



http://www.image-net.org/challenges/LSVRC/


https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks

https://arxiv.org/abs/1409.1556



https://github.com/fastai/imagenette



from torchvision.models import alexnet alex = alexnet(weights=None) alex
AlexNet( (features): Sequential( (0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2)) (1): ReLU(inplace=True) (2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2)) (4): ReLU(inplace=True) (5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (7): ReLU(inplace=True) (8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (9): ReLU(inplace=True) (10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): ReLU(inplace=True) (12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) ) (avgpool): AdaptiveAvgPool2d(output_size=(6, 6)) (classifier): Sequential( (0): Dropout(p=0.5, inplace=False) (1): Linear(in_features=9216, out_features=4096, bias=True) (2): ReLU(inplace=True) (3): Dropout(p=0.5, inplace=False) (4): Linear(in_features=4096, out_features=4096, bias=True) (5): ReLU(inplace=True) (6): Linear(in_features=4096, out_features=1000, bias=True) ) )


result1 = F.adaptive_avg_pool2d(torch.randn(16, 32, 32), output_size=(6, 6)) result2 = F.adaptive_avg_pool2d(torch.randn(16, 12, 12), output_size=(6, 6)) result1.shape, result2.shape # (torch.Size([16, 6, 6]), torch.Size([16, 6, 6]))
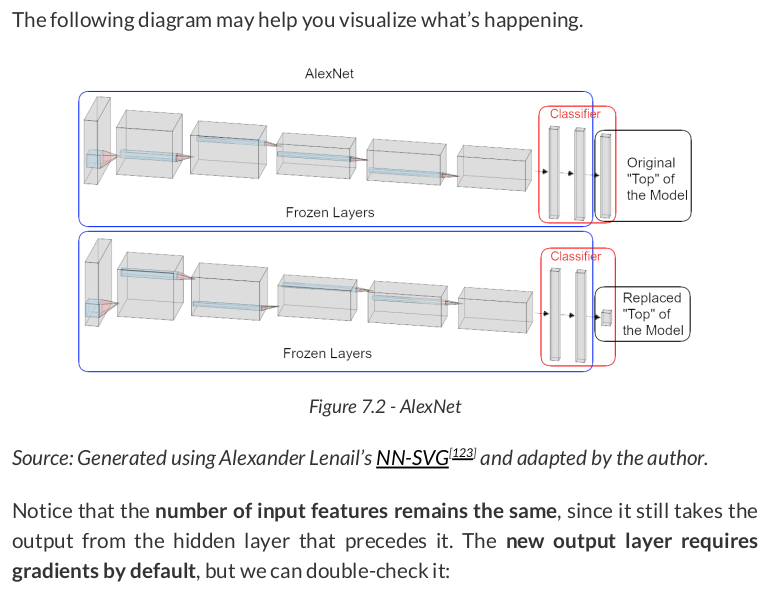
Cool, right? We have the architecture already, but our model is untrained (it still has random weights). Let’s fix that by…

from torchvision.models.alexnet import AlexNet_Weights weights = AlexNet_Weights.DEFAULT url = weights.url url # 'https://download.pytorch.org/models/alexnet-owt-7be5be79.pth'



# UPDATED ########################################################### # This is the recommended way of loading a pretrained # model's weights weights = AlexNet_Weights.DEFAULT alex = alexnet(weights=AlexNet_Weights.DEFAULT) ###########################################################
Downloading: "https://download.pytorch.org/models/alexnet-owt-7be5be79.pth" to /home/zzh/.cache/torch/hub/checkpoints/alexnet-owt-7be5be79.pth 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 233M/233M [00:56<00:00, 4.30MB/s]
Second run of this code will not download the weights again. It will use the downloaded file.

def freeze_model(model): for p in model.parameters(): p.requires_grad = False freeze_model(alex)

alex.classifier
Sequential( (0): Dropout(p=0.5, inplace=False) (1): Linear(in_features=9216, out_features=4096, bias=True) (2): ReLU(inplace=True) (3): Dropout(p=0.5, inplace=False) (4): Linear(in_features=4096, out_features=4096, bias=True) (5): ReLU(inplace=True) (6): Linear(in_features=4096, out_features=1000, bias=True) )

torch.manual_seed(11)
alex.classifier[6] = nn.Linear(4096, 3)
for name, param in alex.named_parameters(): if param.requires_grad == True: print(name)
classifier.6.weight classifier.6.bias





torch.manual_seed(17) ce_loss_fn = nn.CrossEntropyLoss(reduction='mean') optimizer_alex = optim.Adam(alex.parameters(), lr=3e-4)


normalizer = Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) composer = Compose([Resize(256), CenterCrop(224), ToImage(), ToDtype(torch.float32, scale=True), normalizer]) train_data = ImageFolder(root='rps', transform=composer) val_data = ImageFolder(root='rps-test-set', transform=composer) train_loader = DataLoader(dataset=train_data, batch_size=16, shuffle=True) val_loader = DataLoader(dataset=val_data, batch_size=16)

sbs_alex = StepByStep(alex, ce_loss_fn, optimizer_alex)
sbs_alex.set_loaders(train_loader, val_loader)
sbs_alex.train(1)
19.2s

