

Spring的Bean实例化过程应该是怎样的
对于写Java的程序员来说,Spring已经成为了目前最流行的第三方开源框架之一,在我们充分享受Spring IOC容器带来的红利的同时,我们也应该考虑一下Spring这个大工厂是如何将一个个的Bean生产出来的,本期我们就一起来讨论一下Spring中Bean的实例化过程。
这里我们并不会详细的分析源代码,只是给出Spring在完成哪些工作的时候使用到了什么类,这些类具体的职责都是什么,如果我们要弄清楚Spring Bean实例化的内幕与详细信息,那么可以看哪些源代码? 至于具体的详细的代码信息,大家可以查看Spring相关类的代码。
两个阶段
这里首先声明一下,Spring将管理的一个个的依赖对象称之为Bean,这从xml配置文件中也可以看出。
Spring IOC容器就好像一个生产产品的流水线上的机器,Spring创建出来的Bean就好像是流水线的终点生产出来的一个个精美绝伦的产品。既然是机器,总要先启动,Spring也不例外。因此Bean的一生从总体上来说可以分为两个阶段:
- 容器启动阶段
- Bean实例化阶段
容器的启动阶段做了很多的预热工作,为后面Bean的实例化做好了充分的准备,我们首先看一下容器的启动阶段都做了哪些预热工作。
容器启动阶段
1、配置元信息
我们说Spring IOC容器将对象实例的创建与对象实例的使用分离,我们的业务中需要依赖哪个对象不再依靠我们自己手动创建,只要向Spring要,Spring就会以注入的方式交给我们需要的依赖对象。
但是,你不干,我不干,总要有人干,既然我们将对象创建的任务交给了Spring,那么Spring就需要知道创建一个对象所需要的一些必要的信息。而这些必要的信息可以是Spring过去支持最完善的xml配置文件,或者是其他形式的例如properties的磁盘文件,也可以是现在主流的注解,甚至是直接的代码硬编码。总之,这些创建对象所需要的必要信息称为配置元信息。
<bean id="role" class="com.wbg.springxmlbean.entity.Role">
<!-- property元素是定义类的属性,name属性定义的是属性名称 value是值
相当于:
Role role=new Role();
role.setId(1);
role.setRoleName("高级工程师");
role.setNote("重要人员");-->
<property name="id" value="1"/>
<property name="roleName" value="高级工程师"/>
<property name="note" value="重要人员"/>
</bean>
2、BeanDefination
我们大家都知道,在Java世界中,万物皆对象,散落于程序代码各处的注解以及保存在磁盘上的xml或者其他文件等等配置元信息,在内存中总要以一种对象的形式表示,就好比我们活生生的人对应到Java世界中就是一个Person类。
而Spring选择在内存中表示这些配置元信息的方式就是BeanDefination,这里我们不会去分析BeanDefination的代码,感兴趣的可以去看相关源码,这里我们只是需要知道配置元信息被加载到内存之后是以BeanDefination的形存在的即可。
3、BeanDefinationReader
大家肯定很好奇,我们是看得懂Spring中xml配置文件中一个个的Bean定义,但是Spring是如何看懂这些配置元信息的呢?这个就要靠我们的BeanDefinationReader了。
不同的BeanDefinationReader就像葫芦兄弟一样,各自拥有各自的本领。如果我们要读取xml配置元信息,那么可以使用XmlBeanDefinationReader。如果我们要读取properties配置文件,那么可以使用PropertiesBeanDefinitionReader加载。
而如果我们要读取注解配置元信息,那么可以使用 AnnotatedBeanDefinitionReader加载。我们也可以很方便的自定义BeanDefinationReader来自己控制配置元信息的加载。例如我们的配置元信息存在于三界之外,那么我们可以自定义From天界之外BeanDefinationReader。
总的来说,BeanDefinationReader的作用就是加载配置元信息,并将其转化为内存形式的BeanDefination,存在某一个地方,至于这个地方在哪里,不要着急,接着往下看!
4、BeanDefinationRegistry
执行到这里,总算不遗余力的将存在于各处的配置元信息加载到内存,并转化为BeanDefination的形式,这样我们需要创建某一个对象实例的时候,找到相应的BeanDefination然后创建对象即可。那么我们需要某一个对象的时候,去哪里找到对应的BeanDefination呢?
