
Technical requirements
• Install Flask and Flask-Limiter, using python -m pip install flask flask-limiter
• Install PyBreaker, using python -m pip install pybreaker
• The Throttling pattern
Throttling is an important pattern we may need to use in today’s applications and APIs. In this context, throttling means controlling the rate of requests a user (or a client service) can send to a given service or API in a given amount of time, to protect the resources of the service from being overused. For example, we may limit the number of user requests for an API to 1,000 per day. Once that limit is reached, the next request is handled by sending an error message with the 429 HTTP status code to the user with a message saying that there are too many requests.
Real-world examples
• Highway traffic management: Traffic lights or speed limits regulate the flow of vehicles on a highway
• Water faucet: Adjusting the flow of water from a faucet
• Concert ticket sales: When tickets for a popular concert go on sale, the website may limit the number of tickets each user can purchase at once to prevent the server from crashing due to a sudden surge in demand
• Electricity usage: Some utility companies offer plans where customers pay different rates based on their electricity usage during peak and off-peak hours
• Buffet line: In a buffet, customers may be limited to taking only one plate of food at a time to ensure that everyone has a fair chance to eat and to prevent food wastage
• django-throttle-requests (https://github.com/sobotklp/django-throttle-requests) is a framework for implementing application-specific rate-limiting middleware for Django projects
• Flask-Limiter (https://flask-limiter.readthedocs.io/en/stable/) provides rate-limiting features to Flask routes
Use cases for the Throttling pattern
This pattern is recommended when you need to ensure your system continuously delivers the service as expected, when you need to optimize the cost of usage of the service, or when you need to handle bursts in activity.
In practice, you may implement the following rules:
• Limit the number of total requests to an API as N/day (for example, N=1000)
• Limit the number of requests to an API as N/day from a given IP address, or from a given country or region
• Limit the number of reads or writes for authenticated users
In addition to the rate-limiting cases, it can be used for resource allocation, ensuring fair distribution of resources among multiple clients.
Implementing the Throttling pattern
Before diving into an implementation example, you need to know that there are several types of throttling, among which are Rate-Limit, IP-level Limit (based on a list of whitelisted IP addresses, for example), and Concurrent Connections Limit, to only cite those three. The first two are relatively easy to experiment with. We will focus on the first one here.
Let’s see an example of rate-limit-type throttling using a minimal web application developed using Flask and its Flask-Limiter extension.

from flask import Flask from flask_limiter import Limiter from flask_limiter.util import get_remote_address app = Flask(__name__) limiter = Limiter( get_remote_address, app=app, default_limits=["100 per day", "10 per hour"], storage_uri="memory://", strategy="fixed-window", ) @app.route("/limited") def limited_api(): return "Welcome to our API!" @app.route("/more_limited") @limiter.limit("2/minute") def more_limited_api(): return "Welcome to our expensive, thus very limited, API!" if __name__ == "__main__": app.run(debug=True)
We start with the imports we need for the example.
As is usual with Flask, we set up the Flask application.
We then define the Limiter instance; we create it by passing a key function, get_remote_address (which we imported), the application object, the default limits values, and other parameters.
Based on that, we can define a route for the /limited path, which will be rate-limited using the default limits.
We also add the definition for a route for the /more_limited path. In this case, we decorate the function with @limiter.limit("2/minute") to ensure a rate limit of two requests per minute.
Finally, we add the snippet that is conventional for Flask applications.
