
使用Python脚本通过.txt文件批量下载
我的使用情景:
因为要从官网上下载CNF文件做测试,但是官网里每一个URL对应一个CNF文件,总共400个文件,肯定不能手动下载。
步骤:
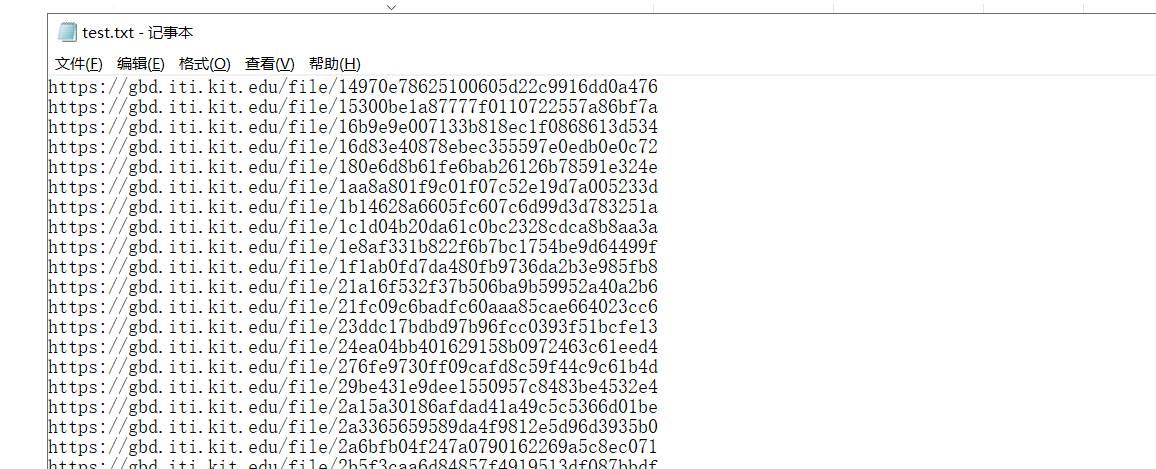
1、首先将所有URL保存到一个.txt内,如图所示。
2、python代码如下
# -- coding:UTF-8 --<code> import requests import re from io import BytesIO file = open("E:/cnf/test.txt") # 打开存放链接的TXT文档 num = 0 while 1: line = file.readline() # 逐行读链接 if not line: break print("正在下载 第 %d cnf...." % num) num += 1 image_url = line ima = image_url.replace('\n','') #去除每行的'\n',不然会404 try: requests.packages.urllib3.disable_warnings() r = requests.get(ima, verify=False) # 创建响应对象 path = re.sub("https://gbd.iti.kit.edu/file/", "E:/cnf/", line) # 通过re模块的搜索和替换功能,生成下载文档的保存地址 path = re.sub('\n', '', path + ".cnf.zip") # 删除path末尾的换行符'\n' f = open(path, "wb") f.write(r.content) # 将响应对象的内容写下来 f.close() except Exception as e: print('无法下载,%s' % e) continue file.close()
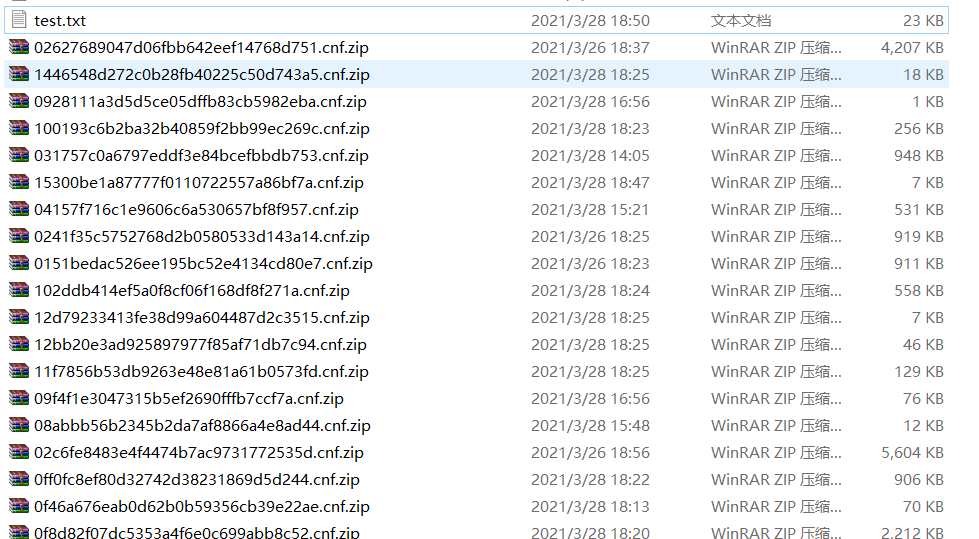
3、运行即可,会保存成如下形式
4、缺点
(1)缺少进度条和下载速度的显示
(2)如果由于种种原因下载失败了,会停止,跑了一晚上还在原地杵。
5、其他解决方法
使用Linux里的wget会更好用,其中.uri文件发挥.txt文件的作用
wget --content-disposition -i sc2020-main.uri

