
sk_learn 中使用SVM使用以及参数意义
1 准备数据集
1 from sklearn.datasets import make_moons 2 X, y = make_moons(n_samples=100, noise=0.15, random_state=42)
2 训练模型
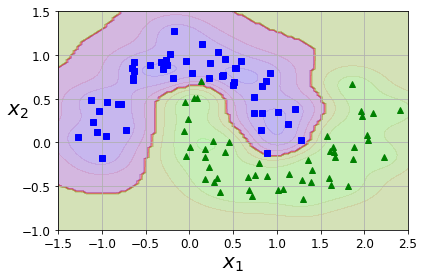
1 from sklearn.pipeline import Pipeline 2 from sklearn.preprocessing import PolynomialFeatures, StandardScaler 3 4 rbf_svm_clf = Pipeline([ 5 ('scaler', StandardScaler()), 6 ('svm_clf', SVC(C = 1, kernel='rbf', gamma = 5)) 7 ]) 8 9 rbf_svm_clf.fit(X, y)
3 结果可视化
1 def plot_dataset(X, y, axes): 2 plt.plot(X[:, 0][y==0], X[:, 1][y==0], "bs") 3 plt.plot(X[:, 0][y==1], X[:, 1][y==1], "g^") 4 plt.axis(axes) 5 plt.grid(True, which='both') 6 plt.xlabel(r"$x_1$", fontsize=20) 7 plt.ylabel(r"$x_2$", fontsize=20, rotation=0) 8 9 def plot_predictions(clf, axes): 10 x0s = np.linspace(axes[0], axes[1], 100) 11 x1s = np.linspace(axes[2], axes[3], 100) 12 x0, x1 = np.meshgrid(x0s, x1s) 13 X = np.c_[x0.ravel(), x1.ravel()] 14 y_pred = clf.predict(X).reshape(x0.shape) 15 y_decision = clf.decision_function(X).reshape(x0.shape) 16 plt.contourf(x0, x1, y_pred, cmap=plt.cm.brg, alpha=0.2) 17 plt.contourf(x0, x1, y_decision, cmap=plt.cm.brg, alpha=0.1) 18 19 plot_predictions(polynomial_svm_clf, [-1.5, 2.5, -1, 1.5]) 20 plot_dataset(X, y, [-1.5, 2.5, -1, 1.5]) 21 22 save_fig("moons_polynomial_svc_plot") 23 plt.show()
结果如下图所示:
注:
核函数使用 rbf(高斯核) 时候,超参数 gamma 表示分离超平面的非线性程度,gamma越大,非线性越强,模型越容易过拟合。
C 同理,不过超参数C代表的是模型对误分类点的惩罚程度,C越大,惩罚越大,模型越容易过拟合训练集数据。

