

SuperMap iObjects for Spark使用
本文档环境基于ubuntu16.04版本,(转发请注明出处:http://www.cnblogs.com/zhangyongli2011/ 如发现有错,请留言,谢谢)
1. 基础环境搭建
基础环境搭建请参考上一篇文档:Hadoop集群+Spark集群搭建(一篇文章就够了).
2. 软件准备
-
SuperMap iObjects Java 9.x
(supermap-iobjectsjava-9.1.1-16827-70590-linux64-all-Bin.tar.gz) -
SuperMap iObjects for Spark 9.x
(supermap-spark-911-20181228.zip)
3. iObjects for Spark部署
3.1 iObjects for Spark 安装
1.下载supermap-iobjectsjava-9.1.1-16827-70590-linux64-all-Bin.tar.gz和相应的supermap-spark-911-20181228.zip组件
2.放到opt下解压,并修改名字
tar -zxvf supermap-iobjectsjava-9.1.1-16827-70590-linux64-all-Bin.tar.gz
mv Bin iobjects_new
3.新建iobjects_spark目录
mkdir /opt/iobjects_spark
4.supermap-spark-911-20181228.zip解压,将lib下的所又内容包拷贝到/opt/iobjects_spark目录中,内容如下:

3.2 iObjects for Spark配置
1.将for Spark和iObjects Java环境变量配置到/etc/profile中,结合之前hadoop和spark配置,并使用命令source /etc/profile使其生效。总配置如下
export JAVA_HOME=/opt/jdk
export JRE_HOME=/opt/jdk/jre
export HADOOP_HOME=/opt/hadoop-2.7.7
export PATH=$HADOOP_HOME/bin:$HIVE_HOME/bin:$JAVA_HOME/bin:$PATH
export SPARK_HOME=/opt/spark-2.1.0-bin-hadoop2.7
export SUPERMAP_OBJ=/opt/iobjects_new
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$SUPERMAP_OBJ
export SPARK_CLASSPATH=$SPARK_CLASSPATH:/opt/iobjects_spark
2.进入spark-2.1.0-bin-hadoop2.7/conf
编辑spark-env.sh文件,总配置如下,注意SUPERMAP_OBJ顺序
export JAVA_HOME=/opt/jdk
export SPARK_MASTER_IP=192.168.241.132
export SPARK_WORKER_MEMORY=8g
export SPARK_WORKER_CORES=4
export SPARK_EXECUTOR_MEMORY=4g
export HADOOP_HOME=/opt/hadoop-2.7.7/
export HADOOP_CONF_DIR=/opt/hadoop-2.7.7/etc/hadoop
export SUPERMAP_OBJ=/opt/iobjects_new
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$SUPERMAP_OBJ:/opt/jdk/jre/lib/amd64
3.3 集群配置
主节点修改完文件后,记得scp传递到子节点中,并重启Spark服务。
scp /etc/profile root@另一台机器名:/etc/profile
3.4 实例程序验证
我们使用for Spark示例来验证是否安装成功。
3.4.1 将for Spark产品包中的示例数据放到中/opt/中。
- newyork_taxi_2013-01_14k.csv
- newyork_taxi_2013-01_14k.meta
3.4.2 将示例数据导入到hdfs中。
启动hadoop,在hadoop-2.7.7/bin中执行
./hadoop fs -mkdir /input #创建/input目录
./hdfs dfs -put /opt/newyork_taxi_2013-01_14k.csv /input/
./hdfs dfs -put /opt/newyork_taxi_2013-01_14k.meta /input/
导入完成后,可以使用如下命名查看
./hadoop fs -ls /input

3.4.3 创建文件输出文件夹
mkdir /opt/data/
3.4.4 安装所却检查依赖
可以使用iServer一键化安装依赖工具,支持(Suse、Redhat、Ubuntu)将iServer自带的support文件夹拷贝到opt下,iServer下载地址:http://support.supermap.com.cn/DownloadCenter/DownloadPage.aspx?id=1050
./dependencies_check_and_install.sh install -y
3.4.5 安装许可 (support/SuperMap_License/Support/aksusbd-2.4.1-i386)
./dinst
看到如下输出内容代表安装成功
dpkg-query: no packages found matching aksusbd
Copy AKSUSB daemon to /usr/sbin ...
Copy WINEHASP daemon to /usr/sbin ...
Copy HASPLMD daemon to /usr/sbin ...
Copy start-up script to /etc/init.d ...
Link HASP SRM runtime environment startup script to system startup folder
Starting HASP SRM runtime environment...
Starting AKSUSB daemon: .
Starting WINEHASP daemon: .
Starting HASPLM daemon: .
Coping VLIB...
Installing v2c...
Done
3.4.6 启动Spark,切换到spark-2.1.0-bin-hadoop2.7/bin下执行(点数据集网格聚合统计)
./spark-submit --class com.supermap.bdt.main.SummarizeMeshMain --master spark://master:7077 /opt/iobjects_spark/com.supermap.bdt.core-9.1.1.jar --input '{"type":"csv","info":[{"server":"hdfs://master:9000/input/newyork_taxi_2013-01_14k.csv"}]}' --meshType hexagon --bounds -74.05,40.6,-73.75,40.9 --meshSize 100 --output '{"type":"udb","server":"/opt/data/SummaryMain.udb","datasetName":"SummaryMain"}'
简单解释下命令
--class 表示主类名称,含包名,本例子指的是需要执行的类
--master Spark集群总入口
--input 简单理解为操作数据来源
--meshType 网格类型
-- bounds 范围
--output 输出路径
--meshSize 聚合范围(默认单位是米)
3.4.7 执行开始

