Hadoop(十二)MapReduce概述
前言
前面以前把关于HDFS集群的所有知识给讲解完了,接下来给大家分享的是MapReduce这个Hadoop的并行计算框架。
一、背景
1)爆炸性增长的Web规模数据量
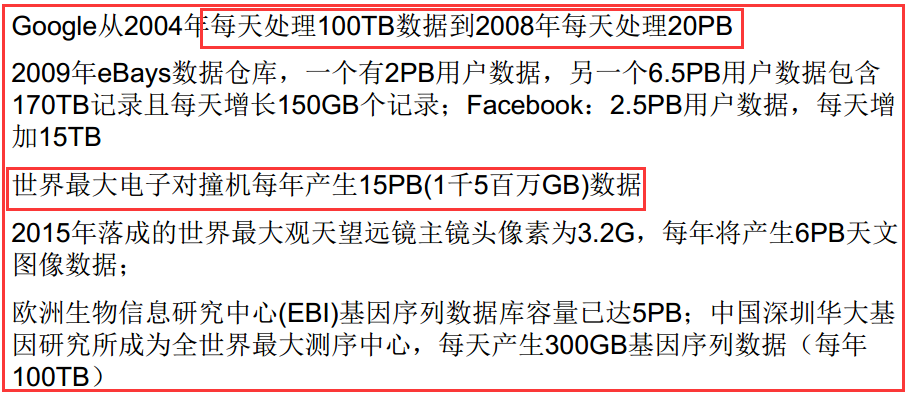
2)超大的计算量/计算复杂度

3)并行计算大趋所势

二、大数据的并行计算
1)一个大数据若可以分为具有同样计算过程的数据块,并且这些数据块之间不存在数据依赖关系,则提高处理速度最好的办法就是并行计算。
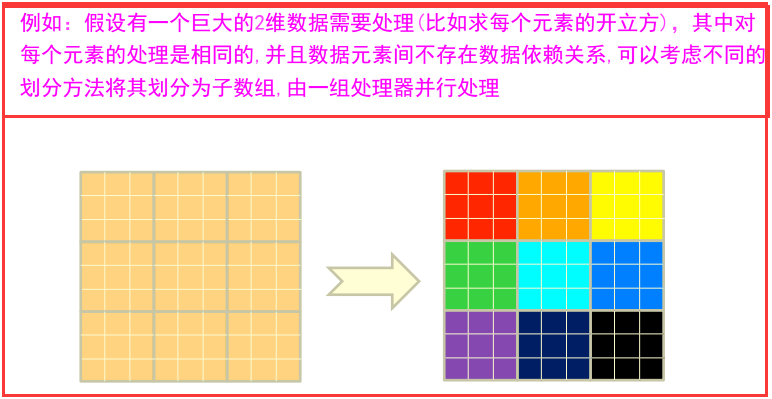
2)大数据并行计算
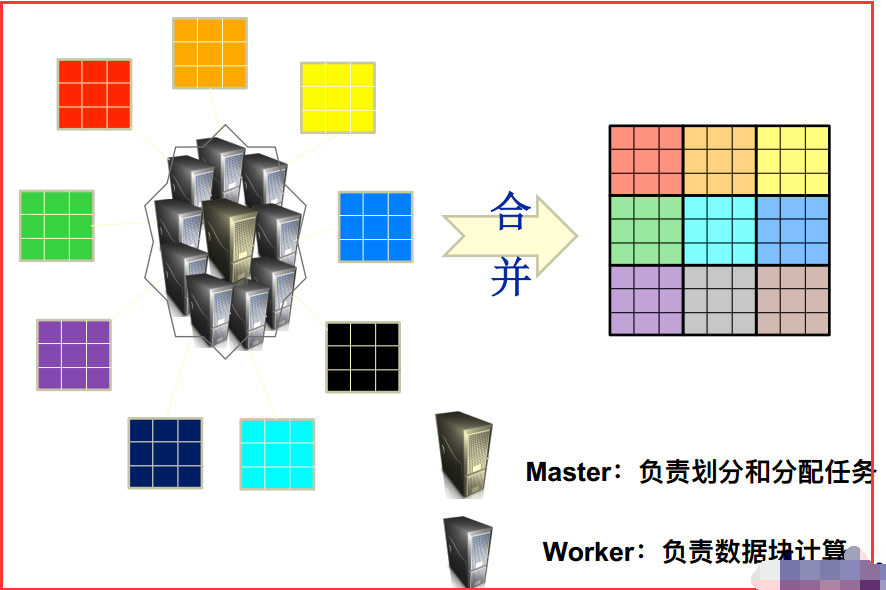
三、Hadoop的MapReduce概述
3.1、需要MapReduce原因

