
引言
你是否遇到过两个(多个)系统间需要通过定时任务来同步某些数据?你是否在为异构系统的不同进程间相互调用、通讯的问题而苦恼、挣扎?如果是,那么恭喜你,消息服务让你可以很轻松地解决这些问题。
消息服务擅长于解决多系统、异构系统间的数据交换(消息通知/通讯)问题,你也可以把它用于系统间服务的相互调用(RPC)。本文将要介绍的RabbitMQ就是当前最主流的消息中间件之一。
RabbitMQ简介
RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现。AMQP 的出现其实也是应了广大人民群众的需求,虽然在同步消息通讯的世界里有很多公开标准(如 COBAR的 IIOP ,或者是 SOAP 等),但是在异步消息处理中却不是这样,只有大企业有一些商业实现(如微软的 MSMQ ,IBM 的 Websphere MQ 等),因此,在 2006 年的 6 月,Cisco 、Redhat、iMatix 等联合制定了 AMQP 的公开标准。
RabbitMQ是由RabbitMQ Technologies Ltd开发并且提供商业支持的。该公司在2010年4月被SpringSource(VMWare的一个部门)收购。在2013年5月被并入Pivotal。其实VMWare,Pivotal和EMC本质上是一家的。不同的是VMWare是独立上市子公司,而Pivotal是整合了EMC的某些资源,现在并没有上市。
RabbitMQ的官网是http://www.rabbitmq.com
- RabbitMQ Server:也叫
broker server,它不是运送食物的卡车,而是一种传输服务。原话是RabbitMQ isn’t a food truck, it’s a delivery service. 他的角色就是维护一条从Producer到Consumer的路线,保证数据能够按照指定的方式进行传输。但是这个保证也不是100%的保证,但是对于普通的应用来说这已经足够了。当然对于商业系统来说,可以再做一层数据一致性的guard,就可以彻底保证系统的一致性了。 - Client A & B:也叫
Producer,数据的发送方。Create messages and Publish (Send) them to a broker server (RabbitMQ)。一个Message有两个部分:Payload(有效载荷)和Label(标签)。Payload顾名思义就是传输的数据,Label是Exchange的名字或者说是一个tag,它描述了payload,而且RabbitMQ也是通过这个label来决定把这个Message发给哪个Consumer。AMQP仅仅描述了label,而RabbitMQ决定了如何使用这个label的规则。 - Client 1,2,3:也叫
Consumer,数据的接收方。Consumers attach to a broker server (RabbitMQ) and subscribe to a queue。把queue比作是一个有名字的邮箱。当有Message到达某个邮箱后,RabbitMQ把它发送给它的某个订阅者即Consumer。当然可能会把同一个Message发送给很多的Consumer。在这个Message中,只有payload,label已经被删掉了。对于Consumer来说,它是不知道谁发送的这个信息的。就是协议本身不支持。但是当然了如果Producer发送的payload包含了Producer的信息就另当别论了。
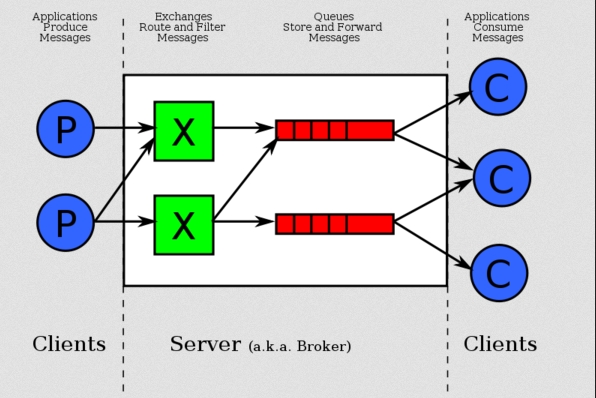
对于一个数据从Producer到Consumer的正确传递,还有三个概念需要明确:exchanges, queues and bindings。
- Exchanges are where producers publish their messages. 消息交换机,它指定消息按什么规则,路由到哪个队列
- Queues are where the messages end up and are received by consumers. 消息队列载体,每个消息都会被投入到一个或多个队列
- Bindings are how the messages get routed from the exchange to particular queues. 绑定,它的作用就是把exchange和queue按照路由规则绑定起来
- Routing Key:路由关键字,exchange根据这个关键字进行消息投递
还有几个概念是上述图中没有标明的,那就是Connection(连接),Channel(通道,频道),Vhost(虚拟主机)。
- Connection:就是一个TCP的连接。Producer和Consumer都是通过TCP连接到RabbitMQ Server的。以后我们可以看到,程序的起始处就是建立这个TCP连接。
- Channel:虚拟连接。它建立在上述的TCP连接中。数据流动都是在Channel中进行的。也就是说,一般情况是程序起始建立TCP连接,第二步就是建立这个Channel。
- Vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。每个virtual host本质上都是一个RabbitMQ Server,拥有它自己的queue,exchagne,和bings rule等等。这保证了你可以在多个不同的application中使用RabbitMQ。
Channel的选择
那么,为什么使用Channel,而不是直接使用TCP连接?
对于OS来说,建立和关闭TCP连接是有代价的,频繁的建立关闭TCP连接对于系统的性能有很大的影响,而且TCP的连接数也有限制,这也限制了系统处理高并发的能力。但是,在TCP连接中建立Channel是没有上述代价的。对于Producer或者Consumer来说,可以并发的使用多个Channel进行Publish或者Receive。
有实验表明,1s的数据可以Publish10K的数据包。当然对于不同的硬件环境,不同的数据包大小这个数据肯定不一样,但是我只想说明,对于普通的Consumer或者Producer来说,这已经足够了。如果不够用,你考虑的应该是如何细化split你的设计。
消息队列执行过程
- 客户端连接到消息队列服务器,打开一个Channel。
- 客户端声明一个Exchange,并设置相关属性。
- 客户端声明一个Queue,并设置相关属性。
- 客户端使用Routing key,在Exchange和Queue之间建立好绑定关系。
- 客户端投递消息到Exchange。
Exchange接收到消息后,就根据消息的key和已经设置的Binding,进行消息路由,将消息投递到一个或多个队列里。有三种类型的Exchanges:direct,fanout,topic,每个实现了不同的路由算法(routing algorithm):
- Direct exchange:完全根据key进行投递的叫做Direct交换机。如果Routing key匹配, 那么Message就会被传递到相应的queue中。其实在queue创建时,它会自动的以queue的名字作为routing key来绑定那个exchange。例如,绑定时设置了Routing key为”abc”,那么客户端提交的消息,只有设置了key为”abc”的才会投递到队列。
- Fanout exchange:不需要key的叫做Fanout交换机。它采取广播模式,一个消息进来时,投递到与该交换机绑定的所有队列。
- Topic exchange:对key进行模式匹配后进行投递的叫做Topic交换机。比如符号”#”匹配一个或多个词,符号””匹配正好一个词。例如”abc.#”匹配”abc.def.ghi”,”abc.”只匹配”abc.def”。
RabbitMQ是AMQP协议的实现。它主要包括以下组件:
1.Server(broker): 接受客户端连接,实现AMQP消息队列和路由功能的进程。
2.Virtual Host:其实是一个虚拟概念,类似于权限控制组,一个Virtual Host里面可以有若干个Exchange和Queue,但是权限控制的最小粒度是Virtual Host
3.Exchange:接受生产者发送的消息,并根据Binding规则将消息路由给服务器中的队列。ExchangeType决定了Exchange路由消息的行为,例如,在RabbitMQ中,ExchangeType有direct、Fanout和Topic三种,不同类型的Exchange路由的行为是不一样的。
4.Message Queue:消息队列,用于存储还未被消费者消费的消息。
5.Message: 由Header和Body组成,Header是由生产者添加的各种属性的集合,包括Message是否被持久化、由哪个Message Queue接受、优先级是多少等。而Body是真正需要传输的APP数据。
6.Binding:Binding联系了Exchange与Message Queue。Exchange在与多个Message Queue发生Binding后会生成一张路由表,路由表中存储着Message Queue所需消息的限制条件即Binding Key。当Exchange收到Message时会解析其Header得到Routing Key,Exchange根据Routing Key与Exchange Type将Message路由到Message Queue。Binding Key由Consumer在Binding Exchange与Message Queue时指定,而Routing Key由Producer发送Message时指定,两者的匹配方式由Exchange Type决定。
7.Connection:连接,对于RabbitMQ而言,其实就是一个位于客户端和Broker之间的TCP连接。
8.Channel:信道,仅仅创建了客户端到Broker之间的连接后,客户端还是不能发送消息的。需要为每一个Connection创建Channel,AMQP协议规定只有通过Channel才能执行AMQP的命令。一个Connection可以包含多个Channel。之所以需要Channel,是因为TCP连接的建立和释放都是十分昂贵的,如果一个客户端每一个线程都需要与Broker交互,如果每一个线程都建立一个TCP连接,暂且不考虑TCP连接是否浪费,就算操作系统也无法承受每秒建立如此多的TCP连接。RabbitMQ建议客户端线程之间不要共用Channel,至少要保证共用Channel的线程发送消息必须是串行的,但是建议尽量共用Connection。
