


Data Generation
x, y = load_data(n_points=1000, n_dims=10)
Next, we can use these data points to create a dataset and a data loader (no mini-batches this time):
Data Preparation
ball_dataset = TensorDataset(torch.as_tensor(x).float(), torch.as_tensor(y).float())
ball_loader = DataLoader(dataset=ball_dataset, batch_size=len(x))

torch.manual_seed(11) n_features = x.shape[1] n_layers = 5 n_hidden_units = 100 activation_fn = nn.ReLU model = build_model(n_features, n_layers, n_hidden_units, activation_fn, use_bn=False) model

Sequential( (h1): Linear(in_features=10, out_features=100, bias=True) (a1): ReLU() (h2): Linear(in_features=100, out_features=100, bias=True) (a2): ReLU() (h3): Linear(in_features=100, out_features=100, bias=True) (a3): ReLU() (h4): Linear(in_features=100, out_features=100, bias=True) (a4): ReLU() (h5): Linear(in_features=100, out_features=100, bias=True) (a5): ReLU() (o): Linear(in_features=100, out_features=1, bias=True) )

loss_fn = nn.BCEWithLogitsLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)

hidden_layers = [f'h{i}' for i in range(1, n_layers + 1)] activation_layers = [f'a{i}' for i in range(1, n_layers + 1)] sbs = StepByStep(model, loss_fn, optimizer) sbs.set_loaders(ball_loader) sbs.capture_parameters(hidden_layers) sbs.capture_gradients(hidden_layers) sbs.attach_hooks(activation_layers) sbs.train(1)

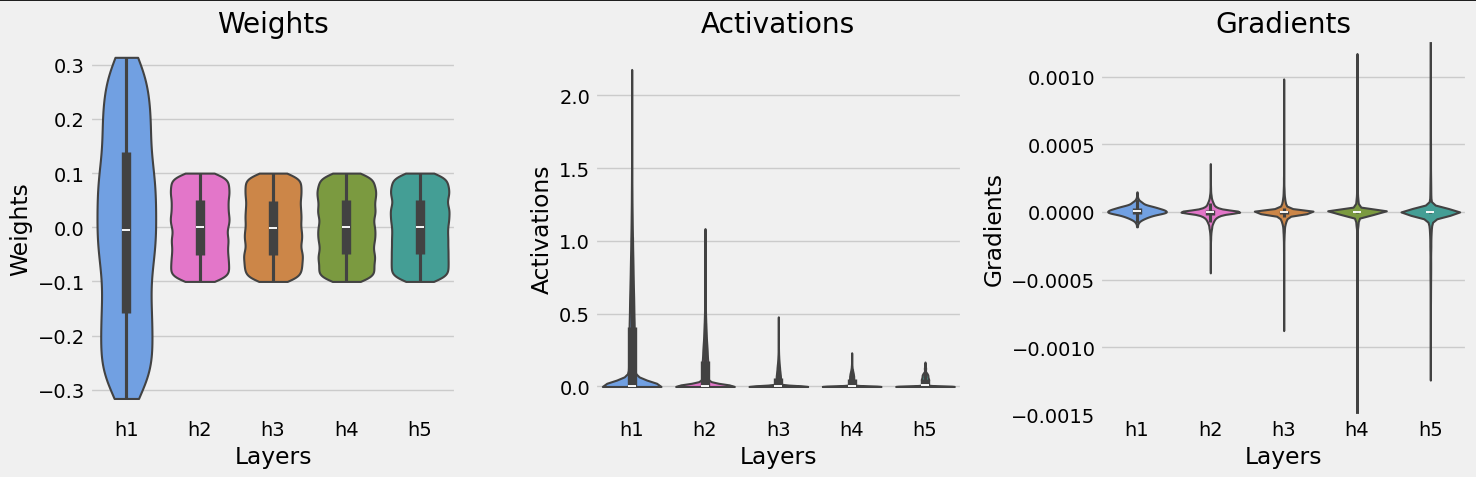
parms, gradients, activations = get_plot_data(train_loader=ball_loader, model=model)
fig = plot_violins(parms, gradients, activations)




from torch.nn import functional as F, init class Linear(Module): r"""Applies an affine linear transformation to the incoming data: :math:`y = xA^T + b`. This module supports :ref:`TensorFloat32<tf32_on_ampere>`. On certain ROCm devices, when using float16 inputs this module will use :ref:`different precision<fp16_on_mi200>` for backward. Args: in_features: size of each input sample out_features: size of each output sample bias: If set to ``False``, the layer will not learn an additive bias. Default: ``True`` Shape: - Input: :math:`(*, H_{in})` where :math:`*` means any number of dimensions including none and :math:`H_{in} = \text{in\_features}`. - Output: :math:`(*, H_{out})` where all but the last dimension are the same shape as the input and :math:`H_{out} = \text{out\_features}`. Attributes: weight: the learnable weights of the module of shape :math:`(\text{out\_features}, \text{in\_features})`. The values are initialized from :math:`\mathcal{U}(-\sqrt{k}, \sqrt{k})`, where :math:`k = \frac{1}{\text{in\_features}}` bias: the learnable bias of the module of shape :math:`(\text{out\_features})`. If :attr:`bias` is ``True``, the values are initialized from :math:`\mathcal{U}(-\sqrt{k}, \sqrt{k})` where :math:`k = \frac{1}{\text{in\_features}}` Examples:: >>> m = nn.Linear(20, 30) >>> input = torch.randn(128, 20) >>> output = m(input) >>> print(output.size()) torch.Size([128, 30]) """ __constants__ = ["in_features", "out_features"] in_features: int out_features: int weight: Tensor def __init__( self, in_features: int, out_features: int, bias: bool = True, device=None, dtype=None, ) -> None: factory_kwargs = {"device": device, "dtype": dtype} super().__init__() self.in_features = in_features self.out_features = out_features self.weight = Parameter( torch.empty((out_features, in_features), **factory_kwargs) ) if bias: self.bias = Parameter(torch.empty(out_features, **factory_kwargs)) else: self.register_parameter("bias", None) self.reset_parameters() def reset_parameters(self) -> None: # Setting a=sqrt(5) in kaiming_uniform is the same as initializing with # uniform(-1/sqrt(in_features), 1/sqrt(in_features)). For details, see # https://github.com/pytorch/pytorch/issues/57109 init.kaiming_uniform_(self.weight, a=math.sqrt(5)) if self.bias is not None: fan_in, _ = init._calculate_fan_in_and_fan_out(self.weight) bound = 1 / math.sqrt(fan_in) if fan_in > 0 else 0 init.uniform_(self.bias, -bound, bound) def forward(self, input: Tensor) -> Tensor: return F.linear(input, self.weight, self.bias) def extra_repr(self) -> str: return f"in_features={self.in_features}, out_features={self.out_features}, bias={self.bias is not None}"


Weight Initialization
def weights_init(model): if isinstance(model, nn.Linear): nn.init.kaiming_uniform_(model.weight, nonlinearity='relu') if model.bias is not None: nn.init.zeros_(model.bias)

with torch.no_grad():
model.apply(weights_init)
You should also use the no_grad() context manager while initializing / modifying the weights and biases of your model.

fig = plot_schemes(n_features, n_layers, n_hidden_units, ball_loader)
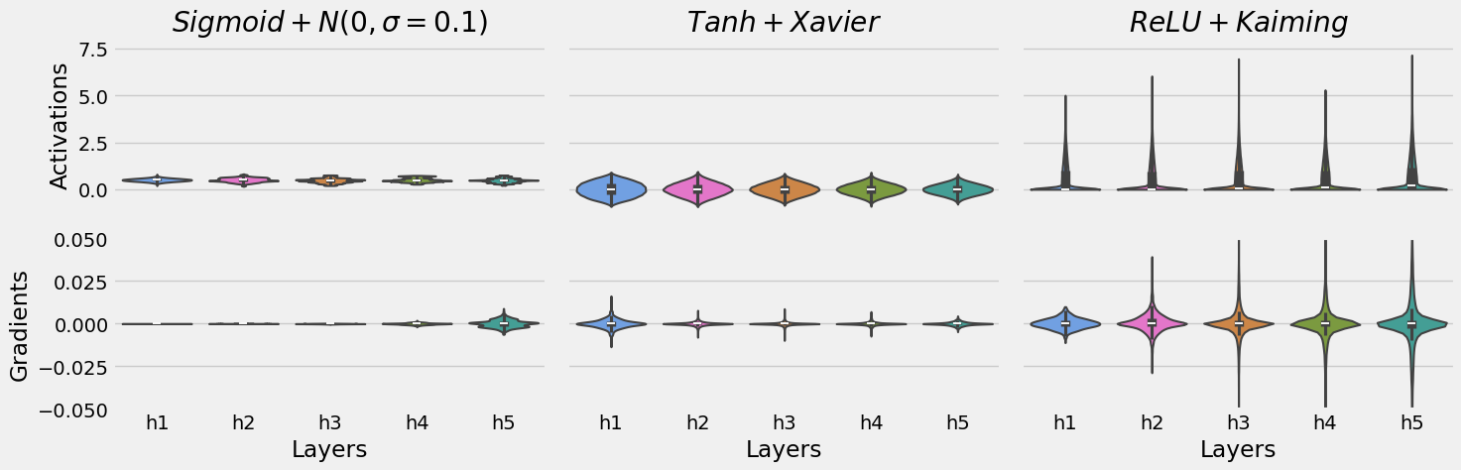