这种通过Bean定义的id找到对象的BeanDefination的对应关系或者说映射关系又是如何保存的呢?这就引出了BeanDefinationRegistry了。
Spring通过BeanDefinationReader将配置元信息加载到内存生成相应的BeanDefination之后,就将其注册到BeanDefinationRegistry中,BeanDefinationRegistry就是一个存放BeanDefination的大篮子,它也是一种键值对的形式,通过特定的Bean定义的id,映射到相应的BeanDefination。
5、BeanFactoryPostProcessor
BeanFactoryPostProcessor是容器启动阶段Spring提供的一个扩展点,主要负责对注册到BeanDefinationRegistry中的一个个的BeanDefination进行一定程度上的修改与替换。
例如我们的配置元信息中有些可能会修改的配置信息散落到各处,不够灵活,修改相应配置的时候比较麻烦,这时我们可以使用占位符的方式来配置。例如配置Jdbc的DataSource连接的时候可以这样配置:
<bean id="dataSource"
class="org.apache.commons.dbcp.BasicDataSource"
destroy-method="close">
<property name="maxIdle" value="${jdbc.maxIdle}"></property>
<property name="maxActive" value="${jdbc.maxActive}"></property>
<property name="maxWait" value="${jdbc.maxWait}"></property>
<property name="minIdle" value="${jdbc.minIdle}"></property>
<property name="driverClassName"
value="${jdbc.driverClassName}">
</property>
<property name="url" value="${jdbc.url}"></property>
<property name="username" value="${jdbc.username}"></property>
<property name="password" value="${jdbc.password}"></property>
</bean>
BeanFactoryPostProcessor就会对注册到BeanDefinationRegistry中的BeanDefination做最后的修改,替换$占位符为配置文件中的真实的数据。
至此,整个容器启动阶段就算完成了,容器的启动阶段的最终产物就是注册到BeanDefinationRegistry中的一个个BeanDefination了,这就是Spring为Bean实例化所做的预热的工作。让我们再通过一张图的形式回顾一下容器启动阶段都是搞了什么事吧。
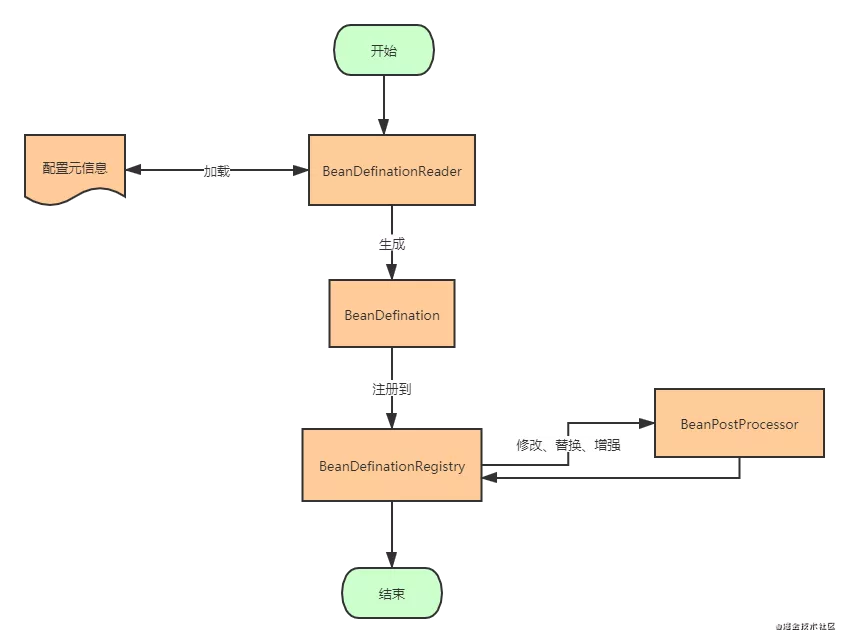
Bean实例化阶段
需要指出,容器启动阶段与Bean实例化阶段存在多少时间差,Spring把这个决定权交给了我们程序员(是不是瞬间开心了一点点!)。
如果我们选择懒加载的方式,那么直到我们伸手向Spring要依赖对象实例之前,其都是以BeanDefinationRegistry中的一个个的BeanDefination的形式存在,也就是Spring只有在我们需要依赖对象的时候才开启相应对象的实例化阶段。
而如果我们不是选择懒加载的方式,容器启动阶段完成之后,将立即启动Bean实例化阶段,通过隐式的调用所有依赖对象的getBean方法来实例化所有配置的Bean并保存起来。
接下来我们就聊一聊Bean实例化过程的那些事儿~
1、对象创建策略
到了这个时候,Spring就开始真刀真枪的干了,对象的创建采用了策略模式,借助我们前面BeanDefinationRegistry中的BeanDefination,我们可以使用反射的方式创建对象,也可以使用CGlib字节码生成创建对象。
同时我们可以灵活的配置来告诉Spring采用什么样的策略创建指定的依赖对象。Spring中Bean的创建是策略设计模式的经典应用。这个时候,内存中应该已经有一个我们想要的具体的依赖对象的实例了,但是故事的发展还没有我们想象中的那么简单。
关于策略模式有不了解的可以查阅相关书籍,或者网上相关资料,这是设计模式相关的内容,本文主要关注Bean实例化的整体流程,设计模式相关知识不在讨论。
2、BeanWrapper——对象的外衣
Spring中的Bean并不是以一个个的本来模样存在的,由于Spring IOC容器中要管理多种类型的对象,因此为了统一对不同类型对象的访问,Spring给所有创建的Bean实例穿上了一层外套,这个外套就是BeanWrapper(关于BeanWrapper的具体内容感兴趣的请查阅相关源码)。
BeanWrapper实际上是对反射相关API的简单封装,使得上层使用反射完成相关的业务逻辑大大的简化,我们要获取某个对象的属性,调用某个对象的方法,现在不需要在写繁杂的反射API了以及处理一堆麻烦的异常,直接通过BeanWrapper就可以完成相关操作,简直不要太爽了。
3、设置对象属性
