
Warning FailedScheduling 89s default-scheduler 0/1 nodes are available: 1 node(s) had untolerated taint {node.cloudprovider.kubernetes.io │
│ /uninitialized: true}. preemption: 0/1 nodes are available: 1 Preemption is not helpful for scheduling.. │
│ Warning FailedScheduling 77s default-scheduler 0/1 nodes are available: 1 Too many pods. preemption: 0/1 nodes are available: 1 No preemp │
│ tion victims found for incoming pod..
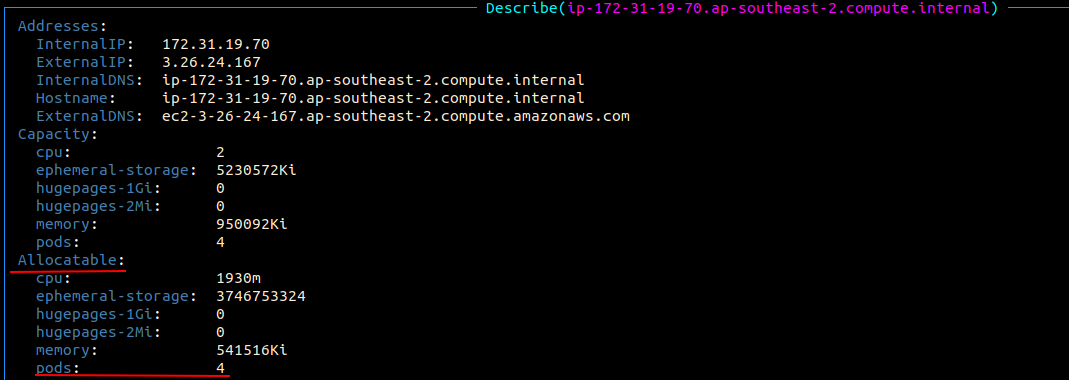
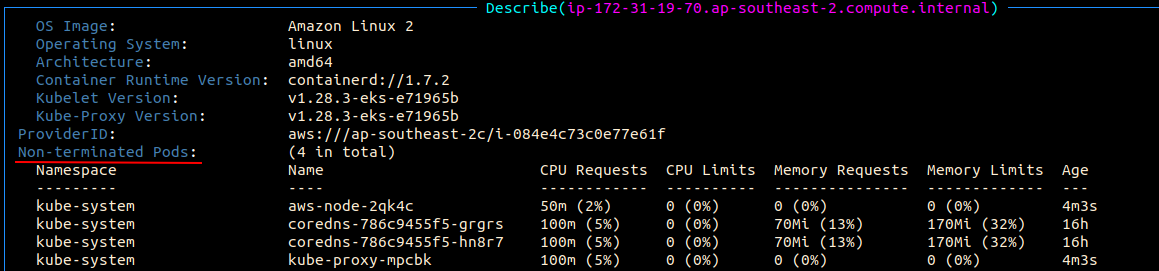
The cause is that 4 running kube-system pods have taken up all allocatable pod slots.
How the maximum number of pods is calculated can be found here: https://github.com/awslabs/amazon-eks-ami/blob/master/files/eni-max-pods.txt :

# Mapping is calculated from AWS EC2 API using the following formula: # * First IP on each ENI is not used for pods # * +2 for the pods that use host-networking (AWS CNI and kube-proxy) # # # of ENI * (# of IPv4 per ENI - 1) + 2 # # https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-eni.html#AvailableIpPerENI ...... t3.micro 4 t3.nano 4 t3.small 11 ......
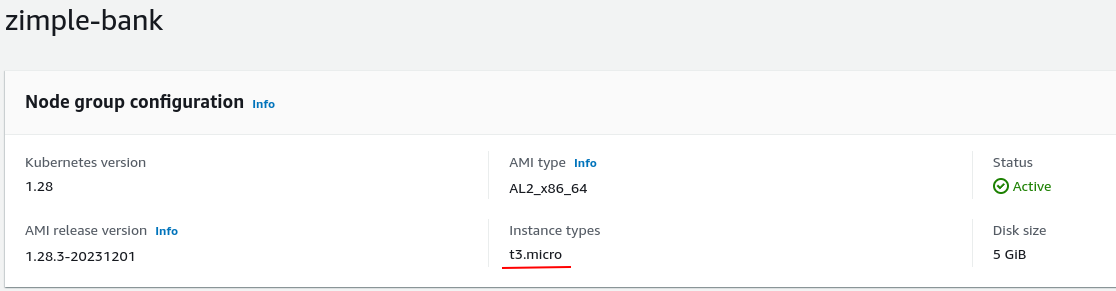
The resolution will be deleting the node group and creating a new one with instance type of t3.small.
After deleting the node group, need to manually delete the deployment, because deleting node group won't automatically delete deployment. By the way, deleting depoyment will delete its managed pods as well.



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律