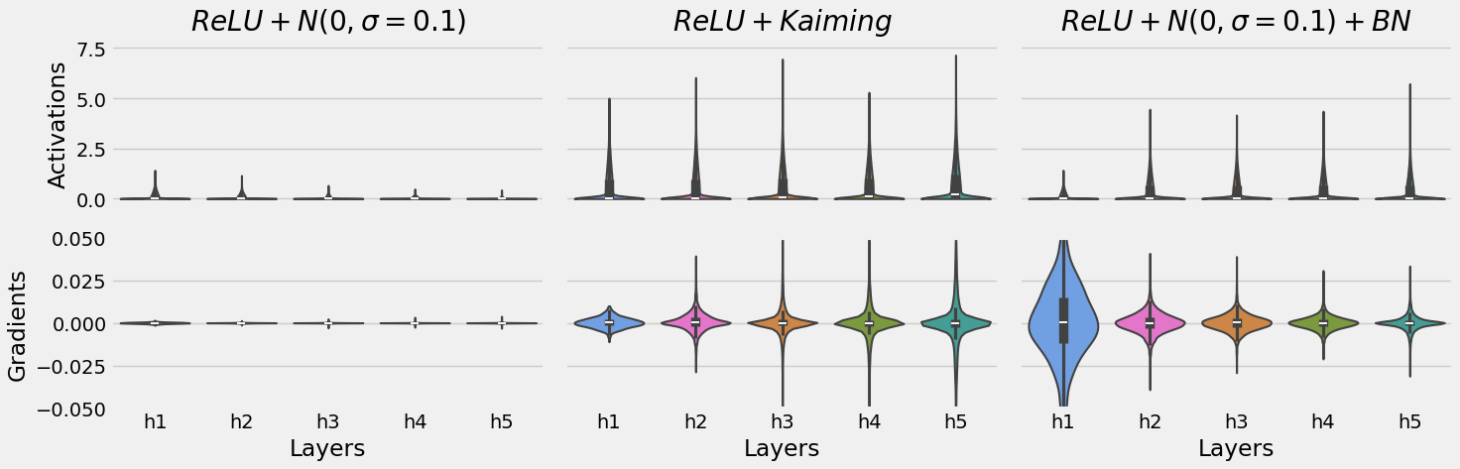
fig = plot_scheme_bn(n_features, n_layers, n_hidden_units, ball_loader)


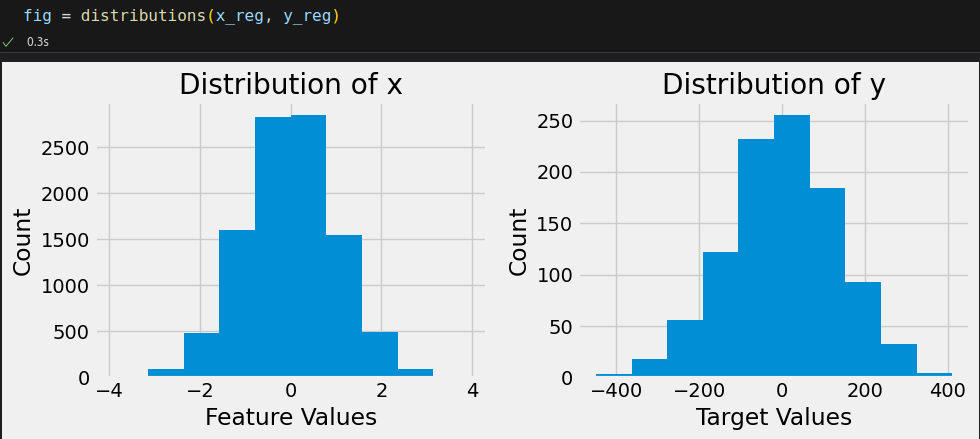
from sklearn.datasets import make_regression x_reg, y_reg = make_regression(n_samples=1000, n_features=10, noise=0.1, random_state=42) x_reg = torch.as_tensor(x_reg).float() y_reg = torch.as_tensor(y_reg).float() dataset = TensorDataset(x_reg, y_reg) train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True)
Even though we cannot plot a ten-dimensional regression, we can still visualize the distribution of both features and target values.