上一步包裹在BeanWrapper中的对象还是一个少不经事的孩子,需要为其设置属性以及依赖对象。
对于基本类型的属性,如果配置元信息中有配置,那么将直接使用配置元信息中的设置值赋值即可,即使基本类型的属性没有设置值,那么得益于JVM对象实例化过程,属性依然可以被赋予默认的初始化零值。
对于引用类型的属性,Spring会将所有已经创建好的对象放入一个Map结构中,此时Spring会检查所依赖的对象是否已经被纳入容器的管理范围之内,也就是Map中是否已经有对应对象的实例了。如果有,那么直接注入,如果没有,那么Spring会暂时放下该对象的实例化过程,转而先去实例化依赖对象,再回过头来完成该对象的实例化过程。
这里有一个Spring中的经典问题,那就是Spring是如何解决循环依赖的?
这里简单提一下,Spring是通过三级缓存解决循环依赖,并且只能解决Setter注入的循环依赖,请大家思考一下如何解决?为何只能是Setter注入?详细内容可以查阅相关博客,文档,书籍。
4、检查Aware相关接口
我们知道,我们如果想要依赖Spring中的相关对象,使用Spring的相关API,那么可以实现相应的Aware接口,Spring IOC容器就会为我们自动注入相关依赖对象实例。
Spring IOC容器大体可以分为两种,BeanFactory提供IOC思想所设想所有的功能,同时也融入AOP等相关功能模块,可以说BeanFactory是Spring提供的一个基本的IOC容器。ApplicationContext构建于BeanFactory之上,同时提供了诸如容器内的时间发布、统一的资源加载策略、国际化的支持等功能,是Spring提供的更为高级的IOC容器。
讲了这么多,其实就是想表达对于BeanFactory来说,这一步的实现是先检查相关的Aware接口,然后去Spring的对象池(也就是容器,也就是那个Map结构)中去查找相关的实例(例如对于ApplicationContextAware接口,就去找ApplicationContext实例),也就是说我们必须要在配置文件中或者使用注解的方式,将相关实例注册容器中,BeanFactory才可以为我们自动注入。
而对于ApplicationContext,由于其本身继承了一系列的相关接口,所以当检测到Aware相关接口,需要相关依赖对象的时候,ApplicationContext完全可以将自身注入到其中,ApplicationContext实现这一步是通过下面要讲到的东东——BeanPostProcessor。

例如ApplicationContext继承自ResourceLoader和MessageSource,那么当我们实现ResourceLoaderAware和MessageSourceAware相关接口时,就将其自身注入到业务对象中即可。
5、BeanPostProcessor前置处理
唉?刚才那个是什么Processor来?相信刚看这两个东西的人肯定有点晕乎了,我当初也是,不过其实也好区分,只要记住BeanFactoryPostProcessor存在于容器启动阶段而BeanPostProcessor存在于对象实例化阶段,BeanFactoryPostProcessor关注对象被创建之前 那些配置的修修改改,缝缝补补,而BeanPostProcessor阶段关注对象已经被创建之后 的功能增强,替换等操作,这样就很容易区分了。
BeanPostProcessor与BeanFactoryPostProcessor都是Spring在Bean生产过程中强有力的扩展点。如果你还对它感到很陌生,那么你肯定知道Spring中著名的AOP(面向切面编程),其实就是依赖BeanPostProcessor对Bean对象功能增强的。
BeanPostProcessor前置处理就是在要生产的Bean实例放到容器之前,允许我们程序员对Bean实例进行一定程度的修改,替换等操作。
前面讲到的ApplicationContext对于Aware接口的检查与自动注入就是通过BeanPostProcessor实现的,在这一步Spring将检查Bean中是否实现了相关的Aware接口,如果是的话,那么就将其自身注入Bean中即可。Spring中AOP就是在这一步实现的偷梁换柱,产生对于原生对象的代理对象,然后将对源对象上的方法调用,转而使用代理对象的相同方法调用实现的。
6、自定义初始化逻辑
在所有的准备工作完成之后,如果我们的Bean还有一定的初始化逻辑,那么Spring将允许我们通过两种方式配置我们的初始化逻辑:
- InitializingBean
- 配置init-method参数
一般通过配置init-method方法比较灵活。
7、BeanPostProcess后置处理
与前置处理类似,这里是在Bean自定义逻辑也执行完成之后,Spring又留给我们的最后一个扩展点。我们可以在这里在做一些我们想要的扩展。
8、自定义销毁逻辑
这一步对应自定义初始化逻辑,同样有两种方式:
- 实现DisposableBean接口
- 配置destory-method参数。
这里一个比较典型的应用就是配置dataSource的时候destory-method为数据库连接的close()方法。
9、使用
经过了以上道道工序,我们终于可以享受Spring为我们带来的便捷了,这个时候我们像对待平常的对象一样对待Spring为我们产生的Bean实例,如果你觉得还不错的话,动手试一下吧!
