
《密码与安全新技术专题》第六周作业
学号 2018-2019-2 《密码与安全新技术专题》第六周作业
课程:《密码与安全新技术专题》
上课教师:谢四江
1.本次讲座的学习总结
在Google-Play规模上大规模审查新的威胁
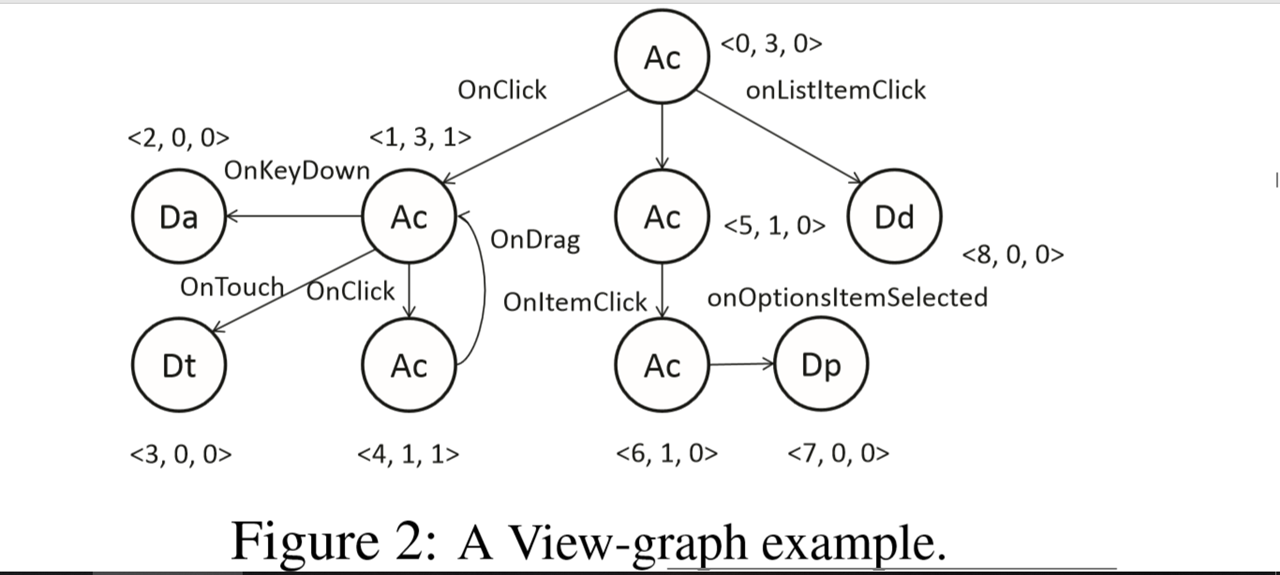
我们的想法是将应用程序的视图图形(即,其用户界面之间的互连)(例如窗口小部件和事件的类型)的一组特征投影到单个维度,使用唯一索引来表示应用程序在维度内的位置以及相似度。它的界面结构与其他人的界面结构。在我们的研究中,我们将该指数计算为视图的几何中心,称为v-core。市场上所有应用程序的v核都经过排序,以便在审核新应用程序时启用二进制搜索,从而使此步骤具有高度可扩展性。
这里的高级思想应用于应用程序克隆检测,这是一种在我们的研究中使用的技术(将Java方法的特征映射到我们研究中称为m-core的索引),用于查找常见方法不同的应用程序(第3.3节)。
重新包装。应用程序重新打包是一个过程,修改由另一方开发的应用程序,并已在市场上发布,以添加一些新的功能,然后再分配给Android用户。根据趋势科技(2014年7月15日)的数据,Google Play上排名前50位的免费应用程序中有近80%具有重新打包的版本。
但是恶意软件作者发现,利用这些流行的合法应用程序是分发irattackpayloads的最有效和最方便的途径:重新包装,以及建立有用的功能,以及使用smali / baksmali 等工具自动化过程。
研究表明绝大多数Android恶意软件都是重新打包的应用程序,约占86%。所有这些重新包装的应用程序共享的一个突出特征是恶意与否,它们倾向于保持原始用户界面的完整性,以便模仿流行的合法应用程序。
范围和假设:重打包+无混淆
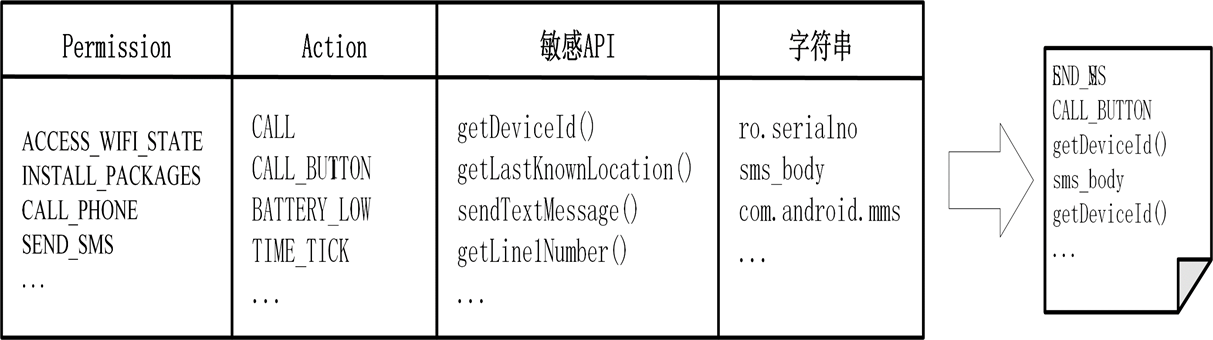
工作思路:
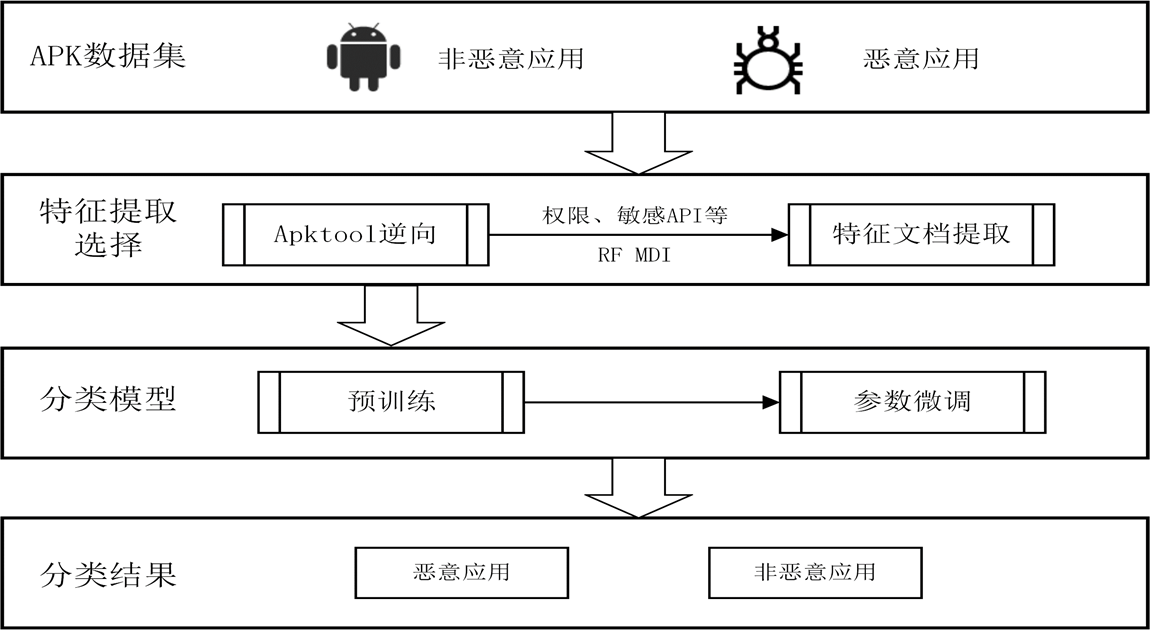
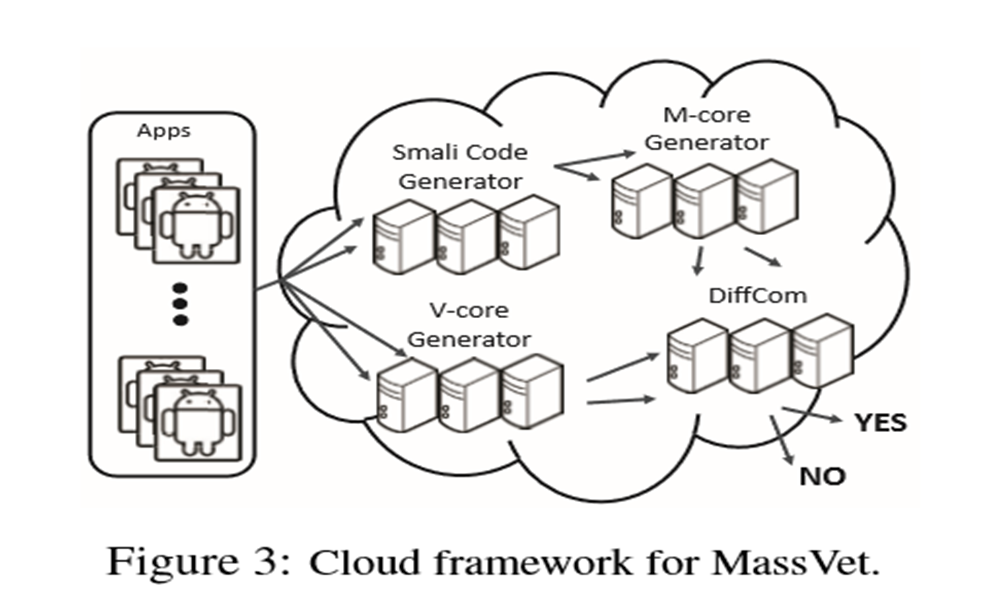
