

python爬虫
9
8
7
6.request-xhr
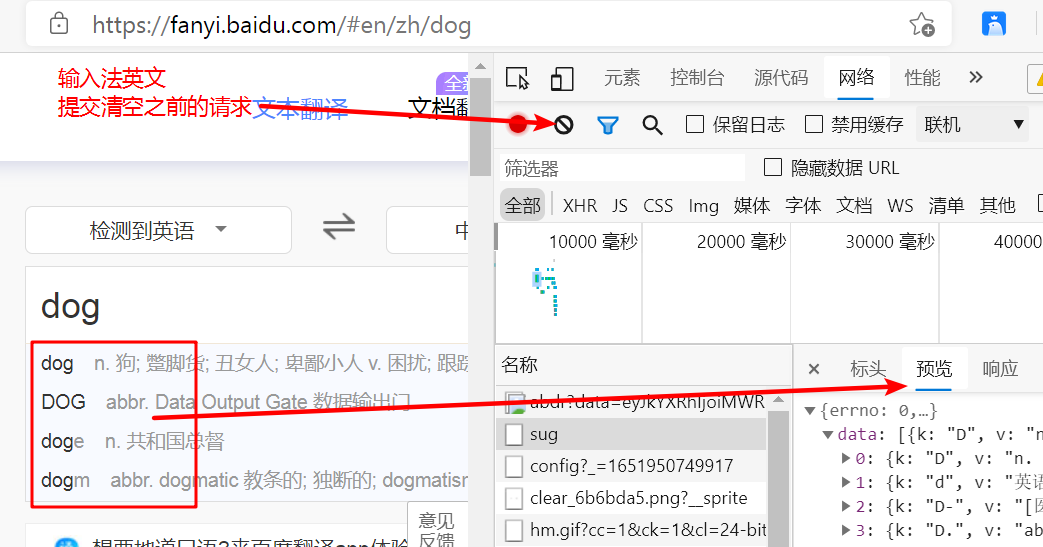
xhr 二次请求的数据
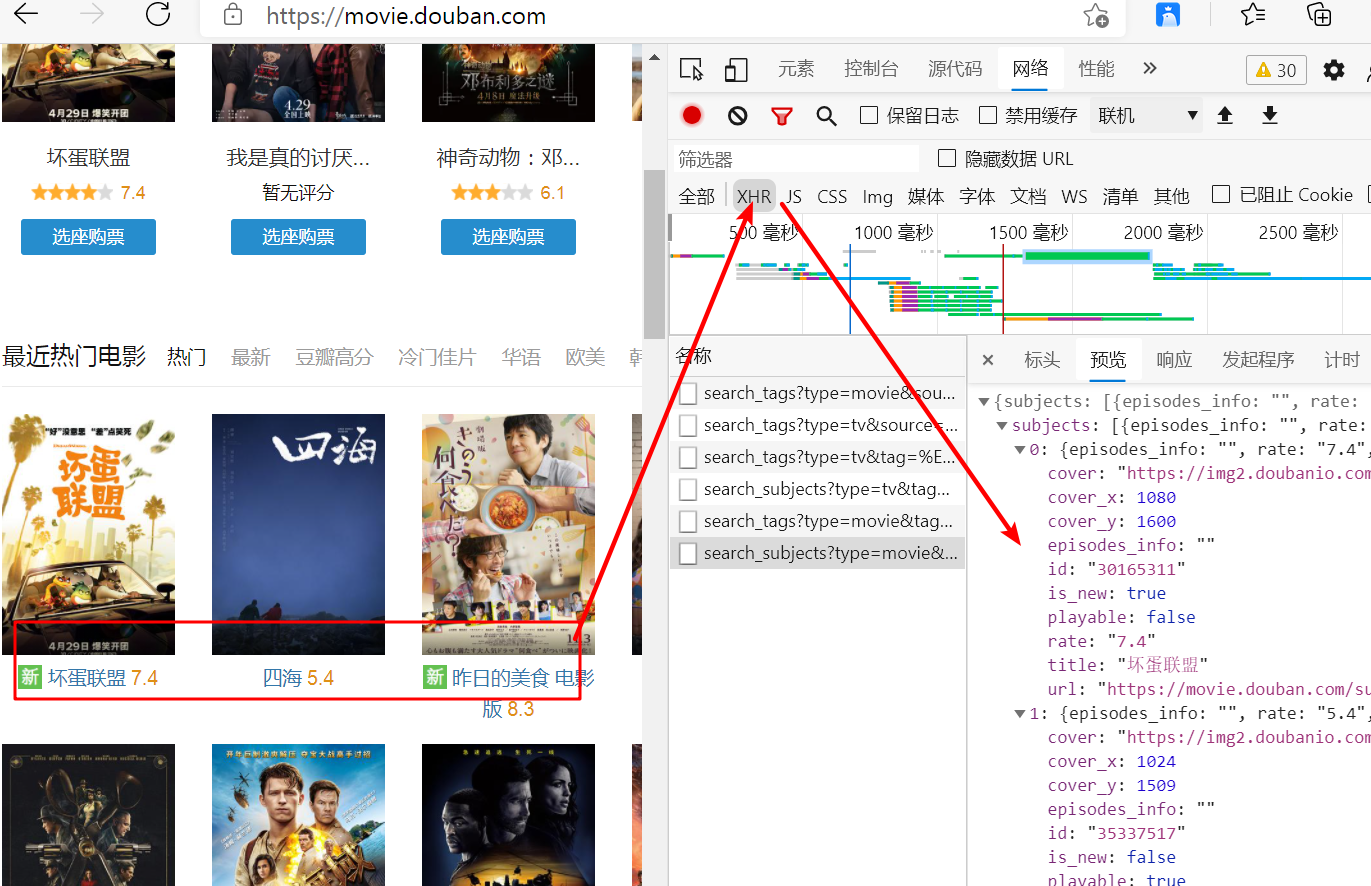
随便看一个请求
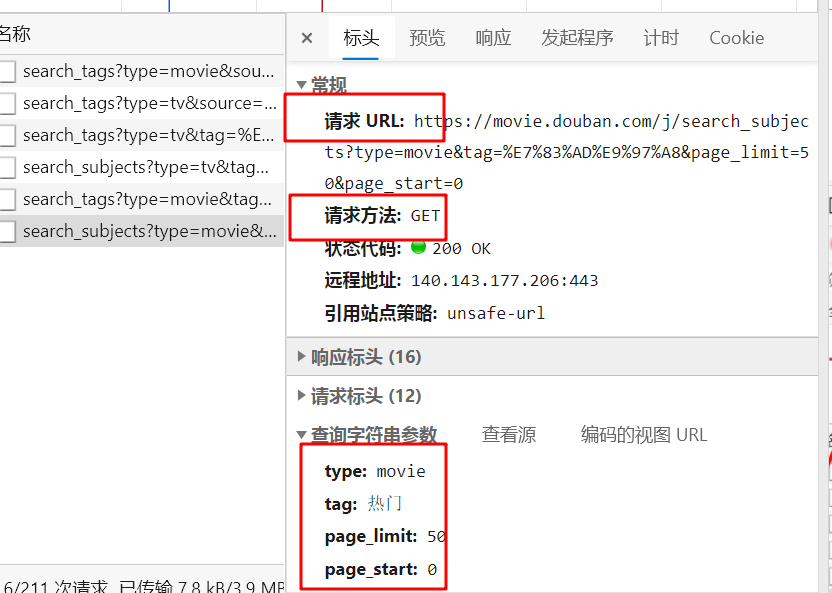
有了这三个就可以写爬虫了 注意这种链接比较长的
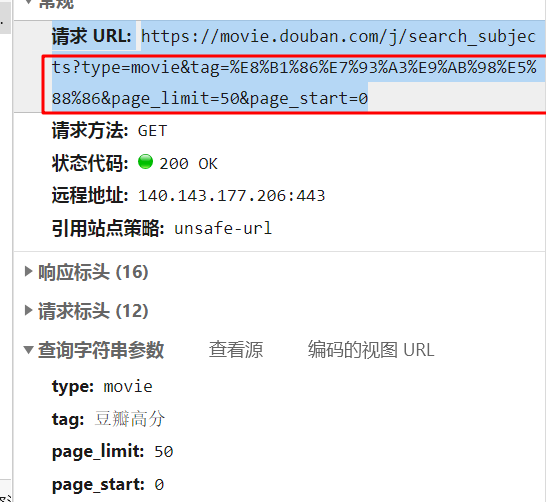
可以把他参数写在字典里 ?后面就是提交的参数
import requests
url= "https://movie.douban.com/j/search_subjects"
parms ={
"type": "movie",
"tag": "豆瓣高分",
"page_limit": "50",
"page_start": "0"
}
res = requests.get(url,params=parms)
print(res.request.url)
print("https://movie.douban.com/j/search_subjects?type=movie&tag=%E8%B1%86%E7%93%A3%E9%AB%98%E5%88%86&page_limit=50&page_start=0")
可以这两个地址是一样的
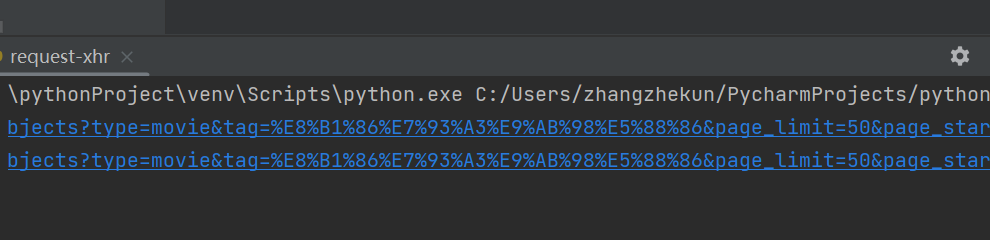
如果拼接好的地址获取不到数据
首先要判断是不是ua有问题
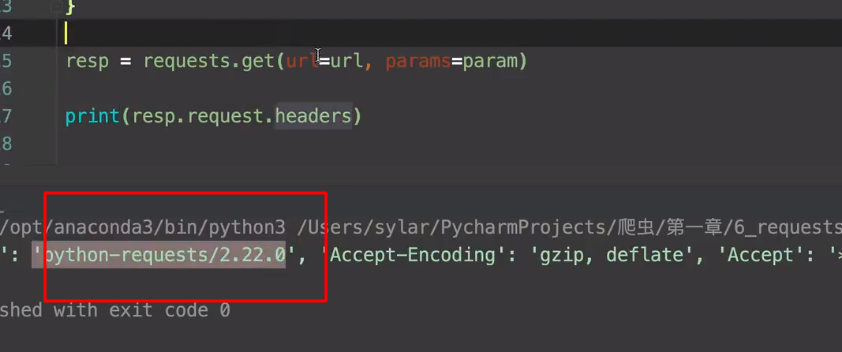