StepByStep.loader_apply(val_loader, sbs_alex.correct)
tensor([[110, 124], [124, 124], [124, 124]])
That’s 96.24% accuracy in the validation set (it is 99.33% for the training set, in case you’re wondering). Even if it is taking some time to train, these results are pretty good!


alex.classifier[6] = nn.Identity()
alex.classifier
Sequential( (0): Dropout(p=0.5, inplace=False) (1): Linear(in_features=9216, out_features=4096, bias=True) (2): ReLU(inplace=True) (3): Dropout(p=0.5, inplace=False) (4): Linear(in_features=4096, out_features=4096, bias=True) (5): ReLU(inplace=True) (6): Identity() )
sbs_alex.model.classifier
Sequential( (0): Dropout(p=0.5, inplace=False) (1): Linear(in_features=9216, out_features=4096, bias=True) (2): ReLU(inplace=True) (3): Dropout(p=0.5, inplace=False) (4): Linear(in_features=4096, out_features=4096, bias=True) (5): ReLU(inplace=True) (6): Identity() )

def preprocessed_dataset(model, loader, device=None): if device is None: device = next(model.parameters()).device features = None labels = None for i, (x, y) in enumerate(loader): model.eval() x = x.to(device) output = model(x) if i == 0: features = output.detach().cpu() labels = y.cpu() else: features = torch.cat([features, output.detach().cpu()]) labels = torch.cat([labels, y.cpu()]) dataset = TensorDataset(features, labels) return dataset
We can use it to pre-process our datasets:
train_preproc = preprocessed_dataset(alex, train_loader)
val_preproc = preprocessed_dataset(alex, val_loader)

torch.save(train_preproc.tensors, 'save/rps_train_preproc.pth') torch.save(val_preproc.tensors, 'save/rps_val_preproc.pth')
This way, they can be used to build datasets later:
x, y = torch.load('save/rps_train_preproc.pth') train_preproc = TensorDataset(x, y) val_preproc = TensorDataset(*torch.load('save/rps_val_preproc.pth'))
/tmp/ipykernel_7773/4044978548.py:1: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
x, y = torch.load('save/rps_train_preproc.pth')
/tmp/ipykernel_7773/4044978548.py:3: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
val_preproc = TensorDataset(*torch.load('save/rps_val_preproc.pth'))
The last step of data preparation, as usual, is the creation of the data loader:
train_preproc_loader = DataLoader(dataset=train_preproc, batch_size=16, shuffle=True)
val_preproc_loader = DataLoader(dataset=val_preproc, batch_size=16)

torch.manual_seed(17) top_model = nn.Sequential(nn.Linear(4096, 3)) ce_loss_fn = nn.CrossEntropyLoss(reduction='mean') optimizer_top = optim.Adam(top_model.parameters(), lr=3e-4)

sbs_top = StepByStep(top_model, ce_loss_fn, optimizer_top)
sbs_top.set_loaders(train_preproc_loader, val_preproc_loader)
sbs_top.train(10)

sbs_alex.model.classifier[6] = top_model
sbs_alex.model.classifier
Sequential( (0): Dropout(p=0.5, inplace=False) (1): Linear(in_features=9216, out_features=4096, bias=True) (2): ReLU(inplace=True) (3): Dropout(p=0.5, inplace=False) (4): Linear(in_features=4096, out_features=4096, bias=True) (5): ReLU(inplace=True) (6): Sequential( (0): Linear(in_features=4096, out_features=3, bias=True) ) )
alex.classifier
Sequential( (0): Dropout(p=0.5, inplace=False) (1): Linear(in_features=9216, out_features=4096, bias=True) (2): ReLU(inplace=True) (3): Dropout(p=0.5, inplace=False) (4): Linear(in_features=4096, out_features=4096, bias=True) (5): ReLU(inplace=True) (6): Sequential( (0): Linear(in_features=4096, out_features=3, bias=True) ) )

StepByStep.loader_apply(val_loader, sbs_alex.correct)
tensor([[109, 124], [124, 124], [124, 124]])