3.2、MapReduce简介
1)产生MapReduce背景

2)整体认识
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,用于解决海量数据的计算问题。
MapReduce分成了两个部分:
1)映射(Mapping)对集合里的每个目标应用同一个操作。即,如果你想把表单里每个单元格乘以二,那么把这个函数单独地应用在每个单元格上的操作就属于mapping。
2)化简(Reducing)遍历集合中的元素来返回一个综合的结果。即,输出表单里一列数字的和这个任务属于reducing。
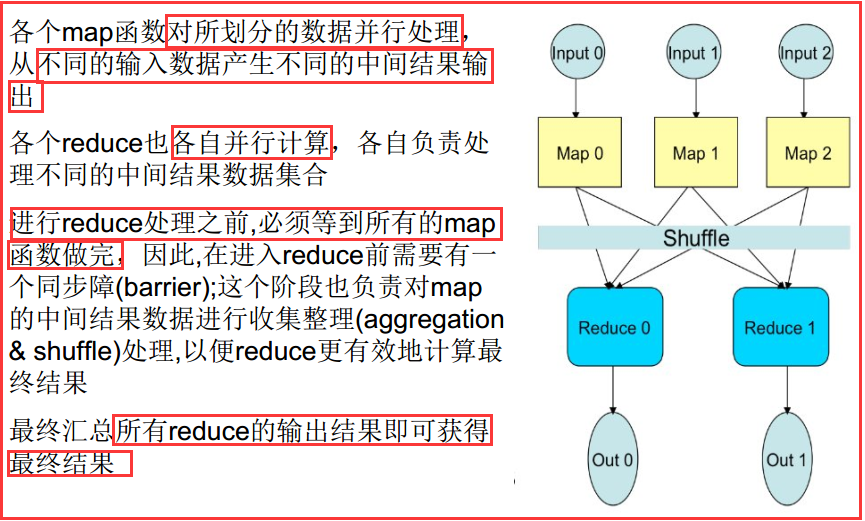
你向MapReduce框架提交一个计算作业时,它会首先把计算作业拆分成若干个Map任务,然后分配到不同的节点上去执行,
每一个Map任务处理输入数据中的一部分,当Map任务完成后,它会生成一些中间文件,这些中间文件将会作为Reduce任务的输入数据。
Reduce任务的主要目标就是把前面若干个Map的输出汇总到一起并输出。
MapReduce的伟大之处就在于编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
3.3、MapReduce编程模型
1)MapReduce借鉴了函数式程序设计语言Lisp中的思想,定义了如下的Map和Reduce两个抽象的编程接口。由用户去编程实现:

注意:Map是一行一行去处理数据的。
2)详细的处理过程
四、编写MapReduce程序
4.1、数据样式与环境
1)环境
我使用的是Maven,前面 有我配置的pom.xml文件。
2)数据样式
这是一个专利引用文件,格式是这样的:
专利ID:被引用专利ID
1,2
1,3
2,3
3,4
2,4
4.2、需求分析
1)需求
计算出被引用专利的次数
2)分析
从上面的数据分析出,我们需要的是一行数据中的后一个数据。分析一下:
在map函数中,输入端v1代表的是一行数据,输出端的k2可以代表是被引用的专利,在一行数据中所以v2可以被赋予为1。
在reduce函数中,k2还是被引用的专利,而[v2]是一个数据集,这里是将k2相同的键的v2数据合并起来。最后输出的是自己需要的数据k3代表的是被引用的专利,v3是引用的次数。
画图分析:

4.3、代码实现
1)编写一个解析类,用来解析数据文件中一行一行的数据。

import org.apache.hadoop.io.Text; public class PatentRecordParser { //1,2 //1,3 //2,3 //表示数据中的第一列 private String patentId; //表示数据中的第二列 private String refPatentId; //表示解析的当前行的数据是否有效 private boolean valid; public void parse(String line){ String[] strs = line.split(","); if (strs.length==2){ patentId = strs[0].trim(); refPatentId = strs[1].trim(); if (patentId.length()>0&&refPatentId.length()>0){ valid = true; } } } public void parse(Text line){ parse(line.toString()); } public String getPatentId() { return patentId; } public void setPatentId(String patentId) { this.patentId = patentId; } public String getRefPatentId() { return refPatentId; } public void setRefPatentId(String refPatentId) { this.refPatentId = refPatentId; } public boolean isValid() { return valid; } public void setValid(boolean valid) { this.valid = valid; } }
2)编写PatentReference_0011去实现真正的计算
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.IOException; public class PatentReference_0011 extends Configured implements Tool { //-Dinput=/data/patent/cite75_99.txt public static class PatentMapper extends Mapper<LongWritable,Text,Text,IntWritable>{ private PatentRecordParser parser = new PatentRecordParser(); private Text key = new Text(); //把进入reduce的value都设置成1 private IntWritable value = new IntWritable(1); //进入map端的数据,每次进入一行。 //MapReduce都是具有一定结构的数据,有一定含义的数据。 //进入时候map的k1(该行数据首个字符距离整个文档首个字符的距离),v1(这行数据的字符串) @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { parser.parse(value); if (parser.isValid()){ this.key.set(parser.getRefPatentId()); context.write(this.key,this.value); } } } public static class PatentReducer extends Reducer<Text,IntWritable,Text,IntWritable>{ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count = 0; for (IntWritable iw:values){ count+=iw.get(); } context.write(key,new IntWritable(count)); //注意:在map或reduce上面的打印语句是没有办法输出的,但会记录到日志文件当中。 } } @Override public int run(String[] args) throws Exception { //构建作业所处理的数据的输入输出路径 Configuration conf = getConf(); Path input = new Path(conf.get("input")); Path output = new Path(conf.get("output")); //构建作业配置 Job job = Job.getInstance(conf,this.getClass().getSimpleName()+"Lance");//如果不指定取的名字就是当前类的类全名 //设置该作业所要执行的类 job.setJarByClass(this.getClass()); //设置自定义的Mapper类以及Map端数据输出时的类型 job.setMapperClass(PatentMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //设置自定义的Reducer类以及输出时的类型 job.setReducerClass(PatentReducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); //设置读取最原始数据的格式信息以及 //数据输出到HDFS集群中的格式信息 job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); //设置数据读入和写出的路径到相关的Format类中 TextInputFormat.addInputPath(job,input); TextOutputFormat.setOutputPath(job,output); //提交作业 return job.waitForCompletion(true)?0:1; } public static void main(String[] args) throws Exception { System.exit( ToolRunner.run(new PatentReference_0011(),args) );; } }
3)使用Maven打包好,上传到安装配置好集群客户端的Linux服务器中
4)运行测试

执行上面的语句,注意指定输出路径的时候,一定是集群中的路径并且目录要预先不存在,因为程序会自动去创建这个目录。
5)然后我们可以去Web控制页面去观察htttp://ip:8088去查看作业的进度
喜欢就点“推荐”哦!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构