

zzh@ZZHPC:~$ curl "localhost:4000/v1/movies?title=godfather&genres=crime,drama&page=1&page_size=5&sort=year"
{Title:godfather Genres:[crime drama] Page:1 PageSize:5 Sort:year}

Creating a Filter struct
The page , page_size and sort query string parameters are things that you’ll potentially want to use on other endpoints in your API too. So, to help make this easier, let’s quickly split them out into a reusable Filters struct.
If you’re following along, go ahead and create a new internal/data/filter.go file:

package data import "greenlight.zzh.net/internal/validator" // Filter is used for filtering, sorting and pagination. type Filter struct { Page int PageSize int Sort string SortSafeList []string } // ValidateFilter validates the fields of f using validator v. func ValidateFilter(v *validator.Validator, f Filter) { v.Check(f.Page > 0, "page", "must be greater than 0") v.Check(f.Page <= 10_000_000, "page", "must be less than or equal to 10000000") v.Check(f.PageSize > 0, "page_size", "must be greater than 0") v.Check(f.PageSize <= 100, "page_size", "must be less than or equal to 100") v.Check(validator.PermittedValue(f.Sort, f.SortSafeList...), "sort", "invalid sort value") }
func (app *application) listMoviesHandler(w http.ResponseWriter, r *http.Request) { // Embed the Filter struct. var input struct { Title string Genres []string data.Filter } v := validator.New() qs := r.URL.Query() input.Title = app.readString(qs, "title", "") input.Genres = app.readCSV(qs, "genres", []string{}) input.Filter.Page = app.readInt(qs, "page", 1, v) input.Filter.PageSize = app.readInt(qs, "page_size", 20, v) input.Filter.Sort = app.readString(qs, "sort", "id") input.Filter.SortSafeList = []string{"id", "title", "year", "runtime", "-id", "-title", "-year", "-runtime"} if data.ValidateFilter(v, input.Filter); !v.Valid() { app.failedValidationResponse(w, r, v.Errors) return } fmt.Fprintf(w, "%+v\n", input) }
zzh@ZZHPC:~$ curl "localhost:4000/v1/movies?page=-1&page_size=-1&sort=foo"
{
"error": {
"page": "must be greater than 0",
"page_size": "must be greater than 0",
"sort": "invalid sort value"
}
}
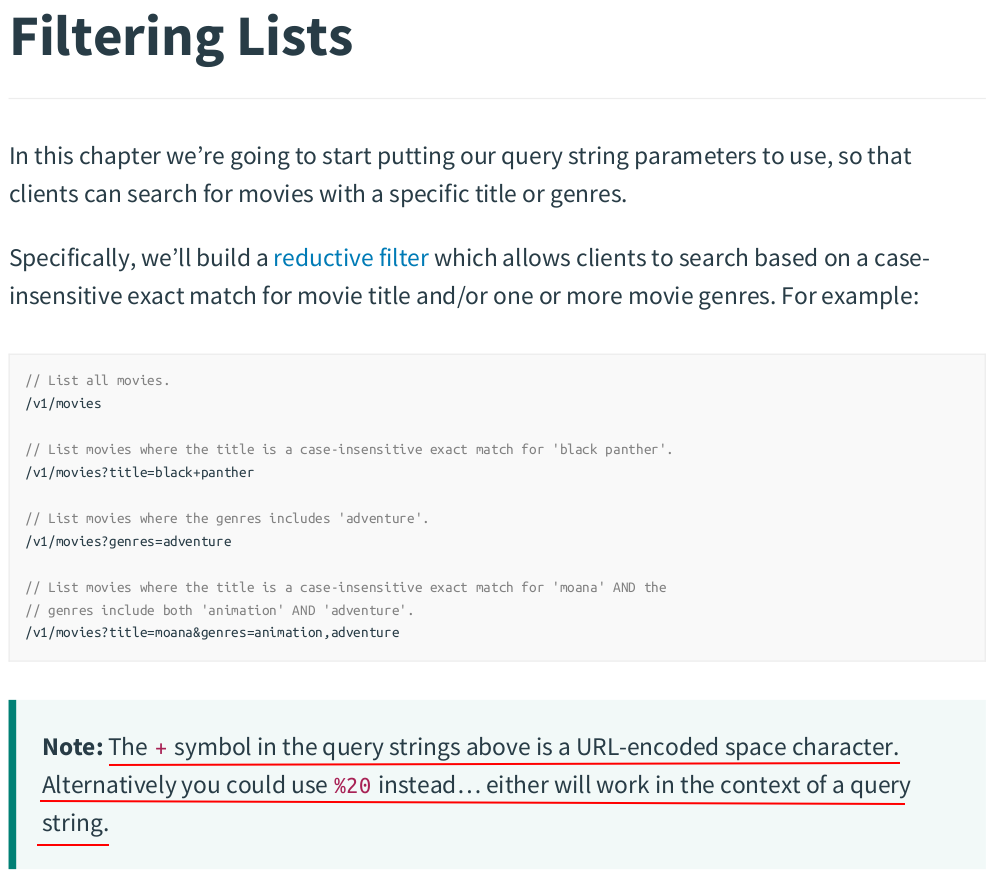

