
We should understand the distinction between a charset and an encoding:
A charset, as the name suggests, is a set of characters. For example, the Unicode charset contains 2^21 characters.
An encoding is the translation of a character’s list in binary. For example, UTF-8 is an encoding standard capable of encoding all the Unicode characters in a variable number of bytes (from 1 to 4 bytes).
We mentioned characters to simplify the charset definition. But in Unicode, we use the concept of a code point to refer to an item represented by a single value. For example, the 汉 character is identified by the U+6C49 code point. Using UTF-8, 汉 is encoded using three bytes: 0xE6, 0xB1, and 0x89. Why is this important? Because in Go, a rune is a Unicode code point.
Meanwhile, we mentioned that UTF-8 encodes characters into 1 to 4 bytes, hence, up to 32 bits. This is why in Go, a rune is an alias of int32:
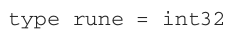
Another thing to highlight about UTF-8: some people believe that Go strings are always UTF-8, but this isn’t true. Let’s consider the following example:
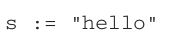
We assign a string literal (a string constant) to s. In Go, a source code is encoded in UTF-8. So, all string literals are encoded into a sequence of bytes using UTF-8. However, a string is a sequence of arbitrary bytes; it’s not necessarily based on UTF-8. Hence, when we manipulate a variable that wasn’t initialized from a string literal (for example, reading from the filesystem), we can’t necessarily assume that it uses the UTF-8 encoding.
Let’s get back to the hello example. We have a string composed of five characters: h, e, l, l, and o. These simple characters are encoded using a single byte each. This is why getting the length of s returns 5:

But a character isn’t always encoded into a single byte. Coming back to the 汉 character, we mentioned that with UTF-8, this character is encoded into three bytes. We can validate this with the following example:

Instead of printing 1, this example prints 3. Indeed, the len built-in function applied on a string doesn’t return the number of characters; it returns the number of bytes. Conversely, we can create a string from a list of bytes. We mentioned that the 汉 character was encoded using three bytes, 0xE6, 0xB1, and 0x89:

Here, we build a string composed of these three bytes. When we print the string, instead of printing three characters, the code prints a single one: 汉.
In summary:
A charset is a set of characters, whereas an encoding describes how to translate a charset into binary.
In Go, a string references an immutable slice of arbitrary bytes.
Go source code is encoded using UTF-8. Hence, all string literals are UTF-8 strings. But because a string can contain arbitrary bytes, if it’s obtained from somewhere else (not the source code), it isn’t guaranteed to be based on the UTF-8 encoding.
A rune corresponds to the concept of a Unicode code point, meaning an item represented by a single value.
Using UTF-8, a Unicode code point can be encoded into 1 to 4 bytes.
Using len on a string in Go returns the number of bytes, not the number of runes.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律