Then, if you point your browser to http://127.0.0.1:5000/limited, you will see the welcome content displayed on the page, as follows:
It gets interesting if you keep hitting the Refresh button. The 10th time, the page content will change and show you a Too Many Requests error message, as shown in the following screenshot:
Let’s not stop here. Remember – there is a second route in the code, /more_limited, with a specific limit of two requests per minute. To test that second route, point your browser to http://127.0.0.1:5000/more_limited. You will see new welcome content displayed on the page, as follows:
If we hit the Refresh button and do it more than twice in a window of 1 minute, we get another Two Many Requests message, as shown in the following screenshot:
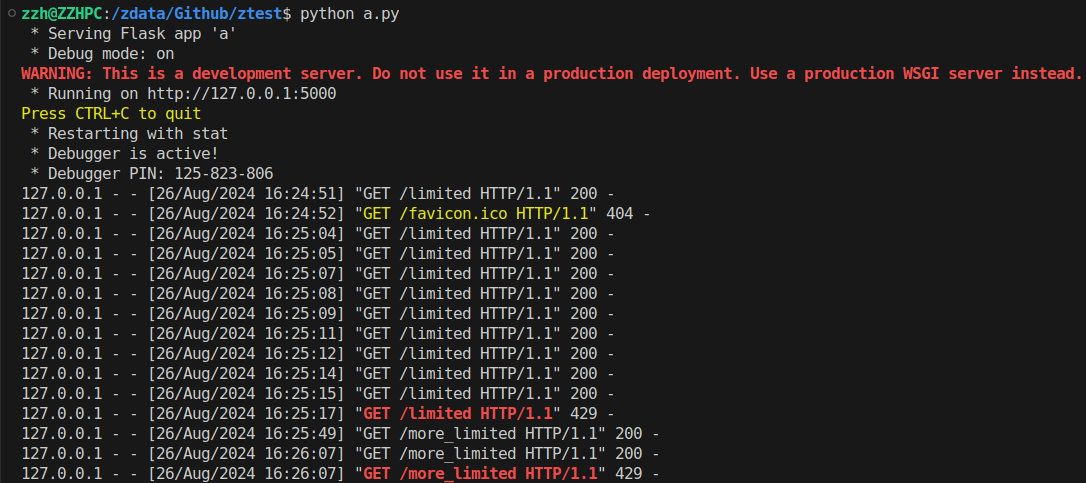
Also, looking at the console where the Flask server is running, you will notice the mention of each HTTP request received and the status code of the response the application sent. It should look like the following screenshot:
• The Retry pattern
Real-world examples
• In Python, the Retrying library (https://github.com/rholder/retrying) is available to simplify the task of adding retry behavior to our functions
• The Pester library (https://github.com/sethgrid/pester) for Go developers
Use cases for the Retry pattern
This pattern is recommended to alleviate the impact of identified transient failures while communicating with an external component or service, due to network failure or server overload.
Note that the retrying approach is not recommended for handling failures such as internal exceptions caused by errors in the application logic itself. Also, we must analyze the response from the external service. If the application experiences frequent busy faults, it’s often a sign that the service being accessed has a scaling issue that should be addressed.
We can relate retrying to the microservices architecture, where services often communicate over the network. The Retry pattern ensures that transient failures don’t cause the entire system to fail.
Another type of use case is data synchronization. When syncing data between two systems, retries can handle the temporary unavailability of one system.
Implementing the Retry pattern
In this example, we’ll implement the Retry pattern for a database connection. We’ll use a decorator to handle the retry mechanism.
import logging import random import time logging.basicConfig(level=logging.DEBUG) def retry(attempt_cnt): def decorator(func): def wrapper(*args, **kwargs): for _ in range(attempt_cnt): try: logging.info("Retry happening") return func(*args, **kwargs) except Exception as e: time.sleep(1) logging.debug(e) return "Failure after all atempts" return wrapper return decorator @retry(attempt_cnt=3) def connect_to_database(): if random.randint(0, 1): raise Exception("Temporary Database Error") return "Connected to Database" if __name__ == "__main__": for i in range(1, 6): logging.info(f"Connection attempt #{i}") print(f"--> {connect_to_database()}")
We add our function that will support the decorator to automatically retry the execution of the decorated function up to the number of attempts specified.
Then, we add the connect_to_database() function, which simulates a database connection. It is decorated by the @retry decorator. We want the decorator to automatically retry the connection up to three times if it fails.
zzh@ZZHPC:/zdata/Github/ztest$ python a.py INFO:root:Connection attempt #1 INFO:root:Retry happening --> Connected to Database INFO:root:Connection attempt #2 INFO:root:Retry happening DEBUG:root:Temporary Database Error INFO:root:Retry happening --> Connected to Database INFO:root:Connection attempt #3 INFO:root:Retry happening --> Connected to Database INFO:root:Connection attempt #4 INFO:root:Retry happening --> Connected to Database INFO:root:Connection attempt #5 INFO:root:Retry happening DEBUG:root:Temporary Database Error INFO:root:Retry happening DEBUG:root:Temporary Database Error INFO:root:Retry happening --> Connected to Database
• The Circuit Breaker pattern
One approach to FT involves retries, as we have just seen. But, when a failure due to communication with an external component is likely to be long-lasting, using a retry mechanism can affect the responsiveness of the application. We might be wasting time and resources trying to repeat a request that’s likely to fail. This is where another pattern can be useful: the Circuit Breaker pattern.
With the Circuit Breaker pattern, you wrap a fragile function call, or an integration point with an external service, in a special (circuit breaker) object, which monitors for failures. Once the failures reach a certain threshold, the circuit breaker trips and all subsequent calls to the circuit breaker return with an error, without the protected call being made at all.
Real-world examples
In life, we can think of a water or electricity distribution circuit where a circuit breaker plays an important role.
In software, a circuit breaker is used in the following examples:
• E-commerce checkout: If the payment gateway is down, the circuit breaker can halt further payment attempts, preventing system overload
• Rate-limited APIs: When an API has reached its rate limit, a circuit breaker can stop additional requests to avoid penalties
Use cases for the Circuit Breaker pattern
As already said, the Circuit Breaker pattern is recommended when you need a component from your system to be fault-tolerant to long-lasting failures when communicating with an external component, service, or resource.
Implementing the Circuit Breaker pattern
Let’s say you want to use a circuit breaker on a flaky function, a function that is fragile, for example, due to the networking environment it depends on. We are going to use the pybreaker library (https://pypi.org/project/pybreaker/) to show an example of implementing the Circuit Breaker pattern.
import pybreaker from datetime import datetime import random from time import sleep breaker = pybreaker.CircuitBreaker(fail_max=2, reset_timeout=5) @breaker def fragile_function(): if random.choice([True, False]): print(" / OK", end="") else: print(" / FAIL", end="") raise Exception("This is a sample Exception") def main(): while True: print(datetime.now().strftime("%Y-%m-%d %H:%M:%S"), end="") try: fragile_function() except Exception as e: print(" / {} {}".format(type(e), e), end="") finally: print("") sleep(1) if __name__ == "__main__": main()
zzh@ZZHPC:/zdata/Github/ztest$ python a.py 2024-08-26 19:55:05 / OK 2024-08-26 19:55:06 / FAIL / <class 'Exception'> This is a sample Exception 2024-08-26 19:55:07 / OK 2024-08-26 19:55:08 / FAIL / <class 'Exception'> This is a sample Exception 2024-08-26 19:55:09 / FAIL / <class 'pybreaker.CircuitBreakerError'> Failures threshold reached, circuit breaker opened 2024-08-26 19:55:10 / <class 'pybreaker.CircuitBreakerError'> Timeout not elapsed yet, circuit breaker still open 2024-08-26 19:55:11 / <class 'pybreaker.CircuitBreakerError'> Timeout not elapsed yet, circuit breaker still open 2024-08-26 19:55:12 / <class 'pybreaker.CircuitBreakerError'> Timeout not elapsed yet, circuit breaker still open 2024-08-26 19:55:13 / <class 'pybreaker.CircuitBreakerError'> Timeout not elapsed yet, circuit breaker still open 2024-08-26 19:55:14 / FAIL / <class 