from torchvision.models import inception_v3 from torchvision.models.inception import Inception_V3_Weights model = inception_v3(weights=Inception_V3_Weights.DEFAULT)
Downloading: "https://download.pytorch.org/models/inception_v3_google-0cc3c7bd.pth" to /home/zzh/.cache/torch/hub/checkpoints/inception_v3_google-0cc3c7bd.pth 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 104M/104M [00:50<00:00, 2.17MB/s]
model
Inception3( (Conv2d_1a_3x3): BasicConv2d( (conv): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), bias=False) (bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (Conv2d_2a_3x3): BasicConv2d( (conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), bias=False) (bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (Conv2d_2b_3x3): BasicConv2d( (conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (maxpool1): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (Conv2d_3b_1x1): BasicConv2d( (conv): Conv2d(64, 80, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(80, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (Conv2d_4a_3x3): BasicConv2d( (conv): Conv2d(80, 192, kernel_size=(3, 3), stride=(1, 1), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (maxpool2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (Mixed_5b): InceptionA( (branch1x1): BasicConv2d( (conv): Conv2d(192, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch5x5_1): BasicConv2d( (conv): Conv2d(192, 48, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(48, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch5x5_2): BasicConv2d( (conv): Conv2d(48, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3dbl_1): BasicConv2d( (conv): Conv2d(192, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3dbl_2): BasicConv2d( (conv): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3dbl_3): BasicConv2d( (conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch_pool): BasicConv2d( (conv): Conv2d(192, 32, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) ) (Mixed_5c): InceptionA( (branch1x1): BasicConv2d( (conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch5x5_1): BasicConv2d( (conv): Conv2d(256, 48, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(48, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch5x5_2): BasicConv2d( (conv): Conv2d(48, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3dbl_1): BasicConv2d( (conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3dbl_2): BasicConv2d( (conv): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3dbl_3): BasicConv2d( (conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch_pool): BasicConv2d( (conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) ) (Mixed_5d): InceptionA( (branch1x1): BasicConv2d( (conv): Conv2d(288, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch5x5_1): BasicConv2d( (conv): Conv2d(288, 48, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(48, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch5x5_2): BasicConv2d( (conv): Conv2d(48, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3dbl_1): BasicConv2d( (conv): Conv2d(288, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3dbl_2): BasicConv2d( (conv): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3dbl_3): BasicConv2d( (conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch_pool): BasicConv2d( (conv): Conv2d(288, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) ) (Mixed_6a): InceptionB( (branch3x3): BasicConv2d( (conv): Conv2d(288, 384, kernel_size=(3, 3), stride=(2, 2), bias=False) (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3dbl_1): BasicConv2d( (conv): Conv2d(288, 64, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3dbl_2): BasicConv2d( (conv): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3dbl_3): BasicConv2d( (conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(2, 2), bias=False) (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) ) (Mixed_6b): InceptionC( (branch1x1): BasicConv2d( (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7_1): BasicConv2d( (conv): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7_2): BasicConv2d( (conv): Conv2d(128, 128, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7_3): BasicConv2d( (conv): Conv2d(128, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7dbl_1): BasicConv2d( (conv): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7dbl_2): BasicConv2d( (conv): Conv2d(128, 128, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7dbl_3): BasicConv2d( (conv): Conv2d(128, 128, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7dbl_4): BasicConv2d( (conv): Conv2d(128, 128, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7dbl_5): BasicConv2d( (conv): Conv2d(128, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch_pool): BasicConv2d( (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) ) (Mixed_6c): InceptionC( (branch1x1): BasicConv2d( (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7_1): BasicConv2d( (conv): Conv2d(768, 160, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7_2): BasicConv2d( (conv): Conv2d(160, 160, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False) (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7_3): BasicConv2d( (conv): Conv2d(160, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7dbl_1): BasicConv2d( (conv): Conv2d(768, 160, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7dbl_2): BasicConv2d( (conv): Conv2d(160, 160, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False) (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7dbl_3): BasicConv2d( (conv): Conv2d(160, 160, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False) (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7dbl_4): BasicConv2d( (conv): Conv2d(160, 160, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False) (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7dbl_5): BasicConv2d( (conv): Conv2d(160, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch_pool): BasicConv2d( (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) ) (Mixed_6d): InceptionC( (branch1x1): BasicConv2d( (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7_1): BasicConv2d( (conv): Conv2d(768, 160, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7_2): BasicConv2d( (conv): Conv2d(160, 160, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False) (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7_3): BasicConv2d( (conv): Conv2d(160, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7dbl_1): BasicConv2d( (conv): Conv2d(768, 160, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7dbl_2): BasicConv2d( (conv): Conv2d(160, 160, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False) (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7dbl_3): BasicConv2d( (conv): Conv2d(160, 160, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False) (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7dbl_4): BasicConv2d( (conv): Conv2d(160, 160, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False) (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7dbl_5): BasicConv2d( (conv): Conv2d(160, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch_pool): BasicConv2d( (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) ) (Mixed_6e): InceptionC( (branch1x1): BasicConv2d( (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7_1): BasicConv2d( (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7_2): BasicConv2d( (conv): Conv2d(192, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7_3): BasicConv2d( (conv): Conv2d(192, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7dbl_1): BasicConv2d( (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7dbl_2): BasicConv2d( (conv): Conv2d(192, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7dbl_3): BasicConv2d( (conv): Conv2d(192, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7dbl_4): BasicConv2d( (conv): Conv2d(192, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7dbl_5): BasicConv2d( (conv): Conv2d(192, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch_pool): BasicConv2d( (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) ) (AuxLogits): InceptionAux( (conv0): BasicConv2d( (conv): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (conv1): BasicConv2d( (conv): Conv2d(128, 768, kernel_size=(5, 5), stride=(1, 1), bias=False) (bn): BatchNorm2d(768, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (fc): Linear(in_features=768, out_features=1000, bias=True) ) (Mixed_7a): InceptionD( (branch3x3_1): BasicConv2d( (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3_2): BasicConv2d( (conv): Conv2d(192, 320, kernel_size=(3, 3), stride=(2, 2), bias=False) (bn): BatchNorm2d(320, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7x3_1): BasicConv2d( (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7x3_2): BasicConv2d( (conv): Conv2d(192, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7x3_3): BasicConv2d( (conv): Conv2d(192, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch7x7x3_4): BasicConv2d( (conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(2, 2), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) ) (Mixed_7b): InceptionE( (branch1x1): BasicConv2d( (conv): Conv2d(1280, 320, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(320, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3_1): BasicConv2d( (conv): Conv2d(1280, 384, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3_2a): BasicConv2d( (conv): Conv2d(384, 384, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False) (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3_2b): BasicConv2d( (conv): Conv2d(384, 384, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False) (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3dbl_1): BasicConv2d( (conv): Conv2d(1280, 448, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(448, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3dbl_2): BasicConv2d( (conv): Conv2d(448, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3dbl_3a): BasicConv2d( (conv): Conv2d(384, 384, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False) (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3dbl_3b): BasicConv2d( (conv): Conv2d(384, 384, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False) (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch_pool): BasicConv2d( (conv): Conv2d(1280, 192, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) ) (Mixed_7c): InceptionE( (branch1x1): BasicConv2d( (conv): Conv2d(2048, 320, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(320, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3_1): BasicConv2d( (conv): Conv2d(2048, 384, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3_2a): BasicConv2d( (conv): Conv2d(384, 384, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False) (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3_2b): BasicConv2d( (conv): Conv2d(384, 384, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False) (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3dbl_1): BasicConv2d( (conv): Conv2d(2048, 448, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(448, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3dbl_2): BasicConv2d( (conv): Conv2d(448, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False) (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3dbl_3a): BasicConv2d( (conv): Conv2d(384, 384, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False) (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch3x3dbl_3b): BasicConv2d( (conv): Conv2d(384, 384, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False) (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) (branch_pool): BasicConv2d( (conv): Conv2d(2048, 192, kernel_size=(1, 1), stride=(1, 1), bias=False) (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True) ) ) (avgpool): AdaptiveAvgPool2d(output_size=(1, 1)) (dropout): Dropout(p=0.5, inplace=False) (fc): Linear(in_features=2048, out_features=1000, bias=True) )
freeze_model(model) torch.manual_seed(42) model.AuxLogits.fc = nn.Linear(768, 3) model.fc = nn.Linear(2048, 3)