10、调用回调销毁接口
Spring的Bean在为我们服务完之后,马上就要消亡了(通常是在容器关闭的时候),别忘了我们的自定义销毁逻辑,这时候Spring将以回调的方式调用我们自定义的销毁逻辑,然后Bean就这样走完了光荣的一生!
我们再通过一张图来一起看一看Bean实例化阶段的执行顺序是如何的?
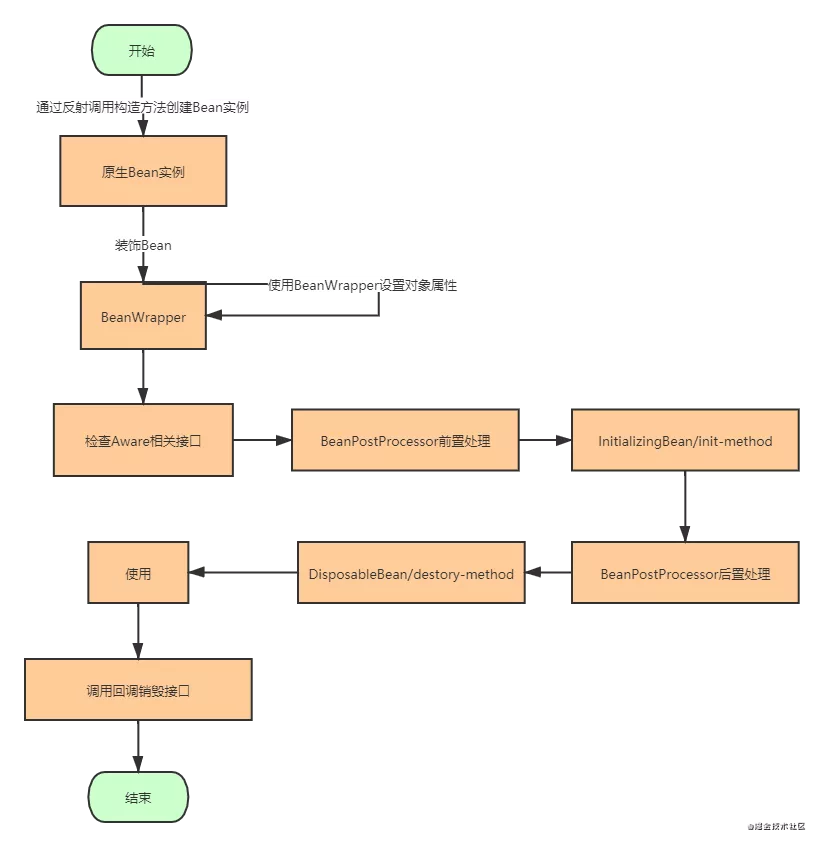
需要指出,容器启动阶段与Bean实例化阶段之间的桥梁就是我们可以选择自定义配置的延迟加载策略,如果我们配置了Bean的延迟加载策略,那么只有我们在真实的使用依赖对象的时候,Spring才会开始Bean的实例化阶段。
而如果我们没有开启Bean的延迟加载,那么在容器启动阶段之后,就会紧接着进入Bean实例化阶段,通过隐式的调用getBean方法,来实例化相关Bean。
来源:juejin.cn/post/6929672218322731022


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix