
node的知识点
(一)Node能够解决什么问题?
1)Node的首要目标是提供一种简单的,用于创建高性能服务器的开发工具
2)对比Java和Php的实现方式,Web服务器的瓶颈在于并发的用户量
3)Node在处理高并发,I/O密集场景有明显的性能优势
1)高并发,是指在同一时间并发访问服务器
2)I/O密集指的是文件操作、网络操作、数据库
3)与I/O密集相对的是CPU密集,CPU密集指的是逻辑处理运算、压缩、解压、加密、解密
4)Web主要场景就是接收客户端的请求,读取静态资源和渲染界面,所以Node非常适合Web应用的开发
2)Node出现的背景
为了解决Web服务器的高并发性能问题
1)什么性能问题?

1)缩短发送到响应的时长
1)发送请求快一点
不能控制(客户端网速决定)
2)响应快一点
可以控制(服务器带宽提高, CDN加速...)
3)服务器处理请求任务快一点
可以控制(优秀的程序员)
4)服务器从磁盘读取/写入数据到数据库快一点
所有项目后期都会遇到的瓶颈
不能控制(磁盘的读取速度有上限)
....
2)传统服务器的运作流程
多线程
发送一个请求就开启一条线程
举例: 饭店服务员
需要大量的资源支持
2)Ryan Dahl(瑞安·达尔)尝试过用Ruby, c, Lua去解决, 但都因为语言自身的各种限制而一一失败
江山易改,本性难移
语言历史包袱太重, 船大难掉头
各种语言的思想都根深蒂固, 生态没法轻易改变
3)V8引擎的出现
渐渐摸索到解决问题的钥匙
事件驱动
异步I/O
3)V8引擎的出现
1)什么是V8引擎?
一款专门对JavaScript语言进行解释和执行的流程虚拟机
比如把V8引擎嵌入到浏览器中,那么我们写的JavaScript代码就会被浏览器所执行;那么如果把V8引擎嵌入到NodeJS环境下,那么我们写的JavaScript代码就会被服务器所执行
V8引擎嵌入到不同的宿主环境中时,可以把JavaScript语言应用到不同的多领域中
2)起初的作用?
用于Chrome浏览器解析js脚本
比如: 发送HTTP请求给服务器, 响应服务器端返回的HTTP请求
3)V8引擎的优势?
1)强大的编译和快速的执行效率
运用了大量的算法和奇技淫巧
2)性能非常好, 它的执行效率远超Python, Ruby等其它脚本语言
3)历史包袱轻, 没有同步I/O
4)强大的事件驱动机制
4)Node的诞生 Ryan Dahl(瑞安·达尔)修改V8引擎的内核, 把它用在了服务器开发, 经过修改后的这样一套东西就被称为Node.js
(三) Node.js简介
1)什么是Node.js
1)Node.js是一个基于 Chrome V8 引擎的JavaScript运行环境(runtime)
1)Node不是一门语言,而是一个开发工具,让JS运行在后端
2)Node不包含JavaScript全集,在服务器端没有DOM和BOM
3)Node也提供了一系列新的模块,例如:http,fs模块等
4)Node之前, js代码只能运行在客户端, 最多只能在浏览器内翻江倒海
5)Node之后, js代码可以和操作系统(Mac OS, windows, Linux...)交互, 战场从浏览器延伸到了服务器
6)版本变化
一开始叫Web.js, 目的就是用于写高性能Web服务器的
越写越大, 形成生态(服务器开发, 各种框架的依赖...), 改名为Node.js
Node: 节点, Node的开源团队希望它像节点一样可以不断扩展, 壮大
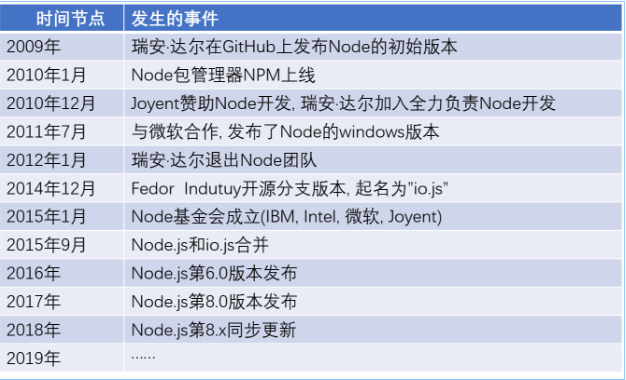
图示
2)功能类似的其他后端语言
PHP、JSP、Python、Ruby
和系统进行交互
3)和其它后端语言的区别
1)Node.js不是一种独立的语言
1)PHP, JSP,.... 既是语言, 也是平台
2)Node.js用JavaScript进行编程, 运行平台是包装后的js引擎(V8)
2)轻量级架构
1)java,php,.net都需要运行在服务器上,apache,tomat,nginx,IIS
2)Node.js不用架设在任何服务器软件之上
3)用最小的硬件成本, 达到更高的并发, 更优的处理性能
4)Node.js 使用了事件驱动、非阻塞式 I/O 的模型,使其轻量又高效;并且Node.js 的包管理器 npm,是全球最大的开源库生态系统
2)进程与线程 1)概念
1)进程是操作系统分配资源和调度任务的基本单位
2)线程是建立在进程上的一次程序运行单位,一个进程上可以有多个线程
2)浏览器是单线程还是多线程?
1)图示

3)浏览器是多线程的,我们更关注的是浏览器的渲染引擎
3)渲染引擎
1)渲染引擎内部是多线程的,内部包含两个最为重要的线程ui线程和js线程
2)ui线程和js线程是互斥的,因为JS运行结果会影响到ui线程的结果
3)ui更新会被保存在队列中等到js线程空闲时立即被执行
4)JS是单线程的
1)JS在最初设计时就设计成了单线程,因为当时是用于UI绘制,多个线程同时操作DOM会很混乱
2)这里所说的单线程指的是主线程是单线程的,所以在Node中主线程依旧是单线程的
3)其他线程
1)浏览器事件触发线程(用来控制事件循环,存放setTimeout、浏览器事件、ajax的回调函数)
2)定时触发器线程(setTimeout定时器所在线程)
3)异步HTTP请求线程(ajax请求线程
4)补充
1)单线程特点是节约了内存,并且不需要再切换执行上下文
2)而且单线程不需要管锁的问题
例如:下课了大家都要去上厕所,厕所就一个大号,相当于所有人都要访问同一个资源,那么先进去的就要上锁
而对于node来说,下课了就一个人去厕所,所以免除了锁的问题
5)查看线程
右击 任务栏 -->任务管理器 --> 进程
3)事件循环
1)图示
2)运行原理
1)所有同步任务都在主线程上执行,形成一个执行栈
2)主线程之外,还存在一个任务队列;只要异步任务有了运行结果,就在任务队列之中放置一个事件
3)一旦执行栈中的所有同步任务执行完毕,系统就会读取任务队列,将队列中的事件放到执行栈中依次执行
4)主线程从任务队列中读取事件,这个过程是循环不断的
4)Node运行过程
1)图示
2)运行过程
1)我们写的js代码会交给v8引擎进行处理
2)代码中可能会调用nodeApi,node会交给libuv库处理
3)libuv通过阻塞i/o和多线程实现了异步io
4)通过事件驱动的方式,将结果放到事件队列中,最终交给我们的应用
3)同步与异步
同步和异步关注的是消息通知机制
2)同步
同步就是发出调用后,没有得到结果之前,该调用不返回,一旦调用返回,就得到返回值了
调用者主动等待这个调用的结果
3)异步
异步则相反,调用者在发出调用后这个调用就直接返回了,所以没有返回结果
当一个异步过程调用发出后,调用者不会立刻得到结果,而是调用发出后,被调用者通过状态、通知或回调函数处理这个调用
4)阻塞与非阻塞
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态
2)阻塞调用
指调用结果返回之前,当前线程会被挂起
调用线程只有在得到结果之后才会返回
3)非阻塞调用
在不能立刻得到结果之前,该调用不会阻塞当前线程
2)Node.js的特点
1)单线程
1)优势
减少了内存开销(操作系统完全不再有线程创建、销毁的时间开销)
Node.js不为每个客户连接创建一个新的线程,而仅仅使用一个线程
2)劣势
如果某一个事情,进入了,但是被I/O阻塞了,整个线程就阻塞了
如果一个人把Node.js主线程搞崩溃,全部崩溃(但很难搞崩溃)
2)非阻塞I/O
1)基本概念?