torch.manual_seed(11) model = nn.Sequential() model.add_module('fc1', nn.Linear(10, 15)) model.add_module('act', nn.ReLU()) model.add_module('fc2', nn.Linear(15, 1)) loss_fn = nn.MSELoss() optimizer = optim.SGD(model.parameters(), lr=0.01)
Before training it, let’s set our instance of the StepByStep class to capture the gradients for the weights in the hidden layer (fc1):
Model Training
sbs_reg = StepByStep(model, loss_fn, optimizer) sbs_reg.set_loaders(train_loader) sbs_reg.capture_gradients(['fc1'])
sbs_reg.train(2) sbs_reg.losses # [np.float64(17367.675262451172), np.float64(17306.57373046875)]
It turns out, two epochs are not enough to get exploding gradients.
Train another two epochs:
sbs_reg.train(2) sbs_reg.losses # [np.float64(17367.675262451172), # np.float64(17306.57373046875), # np.float64(17362.7119140625), # np.float64(17301.90805053711)]
Increase learning rate to get exploding gradients at the second epoch:
torch.manual_seed(11) model = nn.Sequential() model.add_module('fc1', nn.Linear(10, 15)) model.add_module('act', nn.ReLU()) model.add_module('fc2', nn.Linear(15, 1)) loss_fn = nn.MSELoss() optimizer = optim.SGD(model.parameters(), lr=0.03509966) sbs_reg = StepByStep(model, loss_fn, optimizer) sbs_reg.set_loaders(train_loader) sbs_reg.capture_gradients(['fc1']) sbs_reg.train(2) sbs_reg.losses # [np.float64(2.7670513733822185e+29), np.float64(nan)]

grads = np.array(sbs_reg._gradients['fc1']['weight']) print(grads.mean(axis=(1, 2)))
[ 2.44117905e-02 2.06106851e-01 1.81766347e-02 -2.35392176e+00
1.11135334e+01 -2.45726564e+01 -6.84081076e-01 -5.51755449e+00
2.17133981e+00 1.24698135e+00 -1.04324239e-01 9.37458067e-02
2.01123643e-01 5.32199112e-01 2.62268398e+01 -2.59524339e+01
6.88615245e-01 -1.83998085e-01 -3.75629093e+00 -1.86331088e-01
2.50075083e+00 1.52384045e-01 9.11065417e-03 6.15998185e-02
7.58073210e-01 4.96338612e-01 7.26849278e-01 7.53988466e-02
1.81392539e+01 -6.54686861e+01 1.38875571e+07 -2.59043075e+21
nan nan nan nan
nan nan nan nan
nan nan nan nan
nan nan nan nan
nan nan nan nan
nan nan nan nan
nan nan nan nan
nan nan nan nan]
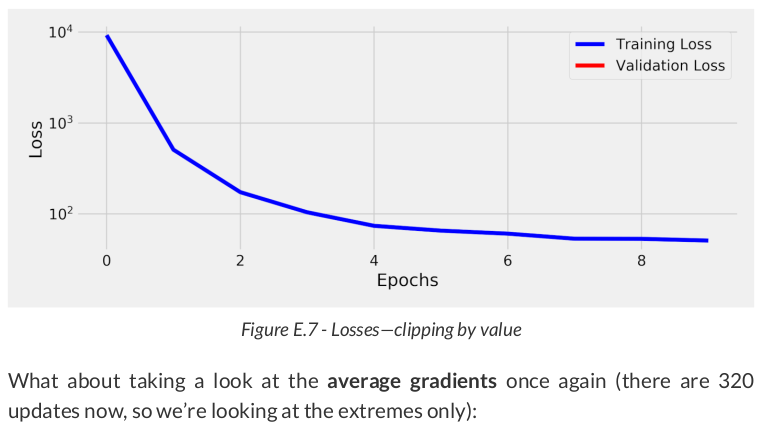
The first NaN shows up at the 33rd update, but the explosion started at the 31st update: The average gradient goes from tens (1e+01) to ten millions (1e+07) in one step, to (1e+21) or whatever this is called in the next, to a full-blown NaN.

torch.manual_seed(42) parm = nn.Parameter(torch.randn(2, 1)) fake_grads = torch.tensor([[2.5], [.8]])

parm.grad = fake_grads.clone() # Gradient Value Clipping nn.utils.clip_grad_value_(parm, clip_value=1.0) parm.grad # tensor([[1.0000], # [0.8000]])
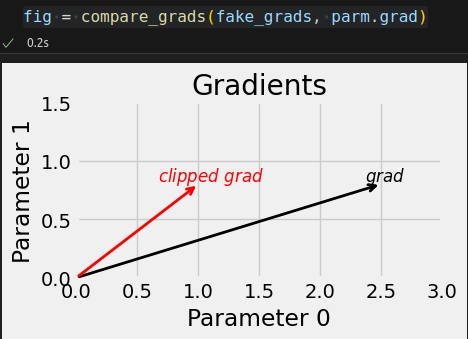

def clip_backprop(model, clip_value): handles = [] for p in model.parameters(): if p.requires_grad: func = lambda grad: torch.clamp(grad, -clip_value, clip_value) handle = p.register_hook(func) handles.append(handle) return handles
Do not forget that you should remove the hooks using handle.remove() after you’re done with them.


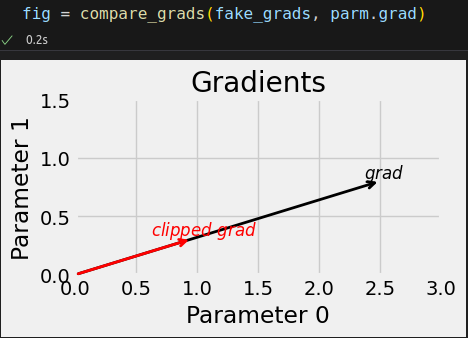
parm.grad = fake_grads.clone() # Gradient Norm Clipping nn.utils.clip_grad_norm_(parm, max_norm=1.0, norm_type=2) print(fake_grads) print(fake_grads.norm()) print(parm.grad) print(parm.grad.norm())
tensor([[2.5000], [0.8000]]) tensor(2.6249) tensor([[0.9524], [0.3048]]) tensor(1.0000)



self.clipping = None def set_clip_grad_value(self, clip_value): self.clipping = lambda: nn.utils.clip_grad_value_(self.model.parameters(), clip_value=clip_value) def set_clip_grad_norm(self, max_norm, norm_type=2): self.clipping = lambda: nn.utils.clip_grad_norm_(self.model.parameters(), max_norm=max_norm, norm_type=norm_type) def remove_clip(self): self.clipping = None def _make_train_step_fn(self): # Build function that performs a step in the train loop def perform_train_step_fn(x, y): self.model.train() yhat = self.model(x) loss = self.loss_fn(yhat, y) loss.backward() if callable(self.clipping): self.clipping() self.optimizer.step() self.optimizer.zero_grad() return loss.item() return perform_train_step_fn

def set_clip_backprop(self, clip_value): if self.clipping is None: self.clipping = [] for p in self.model.parameters(): if p.requires_grad: func = lambda grad: torch.clamp(grad, -clip_value, clip_value) handle = p.register_hook(func) self.clipping.append(handle) def remove_clip(self): if isinstance(self.clipping, list): for handle in self.clipping: handle.remove() self.clipping = None