SELECT id, created_at, title, year, runtime, genres, version FROM movies WHERE (LOWER(title) = LOWER($1) OR $1 = '') AND (genres @> $2 OR $2 = '{}') ORDER BY id

https://www.postgresql.org/docs/current/functions-array.html
// GetAll returns a slice of movies. func (m MovieModel) GetAll(title string, genres []string, filter Filter) ([]*Movie, error) { query := `SELECT id, created_at, title, year, runtime, genres, version FROM movie WHERE (LOWER(title) = LOWER($1) OR $1 = '') AND (genres @> $2 OR $2 = '{}') ORDER BY id` ctx, cancel := context.WithTimeout(context.Background(), 3 * time.Second) defer cancel() rows, err := m.DB.Query(ctx, query, title, genres) if err != nil { return nil, err } defer rows.Close() movies := []*Movie{} for rows.Next() { var movie Movie err := rows.Scan( &movie.ID, &movie.CreatedAt, &movie.Title, &movie.Year, &movie.Runtime, &movie.Genres, &movie.Version, ) if err != nil { return nil, err } movies = append(movies, &movie) } if err = rows.Err(); err != nil { return nil, err } return movies, nil }
zzh@ZZHPC:~$ curl "localhost:4000/v1/movies?title=black+panther"
{
"movies": [
{
"id": 2,
"title": "Black Panther",
"year": 2018,
"runtime": "134 mins",
"genres": [
"sci-fi",
"action",
"adventure"
],
"version": 2
}
]
}
zzh@ZZHPC:~$ curl "localhost:4000/v1/movies?genres=adventure"
{
"movies": [
{
"id": 1,
"title": "Moana",
"year": 2016,
"runtime": "107 mins",
"genres": [
"animation",
"adventure"
],
"version": 1
},
{
"id": 2,
"title": "Black Panther",
"year": 2018,
"runtime": "134 mins",
"genres": [
"sci-fi",
"action",
"adventure"
],
"version": 2
}
]
}
zzh@ZZHPC:~$ curl "localhost:4000/v1/movies?title=moana&genres=animation,adventure"
{
"movies": [
{
"id": 1,
"title": "Moana",
"year": 2016,
"runtime": "107 mins",
"genres": [
"animation",
"adventure"
],
"version": 1
}
]
}
You can also try making a request with a filter that doesn’t match any records. In this case, you should get an empty JSON array in the response like so:
zzh@ZZHPC:~$ curl "localhost:4000/v1/movies?genres=western"
{
"movies": []
}
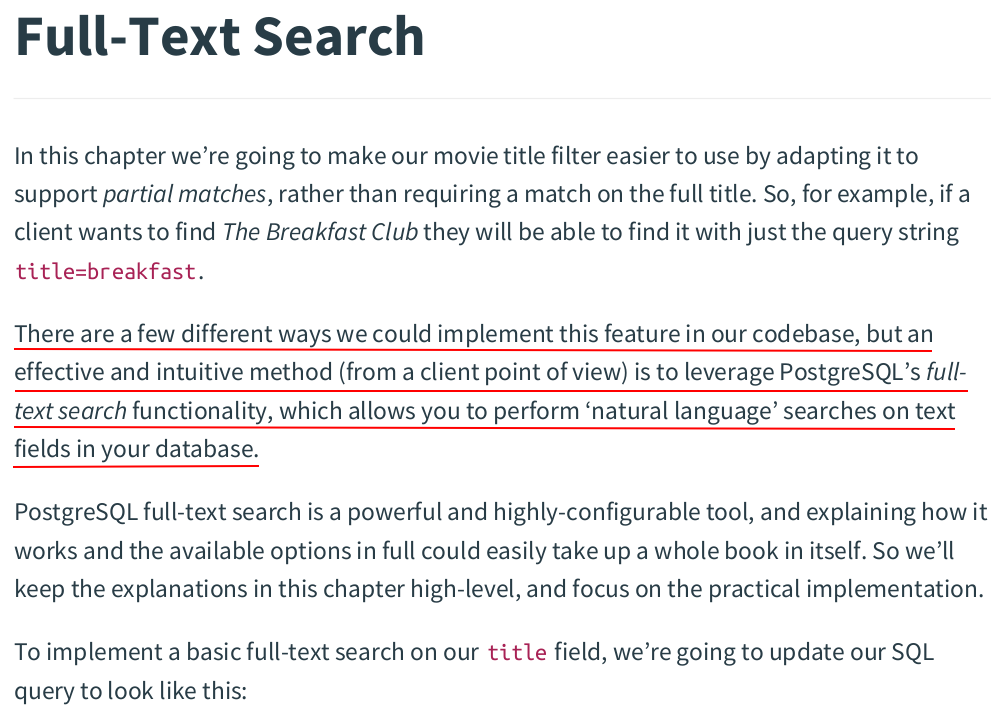
SELECT id, created_at, title, year, runtime, genres, version FROM movies WHERE (to_tsvector('simple', title) @@ plainto_tsquery('simple', $1) OR $1 = '') AND (genres @> $2 OR $2 = '{}') ORDER BY id

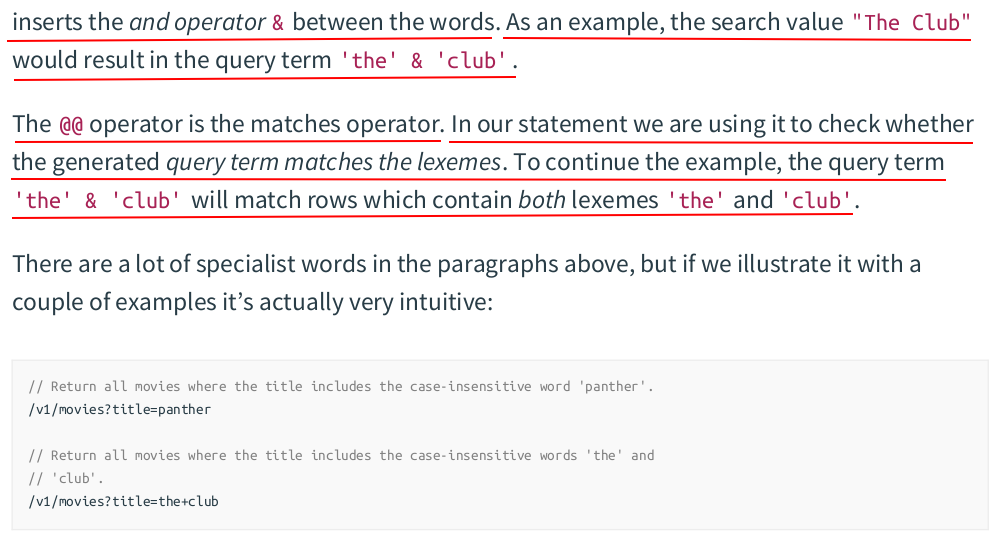
zzh@ZZHPC:~$ curl "localhost:4000/v1/movies?title=panther"
{
"movies": [
{
"id": 2,
"title": "Black Panther",
"year": 2018,
"runtime": "134 mins",
"genres": [
"sci-fi",
"action",
"adventure"
],
"version": 2
}
]
}
zzh@ZZHPC:~$ curl "localhost:4000/v1/movies?title=the+club"
{
"movies": [
{
"id": 4,
"title": "The Breakfast Club",
"year": 1985,
"runtime": "97 mins",
"genres": [
"drama"
],
"version": 6
}
]
}

https://www.postgresql.org/docs/current/indexes-intro.html
https://www.postgresql.org/docs/current/indexes-types.html

https://www.postgresql.org/docs/current/textsearch-indexes.html
If you’re following along, go ahead and create a new pair of migration files:
zzh@ZZHPC:/zdata/Github/greenlight$ migrate create -seq -ext .sql -dir ./migrations add_movie_indexes /zdata/Github/greenlight/migrations/000003_add_movie_indexes.up.sql /zdata/Github/greenlight/migrations/000003_add_movie_indexes.down.sql
CREATE INDEX IF NOT EXISTS idx_movie_title ON movie USING GIN (to_tsvector('simple', title)); CREATE INDEX IF NOT EXISTS idx_movie_genres ON movie USING GIN (genres);
DROP INDEX IF EXISTS idx_movie_title; DROP INDEX IF EXISTS idx_movie_genres;
migrate_up: migrate -path ./migrations -database "$(GREENLIGHT_DB_DSN)" up
zzh@ZZHPC:/zdata/Github/greenlight$ make migrate_up migrate -path ./migrations -database "postgres://greenlight:greenlight@localhost/greenlight?sslmode=disable" up 3/u add_movie_indexes (13.369506ms)

greenlight=> \dF
List of text search configurations
Schema | Name | Description
------------+------------+---------------------------------------
pg_catalog | arabic | configuration for arabic language
pg_catalog | armenian | configuration for armenian language
pg_catalog | basque | configuration for basque language
pg_catalog | catalan | configuration for catalan language
pg_catalog | danish | configuration for danish language
pg_catalog | dutch | configuration for dutch language
pg_catalog | english | configuration for english language
pg_catalog | finnish | configuration for finnish language
pg_catalog | french | configuration for french language
pg_catalog | german | configuration for german language
pg_catalog | greek | configuration for greek language
pg_catalog | hindi | configuration for hindi language
pg_catalog | hungarian | configuration for hungarian language
pg_catalog | indonesian | configuration for indonesian language
pg_catalog | irish | configuration for irish language
pg_catalog | italian | configuration for italian language
pg_catalog | lithuanian | configuration for lithuanian language
pg_catalog | nepali | configuration for nepali language
pg_catalog | norwegian | configuration for norwegian language
pg_catalog | portuguese | configuration for portuguese language
pg_catalog | romanian | configuration for romanian language
pg_catalog | russian | configuration for russian language
pg_catalog | serbian | configuration for serbian language
pg_catalog | simple | simple configuration
pg_catalog | spanish | configuration for spanish language
pg_catalog | swedish | configuration for swedish language
pg_catalog | tamil | configuration for tamil language
pg_catalog | turkish | configuration for turkish language
pg_catalog | yiddish | configuration for yiddish language
(29 rows)
And if you wanted to use the english configuration to search our movies, you could update the SQL query like so:
SELECT id, created_at, title, year, runtime, genres, version FROM movies WHERE (to_tsvector('english', title) @@ plainto_tsquery('english', $1) OR $1 = '') AND (genres @> $2 OR $2 = '{}') ORDER BY id
If you’d like to learn more about PostgreSQL full-text search, the official documentation is an excellent source of information and examples.

SELECT id, created_at, title, year, runtime, genres, version FROM movies WHERE (STRPOS(LOWER(title), LOWER($1)) > 0 OR $1 = '') AND (genres @> $2 OR $2 = '{}') ORDER BY id

SELECT id, created_at, title, year, runtime, genres, version FROM movies WHERE (title ILIKE $1 OR $1 = '') AND (genres @> $2 OR $2 = '{}') ORDER BY id




SELECT id, created_at, title, year, runtime, genres, version FROM movies WHERE (STRPOS(LOWER(title), LOWER($1)) > 0 OR $1 = '') AND (genres @> $2 OR $2 = '{}') ORDER BY year DESC, id ASC

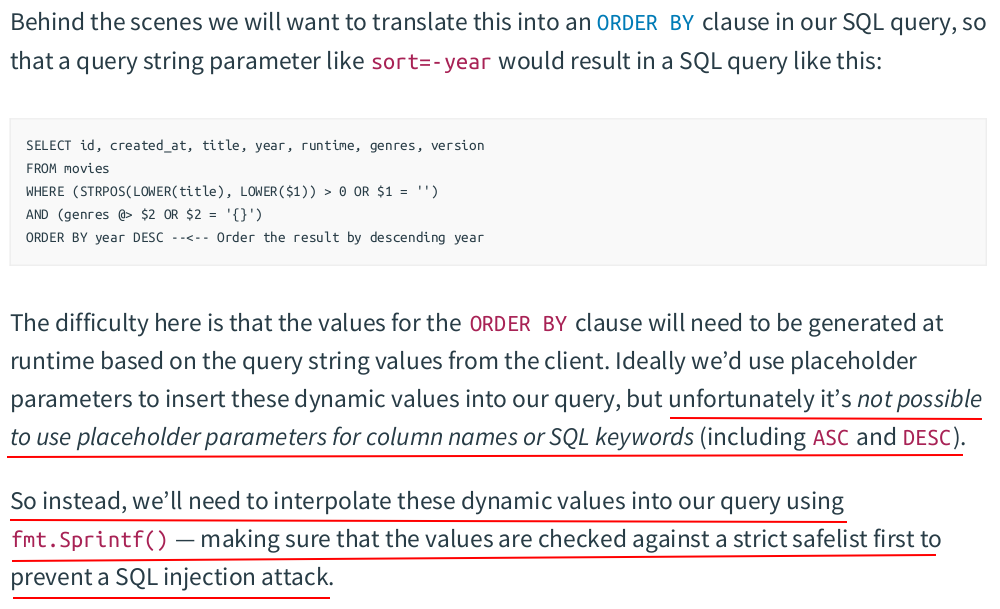
// sortColumn checks that the client-provided filed matches one of the entries in the safelist // and if it does, extracts the column name from the Sort field by stripping the leading hyphen // character (if one exists). func (f Filter) sortColumn() string { for _, safeValue := range f.SortSafeList { if f.Sort == safeValue { return strings.TrimPrefix(f.Sort, "-") } } panic("unsafe sort parameter: " + f.Sort) } // sortDirection returns the sort direction ("ASC" or "DESC") depending on the // prefix character of the Sort field. func (f Filter) sortDirection() string { if strings.HasPrefix(f.Sort, "-") { return "DESC" } return "ASC" }
func (m MovieModel) GetAll(title string, genres []string, filter Filter) ([]*Movie, error) { query := fmt.Sprintf(` SELECT id, created_at, title, year, runtime, genres, version FROM movie WHERE (to_tsvector('simple', title) @@ plainto_tsquery('simple', $1) OR $1 = '') AND (genres @> $2 OR $2 = '{}') ORDER BY %s %s, id ASC`, filter.sortColumn(), filter.sortDirection()) ...
zzh@ZZHPC:~$ curl "localhost:4000/v1/movies?sort=-title"
{
"movies": [
{
"id": 4,
"title": "The Breakfast Club",
"year": 1985,
"runtime": "97 mins",
"genres": [
"drama"
],
"version": 6
},
{
"id": 1,
"title": "Moana",
"year": 2016,
"runtime": "107 mins",
"genres": [
"animation",
"adventure"
],
"version": 1
},
{
"id": 2,
"title": "Black Panther",
"year": 2018,
"runtime": "134 mins",
"genres": [
"sci-fi",
"action",
"adventure"
],
"version": 2
}
]
}

func (f Filter) limit() int { return f.PageSize } func (f Filter) offset() int { return (f.Page - 1) * f.PageSize }

func (m MovieModel) GetAll(title string, genres []string, filter Filter) ([]*Movie, error) { query := fmt.Sprintf(` SELECT id, created_at, title, year, runtime, genres, version FROM movie WHERE (to_tsvector('simple', title) @@ plainto_tsquery('simple', $1) OR $1 = '') AND (genres @> $2 OR $2 = '{}') ORDER BY %s %s, id ASC LIMIT $3 OFFSET $4`, filter.sortColumn(), filter.sortDirection()) ctx, cancel := context.WithTimeout(context.Background(), 3 * time.Second) defer cancel() args := []any{title, genres, filter.limit(), filter.offset()} rows, err := m.DB.Query(ctx, query, args...) if err != nil { return nil, err } defer rows.Close() ...
zzh@ZZHPC:~$ curl "localhost:4000/v1/movies?page_size=2"
{
"movies": [
{
"id": 1,
"title": "Moana",
"year": 2016,
"runtime": "107 mins",
"genres": [
"animation",
"adventure"
],
"version": 1
},
{
"id": 2,
"title": "Black Panther",
"year": 2018,
"runtime": "134 mins",
"genres": [
"sci-fi",
"action",
"adventure"
],
"version": 2
}
]
}
# IMPORTANT: This URL must be surrounded with double-quotes to work correctly.
zzh@ZZHPC:~$ curl "localhost:4000/v1/movies?page_size=2&page=2"
{
"movies": [
{
"id": 4,
"title": "The Breakfast Club",
"year": 1985,
"runtime": "97 mins",
"genres": [
"drama"
],
"version": 6
}
]
}
If you try to request the third page, you should get an empty JSON array in the response like so:
zzh@ZZHPC:~$ curl "localhost:4000/v1/movies?page_size=2&page=3"
{
"movies": []
}



SELECT count(*) OVER(), id, created_at, title, year, runtime, genres, version FROM movies WHERE (to_tsvector('simple', title) @@ plainto_tsquery('simple', $1) OR $1 = '') AND (genres @> $2 OR $2 = '{}') ORDER BY %s %s, id ASC LIMIT $3 OFFSET $4