当在访问数据库取得数据的时候,需要一段时间。在传统的单线程处理机制中,在执行了访问数据库代码之后,整个线程都将暂停下来,等待数据库返回结果,才能执行后面的代码。也就是说,I/O阻塞了代码的执行,极大地降低了程序的执行效率
不会傻等I/O语句结束,而会执行后面的语句
Node.js中采用了非阻塞型I/O机制,因此在执行了访问数据库的代码之后,将立即转而执行其后面的代码,把数据库返回结果的处理代码放在回调函数中,从而提高了程序的执行效率
当某个I/O执行完毕时,将以事件的形式通知执行I/O操作的线程,线程执行这个事件的回调函数。为了处理异步I/O,线程必须有事件循环,不断的检查有没有未处理的事件,依次予以处理
阻塞模式下,一个线程只能处理一项任务,要想提高吞吐量必须通过多线程。而非阻塞模式下,一个线程永远在执行运行操作,这个线程的CPU核心利用率永远是100%
所以,这是一种特别有哲理的解决方案:与其人多,但是好多人闲着;还不如一个人玩命,往死里干活儿
2)非阻塞就能解决问题了么?
比如执行着小红的业务,执行过程中,小刚的I/O回调完成了,此时怎么办??所以要有事件驱动循环
3)事件驱动
1)基本概念?
不管是新用户的请求,还是老用户的I/O完成,都将以事件方式加入事件环,等待调度
2)运作流程?
1)在Node中,客户端请求建立连接,提交数据等行为,会触发相应的事件
2)在Node中,在一个时刻,只能执行一个事件回调函数, 但是在执行一个事件回调函数的中途,可以转而处理其他事件(比如,又有新用户连接了),然后返回继续执行原事件的回调函数,这种处理机制,称为“事件环”机制。
3)当某一个事件发生的时候,就去执行回调函数。执行完毕之后,再去找到事件循环当中找一个新的事件进行来
4)Node.js当中所有的I/O都是异步的, 都是回调函数套回调函数
3)实践2
1)模块标识
当我们使用require()引入外部模块时,使用的就是模块标识,我们可以通过模块标识来找到指定的模块
比如: let myFunc = require("./js/myFunc");
2)思考: export和require怎么来的?
1)错误答案: 全局变量
1)window不是Node中的全局对象
2)Node中有一个全局对象global, 作用和window类似
2)正确答案: 函数参数
1)函数的标识: arguments
获取函数的所有实参
2)获取函数自身 arguments.callee
返回函数本身
3)node文件组成剖析
1)当node在执行模块中的代码时,它会首先在代码的最顶部,添加如下代码 function (exports, require, module, __filename, __dirname) {
2) 在代码的最底部,添加 }
3)所以模块中的代码都是包装在一个函数中执行的,并且在函数执行的同时传递进了5个实参
exports: 该对象用来将函数内部的局部变量或局部函数暴露到外部
require: 用来引入外部的模块
module: 代表的是当前模块本身, exports就是module的属性; 我们既可以使用 exports 导出,也可以使用module.exports导出
__filename: 当前模块的完整路径
__dirname: 当前模块所在文件夹的完整路径

 浙公网安备 33010602011771号
浙公网安备 33010602011771号