def inception_loss(outputs, labels): try: main, aux = outputs except ValueError: main = outputs aux = None loss_aux = 0 ce_loss_fn = nn.CrossEntropyLoss(reduction='mean') loss_main = ce_loss_fn(main, labels) if aux is not None: loss_aux = ce_loss_fn(aux, labels) return loss_main + 0.4 * loss_aux
The auxiliary loss, in this case, is multiplied by a factor of 0.4 before being added to the main loss. Now, we’re only missing an optimizer:
optimizer_incep = optim.Adam(model.parameters(), lr=3e-4)
sbs_incep = StepByStep(model, inception_loss, optimizer_incep)

normalizer = Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) composer = Compose([Resize(299), ToImage(), ToDtype(torch.float32, scale=True), normalizer]) train_data = ImageFolder(root='rps', transform=composer) val_data = ImageFolder(root='rps-test-set', transform=composer) train_loader = DataLoader(train_data, batch_size=16, shuffle=True) val_loader = DataLoader(val_data, batch_size=16)
We’re ready, so let’s train our model for a single epoch and evaluate the result:
sbs_incep.set_loaders(train_loader, val_loader)
sbs_incep.train(1)
28.9s
StepByStep.loader_apply(val_loader, sbs_incep.correct)
tensor([[105, 124], [ 77, 124], [117, 124]])
It achieved an accuracy of 80.38% on the validation set. Not bad!
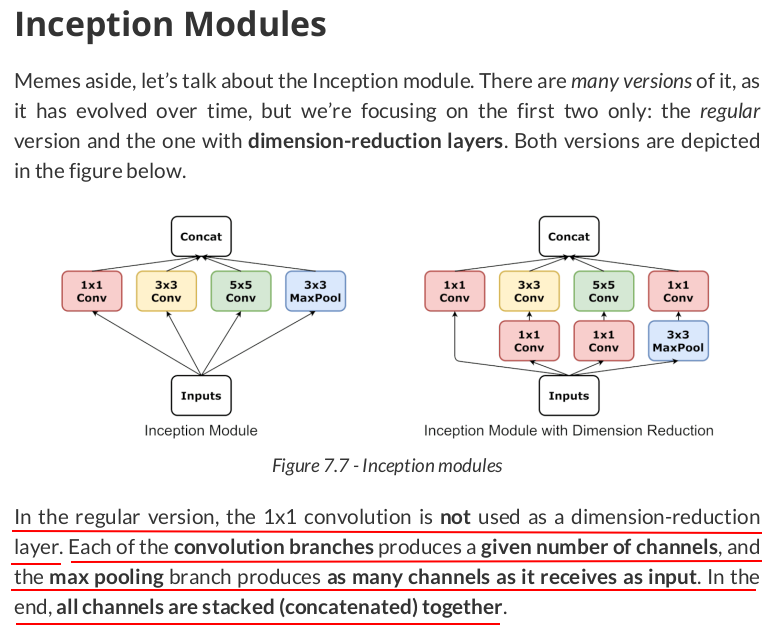
There is more to the Inception model than auxiliary classifiers, though. Let’s check out some of its other architectural elements.