MassVet首先处理所有的应用程序,包括用于查看结构的数据库和用于数据库的数据库(第3.4节)。两个数据库都经过排序以支持二进制搜索,并用于审核提交到市场的新应用程序。考虑一个重新包装的AngryBird。一旦上载到市场,它首先在预处理阶段自动拆解成一个小型表示,从中可以识别其接口结构和方法。它们的功能(用于视图,用户界面,小部件和事件的类型,以及方法,控制流程和代码)通过计算映射到v核(第3.2节)和m核(第3.3节)分别是视图和控制流的几何中心。应用程序的v-cores首先用于通过二进制搜索查询数据库。一旦匹配满足,当存在具有类似的AngryBird用户界面结构的另一个应用程序时,将重新打包的应用程序与方法级别的市场上的应用程序进行比较以识别它们的差异。然后自动分析这些不同的方法(简称差异)以确保它们不是广告库并且确实是可疑的,如果是,则向市场报告(第3.2节)。当没有任何东西2时,MassVet继续寻找方法数据库中的AngryBird的m核心。如果找到了类似的方法,我们的方法会尝试确认包含方法的app确实与提交的AngryBird无关,并且它不是合法的代码重用(第3.3节)。在这种情况下,MassVet报告认为是令人感到满意的。所有这些步骤都是完全完全自动化,无需人工干预。
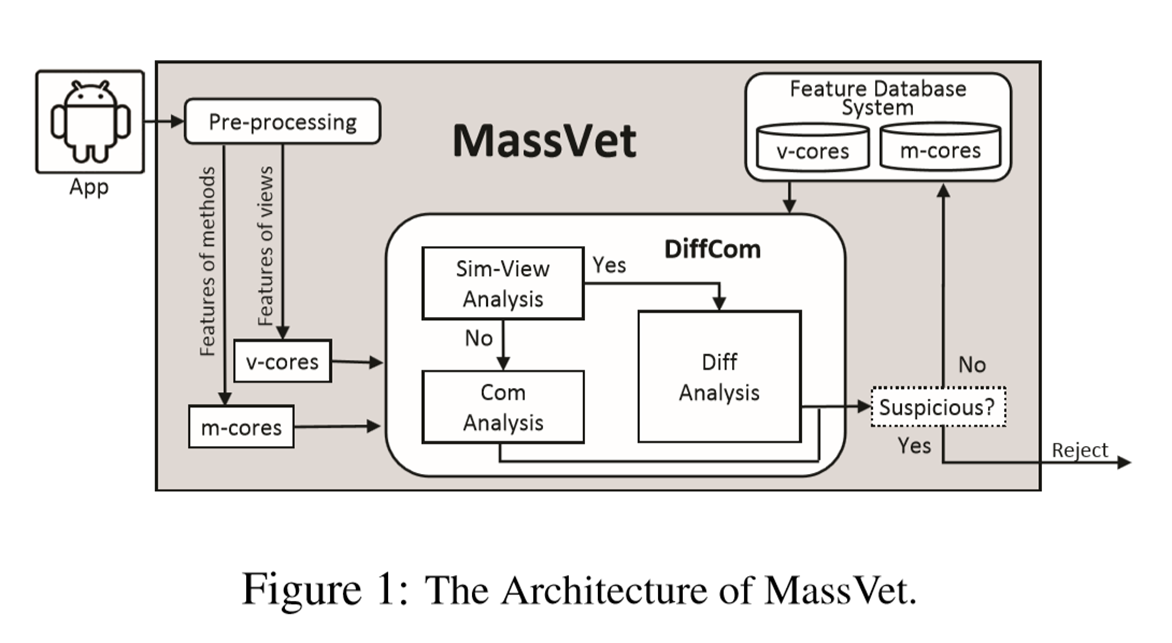
v-core
特征提取。 应用程序的用户界面包含一组视图。 每个视图包含诸如Button,ListView,TextView等的内部视觉小部件。这些UI组件响应用户的输入事件(例如,轻敲和擦除)以及由开发者指定的操作。 这种反应可能会导致当前视图或其他视图的转换。 这种互连结构,以及各个视图的布局和功能,被发现足以表征每个应用程序。
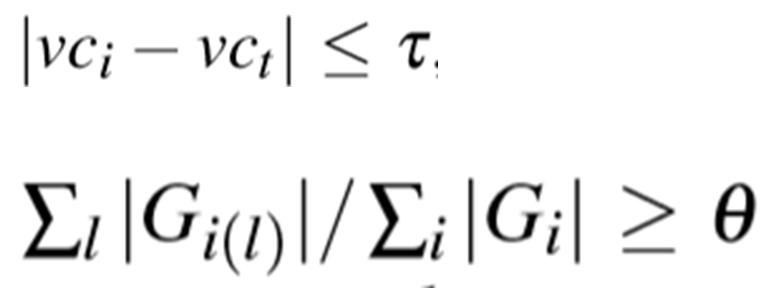
里选择的所有功能,包括UI,小部件的类型和导致UI之间转换的事件,都是不易操纵的,例如,添加垃圾小部件,修改小组类型,改变转换视图)都会敏感地影响用户体验。
DiffCom分析