9.Command:AMQP的命令,客户端通过Command完成与AMQP服务器的交互来实现自身的逻辑。例如在RabbitMQ中,客户端可以通过publish命令发送消息,txSelect开启一个事务,txCommit提交一个事务。
应用场景
1、系统集成,分布式系统的设计。各种子系统通过消息来对接,这种解决方案也逐步发展成一种架构风格,即“通过消息传递的架构”。
2、当系统中的同步处理方式严重影响了吞吐量,比如日志记录。假如需要记录系统中所有的用户行为日志,如果通过同步的方式记录日志势必会影响系统的响应速度,当我们将日志消息发送到消息队列,记录日志的子系统就会通过异步的方式去消费日志消息。
3、系统的高可用性,比如电商的秒杀场景。当某一时刻应用服务器或数据库服务器收到大量请求,将会出现系统宕机。如果能够将请求转发到消息队列,再由服务器去消费这些消息将会使得请求变得平稳,提高系统的可用性。
学习RabbitMQ的使用场景,来自官方教程:https://www.rabbitmq.com/getstarted.html
AMQP当中有四个概念非常重要:虚拟主机(virtual host),交换机(exchange),队列(queue)和绑定(binding)。一个虚拟主机持有一组交换机、队列和绑定。为什么需要多个虚拟主机呢?很简单,RabbitMQ当中,用户只能在虚拟主机的粒度进行权限控制。因此,如果需要禁止A组访问B组的交换机/队列/绑定,必须为A和B分别创建一个虚拟主机。每一个RabbitMQ服务器都有一个默认的虚拟主机“/”。如果这就够了,那现在就可以开始了。
AMQP协议是一种二进制协议,提供客户端应用与消息中间件之间异步、安全、高效地交互。从整体来看,AMQP协议可划分为三层。
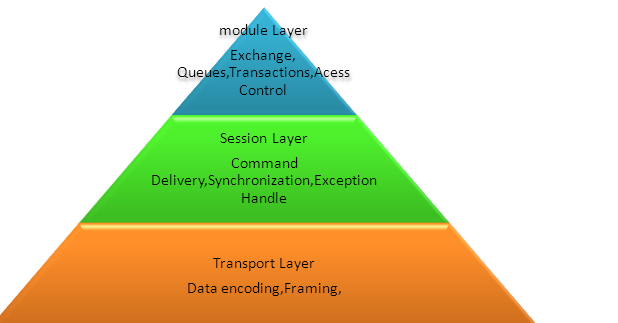
这种分层架构类似于OSI网络协议,可替换各层实现而不影响与其它层的交互。AMQP定义了合适的服务器端域模型,用于规范服务器的行为(AMQP服务器端可称为broker)。
Model层决定这些基本域模型所产生的行为,这种行为在AMQP中用”command”表示,在后文中会着重来分析这些域模型。
Session层定义客户端与broker之间的通信(通信双方都是一个peer,可互称做partner),为command的可靠传输提供保障。
Transport层专注于数据传送,并与Session保持交互,接受上层的数据,组装成二进制流,传送到receiver后再解析数据,交付给Session层。Session层需要Transport层完成网络异常情况的汇报,顺序传送command等工作。
AMQP当中有四个概念非常重要:虚拟主机(virtual host),交换机(exchange),队列(queue)和绑定(binding)。
虚拟主机(virtual host):一个虚拟主机持有一组交换机、队列和绑定。为什么需要多个虚拟主机呢?RabbitMQ当中,用户只能在虚拟主机的粒度进行权限控制。因此,如果需要禁止A组访问B组的交换机/队列/绑定,必须为A和B分别创建一个虚拟主机。每一个RabbitMQ服务器都有一个默认的虚拟主机“/”。
队列(Queue):由消费者建立的,是messages的终点,可以理解成装消息的容器。消息一直存在队列里,直到有客户端或者称为Consumer消费者连接到这个队列并将message取走为止。队列可以有多个。
交换机(Exchange):可以理解成具有路由表的路由程序。每个消息都有一个路由键(routing key),就是一个简单的字符串。交换机中有一系列的绑定(binding),即路由规则(routes)。交换机可以有多个。多个队列可以和同一个交换机绑定,同时多个交换机也可以和同一个队列绑定。(多对多的关系)
三种交换机:
1. Fanout Exchange(不处理路由键):一个发送到交换机上的消息都会被转发到与该交换机绑定的所有队列上。Fanout交换机发消息是最快的。
2. Direct Exchange(处理路由键):如果一个队列绑定到该交换机上,并且当前要求路由键为X,只有路由键是X的消息才会被这个队列转发。
3. Topic Exchange(将路由键和某模式进行匹配,可以理解成模糊处理):路由键的词由“.”隔开,符号“#”表示匹配0个或多个词,符号“*”表示匹配不多不少一个词。因此“audit.#”能够匹配到“audit.irs.corporate”,但是“audit.*”只会匹配到“audit.irs”
持久化:队列和交换机有一个创建时候指定的标志durable,直译叫做坚固的。durable的唯一含义就是具有这个标志的队列和交换机会在重启之后重新建立,它不表示说在队列当中的消息会在重启后恢复。那么如何才能做到不只是队列和交换机,还有消息都是持久的呢?