'pybreaker.CircuitBreakerError'> Trial call failed, circuit breaker opened 2024-08-26 19:55:15 / <class 'pybreaker.CircuitBreakerError'> Timeout not elapsed yet, circuit breaker still open 2024-08-26 19:55:16 / <class 'pybreaker.CircuitBreakerError'> Timeout not elapsed yet, circuit breaker still open 2024-08-26 19:55:17 / <class 'pybreaker.CircuitBreakerError'> Timeout not elapsed yet, circuit breaker still open 2024-08-26 19:55:18 / <class 'pybreaker.CircuitBreakerError'> Timeout not elapsed yet, circuit breaker still open 2024-08-26 19:55:19 / OK 2024-08-26 19:55:20 / FAIL / <class 'Exception'> This is a sample Exception 2024-08-26 19:55:21 / FAIL / <class 'pybreaker.CircuitBreakerError'> Failures threshold reached, circuit breaker opened 2024-08-26 19:55:22 / <class 'pybreaker.CircuitBreakerError'> Timeout not elapsed yet, circuit breaker still open 2024-08-26 19:55:23 / <class 'pybreaker.CircuitBreakerError'> Timeout not elapsed yet, circuit breaker still open 2024-08-26 19:55:24 / <class 'pybreaker.CircuitBreakerError'> Timeout not elapsed yet, circuit breaker still open 2024-08-26 19:55:25 / <class 'pybreaker.CircuitBreakerError'> Timeout not elapsed yet, circuit breaker still open 2024-08-26 19:55:26 / FAIL / <class 'pybreaker.CircuitBreakerError'> Trial call failed, circuit breaker opened 2024-08-26 19:55:27 / <class 'pybreaker.CircuitBreakerError'> Timeout not elapsed yet, circuit breaker still open 2024-08-26 19:55:28 / <class 'pybreaker.CircuitBreakerError'> Timeout not elapsed yet, circuit breaker still open 2024-08-26 19:55:29 / <class 'pybreaker.CircuitBreakerError'> Timeout not elapsed yet, circuit breaker still open 2024-08-26 19:55:30 / <class 'pybreaker.CircuitBreakerError'> Timeout not elapsed yet, circuit breaker still open
By closely looking at the output, we can see that the circuit breaker does its job as expected: when it is open, all fragile_function() calls fail immediately (since they raise the CircuitBreakerError exception) without any attempt to execute the intended operation. And, after a timeout of 5 seconds, the circuit breaker will allow the next call to go through. If that call succeeds, the circuit is closed; if it fails, the circuit is opened again until another timeout elapses.
• Other distributed systems patterns
There are many more distributed systems patterns than the ones we covered here. Among the other patterns developers and architects can use are the following:
• Command and Query Responsibility Segregation (CQRS): This pattern separates the responsibilities for reading and writing data, allowing for optimized data access and scalability by tailoring data models and operations to specific use cases
• Two-Phase Commit: This distributed transaction protocol ensures atomicity and consistency across multiple participating resources by coordinating a two-phase commit process, involving a prepare phase followed by a commit phase
• Saga: A saga is a sequence of local transactions that together form a distributed transaction, providing a compensating mechanism to maintain consistency in the face of partial failures or aborted transactions
• Sidecar: The Sidecar pattern involves deploying additional helper services alongside primary services to enhance functionality, such as adding monitoring, logging, or security features without directly modifying the main application
• Service Registry: This pattern centralizes the management and discovery of services within a distributed system, allowing services to dynamically register and discover each other, facilitating communication and scalability
• Bulkhead: Inspired by ship design, the Bulkhead pattern partitions resources or components within a system to isolate failures and prevent cascading failures from impacting other parts of the system, thereby enhancing FT and resilience
Each of these patterns addresses specific challenges inherent in distributed systems, offering strategies and best practices for architects and developers to design robust and scalable solutions capable of operating in dynamic and unpredictable environments.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律