对于通过批量审查流程的应用程序,视图分析首先确定它是否与市场上已有的应用程序相关。 如果是这样,将进一步比较这两个应用程序,以确定其恶意软件分析的差异。 否则,将在方法级别针对整个市场检查应用程序,以尝试找到与其他应用程序共享的程序组件。 进一步检查差异和公共组件以删除公共代码重用(库,示例代码等)并收集其安全风险的证据。 这种“差异 - 共性”分析由DiffCom模块执行。 我们还提供了有效的代码相似性分析器的实体,并讨论了DiffCom的规避。
DiffCom需要一个高效的代码相似性分析器。 在我们的研究中,我们选择了Centroids 作为这个构建块。 如前所述,该方法以类似于视图分析的方式将程序的CFG投影到其几何中心。 更具体地,该算法将基本程序块作为节点,其包括一系列连续语句,而不包括单个输入和输出。 块的重量是。 对于CFG上的每个节点,分配一个序列号,连同它所连接的分支的计数和它所涉及的循环数。这些参数用于计算程序的几何中心。
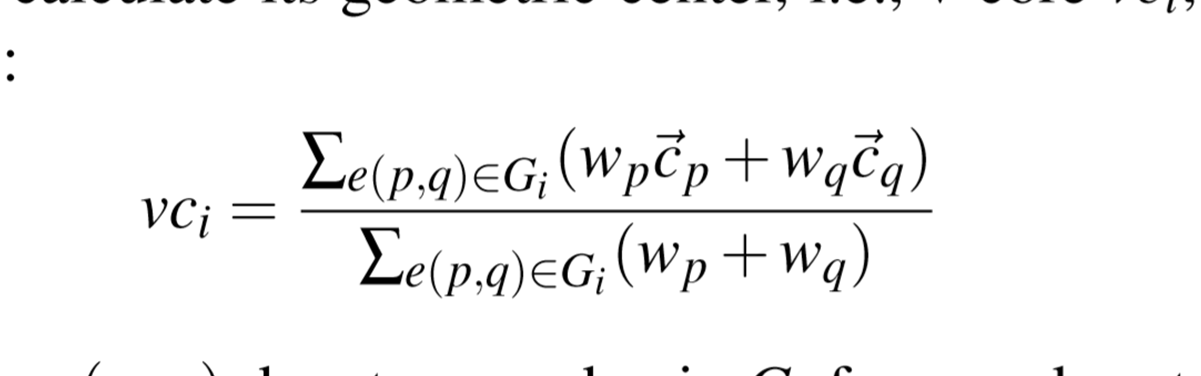
m-core建立
首先通过市场上的所有应用程序,并将其分解为方法。 删除公共库后,预处理模块分析其代码,计算各个方法(即mcores)的几何中心,然后在将结果存储到数据库之前对它们进行排序。 在审核过程中,如果发现提交的应用程序与另一个应用程序共享视图图形,则可以通过比较其个人方法的mcores来快速识别它们的差异。 在适用于执行步骤的过程中,它的方法用于在m-core数据库上进行二进制搜索,该数据库可以快速发现现有应用程序中包含的那些数据库。
每当发现应用程序与其公共视图中的另一个应用程序相关时,我们都希望检查其代码的不同部分以识别可疑活动。 理由是重新打包的应用程序是Android恶意软件的支柱,并且通常会自动注入恶意有效负载(使用smali / baksmali等工具)而不会对原始应用程序的代码进行任何重大更改,因此可以通过查看重新打包来源的应用程序来定位。 通过比较这两个应用程序的m核心,可以快速识别出这样的差异:给定m个核心L和L'的两个有序序列,通过根据元素的顺序合并这两个列表,然后删除那些,可以找到方法级别的应用程序。 与其他名单上的同行相匹配; 这可以在min(| L |,| L'|)步骤内完成。