但是首先一个问题是,你真的需要消息是持久的吗?对于一个需要在重启之后回复的消息来说,它需要被写入到磁盘上,而即使是最简单的磁盘操作也是要消耗时间的。如果和消息的内容相比,你更看重的是消息处理的速度,那么不要使用持久化的消息。
当你将消息发布到交换机的时候,可以指定一个标志“Delivery Mode”(投递模式)。根据你使用的AMQP的库不同,指定这个标志的方法可能不太一样。简单的说,就是将 Delivery Mode设置成2,也就是持久的即可。一般的AMQP库都是将Delivery Mode设置成1,也就是非持久的。所以要持久化消息的步骤如下:
1. 将交换机设成 durable。
2. 将队列设成 durable。
3. 将消息的 Delivery Mode 设置成2。
绑定(Bindings)如何持久化?我们无法在创建绑定的时候设置成durable。没问题,如果绑定了一个 durable的队列和一个durable的交换机,RabbitMQ会自动保留这个绑定。类似的,如果删除了某个队列或交换机(无论是不是 durable),依赖它的绑定都会自动删除。
注意两点:
1. RabbitMQ不允许绑定一个非坚固(non-durable)的交换机和一个durable的队列。反之亦然。要想成功必须队列和交换机都是durable的。
2. 一旦创建了队列和交换机,就不能修改其标志了。例如,如果创建了一个non-durable的队列,然后想把它改变成durable的,唯一的办法就是删除这个队列然后重现创建。因此,最好仔细检查创建的标志。
消息队列(MQ)使用过程
几个概念说明:
1. Broker:简单来说就是消息队列服务器实体。
2. Exchange:消息交换机,它指定消息按什么规则,路由到哪个队列。
3. Queue:消息队列载体,每个消息都会被投入到一个或多个队列。
4. Binding:绑定,它的作用就是把exchange和queue按照路由规则绑定起来。
5. Routing Key:路由关键字,exchange根据这个关键字进行消息投递。
6. vhost:虚拟主机,一个broker里可以开设多个vhost,用作不同用户的权限分离。
7. producer:消息生产者,就是投递消息的程序。
8. consumer:消息消费者,就是接受消息的程序。
9. channel:消息通道,在客户端的每个连接里,可建立多个channel,每个channel代表一个会话任务。
消息队列的使用过程大概如下:
1. 客户端连接到消息队列服务器,打开一个channel。
2. 客户端声明一个exchange,并设置相关属性。
3. 客户端声明一个queue,并设置相关属性。
4. 客户端使用routing key,在exchange和queue之间建立好绑定关系。
5. 客户端投递消息到exchange。
6. exchange接收到消息后,就根据消息的key和已经设置的binding,进行消息路由,将消息投递到一个或多个队列里。
rabbitMQ的优点(适用范围)
1. 基于erlang语言开发具有高可用高并发的优点,适合集群服务器。
2. 健壮、稳定、易用、跨平台、支持多种语言、文档齐全。
3. 有消息确认机制和持久化机制,可靠性高。
4. 开源
其他MQ的优势:
1. Apache ActiveMQ曝光率最高,但是可能会丢消息。
2. ZeroMQ延迟很低、支持灵活拓扑,但是不支持消息持久化和崩溃恢复。
消息中间件主要用于组件之间的解耦,消息的发送者无需知道消息使用者的存在,反之亦然:

单向解耦

双向解耦(如:RPC)
例如一个日志系统,很容易使用RabbitMQ简化工作量,一个Consumer可以进行消息的正常处理,另一个Consumer负责对消息进行日志记录,只要在程序中指定两个Consumer所监听的queue以相同的方式绑定到同一个exchange即可,剩下的消息分发工作由RabbitMQ完成。

使用RabbitMQ server需要:
1. ErLang语言包;
2. RabbitMQ安装包;
RabbitMQ同时提供了java的客户端(一个jar包)。
安装RabbitMQ
要想安装RabbitMQ,首先需要安装和配置好它的宿主环境erlang。去erlang官网下载好erlang otp_src源码包,然后在本地执行源码安装。(erlang官网:http://www.erlang.org/)
RabbitMQ安装(linux--服务端)
基础环境: 内核 3.10.0-327.el7.x86_64 系统版本 CentOS Linux release 7.2.1511 (Core) 安装配置epel源 # rpm -ivh http://mirrors.neusoft.edu.cn/epel/7/x86_64/e/epel-release-7-7.noarch.rpm 安装erlang # yum install erlang 下载RabbitMQ 3.6.1 # wget http://www.rabbitmq.com/releases/rabbitmq-server/v3.6.1/rabbitmq-server-3.6.1-1.noarch.rpm 安装rabbitmq-server # rpm -ivh rabbitmq-server-3.6.1-1.noarch.rpm 生成配置文件 # cp /usr/share/doc/rabbitmq-server-3.6.1/rabbitmq.config.example /etc/rabbitmq/rabbitmq.config 启动RabbitMQ # rabbitmq-server start 安装Python API # pip3 install pika
安装API(客户端)
pip install pika or easy_install pika or 源码 https://pypi.python.org/pypi/pika
用户管理
1. 添加用户:rabbitmqctl add_user username password
2. 删除用户:rabbitmqctl delete_user username
3. 修改密码:rabbitmqctl change_password username newpassword
4. 清除密码:rabbitmqctl clear_password {username}
5. 设置用户标签:rabbitmqctl set_user_tags {username} {tag…}如果tag为空则表示清除这个用户的所有标签
6. 列出所有用户 :rabbitmqctl list_users
权限控制
1. 创建虚拟主机:rabbitmqctl add_vhost vhostpath
2. 删除虚拟主机:rabbitmqctl delete_vhost vhostpath
3. 列出所有虚拟主机:rabbitmqctl list_vhosts
4. 设置用户权限:rabbitmqctl set_permissions [-p vhostpath] {username} {conf} {write} {read}
5. 清除用户权限:rabbitmqctl clear_permissions [-p vhostpath] {username}
6. 列出虚拟主机上的所有权限:rabbitmqctl list_permissions [-p vhostpath]
7. 列出用户权限:rabbitmqctl list_user_permissions {username}
RabbitMQ基本示例
实现最简单的队列通信
produce
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters("192.168.244.130",15672))
channel = connection.channel()
#声明queue
channel.queue_declare(queue='hello')
channel.basic_publish(exchange="",
routing_key='hello',
body = 'Hello World!')
print("[x] Sent 'Hello World!")
connection.close()
consume
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters("192.168.16.23"))
channel = connection.channel()
channel.queue_declare(queue="holle",durable=True)
def callback(ch,method,properties,body):
print(ch,method,properties)
print("[x] Received %r" %body)
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,
queue="holle",
no_ack=True)
print('[*] waiting for messages. to exit press ctrl+c')
channel.start_consuming()
- 生产者代码
#!/usr/bin/env python 3
import pika
######### 生产者 #########
#链接rabbit服务器(localhost是本机,如果是其他服务器请修改为ip地址)
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
#创建频道
channel = connection.channel()
#创建一个队列名叫test
channel.queue_declare(queue='test')
# channel.basic_publish向队列中发送信息
# exchange -- 它使我们能够确切地指定消息应该到哪个队列去。
# routing_key 指定向哪个队列中发送消息
# body是要插入的内容, 字符串格式
while True: # 循环向队列中发送信息,quit退出程序
inp = input(">>>").strip()
if inp == 'quit':
break
channel.basic_publish(exchange='',
routing_key='test',
body=inp)
print("生产者向队列发送信息%s" % inp)
#缓冲区已经flush而且消息已经确认发送到了RabbitMQ中,关闭链接
connection.close()
# 输出结果
>>>python
生产者向队列发送信息python
>>>quit
消费者代码
#!/usr/bin/env python 3
import pika
######### 消费者 #########
# 链接rabbit
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
# 创建频道
channel = connection.channel()
# 如果生产者没有运行创建队列,那么消费者也许就找不到队列了。为了避免这个问题,所有消费者也创建这个队列,如果队列已经存在,则这条无效
channel.queue_declare(queue='test')
#接收消息需要使用callback这个函数来接收,他会被pika库来调用,接受到的数据都是字节类型的
def callback(ch, method, properties, body):
"""
ch : 代表 channel
method :队列名
properties : 连接rabbitmq时设置的属性
body : 从队列中取到的内容,获取到的数据时字节类型
"""
print(" [x] Received %r" % body)
# channel.basic_consume 表示从队列中取数据,如果拿到数据 那么将执行callback函数,callback是回调函数
# no_ack=True 表示消费完这个消息以后不主动把完成状态通知rabbitmq
channel.basic_consume(callback,
queue='test',
no_ack=True)
print(' [*] 等待信息. To exit press CTRL+C')
#永远循环等待数据处理和callback处理的数据,start_consuming方法会阻塞循环执行
channel.start_consuming()
# 输出结果,一直等待处理队列中的消息,不知终止,除非人为ctrl+c
[*]等待消息,To exit press CTRL+C
[x] Received b'python'
消息持久化
acknowledgment 消息不丢失的方法
生效方法:channel.basic_consume(consumer_callback, queue, no_ack=False, exclusive=False, consumer_tag=None, arguments=None)
即no_ack=False(默认为False,即必须有确认标识),在回调函数consumer_callback中,未收到确认标识,那么,RabbitMQ会重新将该任务添加到队列中。
生产者代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# auth : pangguoping
import pika
# ######################### 生产者 #########################
credentials = pika.PlainCredentials('admin', 'admin')
#链接rabbit服务器(localhost是本机,如果是其他服务器请修改为ip地址)
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.103',5672,'/',credentials))
#创建频道
channel = connection.channel()
# 声明消息队列,消息将在这个队列中进行传递。如果将消息发送到不存在的队列,rabbitmq将会自动清除这些消息。如果队列不存在,则创建
channel.queue_declare(queue='hello')
#exchange -- 它使我们能够确切地指定消息应该到哪个队列去。
#向队列插入数值 routing_key是队列名 body是要插入的内容
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print("开始队列")
#缓冲区已经flush而且消息已经确认发送到了RabbitMQ中,关闭链接
connection.close()
消费者代码:
import pika
credentials = pika.PlainCredentials('admin', 'admin')
# 链接rabbit
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.103',5672,'/',credentials))
# 创建频道
channel = connection.channel()
# 如果生产者没有运行创建队列,那么消费者创建队列
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
import time
time.sleep(10)
print
'ok'
ch.basic_ack(delivery_tag=method.delivery_tag) # 主要使用此代码
channel.basic_consume(callback,
queue='hello',
no_ack=False)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
消息持久化存储(Message durability)
虽然有了消息反馈机制,但是如果rabbitmq自身挂掉的话,那么任务还是会丢失。所以需要将任务持久化存储起来。声明持久化存储
channel.queue_declare(queue='wzg', durable=True) # 声明队列持久化
Ps: 但是这样程序会执行错误,因为‘wzg’这个队列已经存在,并且是非持久化的,rabbitmq不允许使用不同的参数来重新定义存在的队列。因此需要重新定义一个队列
channel.queue_declare(queue='test_queue', durable=True) # 声明队列持久化
注意:如果仅仅是设置了队列的持久化,仅队列本身可以在rabbit-server宕机后保留,队列中的信息依然会丢失,如果想让队列中的信息或者任务保留,还需要做以下设置:
channel.basic_publish(exchange='',
routing_key="test_queue",
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # 使消息或任务也持久化存储
))
消息队列持久化包括3个部分:
(1)exchange持久化,在声明时指定durable => 1
(2)queue持久化,在声明时指定durable => 1
(3)消息持久化,在投递时指定delivery_mode=> 2(1是非持久化)
如果exchange和queue都是持久化的,那么它们之间的binding也是持久化的。如果exchange和queue两者之间有一个持久化,一个非持久化,就不允许建立绑定。
消息公平分发
如果Rabbit只管按顺序把消息发到各个消费者身上,不考虑消费者负载的话,很可能出现,一个机器配置不高的消费者那里堆积了很多消息处理不完,同时配置高的消费者却一直很轻松。为解决此问题,可以在各个消费者端,配置perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了。

channel.basic_qos(prefetch_count=1)
带消息持久化+公平分发的完整代码
生产者端
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
message = ' '.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
print(" [x] Sent %r" % message)
connection.close()
消费者端
#!/usr/bin/env python
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(body.count(b'.'))
print(" [x] Done")
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,
queue='task_queue')
channel.start_consuming()
Publish\Subscribe(消息发布\订阅)
RabbitMQ的发布与订阅,借助于交换机(Exchange)来实现。
交换机的工作原理:消息发送端先将消息发送给交换机,交换机再将消息发送到绑定的消息队列,而后每个接收端(consumer)都能从各自的消息队列里接收到信息。
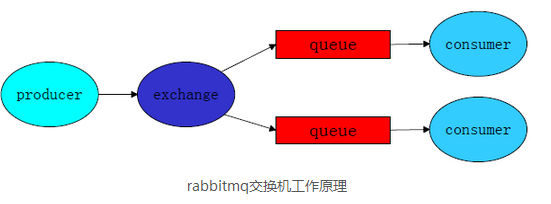
Exchange有三种工作模式,分别为:Fanout, Direct, Topic
- fanout : 所有bind到此exchange的queue都可以接受消息
- direct : 通过routingkey和exchange决定的那个唯一的queue可以接受消息
- topic : 所有符合routingkey(一个表达式)的routingkey所bind的queue
当我们向队列里发送消息时,其实并不是自己直接放入队列中的,而是先交给exchange,然后由exchange放入指定的队列中。想象下当我们要将一条消息发送到多个队列中的时候,如果没有exchange,我们需要发送多条到不同的队列中,但是如果有了exchange,它会先和目标队列建立一种绑定关系,当我们把一条消息发送到exchange中的时候,exchange会根据之前和队列的绑定关系,将这条消息发送到所有与它有绑定关系的队里中。
发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失了。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,二发布者发布消息时,会将消息放置在所有相关队列中。发布订阅本质上就是发布端将消息发送给了exchange,exchange将消息发送给与它绑定关系的所有队列。
exchange type = fanout 和exchange绑定关系的所有队列都会收到信息
模式1 Fanout
任何发送到Fanout Exchange的消息都会被转发到与该Exchange绑定(Binding)的所有Queue上
1.可以理解为路由表的模式
2.这种模式不需要routing_key(即使指定,也是无效的)
3.这种模式需要提前将Exchange与Queue进行绑定,一个Exchange可以绑定多个Queue,一个Queue可以同多个Exchange进行绑定。
4.如果接受到消息的Exchange没有与任何Queue绑定,则消息会被抛弃。
注意:这个时候必须先启动消费者,即订阅者。因为随机队列是在consumer启动的时候随机生成的,并且进行绑定的。producer仅仅是发送至exchange,并不直接与随机队列进行通信。
生产者代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# auth : pangguoping
# rabbitmq 发布者
import pika
credentials = pika.PlainCredentials('admin', 'admin')
#链接rabbit服务器(localhost是本机,如果是其他服务器请修改为ip地址)
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.103',5672,'/',credentials))
channel = connection.channel()
# 定义交换机,exchange表示交换机名称,type表示类型
channel.exchange_declare(exchange='logs_fanout',
type='fanout')
message = 'Hello Python'
# 将消息发送到交换机
channel.basic_publish(exchange='logs_fanout', # 指定exchange
routing_key='', # fanout下不需要配置,配置了也不会生效
body=message)
print(" [x] Sent %r" % message)
connection.close()
消费者代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# auth : pangguoping
# rabbitmq 订阅者
import pika
credentials = pika.PlainCredentials('admin', 'admin')
#链接rabbit服务器(localhost是本机,如果是其他服务器请修改为ip地址)
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.103',5672,'/',credentials))
channel = connection.channel()
# 定义交换机,进行exchange声明,exchange表示交换机名称,type表示类型
channel.exchange_declare(exchange='logs_fanout',
type='fanout')
# 随机创建队列
result = channel.queue_declare(exclusive=True) # exclusive=True表示建立临时队列,当consumer关闭后,该队列就会被删除
queue_name = result.method.queue
# 将队列与exchange进行绑定
channel.queue_bind(exchange='logs_fanout',
queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
# 从队列获取信息
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
模式2 Direct
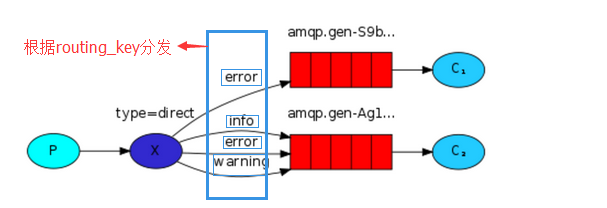