// MetaData holds the pagination metadata. type Metadata struct { CurrentPage int `json:"current_page,omitempty"` PageSize int `json:"page_size,omitempty"` FirstPage int `json:"first_page,omitempty"` LastPage int `json:"last_page,omitempty"` TotalRecords int `json:"total_records,omitempty"` } func calculateMetadata(totalRecords, page, pageSize int) Metadata { if totalRecords == 0 { return Metadata{} } // Note that when the last page value is calculated we are dividing two int values, and // when dividing integer types in Go the result will also be an integer type, with // the modulus (or remainder) dropped. So, for example, if there were 12 records in total // and a page size of 5, the last page value would be (12+5-1)/5 = 3.2, which is then // truncated to 3 by Go. return Metadata{ CurrentPage: page, PageSize: pageSize, FirstPage: 1, LastPage: (totalRecords + pageSize - 1) / pageSize, TotalRecords: totalRecords, } }
func (m MovieModel) GetAll(title string, genres []string, filter Filter) ([]*Movie, Metadata, error) { query := fmt.Sprintf(` SELECT count(*) OVER(), id, created_at, title, year, runtime, genres, version FROM movie WHERE (to_tsvector('simple', title) @@ plainto_tsquery('simple', $1) OR $1 = '') AND (genres @> $2 OR $2 = '{}') ORDER BY %s %s, id ASC LIMIT $3 OFFSET $4`, filter.sortColumn(), filter.sortDirection()) ctx, cancel := context.WithTimeout(context.Background(), 3 * time.Second) defer cancel() args := []any{title, genres, filter.limit(), filter.offset()} rows, err := m.DB.Query(ctx, query, args...) if err != nil { return nil, Metadata{}, err } defer rows.Close() totalRecords := 0 movies := []*Movie{} for rows.Next() { var movie Movie err := rows.Scan( &totalRecords, &movie.ID, &movie.CreatedAt, &movie.Title, &movie.Year, &movie.Runtime, &movie.Genres, &movie.Version, ) if err != nil { return nil, Metadata{}, err } movies = append(movies, &movie) } if err = rows.Err(); err != nil { return nil, Metadata{}, err } metadta := calculateMetadata(totalRecords, filter.Page, filter.PageSize) return movies, metadta, nil }
func (app *application) listMoviesHandler(w http.ResponseWriter, r *http.Request) { var input struct { Title string Genres []string data.Filter } v := validator.New() qs := r.URL.Query() input.Title = app.readString(qs, "title", "") input.Genres = app.readCSV(qs, "genres", []string{}) input.Filter.Page = app.readInt(qs, "page", 1, v) input.Filter.PageSize = app.readInt(qs, "page_size", 20, v) input.Filter.Sort = app.readString(qs, "sort", "id") input.Filter.SortSafeList = []string{"id", "title", "year", "runtime", "-id", "-title", "-year", "-runtime"} if data.ValidateFilter(v, input.Filter); !v.Valid() { app.failedValidationResponse(w, r, v.Errors) return } movies, metadata, err := app.models.Movie.GetAll(input.Title, input.Genres, input.Filter) if err != nil { app.serverErrorResponse(w, r, err) return } err = app.writeJSON(w, http.StatusOK, envelope{"movies": movies, "metadata": metadata}, nil) if err != nil { app.serverErrorResponse(w, r, err) } }
zzh@ZZHPC:~$ curl "localhost:4000/v1/movies?page=1&page_size=2"
{
"metadata": {
"current_page": 1,
"page_size": 2,
"first_page": 1,
"last_page": 2,
"total_records": 3
},
"movies": [
{
"id": 1,
"title": "Moana",
"year": 2016,
"runtime": "107 mins",
"genres": [
"animation",
"adventure"
],
"version": 1
},
{
"id": 2,
"title": "Black Panther",
"year": 2018,
"runtime": "134 mins",
"genres": [
"sci-fi",
"action",
"adventure"
],
"version": 2
}
]
}

zzh@ZZHPC:~$ curl "localhost:4000/v1/movies?genres=adventure"
{
"metadata": {
"current_page": 1,
"page_size": 20,
"first_page": 1,
"last_page": 1,
"total_records": 2
},
"movies": [
{
"id": 1,
"title": "Moana",
"year": 2016,
"runtime": "107 mins",
"genres": [
"animation",
"adventure"
],
"version": 1
},
{
"id": 2,
"title": "Black Panther",
"year": 2018,
"runtime": "134 mins",
"genres": [
"sci-fi",
"action",
"adventure"
],
"version": 2
}
]
}
Lastly, if you make a request with a too-high page value, you should get a response with an empty metadata object and movies array, like this:
zzh@ZZHPC:~$ curl "localhost:4000/v1/movies?page=100"
{
"metadata": {},
"movies": []
}



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2023-11-17 Microservice - Load Balancing (LB)
2023-11-17 Docker - Run MySQL