m-core的问题:
相同的库和UI可以在不同的产品上重复使用。 一个应用程序实际上是另一个应用程序的更新版本是可能的。此外,在不同的开发人员中,开放的UISDK(如Appcelerator 和Envatomarket等模板)很受欢迎,这可能会导致不相关应用的视图结构看起来相似。 此外,即使当应用程序被包装时,差异也可能是广告库中的广告库,而不是广泛的负载。
为了解决这些问题,MassVet首先清理提交的应用程序的方法,删除广告和其他库,然后再针对市场审核应用程序。具体而言,我们维护了基于[6]的合法广告库的白名单,其中包括流行的移动广告平台,如MobWin,Admob等。为了识别不太知名的广告库,我们分析了从三个应用市场中随机抽样的50,000个应用,其中一半来自Google Play。通过这些应用程序,我们的分析发现了由不同方签署的至少27,057个应用程序共享的34,886种方法。对于这些方法中的每一种,我们都进一步了解了主机应用程序。如果发现它们中没有一个是恶意的,我们将该方法放在白名单上。以类似的方式,识别这些应用程序中的流行视图,并且与这些视图相关联的库被列入白名单,以避免在视图 - 图形分析期间检测到错误的重新分组关系。
系统建设
在我们的研究中,我们使用C和Python实现了使用MassVet的原型,从33个市场收集了近120万个应用程序,其中包括来自Google Play的400,000多个应用程序
这些应用程序的APK被反编译成smali(使用工具baksmali)来提取他们的视图和单个方法,它们分别进一步转换为v-cores和m-cores。 使用NetworkX 处理图形和找到循环。在我们的实现中,使用Sqlite数据库系统保留了这样的数据。 对于所有这些应用程序,为v核生成了1.5 GB,为m核生成了97 GB。
实施的查找方法:通过二分查找逐个检查它们。 这将需要数千万步骤进行比较和分析。 我们的实施包括一个有效的替代方案。 具体来说,在v-core数据库中,我们的系统从一端(最小元素)到另一端经历整个序列,评估等价组中的元素:具有相同v核的所有元素被分配到同一组。
但是有一个问题就是,按照他的查找方法:
每个应用程序的UI通常分为大约20个子图,这些子图分布在整个有序的v-core序列中。任何在两个应用程序之间进行比较的尝试都需要通过所有等效组。 最快的方法是在任何两个应用程序之间保持一致的状态。 然而,这种简单的方法在最坏的情况下需要一个非常小的,一百二十二万甚至一百二十万,这不能完全加载到存储器中。 在我们的实现中,通过仅检查20,000个应用程序来节省空间,每次120万个应用程序,这需要通过等效组60次并且每轮使用大约100 GB的内存。
对m内核的检查要简单得多,不需要将一个应用程序与其他应用程序进行比较。 这是因为我们所关心的只是已经出现在个别等效组中的常用方法。 然后进一步分析这些方法以检测可疑方法。
2.学习中遇到的问题及解决
- 问题1:当没有交叉点的时候怎么办
当应用程序与市场上已有的应用程序之间没有明显的连接时,审查过程需要通过交叉点分析。 当DiffCom被配置为执行分析时,也会发生这种情况,因为这些分析并未发现在不同的步骤中。 新提交的应用程序所包含的常用方法的识别相当简单:应用程序的每个方法都映射到m核心,而这些方法用于交换m核心数据库。 如前所述,这可以通过二进制搜索来完成。 一旦找到匹配项,DiffCom将进一步检查,删除应用程序之间的数据连接,并向市场报告发现情况。
同样,这里的主要挑战是确定两个应用程序是否确实无关。 一个简单的签名检查删除了大多数此类连接,但不是全部。 “独立”测试可以检查一组方法是否与应用程序的其余部分密切交互,但不能进行测试。 问题在于,两个重新打包的应用程序之间的常见方法是完全显示出错误的载荷,这使得它们与差异分析步骤中的差异区别开来:不同的恶意软件作者经常使用常见的工具来解决他们的应用程序之间的交叉问题。 这些模块仍然包含与交叉点内部未找到的恶意软件的其他组件的大量交互。 因此,这个功能在差异上运行良好,无法在应用程序之间捕获许多常见代码。