路由键的工作原理:每个接收端的消息队列在绑定交换机的时候,可以设定相应的路由键。发送端通过交换机发送信息时,可以指明路由键 ,交换机会根据路由键把消息发送到相应的消息队列,这样接收端就能接收到消息了。
任何发送到Direct Exchange的消息都会被转发到routing_key中指定的Queue:
1.一般情况可以使用rabbitMQ自带的Exchange:”” (该Exchange的名字为空字符串), 也可以自定义Exchange
2.这种模式下不需要将Exchange进行任何绑定(bind)操作。当然也可以进行绑定。可以将不同的routing_key与不同的queue进行绑定,不同的queue与不同exchange进行绑定
3.消息传递时需要一个“routing_key”
4.如果消息中中不存在routing_key中绑定的队列名,则该消息会被抛弃。
如果一个exchange 声明为direct,并且bind中指定了routing_key,那么发送消息时需要同时指明该exchange和routing_key.
消费者代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# auth : pangguoping
# 消费者
import pika
credentials = pika.PlainCredentials('admin', 'admin')
#链接rabbit服务器(localhost是本机,如果是其他服务器请修改为ip地址)
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.103',5672,'/',credentials))
channel = connection.channel()
# 定义exchange和类型
channel.exchange_declare(exchange='direct_test',
type='direct')
# 生成随机队列
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
severities = ['error', ]
# 将随机队列与routing_key关键字以及exchange进行绑定
for severity in severities:
channel.queue_bind(exchange='direct_test',
queue=queue_name,
routing_key=severity)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
# 接收消息
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
生产者
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# auth : pangguoping
# 发布者
import pika
credentials = pika.PlainCredentials('admin', 'admin')
#链接rabbit服务器(localhost是本机,如果是其他服务器请修改为ip地址)
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.1.103',5672,'/',credentials))
channel = connection.channel()
# 定义交换机名称及类型
channel.exchange_declare(exchange='direct_test',
type='direct')
severity = 'info'
message = '123'
# 发布消息至交换机direct_test,且发布的消息携带的关键字routing_key是info
channel.basic_publish(exchange='direct_test',
routing_key=severity,
body=message)
print(" [x] Sent %r:%r" % (severity, message))
connection.close()
当接收端正在运行时,可以使用rabbitmqctl list_bindings来查看绑定情况。
模式3 Topic
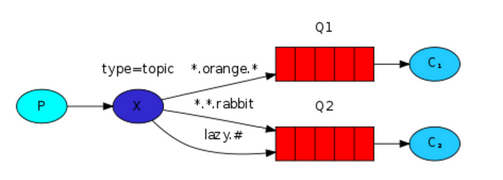
路由键模糊匹配,其实是路由键(routing_key)的扩展,就是可以使用正则表达式,和常用的正则表示式不同,这里的话“#”表示所有、全部的意思;“*”只匹配到一个词。
任何发送到Topic Exchange的消息都会被转发到所有关心routing_key中指定话题的Queue上
1.这种模式较为复杂,简单来说,就是每个队列都有其关心的主题,所有的消息都带有一个“标题”(routing_key),Exchange会将消息转发到所有关注主题能与 routing_key模糊匹配的队列。
2.这种模式需要routing_key,也许要提前绑定Exchange与Queue。
3.在进行绑定时,要提供一个该队列关心的主题,如“#.log.#”表示该队列关心所有涉及log的消息(一个routing_key为”MQ.log.error”的消息会被转发到该队列)。
4.“#”表示0个或若干个关键字,“*”表示一个关键字。如“log.*”能与“log.warn”匹配,无法与“log.warn.timeout”匹配;但是“log.#”能与上述两者匹配。
5.同样,如果Exchange没有发现能够与routing_key匹配的Queue,则会抛弃此消息。
具体代码这里不在多余写,参照第二种模式的就可以,唯一变动的地方就是exchange type的声明,以及进行绑定和发送的时候routing_key使用正则模式即可。
消费者代码
#!/usr/bin/env python3
#coding:utf8
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',type='topic')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
binding_keys = sys.argv[1:]
if not binding_keys:
sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0])
sys.exit(1)
for binding_key in binding_keys:
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key=binding_key)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
生产者代码
#!/usr/bin/env python3
#coding:utf8
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs', type='topic')
routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='topic_logs',
routing_key=routing_key,
body=message)
print(" [x] Sent %r:%r" % (routing_key, message))
connection.close()
有选择的接收消息(exchange type=direct)
RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
publisher
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
type='direct')
severity = sys.argv[1] if len(sys.argv) > 1 else 'info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='direct_logs',
routing_key=severity,
body=message)
print(" [x] Sent %r:%r" % (severity, message))
connection.close()
subscriber
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
