

MySQL发生死锁有哪些原因,怎么避免?
一、Mysql 锁类型和加锁分析
锁类型介绍:
MySQL有三种锁的级别:页级、表级、行级。
- 表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低。
- 行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
- 页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般
算法:
- next KeyLocks锁,同时锁住记录(数据),并且锁住记录前面的Gap
- Gap锁,不锁记录,仅仅记录前面的Gap
- Recordlock锁(锁数据,不锁Gap)
- 所以其实 Next-KeyLocks=Gap锁+ Recordlock锁
二、死锁产生原因和示例
1、产生原因:
所谓死锁<DeadLock>:是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去.此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。表级锁不会产生死锁.所以解决死锁主要还是针对于最常用的InnoDB。
死锁的关键在于:两个(或以上)的Session加锁的顺序不一致。
那么对应的解决死锁问题的关键就是:让不同的session加锁有次序
2、产生示例:
案例一
需求:将投资的钱拆成几份随机分配给借款人。
起初业务程序思路是这样的:
投资人投资后,将金额随机分为几份,然后随机从借款人表里面选几个,然后通过一条条select for update 去更新借款人表里面的余额等。
例如两个用户同时投资,A用户金额随机分为2份,分给借款人1,2
B用户金额随机分为2份,分给借款人2,1
由于加锁的顺序不一样,死锁当然很快就出现了。
对于这个问题的改进很简单,直接把所有分配到的借款人直接一次锁住就行了。
Select * from xxx where id in (xx,xx,xx) for update
在in里面的列表值mysql是会自动从小到大排序,加锁也是一条条从小到大加的锁
例如(以下会话id为主键):
Session1:
mysql> select * from t3 where id in (8,9) for update;
+----+--------+------+---------------------+
| id | course | name | ctime |
+----+--------+------+---------------------+
| 8 | WA | f | 2016-03-02 11:36:30 |
| 9 | JX | f | 2016-03-01 11:36:30 |
+----+--------+------+---------------------+
rows in set (0.04 sec)
Session2:
select * from t3 where id in (10,8,5) for update;
锁等待中……
其实这个时候id=10这条记录没有被锁住的,但id=5的记录已经被锁住了,锁的等待在id=8的这里 不信请看
Session3:
mysql> select * from t3 where id=5 for update;
锁等待中
Session4:
mysql> select * from t3 where id=10 for update;
+----+--------+------+---------------------+
| id | course | name | ctime |
+----+--------+------+---------------------+
| 10 | JB | g | 2016-03-10 11:45:05 |
+----+--------+------+---------------------+
row in set (0.00 sec)
在其它session中id=5是加不了锁的,但是id=10是可以加上锁的。
案例二
在开发中,经常会做这类的判断需求:根据字段值查询(有索引),如果不存在,则插入;否则更新。
以id为主键为例,目前还没有id=22的行
Session1:
select * from t3 where id=22 for update;
Empty set (0.00 sec)
session2:
select * from t3 where id=23 for update;
Empty set (0.00 sec)
Session1:
insert into t3 values(22,'ac','a',now());
锁等待中……
Session2:
insert into t3 values(23,'bc','b',now());
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
当对存在的行进行锁的时候(主键),mysql就只有行锁。
当对未存在的行进行锁的时候(即使条件为主键),mysql是会锁住一段范围(有gap锁)
锁住的范围为:
(无穷小或小于表中锁住id的最大值,无穷大或大于表中锁住id的最小值)
如:如果表中目前有已有的id为(11 , 12),那么就锁住(12,无穷大)
如果表中目前已有的id为(11 , 30),那么就锁住(11,30)
对于这种死锁的解决办法是:
insert into t3(xx,xx) on duplicate key update `xx`='XX';
用mysql特有的语法来解决此问题。因为insert语句对于主键来说,插入的行不管有没有存在,都会只有行锁。
案例三
mysql> select * from t3 where id=9 for update;
+----+--------+------+---------------------+
| id | course | name | ctime |
+----+--------+------+---------------------+
| 9 | JX | f | 2016-03-01 11:36:30 |
+----+--------+------+---------------------+
row in set (0.00 sec)
Session2:
mysql> select * from t3 where id<20 for update;
锁等待中
Session1:
mysql> insert into t3 values(7,'ae','a',now());
ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction
这个跟案例一其它是差不多的情况,只是session1不按常理出牌了,
Session2在等待Session1的id=9的锁,session2又持了1到8的锁(注意9到19的范围并没有被session2锁住),最后,session1在插入新行时又得等待session2,故死锁发生了。
这种一般是在业务需求中基本不会出现,因为你锁住了id=9,却又想插入id=7的行,这就有点跳了,当然肯定也有解决的方法,那就是重理业务需求,避免这样的写法。
案例四