一个替代解决方案,即看似无关的应用程序实际上是连接的。 正如前面所讨论的那样,问题在于开发人员或组织是否在内部使用代码(例如,专有的SDK),而是使用不同的证书签署应用程序。 一旦确定了这种关系,我们就会更加确信共享代码的两个应用程序是否彼此独立。 在这种情况下,在删除所有公共库(例如,在先前研究[6]中使用的列表中的那些库)和代码模板之后,公共代码变得可疑。 在这里,我们描述了一种检测这种隐藏关系的简单技术。
从我们的训练数据集中,我们发现在这种情况下合法重用的大多数代码都涉及用户界面:开发人员倾向于利用现有的视图设计来快速构建新的应用程序。通过这种做法,即使两个应用程序在完整的UI结构方面可能看起来不够相似(因此它们被视图分析视为“无关”),仔细查看其视图的子图可能会发现他们实际上分享了他们观点甚至子图的重要部分。具体来说,从我们培训套装中的50,000个应用程序中删除公共图书馆后,我们发现30,286个其他应用程序的30%,其中16,500个共享50%和8,683个包含不低于80%的常见视图。通过随机抽样这些应用程序(每次10个)并手动分析它们,我们确认当部分超过50%时,几乎所有的应用程序及其对应物都来自同一个开发人员组织,或者具有重新包装起源。此外,一旦共享视图达到80%或更多,几乎总是应用程序参与重新打包。基于这一观察结果,我们对具有共同代码的一对应用程序进行了额外的相关性检查:DiffCom再次比较它们的个别子目录,如果发现一个重要部分(50%)相似,它们被认为是相关的,因此它们的交集不会被报告去市场。
3.本次讲座的学习感悟、思考等)
通过对这篇论文的学习,我的感触很深!首先这篇论文的创新点在于,自己设计了一个全新的算法,并将diff-com算法引入其中,这个算法可以快速搜索到相关页面,来分析判断,然后通过搜索相对应的数据库的进行分析。以往的安全漏洞扫描都是慢速单个的,而这个是大量快速的。其次,我跟老师同学们交流的时候,觉得这篇论文也可以换一种思路来理解,这种方法也可以应用于市场上的APP安全扫描,保护隐私。最后,我觉得在今后的学习过程中,我们要多多思考,多角度的去理解一篇顶会论文,从多个方面去寻找创新点,比如可以改进算法,或者如何预防某种攻击等!