type='direct')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
severities = sys.argv[1:]
if not severities:
sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])
sys.exit(1)
for severity in severities:
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
更细致的消息过滤
Although using the direct exchange improved our system, it still has limitations - it can't do routing based on multiple criteria.
In our logging system we might want to subscribe to not only logs based on severity, but also based on the source which emitted the log. You might know this concept from the syslog unix tool, which routes logs based on both severity (info/warn/crit...) and facility (auth/cron/kern...).
That would give us a lot of flexibility - we may want to listen to just critical errors coming from 'cron' but also all logs from 'kern'.
publisher
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
type='topic')
routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='topic_logs',
routing_key=routing_key,
body=message)
print(" [x] Sent %r:%r" % (routing_key, message))
connection.close()
subscriber
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='topic_logs',
type='topic')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
binding_keys = sys.argv[1:]
if not binding_keys:
sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0])
sys.exit(1)
for binding_key in binding_keys:
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key=binding_key)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
To receive all the logs run:
python receive_logs_topic.py "#"
To receive all logs from the facility "kern":
python receive_logs_topic.py "kern.*"
Or if you want to hear only about "critical" logs:
python receive_logs_topic.py "*.critical"
You can create multiple bindings:
python receive_logs_topic.py "kern.*" "*.critical"
And to emit a log with a routing key "kern.critical" type:
python emit_log_topic.py "kern.critical" "A critical kernel error"
Remote procedure call (RPC)
To illustrate how an RPC service could be used we're going to create a simple client class. It's going to expose a method named call which sends an RPC request and blocks until the answer is received:
|
1
2
3
|
fibonacci_rpc = FibonacciRpcClient()result = fibonacci_rpc.call(4)print("fib(4) is %r" % result) |
RPC server
#_*_coding:utf-8_*_
__author__ = 'Alex Li'
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='rpc_queue')
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2)
def on_request(ch, method, props, body):
n = int(body)
print(" [.] fib(%s)" % n)
response = fib(n)
ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id = \
props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(on_request, queue='rpc_queue')
print(" [x] Awaiting RPC requests")
channel.start_consuming()
RPC client
import pika
import uuid
class FibonacciRpcClient(object):
def __init__(self):
self.connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
self.channel = self.connection.channel()
result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue
self.channel.basic_consume(self.on_response, no_ack=True,
queue=self.callback_queue)
def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body
def call(self, n):
self.response = None
self.corr_id = str(uuid.uuid4())
self.channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to = self.callback_queue,
correlation_id = self.corr_id,
),
body=str(n))
while self.response is None:
self.connection.process_data_events()
return int(self.response)
fibonacci_rpc = FibonacciRpcClient()
print(" [x] Requesting fib(30)")
response = fibonacci_rpc.call(30)
print(" [.] Got %r" % response)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号