from PIL import Image from torchvision.transforms.v2 import Normalize, Compose, Resize, CenterCrop, ToImage, ToDtype, ToPILImage scissors = Image.open('rps/scissors/scissors01-001.png') image = ToDtype(torch.float32, scale=True)(ToImage()(scissors))[:3, :, :].view(1, 3, 300, 300) weights = torch.tensor([0.2126, 0.7152, 0.0722]).view(1, 3, 1, 1) convolved = F.conv2d(input=image, weight=weights) converted = ToPILImage()(convolved[0]) grayscale = scissors.convert('L')






class Inception(nn.Module): def __init__(self, in_channels): super(Inception, self).__init__() # in_channels@HxW -> 2@HxW self.branch1x1_1 = nn.Conv2d(in_channels, 2, kernel_size=1) # in_channels@HxW -> 2@HxW -> 3@HxW self.branch5x5_1 = nn.Conv2d(in_channels, 2, kernel_size=1) self.branch5x5_2 = nn.Conv2d(2, 3, kernel_size=5, padding=2) # in_channels@HxW -> 2@HxW -> 3@HxW self.branch3x3_1 = nn.Conv2d(in_channels, 2, kernel_size=1) self.branch3x3_2 = nn.Conv2d(2, 3, kernel_size=3, padding=1) # in_channels@HxW -> in_channels@HxW -> 2@HxW self.branch_pool_1 = nn.AvgPool2d(kernel_size=3, stride=1, padding=1) self.branch_pool_2 = nn.Conv2d(in_channels, 2, kernel_size=1) def forward(self, x): # Produce 2 channels branch1x1 = self.branch1x1_1(x) # Produce 3 channels branch5x5 = self.branch5x5_1(x) branch5x5 = self.branch5x5_2(branch5x5) # Produce 3 channels branch3x3 = self.branch3x3_1(x) branch3x3 = self.branch3x3_2(branch3x3) # Produce 2 channels branch_pool = self.branch_pool_1(x) branch_pool = self.branch_pool_2(branch_pool) # Concatenate all channels together (10) outputs = torch.cat([branch1x1, branch5x5, branch3x3, branch_pool], 1) return outputs

inception = Inception(in_channels=3) output = inception(image) output.shape # torch.Size([1, 10, 300, 300])









torch.manual_seed(23) dummy_points = torch.randn((200, 2)) + torch.randn((200, 2)) * 2 dummy_labels = torch.randint(2, (200, 1)) dummy_dataset = TensorDataset(dummy_points, dummy_labels) dummy_loader = DataLoader(dataset=dummy_dataset, batch_size=64, shuffle=True)


iterator = iter(dummy_loader) batch1 = next(iterator) batch2 = next(iterator) batch3 = next(iterator)

mean1, var1 = batch1[0].mean(axis=0), batch1[0].var(axis=0) mean1, var1 # (tensor([0.9850, 1.0381]), tensor([1.4802, 1.1832]))
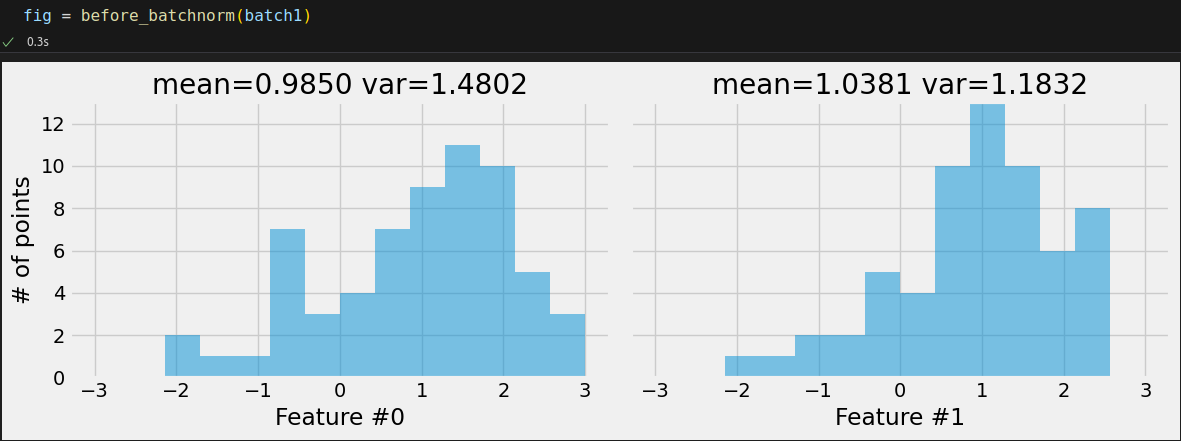
These features can surely benefit from some standardization. We’ll use nn.BatchNorm1d to accomplish it:
batch_normalizer = nn.BatchNorm1d(num_features=2, affine=False, momentum=None)
batch_normalizer.state_dict()
OrderedDict([('running_mean', tensor([0., 0.])), ('running_var', tensor([1., 1.])), ('num_batches_tracked', tensor(0))])

normed1 = batch_normalizer(batch1[0])
batch_normalizer.state_dict()
OrderedDict([('running_mean', tensor([0.9850, 1.0381])), ('running_var', tensor([1.4802, 1.1832])), ('num_batches_tracked', tensor(1))])
Great, it matches the statistics we computed before. The resulting values should be standardized by now, right? Let’s double-check it:
normed1.mean(axis=0), normed1.var(axis=0) # (tensor([1.4901e-08, 2.8871e-08]), tensor([1.0159, 1.0159]))