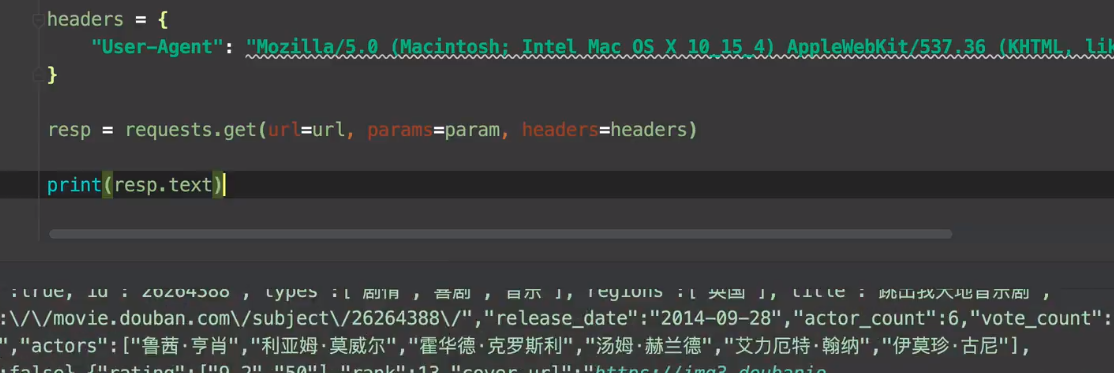
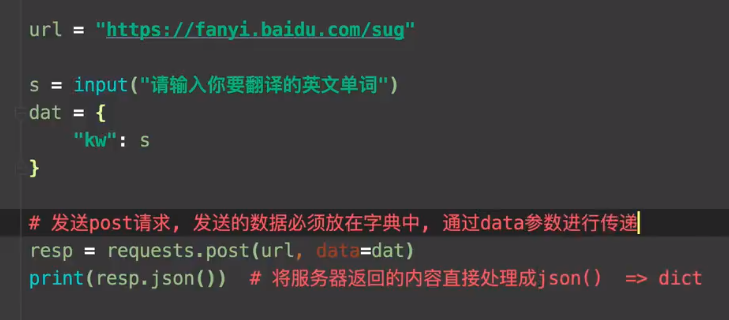
5.request-post
4.request 入门
进一步简化 urllib.response
使用方法
pip install request
pycharm 命令行安装
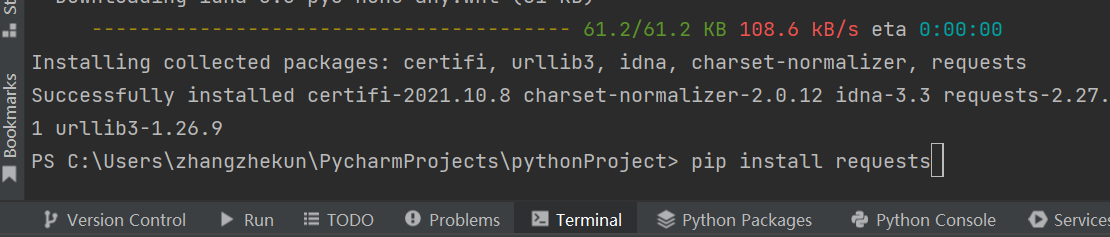
对于没用使用过pycharm 的同学 也不用纠结
什么pip 包啊 源啊 什么virtualenv啊 先找个教程学着
学习曲线 怎么平滑怎么来
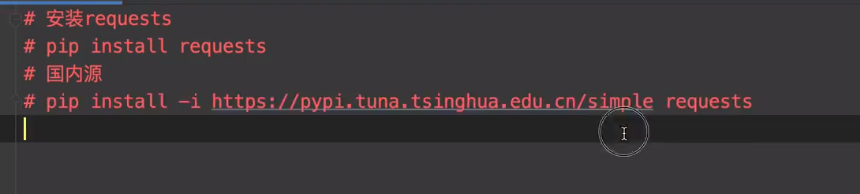
果然还是碰到了问题
命令行安装了 requests 导入包发现找不到
搜了下发现时 因为一开始用pycharm 设置的是virtualenv
所以需要重新在pycharm的设置里面重新下载request
file —> setting —>project —> project —> interprefer —>点击+ —>搜索 requests
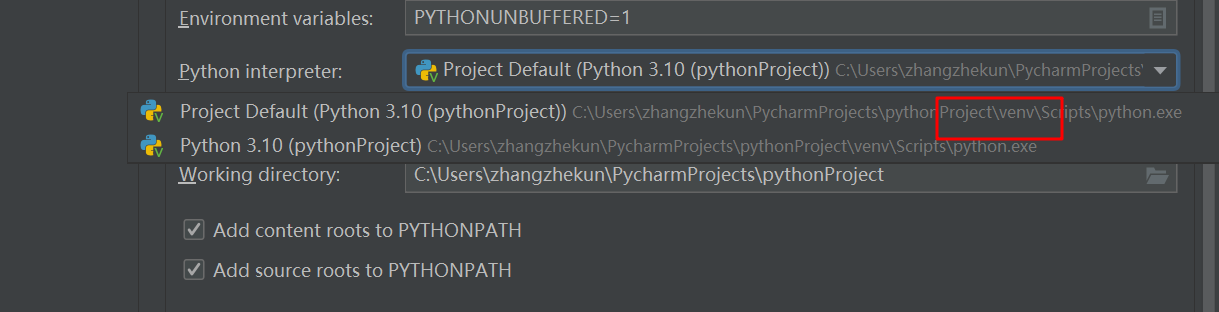
ok 第一个坎过了
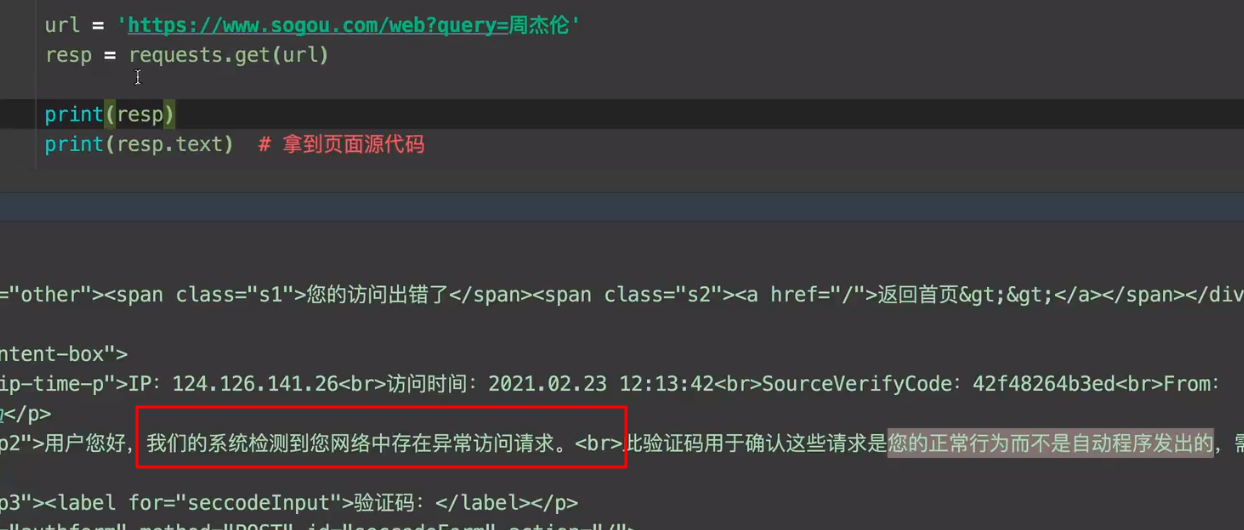
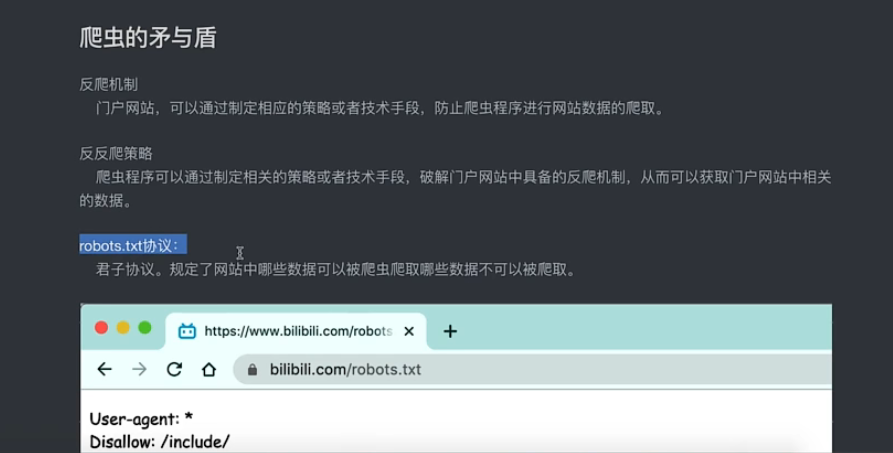
如果出现了反扒拦截
需要把请求伪装成 浏览器的get请求
Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.81
import requests
# url = "http://188977.com"
url="https://www.baidu.com/s?wd=vergin"
# head={ "User-Agent":"Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 Edg/88.0.705.81"}
# res = requests.get(url,headers=head)
res = requests.get(url)
# 如果不处理head 不会返回网页数据
print(res)
print(res.text)
3.http协议
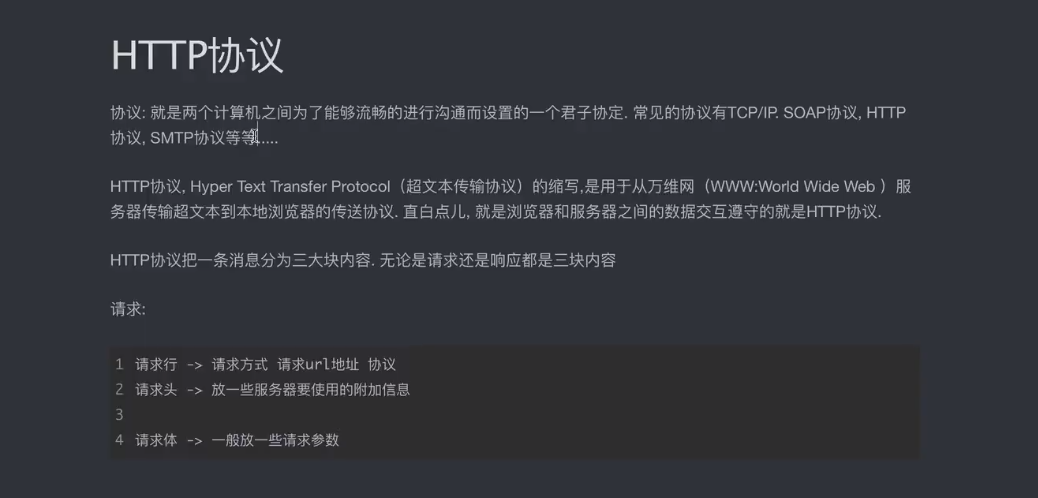
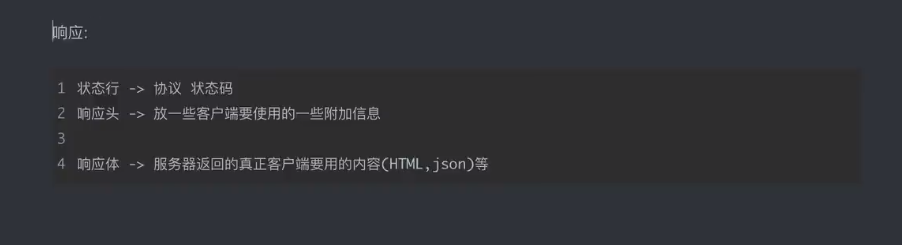

请求方式
GET:显式提交 常用查询东西
POST:隐式提交 上传一些数据
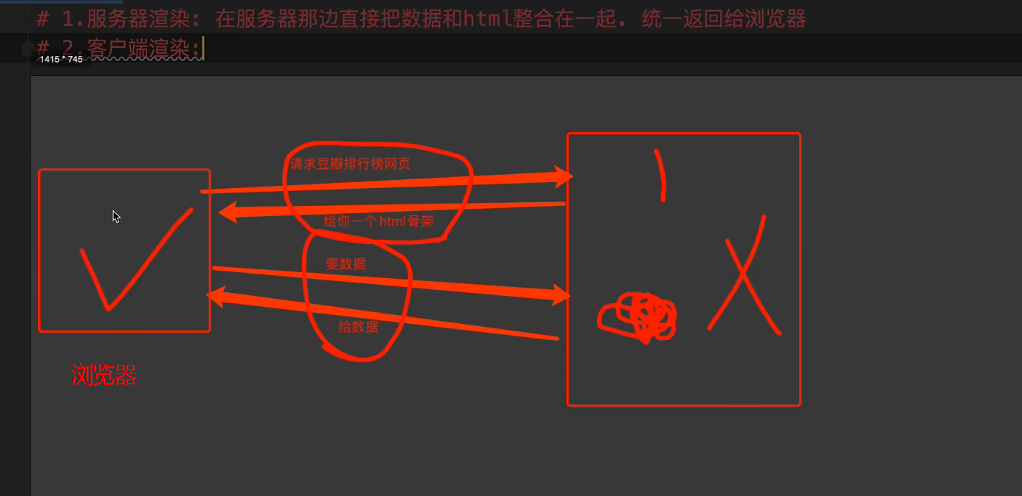
2.web 请求过程剖析
1.手刃一个爬虫
from urllib.request import urlopen
url="http://www.baidu.com"
response= urlopen(url)
# 响应包括响应头等等
# print(resp.read().decode("UTF-8"))
with open("baidu.html",mode="w") as f:
f.write(response.read().decode("UTF-8"))
print("over")


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)