
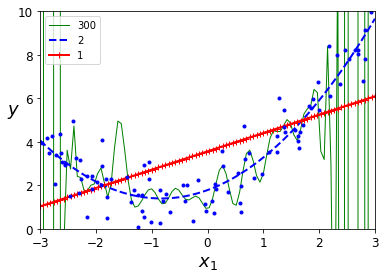
分别用1,2,300次多项式拟合数据集以及Pipeline使用
1 import numpy as np 2 import matplotlib.pyplot as plt 3 from sklearn.linear_model import LinearRegression 4 from sklearn.preprocessing import PolynomialFeatures 5 from sklearn.preprocessing import StandardScaler 6 from sklearn.pipeline import Pipeline 7 8 np.random.seed(42) 9 10 m = 100 #实例个数 11 X = 6 * np.random.rand(m, 1) - 3 #在0,3之间选取100个均匀随机数 12 y = 2 + X + 0.5 * X**2 + np.random.randn(m, 1) #随机创建实例的关系式,最后一项为噪音 13 14 X_new=np.linspace(-3, 3, 100).reshape(100, 1) #*-3到3范围选出100个间隔均匀数字作为描点的横坐标 15 16 for style, width, degree in (('g-', 1, 300), ('b--', 2, 2), ('r-+', 2, 1)): 17 polybig_features = PolynomialFeatures(degree=degree, include_bias=False) 18 std_scaler = StandardScaler() #*特征缩放 19 lin_reg = LinearRegression() 20 polynomial_regression = Pipeline([ 21 ("poly_features", polybig_features), 22 ("std_scaler", std_scaler), 23 ("lin_reg", lin_reg), 24 ]) 25 polynomial_regression.fit(X, y) 26 y_newbig = polynomial_regression.predict(X_new) 27 plt.plot(X_new, y_newbig, style, label=str(degree), linewidth=width) 28 29 plt.plot(X, y, "b.", linewidth=3) 30 plt.legend(loc="upper left") 31 plt.xlabel("$x_1$", fontsize=18) 32 plt.ylabel("$y$", rotation=0, fontsize=18) 33 plt.axis([-3, 3, 0, 10]) 34 plt.show()
结果如图所示,蓝色图线拟合最好。
注:
1. 多项式回归相当于:对原始数据集中添加新的高次项特征得到新的假设函数之后,再对新假设函数进行线性回归求得各项系数
2. pipeline相当于一个内含多个模型的管道,对灌入的数据流依次处理。代码行21 ~ 23 依次对数据进行 特征增加、特征缩放、特征拟合。