This was actually implemented like that by design. We’re not discussing the reasoning here, but, if you’d like to double-check the variance of the standardized mini-batch, you can use the following:
normed1.var(axis=0, unbiased=False) # tensor([1.0000, 1.0000])
That’s more like it! We can also plot the histograms again to more easily visualize the effect of batch normalization.
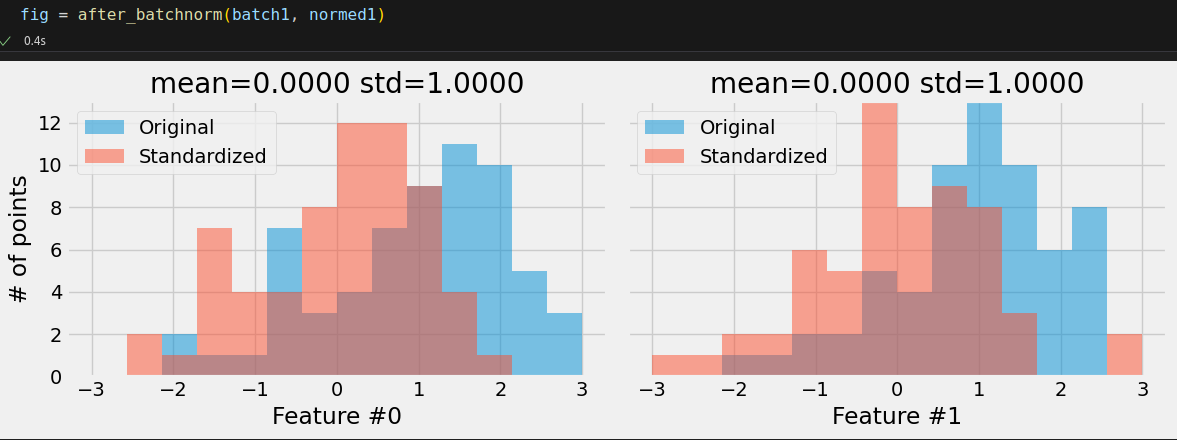

normed2 = batch_normalizer(batch2[0])
batch_normalizer.state_dict()
OrderedDict([('running_mean', tensor([0.9611, 0.9964])), ('running_var', tensor([1.4247, 1.0460])), ('num_batches_tracked', tensor(2))])
Both running mean and running variance are simple averages over the mini-batches:
mean2, var2 = batch2[0].mean(axis=0), batch2[0].var(axis=0) running_mean, running_var = (mean1 + mean2) / 2, (var1 + var2) / 2 running_mean, running_var # (tensor([0.9611, 0.9964]), tensor([1.4247, 1.0460]))
Now, let’s pretend we have finished training (even though we don’t have an actual model), and we’re using the third mini-batch for evaluation.

batch_normalizer.eval() normed3 = batch_normalizer(batch3[0]) normed3.mean(axis=0), normed3.var(axis=0, unbiased=False) # (tensor([-0.0201, 0.2208]), tensor([0.7170, 1.0761]))


batch_normalizer_mom = nn.BatchNorm1d(num_features=2, affine=False, momentum=0.1)
batch_normalizer_mom.state_dict()
OrderedDict([('running_mean', tensor([0., 0.])), ('running_var', tensor([1., 1.])), ('num_batches_tracked', tensor(0))])
Initial values are zero and one, respectively, for running mean and running variance. These will be the running statistics at time t-1. What happens if we run the first mini-batch through it?
normed_mom = batch_normalizer_mom(batch1[0])
batch_normalizer_mom.state_dict()
OrderedDict([('running_mean', tensor([0.0985, 0.1038])), ('running_var', tensor([1.0480, 1.0183])), ('num_batches_tracked', tensor(1))])
The running statistics barely budged after the mini-batch statistics were multiplied by the "momentum" argument. We can easily verify the results for the running means:
running_mean = torch.zeros((1, 2)) running_mean = 0.1 * batch1[0].mean(axis=0) + (1 - 0.1) * running_mean running_mean # tensor([[0.0985, 0.1038]])


torch.manual_seed(39) dummy_images = torch.rand((200, 3, 10, 10)) dummy_labels = torch.randint(2, (200, 1)) dummy_dataset = TensorDataset(dummy_images, dummy_labels) dummy_loader = DataLoader(dummy_dataset, batch_size=64, shuffle=True) iterator = iter(dummy_loader) batch1 = next(iterator) batch1[0].shape # torch.Size([64, 3, 10, 10])

batch_normalizer = nn.BatchNorm2d(num_features=3, affine=False, momentum=None) normed1 = batch_normalizer(batch1[0]) normed1.mean(axis=[0, 2, 3]), normed1.var(axis=[0, 2, 3], unbiased=False)
(tensor([ 2.3283e-08, -2.3693e-08, 8.8960e-08]),
tensor([0.9999, 0.9999, 0.9999]))




torch.manual_seed(23) dummy_points = torch.randn((100, 1)) dummy_dataset = TensorDataset(dummy_points, dummy_points) dummy_loader = DataLoader(dummy_dataset, batch_size=16, shuffle=True)