一般的情况,两个session分别通过一个sql持有一把锁,然后互相访问对方加锁的数据产生死锁。
案例五
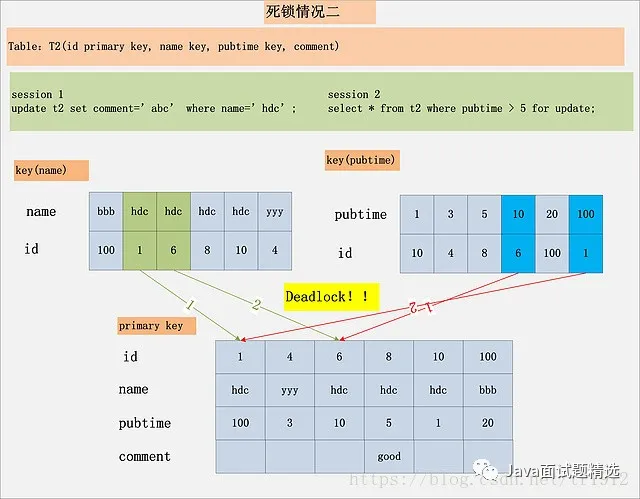
两个单条的sql语句涉及到的加锁数据相同,但是加锁顺序不同,导致了死锁。
案例六
死锁场景如下:
表结构:
CREATE TABLE dltask (
id bigint unsigned NOT NULL AUTO_INCREMENT COMMENT ‘auto id’,
a varchar(30) NOT NULL COMMENT ‘uniq.a’,
b varchar(30) NOT NULL COMMENT ‘uniq.b’,
c varchar(30) NOT NULL COMMENT ‘uniq.c’,
x varchar(30) NOT NULL COMMENT ‘data’,
PRIMARY KEY (id),
UNIQUE KEY uniq_a_b_c (a, b, c)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT=’deadlock test’;
a,b,c三列,组合成一个唯一索引,主键索引为id列。
事务隔离级别:
RR (Repeatable Read)
每个事务只有一条SQL:
delete from dltask where a=? and b=? and c=?;
SQL的执行计划:

死锁日志:

众所周知,InnoDB上删除一条记录,并不是真正意义上的物理删除,而是将记录标识为删除状态。(注:这些标识为删除状态的记录,后续会由后台的Purge操作进行回收,物理删除。但是,删除状态的记录会在索引中存放一段时间。) 在RR隔离级别下,唯一索引上满足查询条件,但是却是删除记录,如何加锁?
InnoDB在此处的处理策略与前两种策略均不相同,或者说是前两种策略的组合:对于满足条件的删除记录,InnoDB会在记录上加next key lock X(对记录本身加X锁,同时锁住记录前的GAP,防止新的满足条件的记录插入。) Unique查询,三种情况,对应三种加锁策略,总结如下:
此处,我们看到了next key锁,是否很眼熟?对了,前面死锁中事务1,事务2处于等待状态的锁,均为next key锁。明白了这三个加锁策略,其实构造一定的并发场景,死锁的原因已经呼之欲出。但是,还有一个前提策略需要介绍,那就是InnoDB内部采用的死锁预防策略。
- 找到满足条件的记录,并且记录有效,则对记录加X锁,No Gap锁(lock_mode X locks rec but not gap);
- 找到满足条件的记录,但是记录无效(标识为删除的记录),则对记录加next key锁(同时锁住记录本身,以及记录之前的Gap:lock_mode X);
- 未找到满足条件的记录,则对第一个不满足条件的记录加Gap锁,保证没有满足条件的记录插入(locks gap before rec);
死锁预防策略
InnoDB引擎内部(或者说是所有的数据库内部),有多种锁类型:事务锁(行锁、表锁),Mutex(保护内部的共享变量操作)、RWLock(又称之为Latch,保护内部的页面读取与修改)。
InnoDB每个页面为16K,读取一个页面时,需要对页面加S锁,更新一个页面时,需要对页面加上X锁。任何情况下,操作一个页面,都会对页面加锁,页面锁加上之后,页面内存储的索引记录才不会被并发修改。
因此,为了修改一条记录,InnoDB内部如何处理:
- 根据给定的查询条件,找到对应的记录所在页面;
- 对页面加上X锁(RWLock),然后在页面内寻找满足条件的记录;
- 在持有页面锁的情况下,对满足条件的记录加事务锁(行锁:根据记录是否满足查询条件,记录是否已经被删除,分别对应于上面提到的3种加锁策略之一);
死锁预防策略: 相对于事务锁,页面锁是一个短期持有的锁,而事务锁(行锁、表锁)是长期持有的锁。因此,为了防止页面锁与事务锁之间产生死锁。InnoDB做了死锁预防的策略:持有事务锁(行锁、表锁),可以等待获取页面锁;但反之,持有页面锁,不能等待持有事务锁。
根据死锁预防策略,在持有页面锁,加行锁的时候,如果行锁需要等待。则释放页面锁,然后等待行锁。此时,行锁获取没有任何锁保护,因此加上行锁之后,记录可能已经被并发修改。因此,此时要重新加回页面锁,重新判断记录的状态,重新在页面锁的保护下,对记录加锁。如果此时记录未被并发修改,那么第二次加锁能够很快完成,因为已经持有了相同模式的锁。但是,如果记录已经被并发修改,那么,就有可能导致本文前面提到的死锁问题。
以上的InnoDB死锁预防处理逻辑,对应的函数,是row0sel.c::row_search_for_mysql()。感兴趣的朋友,可以跟踪调试下这个函数的处理流程,很复杂,但是集中了InnoDB的精髓。
剖析死锁的成因
做了这么多铺垫,有了Delete操作的3种加锁逻辑、InnoDB的死锁预防策略等准备知识之后,再回过头来分析本文最初提到的死锁问题,就会手到拈来,事半而功倍。
首先,假设dltask中只有一条记录:(1, ‘a’, ‘b’, ‘c’, ‘data’)。三个并发事务,同时执行以下的这条SQL:
delete from dltask where a=’a’ and b=’b’ and c=’c’;
并且产生了以下的并发执行逻辑,就会产生死锁:

上面分析的这个并发流程,完整展现了死锁日志中的死锁产生的原因。其实,根据事务1步骤6,与事务0步骤3/4之间的顺序不同,死锁日志中还有可能产生另外一种情况,那就是事务1等待的锁模式为记录上的X锁 + No Gap锁(lock_mode X locks rec but not gap waiting)。这第二种情况,也是”润洁”同学给出的死锁用例中,使用MySQL 5.6.15版本测试出来的死锁产生的原因。
此类死锁,产生的几个前提:
- Delete操作,针对的是唯一索引上的等值查询的删除;(范围下的删除,也会产生死锁,但是死锁的场景,跟本文分析的场景,有所不同)
- 至少有3个(或以上)的并发删除操作;
- 并发删除操作,有可能删除到同一条记录,并且保证删除的记录一定存在;
- 事务的隔离级别设置为Repeatable Read,同时未设置innodb_locks_unsafe_for_binlog参数(此参数默认为FALSE);(Read Committed隔离级别,由于不会加Gap锁,不会有next key,因此也不会产生死锁)
- 使用的是InnoDB存储引擎;(废话!MyISAM引擎根本就没有行锁)
来源:blog.csdn.net/tr1912/article/details/81668423


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix