────────┴─────────────┴──────────┴──────────────┴──────────────┘
In this instance, we have used 9.5 GB of memory to load the contents of the reviews_original. parquet file into the book_reviews table. This includes the automatically created BRIN indexes, which, as mentioned earlier, are created for every column.
Now, we’ll create a multi-column index on the book_reviews table for the combination of the region and review_score columns. A multi-column database index is an index that is created for two (or more) columns of a table. It can potentially speed up queries for which the filter conditions involve all columns. We’ll follow this by using another check of the current memory usage:
D CREATE INDEX book_reviews_idx1 ON book_reviews(region, review_score); D PRAGMA database_size; ┌───────────────┬───────────────┬────────────┬──────────────┬─────────────┬─────────────┬──────────┬──────────────┬──────────────┐ │ database_name │ database_size │ block_size │ total_blocks │ used_blocks │ free_blocks │ wal_size │ memory_usage │ memory_limit │ │ varchar │ varchar │ int64 │ int64 │ int64 │ int64 │ varchar │ varchar │ varchar │ ├───────────────┼───────────────┼────────────┼──────────────┼─────────────┼─────────────┼──────────┼──────────────┼──────────────┤ │ memory │ 0 bytes │ 0 │ 0 │ 0 │ 0 │ 0 bytes │ 9.5 GiB │ 12.3 GiB │ └───────────────┴───────────────┴────────────┴──────────────┴─────────────┴─────────────┴──────────┴──────────────┴──────────────┘



D SET threads TO 1; D COPY ( SELECT * FROM book_reviews ) TO 'book_reviews_hive' ( FORMAT parquet, PARTITION_BY (review_year, region), OVERWRITE_OR_IGNORE true ); 100% ▕████████████████████████████████████████████████████████████▏
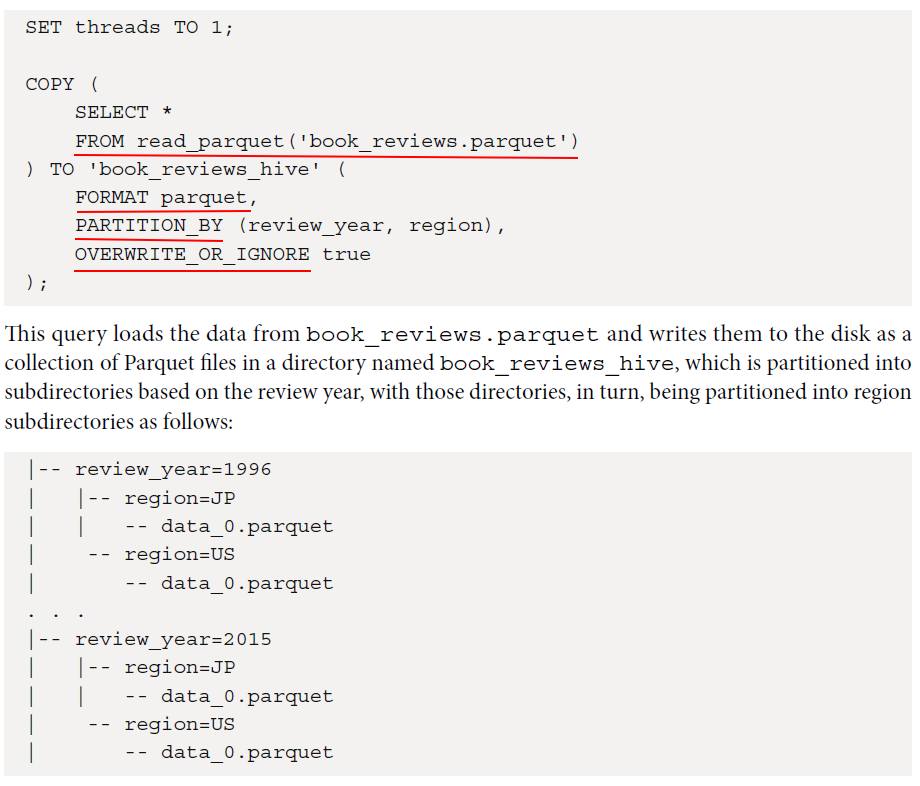

 hive_partitioning
hive_partitioning
D .timer on D SELECT * FROM read_parquet( 'book_reviews_hive/*/*/*.parquet', hive_partitioning=true ) WHERE review_year = '2012' AND region = 'JP'; ......
├─────────────────┴────────────┴──────────────────────┴────────┴───┴──────────────────────┴──────────────────────┴──────────────┴─────────┴─────────────┤ │ 297992 rows (40 shown) 11 columns (9 shown) │ └───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘ Run Time (s): real 1.163 user 0.333164 sys 0.040872
D SELECT * FROM read_parquet('book_reviews.parquet') WHERE review_year = '2012' AND region = 'JP'; 100% ▕████████████████████████████████████████████████████████████▏ ...... ├─────────────────┴────────────┴──────────────────────┴────────┴───┴─────────────┴──────────────────────┴──────────────────────┴──────────────┤ │ 297992 rows (40 shown) 11 columns (8 shown) │ └─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘ Run Time (s): real 9.362 user 3.691476 sys 0.236401

 predicate pushdown
predicate pushdown

D SET threads TO 1; Run Time (s): real 0.000 user 0.000538 sys 0.000088 D .timer off D PRAGMA enable_optimizer; ┌─────────┐ │ Success │ │ boolean │ ├─────────┤ │ 0 rows │ └─────────┘ D PRAGMA enable_profiling; ┌─────────┐ │ Success │ │ boolean │ ├─────────┤ │ 0 rows │ └─────────┘ D PRAGMA profiling_output = 'profile_with_pushdown.log'; D .timer on
Now run the following table creation, followed immediately by closing the profiling capture:
D CREATE OR REPLACE TABLE book_reviews_1970_JP AS SELECT region, review_summary, review_text, review_time, review_year FROM read_parquet('book_reviews.parquet') WHERE region = 'JP' AND review_year = '1970'; Run Time (s): real 0.696 user 0.217030 sys 0.019826 D PRAGMA disable_profiling; ┌─────────┐ │ Success │ │ boolean │ ├─────────┤ │ 0 rows │ └─────────┘ Run Time (s): real 0.001 user 0.000439 sys 0.000072
frank@ZZHPC:/mnt/d/ZZHUBT/workspace/duckdb/data/C04$ cat profile_with_pushdown.log
┌─────────────────────────────────────┐
│┌───────────────────────────────────┐│
││ Query Profiling Information ││
│└───────────────────────────────────┘│
└─────────────────────────────────────┘
CREATE OR REPLACE TABLE book_reviews_1970_JP AS SELECT region, review_summary, review_text, review_time, review_year FROM read_parquet('book_reviews.parquet') WHERE region = 'JP' AND review_year = '1970';
┌────────────────────────────────────────────────┐
│┌──────────────────────────────────────────────┐│
││ Total Time: 0.663s ││
│└──────────────────────────────────────────────┘│
└────────────────────────────────────────────────┘
┌───────────────────────────┐
│ QUERY │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ CREATE_TABLE_AS │
│ ──────────────────── │
│ 1 Rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ──────────────────── │
│ region │
│ review_summary │
│ review_text │
│ review_time │
│ review_year │
│ │
│ 21 Rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ TABLE_SCAN │
│ ──────────────────── │
│ Function: │
│ READ_PARQUET │
│ │
│ Projections: │
│ region │
│ review_year │
│ review_summary │
│ review_text │
│ review_time │
│ │
│ Filters: │
│ region='JP' AND region IS │
│ NOT NULL │
│ review_year='1970' AND │
│ review_year IS NOT NULL │
│ │
│ 21 Rows │
│ (0.66s) │
└───────────────────────────┘
In this example, the filters region = 'JP' AND review_year = '1970' were applied while reading the file, and only 21 rows were returned to DuckDB in 0.66 seconds.

D PRAGMA disable_optimizer; ┌─────────┐ │ Success │ │ boolean │ ├─────────┤ │ 0 rows │ └─────────┘ D PRAGMA enable_profiling; ┌─────────┐ │ Success │ │ boolean │ ├─────────┤ │ 0 rows │ └─────────┘ D PRAGMA profiling_output = 'profile_without_pushdown.log'; D CREATE OR REPLACE TABLE book_reviews_1970_JP AS SELECT region, review_summary, review_text, review_time, review_year FROM read_parquet('book_reviews.parquet') WHERE region = 'JP' AND review_year = '1970'; 100% ▕████████████████████████████████████████████████████████████▏ D PRAGMA disable_profiling; ┌─────────┐ │ Success │ │ boolean │ ├─────────┤ │ 0 rows │ └─────────┘ D PRAGMA enable_optimizer; ┌─────────┐ │ Success │ │ boolean │ ├─────────┤ │ 0 rows │ └─────────┘
frank@ZZHPC:/mnt/d/ZZHUBT/workspace/duckdb/data/C04$ cat profile_without_pushdown.log
┌─────────────────────────────────────┐
│┌───────────────────────────────────┐│
││ Query Profiling Information ││
│└───────────────────────────────────┘│
└─────────────────────────────────────┘
CREATE OR REPLACE TABLE book_reviews_1970_JP AS SELECT region, review_summary, review_text, review_time, review_year FROM read_parquet('book_reviews.parquet') WHERE region = 'JP' AND review_year = '1970';
┌────────────────────────────────────────────────┐
│┌──────────────────────────────────────────────┐│
││ Total Time: 8.99s ││
│└──────────────────────────────────────────────┘│
└────────────────────────────────────────────────┘
┌───────────────────────────┐
│ QUERY │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ CREATE_TABLE_AS │
│ ──────────────────── │
│ 1 Rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ PROJECTION │
│ ──────────────────── │
│ region │
│ review_summary │
│ review_text │
│ review_time │
│ review_year │
│ │
│ 21 Rows │
│ (0.00s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ FILTER │
│ ──────────────────── │
│ ((region = CAST('JP' AS │
│ VARCHAR)) AND │
│ (review_year = CAST('1970'│
│ AS VARCHAR))) │
│ │
│ 21 Rows │
│ (0.01s) │
└─────────────┬─────────────┘
┌─────────────┴─────────────┐
│ TABLE_SCAN │
│ ──────────────────── │
│ Function: │
│ READ_PARQUET │
│ │
│ 6000000 Rows │
│ (8.96s) │
└───────────────────────────┘
In this example, the entire file of just over 6 million rows was returned to DuckDB, a noticeably longer time of 8.96 seconds.
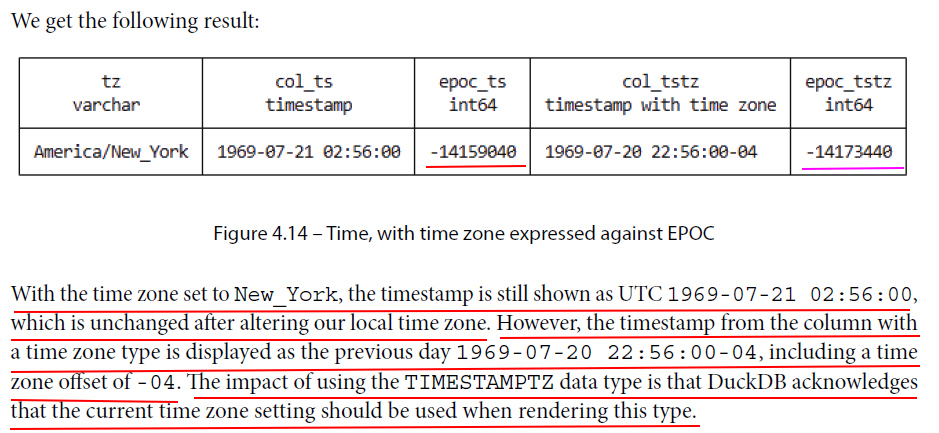
Timestamps represent distinct points in time, often referred to as instants. DuckDB has two data types for representing timestamps: TIMESTAMP and TIMESTAMP WITH TIME ZONE.
The latter type is also available as the alias TIMESTAMPTZ.


TIMESTAMP values do not encode any time zone information, and it is up to the application that is interacting with DuckDB to interpret and display it correctly based on the desired time zone.

As with TIMESTAMP, the TIMESTAMPTZ type stores a specific point in time, but it also stores a time zone alongside this, which is used for binning epoch values.

D SET TimeZone = 'UTC'; D CREATE OR REPLACE TABLE timestamp_demo ( col_ts TIMESTAMP, col_tstz TIMESTAMPTZ );
We will now insert the same moment of the first step on the Moon into each of the TIMESTAMP and TIMESTAMPTZ columns:
D INSERT INTO timestamp_demo (col_ts, col_tstz) VALUES('1969-07-21 02:56:00', '1969-07-21 02:56:00');
We can retrieve these values and see the representation from the perspective of our current UTC time zone setting:
D SELECT current_setting('timezone') AS tz, col_ts, extract(epoch FROM col_ts) AS epoc_ts, col_tstz, extract(epoch FROM col_tstz) AS epoc_tstz FROM timestamp_demo; ┌─────────┬─────────────────────┬─────────────┬──────────────────────────┬─────────────┐ │ tz │ col_ts │ epoc_ts │ col_tstz │ epoc_tstz │ │ varchar │ timestamp │ double │ timestamp with time zone │ double │ ├─────────┼─────────────────────┼─────────────┼──────────────────────────┼─────────────┤ │ UTC │ 1969-07-21 02:56:00 │ -14159040.0 │ 1969-07-21 02:56:00+00 │ -14159040.0 │ └─────────┴─────────────────────┴─────────────┴──────────────────────────┴─────────────┘

D SET TimeZone = 'America/New_York'; D SELECT current_setting('timezone') AS tz, col_ts, extract(epoch FROM col_ts) AS epoc_ts, col_tstz, extract(epoch FROM col_tstz) AS epoc_tstz FROM timestamp_demo; ┌──────────────────┬─────────────────────┬─────────────┬──────────────────────────┬─────────────┐ │ tz │ col_ts │ epoc_ts │ col_tstz │ epoc_tstz │ │ varchar │ timestamp │ double │ timestamp with time zone │ double │ ├──────────────────┼─────────────────────┼─────────────┼──────────────────────────┼─────────────┤ │ America/New_York │ 1969-07-21 02:56:00 │ -14159040.0 │ 1969-07-20 22:56:00-04 │ -14159040.0 │ └──────────────────┴─────────────────────┴─────────────┴──────────────────────────┴─────────────┘

D SELECT current_setting('timezone') AS tz, col_ts, dayofmonth(col_ts) AS day_of_month_ts, dayname(col_ts) AS day_name_ts, col_tstz, dayofmonth(col_tstz) AS day_of_month_tstz, dayname(col_tstz) AS day_name_tstz FROM timestamp_demo; ┌──────────────────┬─────────────────────┬─────────────────┬─────────────┬──────────────────────────┬───────────────────┬───────────────┐ │ tz │ col_ts │ day_of_month_ts │ day_name_ts │ col_tstz │ day_of_month_tstz │ day_name_tstz │ │ varchar │ timestamp │ int64 │ varchar │ timestamp with time zone │ int64 │ varchar │ ├──────────────────┼─────────────────────┼─────────────────┼─────────────┼──────────────────────────┼───────────────────┼───────────────┤ │ America/New_York │ 1969-07-21 02:56:00 │ 21 │ Monday │ 1969-07-20 22:56:00-04 │ 20 │ Sunday │ └──────────────────┴─────────────────────┴─────────────────┴─────────────┴──────────────────────────┴───────────────────┴───────────────┘




The INTERVAL data type provides a way of representing a duration of time in DuckDB.
D SELECT TIMESTAMP '1969-07-21 05:09:00' - TIMESTAMP '1969-07-21 02:56:00' AS interval_on_moon; ┌──────────────────┐ │ interval_on_moon │ │ interval │ ├──────────────────┤ │ 02:13:00 │ └──────────────────┘


D CREATE OR REPLACE VIEW apollo_activities AS SELECT event_description, event_time, astronaut, astronaut_location, LEAD(event_time, 1) OVER ( PARTITION BY astronaut ORDER BY event_time ) AS end_time, end_time - event_time AS event_duration FROM apollo_events;





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2022-01-09 Matplotlib - Figure Layout
2022-01-09 Matplotlib - Tick labels' rotation, size and alignment