Let’s use the weights_init function to initialize the weights so we can reset the parameters of our model that had its gradients exploded.
Moreover, let’s use a ten times higher learning rate; after all, we’re in full control of the gradients now:
Model Configuration
torch.manual_seed(42)
with torch.no_grad():
model.apply(weights_init)
optimizer = optim.SGD(model.parameters(), lr=0.03509966)
Before training it, let’s use set_clip_grad_value() to make sure no gradients are ever above 1.0:
Model Training
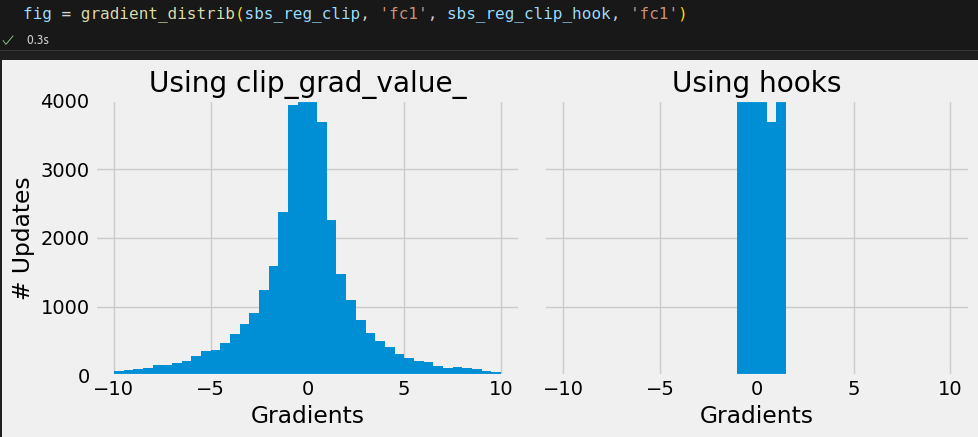
sbs_reg_clip = StepByStep(model, loss_fn, optimizer) sbs_reg_clip.set_loaders(train_loader) sbs_reg_clip.set_clip_grad_value(1.0) sbs_reg_clip.capture_gradients(['fc1']) sbs_reg_clip.train(10) sbs_reg_clip.remove_clip() sbs_reg_clip.remove_hooks()
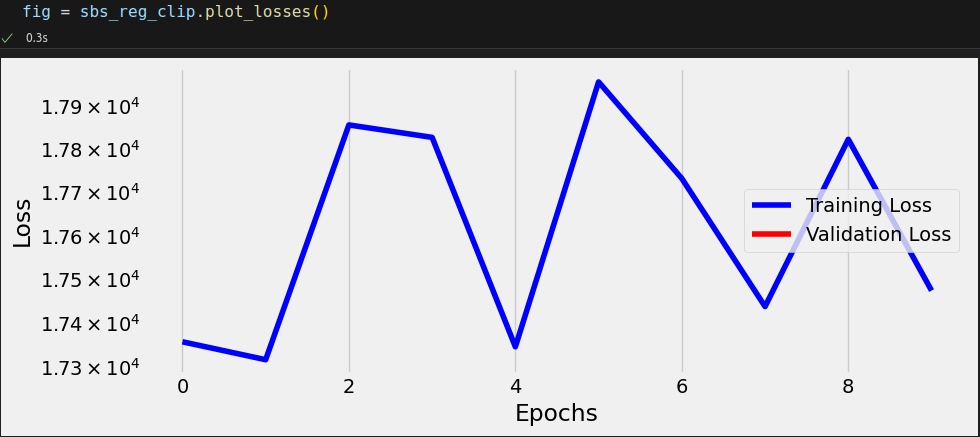
avg_grad = np.array(sbs_reg_clip._gradients['fc1']['weight']).mean(axis=(1, 2)) avg_grad.min(), avg_grad.max() # (np.float64(-6.1622835213318465), np.float64(1.5875422400461199))


torch.manual_seed(42)
with torch.no_grad():
model.apply(weights_init)