class Dummy(nn.Module): def __init__(self): super(Dummy, self).__init__() self.linear = nn.Linear(1, 1) self.activation = nn.ReLU() def forward(self, x): out = self.linear(x) out = self.activation(out) return out
torch.manual_seed(555) dummy_model = Dummy() dummy_loss_fn = nn.MSELoss() dummy_optimizer = optim.SGD(dummy_model.parameters(), lr=0.1)
dummy_sbs = StepByStep(dummy_model, dummy_loss_fn, dummy_optimizer)
dummy_sbs.set_loaders(dummy_loader)
dummy_sbs.train(200)
If we compare the actual labels with the model’s predictions, we’ll see that it failed to learn the identity function:
np.concatenate([dummy_points[:5].numpy(),
dummy_sbs.predict(dummy_points[:5])], axis=1)
array([[-0.9012059 , 0. ], [ 0.56559485, 0.56559485], [-0.48822638, 0. ], [ 0.75069577, 0.7506957 ], [ 0.58925384, 0.58925384]], dtype=float32)

class DummyResidual(nn.Module): def __init__(self): super(DummyResidual, self).__init__() self.linear = nn.Linear(1, 1) self.activation = nn.ReLU() def forward(self, x): identity = x out = self.linear(x) out = self.activation(out) out = out + identity return out
Guess what happens if we replace the Dummy model with the DummyResidual model and retrain it?
torch.manual_seed(555) dummy_model = DummyResidual() dummy_loss_fn = nn.MSELoss() dummy_optimizer = optim.SGD(dummy_model.parameters(), lr=0.1) dummy_sbs = StepByStep(dummy_model, dummy_loss_fn, dummy_optimizer) dummy_sbs.set_loaders(dummy_loader) dummy_sbs.train(200) np.concatenate([dummy_points[:5].numpy(), dummy_sbs.predict(dummy_points[:5])], axis=1)
array([[-0.9012059 , -0.9012059 ], [ 0.56559485, 0.56559485], [-0.48822638, -0.48822638], [ 0.75069577, 0.75069577], [ 0.58925384, 0.58925384]], dtype=float32)
It looks like the model actually learned the identity function … or did it? Let’s check its parameters:
dummy_model.state_dict()
OrderedDict([('linear.weight', tensor([[0.1490]])), ('linear.bias', tensor([-0.3329]))])
Close enough! I am assuming you answered 2.2352, but it is just a little bit less than that:
dummy_points.max() # tensor(2.2347)


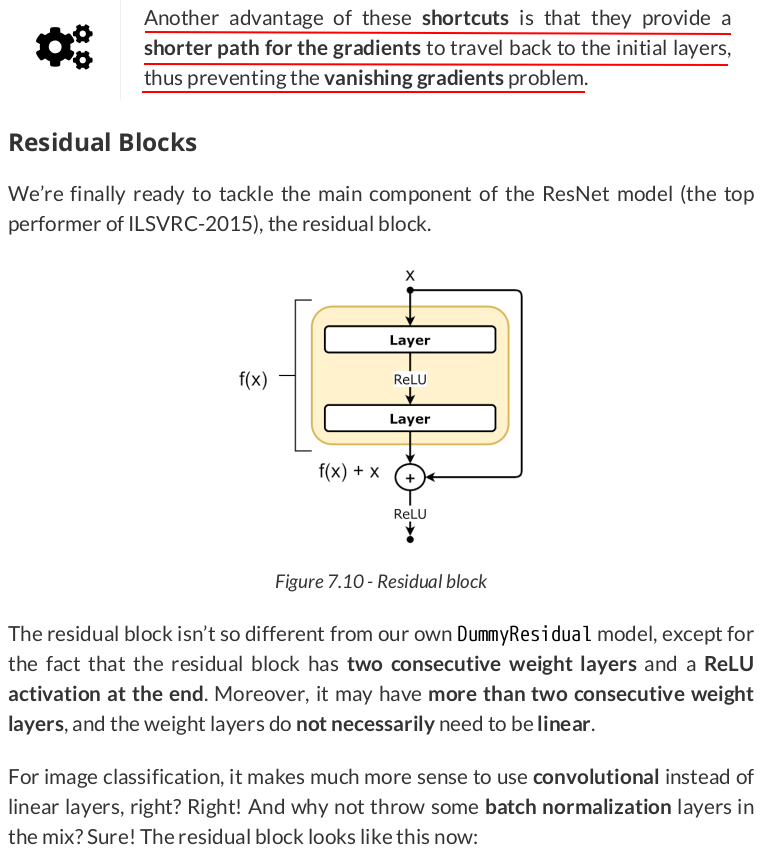
class ResidualBlock(nn.Module): def __init__(self, in_channels, out_channels, stride=1, skip=True): super(ResidualBlock, self).__init__() self.skip = skip self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1, stride=stride, bias=False) self.bn1 = nn.BatchNorm2d(out_channels) self.relu = nn.ReLU(inplace=True) self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, bias=False) self.bn2 = nn.BatchNorm2d(out_channels) self.downsample = None if out_channels != in_channels: self.downsample = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride) def forward(self, x): identity = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) if self.skip: if self.downsample is not None: identity = self.downsample(identity) out += identity out = self.relu(out) return out