3.4.8 执行过程中,可以访问http://192.168.241.132:4040/jobs/查看执行情况

3.4.9 执行完成后,访问/opt/data可以查看完成的内容,如果大小不为0则代表分析成功
root@master:/opt/spark-2.1.0-bin-hadoop2.7/bin# ll /opt/data/
total 2376
drwxr-xr-x 2 root root 4096 Mar 19 17:13 ./
drwxr-xr-x 11 root root 4096 Mar 19 16:43 ../
-rw-r--r-- 1 root root 1437160 Mar 19 17:13 SummaryMain.udb
-rw-r--r-- 1 root root 986112 Mar 19 17:13 SummaryMain.udd

3.4.10 将数据下载下来使用iDesktop .NET 打开查看
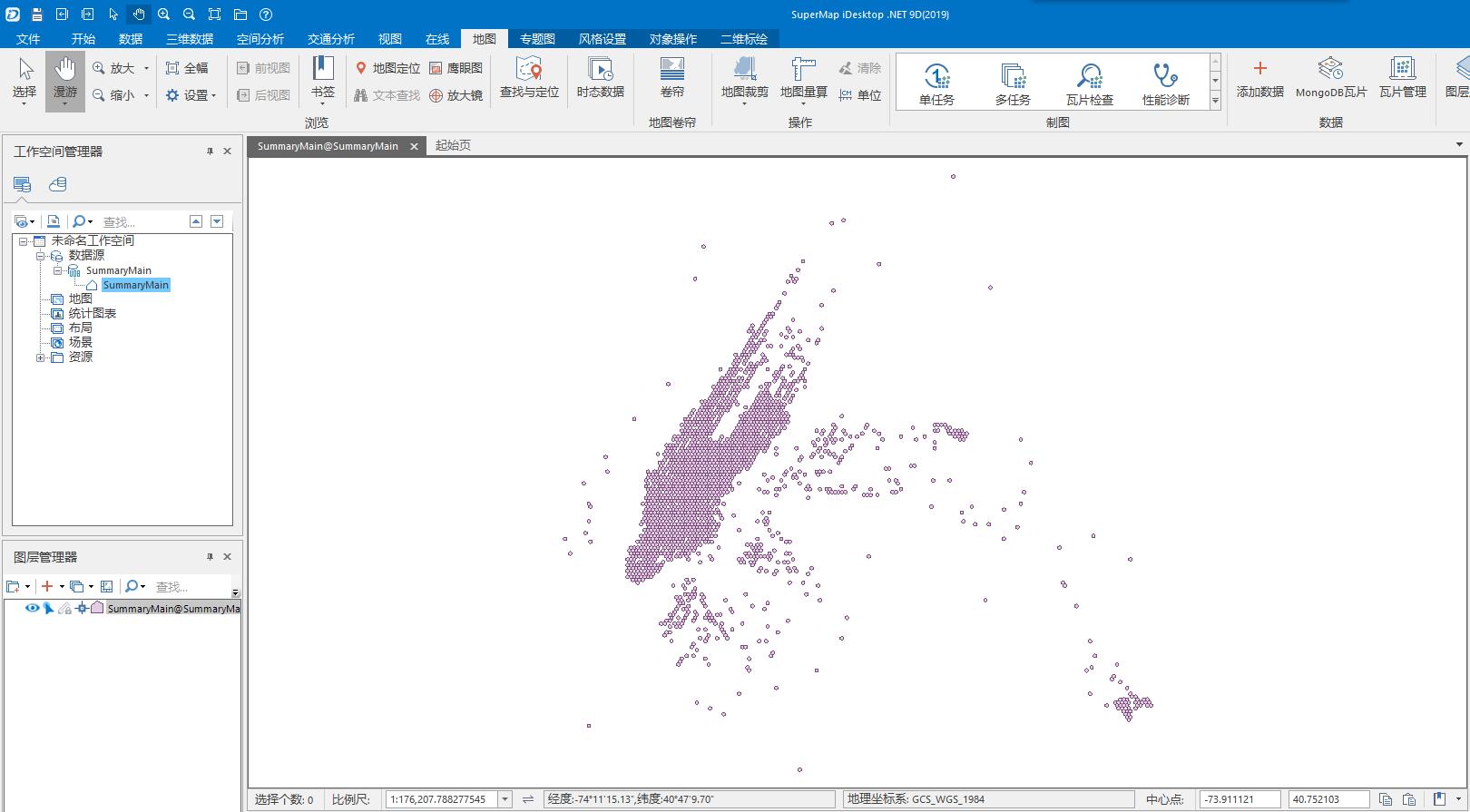
(转发请注明出处:http://www.cnblogs.com/zhangyongli2011/ 如发现有错,请留言,谢谢)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了
· 上周热点回顾(2.24-3.2)