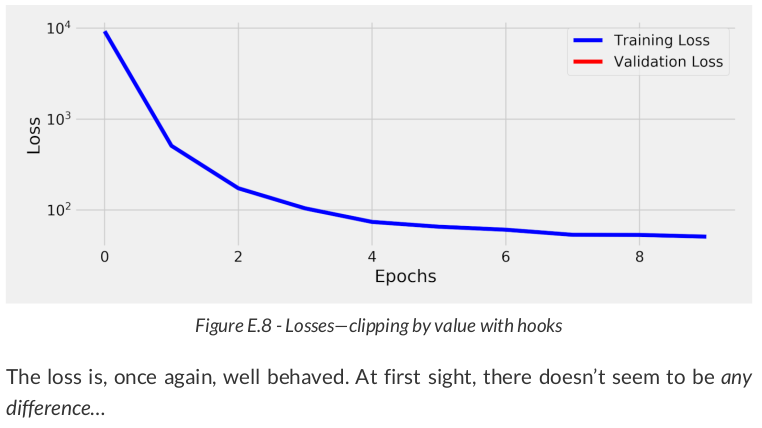
sbs_reg_clip_hook = StepByStep(model, loss_fn, optimizer) sbs_reg_clip_hook.set_loaders(train_loader) sbs_reg_clip_hook.set_clip_backprop(1.0) sbs_reg_clip_hook.capture_gradients(['fc1']) sbs_reg_clip_hook.train(10) sbs_reg_clip_hook.remove_clip() sbs_reg_clip_hook.remove_hooks()
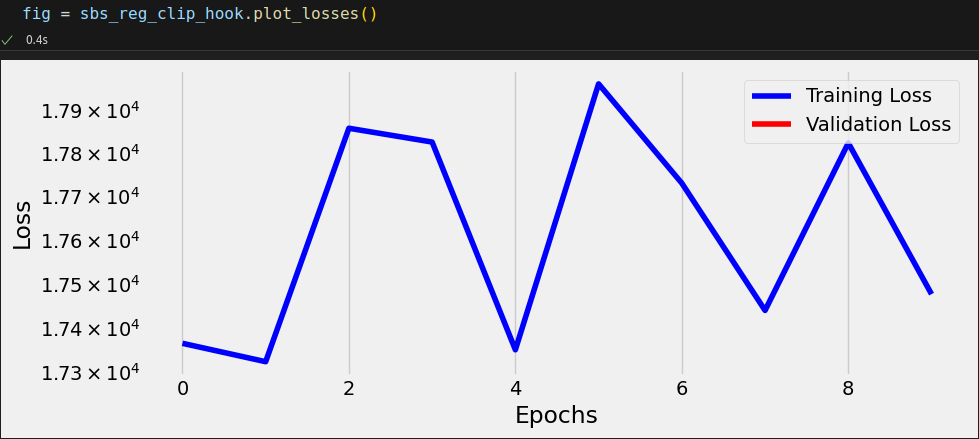
torch.manual_seed(42) with torch.no_grad(): model.apply(weights_init) optimizer = optim.SGD(model.parameters(), lr=0.01) sbs_reg_clip_hook = StepByStep(model, loss_fn, optimizer) sbs_reg_clip_hook.set_loaders(train_loader) sbs_reg_clip_hook.set_clip_backprop(1.0) sbs_reg_clip_hook.capture_gradients(['fc1']) sbs_reg_clip_hook.train(10) sbs_reg_clip_hook.remove_clip() sbs_reg_clip_hook.remove_hooks()
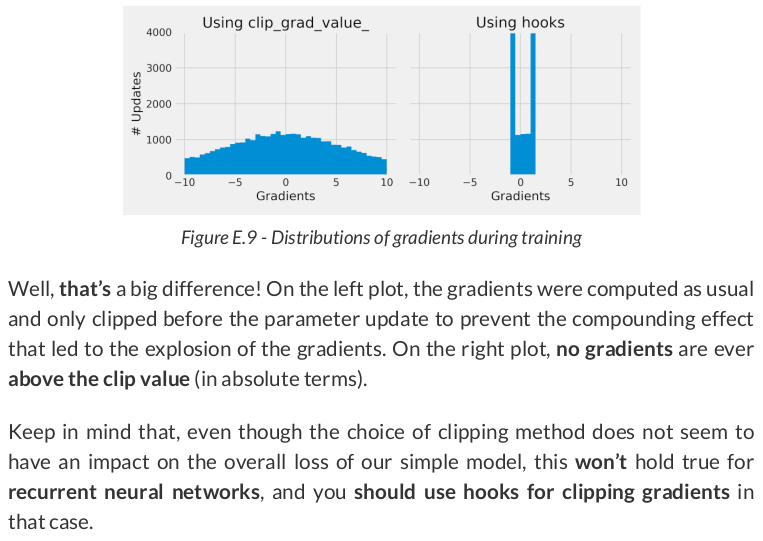





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律
2022-10-29 Git - reset