scissors = Image.open('rps/scissors/scissors01-001.png') image = ToDtype(torch.float32, scale=True)(ToImage()(scissors))[:3, :, :].view(1, 3, 300, 300) seed = 14 torch.manual_seed(seed) skip_image = ResidualBlock(3, 3)(image) skip_image = ToPILImage()(skip_image[0]) torch.manual_seed(seed) noskip_image = ResidualBlock(3, 3, skip=False)(image) noskip_image = ToPILImage()(noskip_image[0])
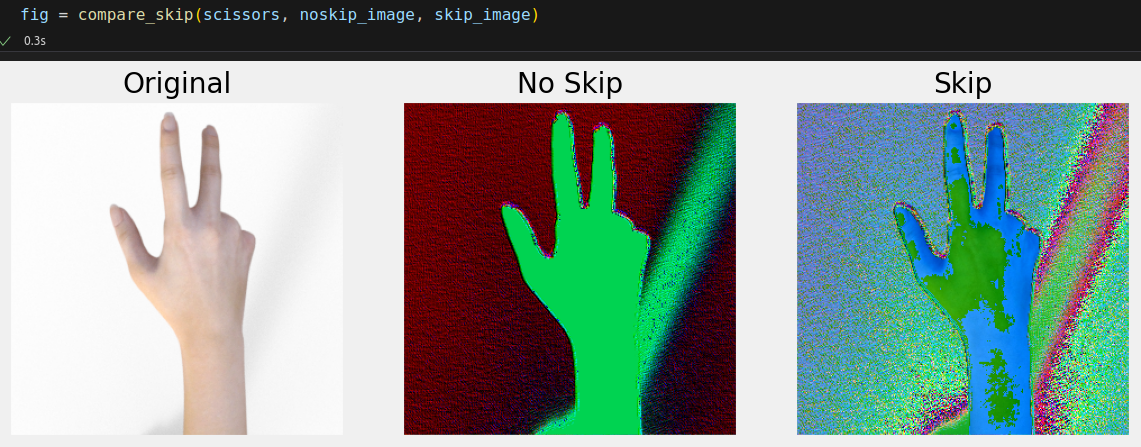

# ImageNet statistics normalizer = Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) composer = Compose([Resize(256), CenterCrop(224), ToImage(), ToDtype(torch.float32, scale=True), normalizer]) train_data = ImageFolder(root='rps', transform=composer) val_data = ImageFolder(root='rps-test-set', transform=composer) train_loader = DataLoader(train_data, batch_size=16, shuffle=True) val_loader = DataLoader(val_data, batch_size=16)

from torchvision.models import resnet18 from torchvision.models.resnet import ResNet18_Weights # UPDATED ########################################################### # This is the recommended way of loading a pretrained # model's weights model = resnet18(weights=ResNet18_Weights.DEFAULT) # model = resnet18(pretrained=True) ########################################################### torch.manual_seed(42) model.fc = nn.Linear(512, 3)
Downloading: "https://download.pytorch.org/models/resnet18-f37072fd.pth" to /home/zzh/.cache/torch/hub/checkpoints/resnet18-f37072fd.pth 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 44.7M/44.7M [00:47<00:00, 996kB/s]

ce_loss_fn = nn.CrossEntropyLoss(reduction='mean') optimizer_model = optim.Adam(model.parameters(), lr=3e-4) sbs_transfer = StepByStep(model, ce_loss_fn, optimizer_model)
Model Training
sbs_transfer.set_loaders(train_loader, val_loader)
sbs_transfer.train(1)
7m45s
Let’s see what the model can accomplish after training for a single epoch:
Evaluation
StepByStep.loader_apply(val_loader, sbs_transfer.correct)
tensor([[118, 124], [123, 124], [124, 124]])
Excellent score!

device = 'cuda' if torch.cuda.is_available() else 'cpu' # UPDATED ########################################################### model = resnet18(weights=ResNet18_Weights.DEFAULT).to(device) # model = resnet18(pretrained=True).to(device) ########################################################### model.fc = nn.Identity() freeze_model(model)
Data Preparation — Preprocessing
train_preproc = preprocessed_dataset(model, train_loader) val_preproc = preprocessed_dataset(model, val_loader) train_preproc_loader = DataLoader(train_preproc, batch_size=16, shuffle=True) val_preproc_loader = DataLoader(val_preproc, batch_size=16)

torch.manual_seed(42) top_model = nn.Sequential(nn.Linear(512, 3)) ce_loss_fn = nn.CrossEntropyLoss(reduction='mean') optimizer_top = optim.Adam(top_model.parameters(), lr=3e-4)
Model Training — Top Model
sbs_top = StepByStep(top_model, ce_loss_fn, optimizer_top)
sbs_top.set_loaders(train_preproc_loader, val_preproc_loader)
sbs_top.train(10)
We surely can evaluate the model now, as it is using the same data loaders (containing pre-processed features):
StepByStep.loader_apply(val_preproc_loader, sbs_top.correct)
tensor([[ 90, 124], [124, 124], [100, 124]])
But, if we want to try it out on the original dataset (containing the images), we need to reattach the "top" layer:
Replacing Top Layer
model.fc = top_model
sbs_temp = StepByStep(model, None, None)
We can still create a separate instance of StepByStep for the full model so as to be able to call its predict() or correct() methods (in this case, both loss function and optimizers are set to None since we won’t be training the model anymore):
StepByStep.loader_apply(val_loader, sbs_temp.correct)
tensor([[ 90, 124], [124, 124], [100, 124]])
We got the same results, as expected.




 浙公网安备 33010602011771号
浙公网安备 33010602011771号